
基于激光雷达和视觉信息融合的车辆识别与跟踪*
2020-11-27 12:16宫铭钱冀杰种一帆陈琼红
汽车技术 2020年11期
宫铭钱 冀杰 种一帆 陈琼红
(西南大学,重庆 400715)
1 前言
利用车载传感器对车辆目标进行识别和跟踪,是实现自动驾驶功能最重要的任务之一,国内外诸多学者正对该领域进行积极探索和研究。Zhang[1]等人采用3D连通分量分析技术处理激光雷达点云数据,并提出面积、矩形和细长度3 个特征来检测车辆。基于不同障碍物对激光反射强度不同的特性,Attila Börcs[2]等人将激光雷达点云投影到地面,并在地面俯视图中将车辆近似成矩形。孔栋[3]、邹斌[4]、苏致远[5]等人对激光雷达点云数据进行边界提取,分别采用K-Means 算法和DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法对边界内的障碍物点云进行聚类,根据障碍物内部特征点和边界特征判断是否为车辆目标。车辆在行驶过程中容易被其他车辆或环境障碍物遮挡,因此,仅依靠激光雷达点云数据识别车辆目标具有一定的局限性。
机器视觉是识别车辆目标的另外一个重要手段。Liu[6]和Sayanan Sivaraman[7]等人将支持向量机(Support Vector Machine,SVM)分别与含有Haar小波系数的特征向量和方向梯度直方图(Histogram of Oriented Gradient,HOG)特征结合,实现图像中车辆目标的识别。Cui[8]等人结合Haar-like 特征与AdaBoost 分类器,通过检测车辆的尾部来判断车辆目标。在深度学习领域,更快速区域卷积神经网络(Faster Region-based Convolutional Neural Network,Faster R-CNN)[9]框架提出了利用区域建议网络(Region Propose Network,RPN)来寻找区域候选框,进而得到车辆目标的方法,该网络在GPU 上运行,识别速度和精度大幅提高。
Tan[10]等人采用HOG 特征和SVM 分类器识别车辆目标,并利用毫米波雷达确定目标的深度信息。Huang[11]等人使用Haar-like 特征识别车辆目标,采用激光雷达测量目标的深度信息。融合两种传感器的信息能够弥补单一传感器的一些局限性,得到更加丰富的目标信息。
多目标跟踪中常用的数据关联方法有最近邻(Nearest Neighbors,NN)算法、全局最近邻(Global Nearest Neighbor,GNN)算法、概率数据关联(Probabilistic Data Association,PDA)算法、联合概率数据关联(Joint Probabilistic Data Association,JPDA)算法、多假设跟踪(Multiple Hypothesis Tracking,MHT)算法[12]。MHT算法计算所有测量结果与已知目标的关联,其固有的复杂性延长了计算时间。JPDA 算法避免了NN 算法的唯一性,且只考虑有效测量结果与已知目标的关联,是目前在杂波环境中进行多目标跟踪常用的方法。
本文对激光雷达点云数据进行分割和聚类处理,采用深度学习框架识别图像中的车辆目标,融合两种信息获得完整的车辆目标信息,并利用JPDA 算法和卡尔曼滤波器对车辆目标进行跟踪。
2 激光雷达点云数据处理
以Velodyne 64 线激光雷达为例,每帧采集的点云数据数量级达10 万个,直接处理原始数据比较复杂。智能车在行驶过程中只需要对车道范围附近的车辆目标进行识别,因此可以缩小激光雷达的扫描范围,减少需处理的点云数据量。点云数据中相当一部分点云属于地面点云,因此,根据激光雷达在智能车上的安装位置,选取距离地面0.2 m以上范围内的点云进行处理,从而避免地面点云的影响。原始点云数据与去除地面点云后的数据如图1所示。由图1可以看出:原始点云的数据量较大且地面点云所占比重较大,而经过地面点云去除处理后,保留的障碍物点云数据量大幅减少,有利于提高点云处理的效率。
去除地面点云后,本文选择基于密度的聚类算法DBSCAN[13]对剩余的障碍物点云进行聚类,该算法的主要思想是将空间中密度足够大的区域归为一簇,它能够发现空间中任意形状的障碍物且不受聚类数量的影响。相比于K-Means 算法和只考虑点云到单个聚类质心的欧氏距离的迭代式自组织数据分析技术算法(Iterative Self-Organizing Data Analysis Technique Algorithm,ISODATA),DBSCAN算法更具优势。定义参数ε和M,分别表示聚类阈值和目标数量,当给定对象的ε邻域内目标数量超过M时,将该邻域内所有对象归为相同簇。
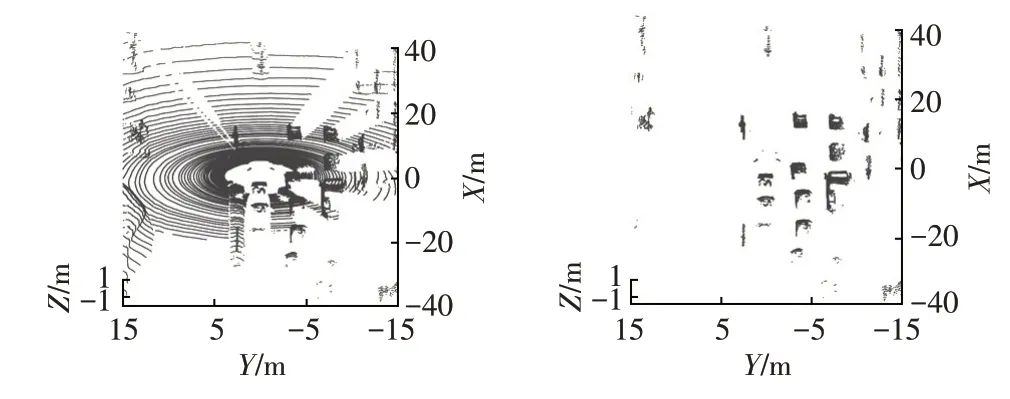
图1 地面点云处理结果
激光雷达的激光以雷达为中心向外发散,因此,距离激光雷达越远,相邻扫描点的距离就越远,点云的密度随着深度的变化而变化。因此,本文在传统DBSCAN 算法的基础上提出了一种自适应聚类阈值的算法,该算法能够根据扫描点与激光雷达的距离自动调整聚类阈值。
三维激光雷达对立体物体的相邻2 次扫描结果如图2所示。其中,α、β分别为激光雷达垂直、水平方向的角度间隔,L1为点1到激光雷达的距离,L12、L14分别为点1与点2、点1与点4之间的距离。
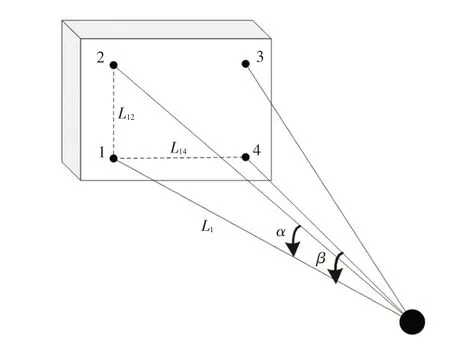
图2 激光雷达相邻2次扫描结果
假设点1 为选定对象,则L12、L14分别可以近似为L1×α/180和L1×β/180,则,因此,对象i的聚类阈值εi可以表示为:
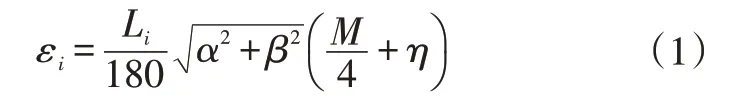
式中,Li为点i到激光雷达的距离;η为补偿参数,本文取η=2。
改进后的DBSCAN 算法对于距离激光雷达较远的障碍物聚类更加准确。利用改进的DBSCAN算法,点云数据被处理成多个大小不一的障碍物和噪声点。由于汽车可以近似看成空间中的立方体,因此对于聚类后的障碍物,采用一个包罗其边界的最小六面体来代表该障碍物。提取每个六面体最靠近激光雷达的水平线的中点坐标作为该障碍物的坐标(x,y),用于表征该障碍物与激光雷达的距离。传统DBSCAN算法与改进的DBSCAN算法对点云数据的处理结果如图3所示。从图3中可以看出:由于远处的点云比较稀疏,固定的ε对远处点云的聚类效果变差,导致图中1、2处的障碍物无法被完整地聚类,甚至部分有效目标被划分为环境中的噪声点,此种情况下无法得到较为完整的障碍物信息;而采用了随点云距离自适应的ε后,任意位置的障碍物都能够被完整地聚类,保证了障碍物在不同位置时的信息完整性。
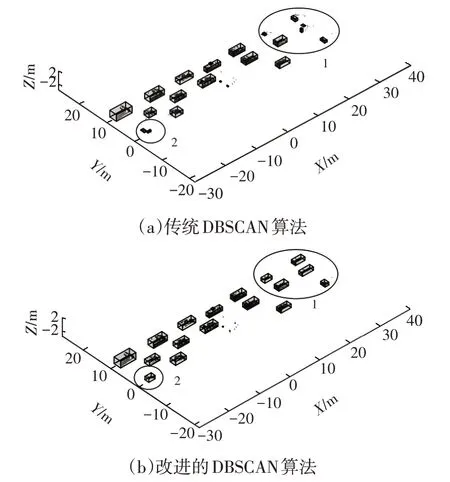
图3 2种算法的点云数据处理结果
3 图像处理
Faster R-CNN 是在快速区域卷积神经网络(Fast Region-based Convolutional Neural Network,Fast RCNN)的基础上提出的一种目标检测方法,它利用RPN 来寻找可能包含目标的区域候选框。RPN 与检测网络共享全图像卷积特征并且在GPU 上运行,提高了检测网络的处理速度。该方法的工作过程如图4所示。
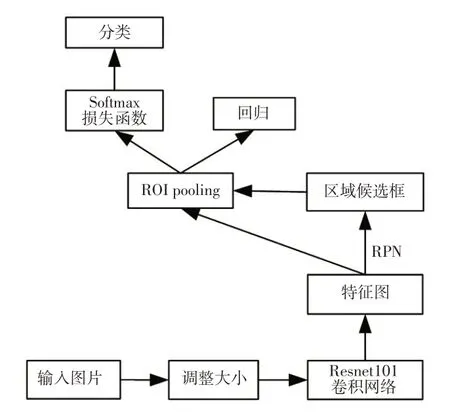
图4 Faster R-CNN架构
本文使用KITTI 数据集中6 000 张包含汽车的图片对神经网络进行训练。首先输入图像,并根据选用的Resnet101 卷积网络调整图像的大小,得到卷积特征图,然后利用RPN 在特征图上提取可能包含目标的区域候选框。ROI pooling 部分对区域候选框进行池化操作,与Fast R-CNN 相同,将不同尺寸的输入转换为固定尺寸的输出。最后利用检测网络进行回归和分类处理,得到目标边框和得分如图5 所示。由图5 可知,目标分类器能够在丰富的图像信息中准确地识别到车辆目标,目标的得分接近于1,表明目标的识别精度非常高。

图5 车辆目标识别结果
4 传感器信息融合
传感器信息融合涉及时间同步和空间匹配。由于激光雷达扫描范围的缩小以及地面点云的去除,实际处理的点云数据量较少,点云聚类速度达到20 帧/s,基本满足低、中速驾驶的需求。鉴于激光雷达的扫描频率较为稳定,且相机的扫描频率高于激光雷达,因此以激光雷达的扫描时刻为基准,每次扫描的同时触发相机进行一次扫描,以此保证激光雷达数据和相机数据的时间一致性。
点云数据位于以激光雷达为圆心的激光雷达坐标系OlXlYlZl下,视觉图像信息位于以相机为圆心的相机坐标系OcXcYcZc下。由于激光雷达与相机的安装位置和角度不同,为了实现2 种传感器的空间信息融合,需要对其坐标系进行联合标定。激光雷达坐标系与相机坐标系的转换关系可以表示为[14]:
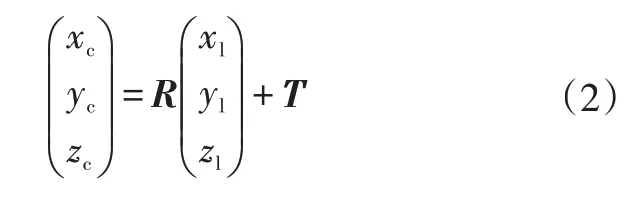
式中,R、T分别为2 个坐标系的相对旋转矩阵和转移矩阵。
在KITTI 数据集中,3D 点云b=(x,y,z)在校正过的相机中的投影位置a=(u,v)可以表示为:
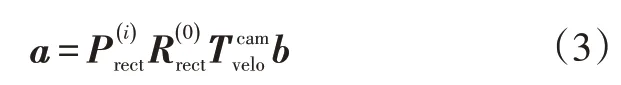
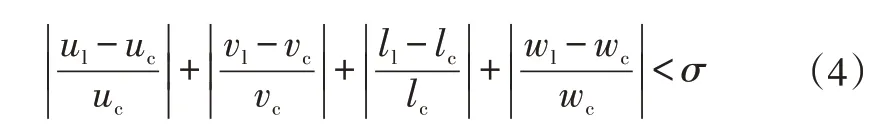
当式(4)成立时,认为该对边框信息匹配成功,激光雷达和相机识别到同一车辆目标,同时确定该车辆目标的尺寸和坐标信息,本文取σ=8%。完整的车辆目标信息如图7所示。

图6 障碍物点云投影结果

图7 完整的车辆目标信息
5 多车辆目标跟踪
5.1 数据关联
利用激光雷达和机器视觉信息融合方法,可确定车辆目标的边框左上角坐标、长、宽尺寸以及距离信息。将其依次作为状态参数[u v l w x y]′并采用等加速度运动模型在卡尔曼滤波器中对车辆目标的状态进行预测和更新。数据关联是多目标跟踪中关键的一步,其目的是将测量到的对象与已知的航迹进行匹配。JPDA算法是在杂波环境中对多目标跟踪进行数据关联的较好方法。假设在杂波环境中跟踪n个目标,目标的状态方程可以表示为:
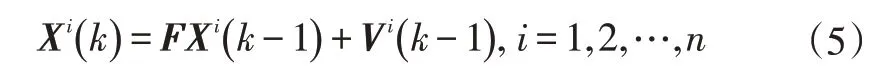
式中,Xi(k)、Vi(k)分别为k时刻目标i的状态向量和零均值高斯过程噪声向量,不同时刻的过程噪声相互独立;

目标的测量方程可以表示为:
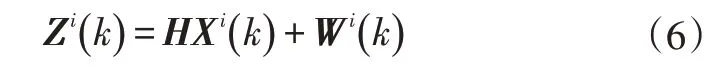
式中,Zi(k)、Wi(k)分别为k时刻目标i的测量向量和零均值高斯测量噪声向量,不同时刻的测量噪声相互独立;

JPDA 算法接收到状态向量和测量向量后,针对当前目标设置验证门,只对门内的有效量测进行数据关联,避免处理所有量测数据。验证门的范围为椭圆形:
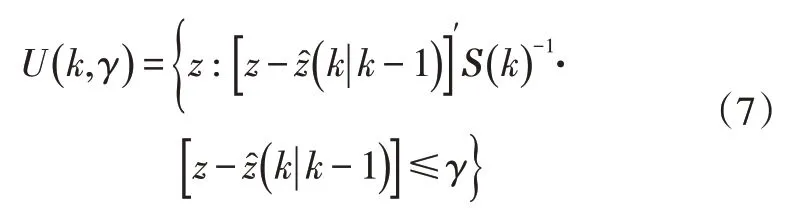
式中,z为目标测量值;为预测测量值;S(k)为预测测量的协方差矩阵;γ为门限值,本文取γ=0.97。
该验证门假设所有的有效量测都由目标或噪声产生,且每个目标最多产生1个有效量测。所有可能的联合关联事件A(k)都由验证门创建,可以表示为:
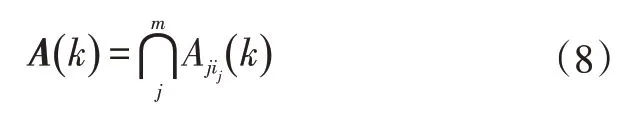
式中,Aji(k)为k时刻有效量测j来自于目标i的事件,j=1,2,…,m;m为有效量测的数量;ij为所考虑事件中与有效量测j关联的目标的索引。
基于所有量测Zk的联合关联事件A(k)的联合关联概率可以写成:
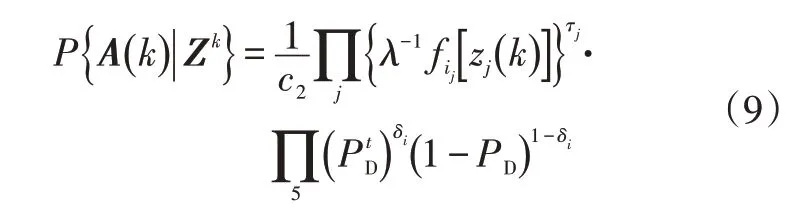
当量测进入某个目标的验证门内时,认为该量测为有效量测。有效量测j与目标i的关联概率为:
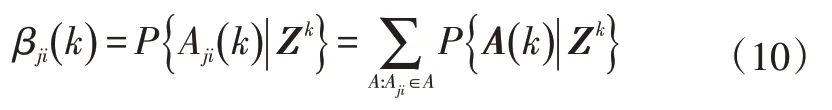
每个目标的状态更新矩阵为:
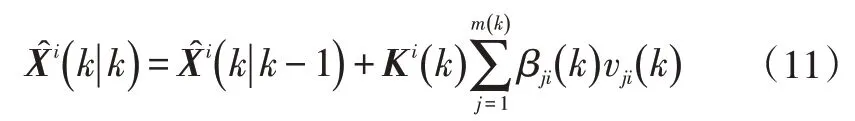
式中,Ki(k)=Pi(k|k-1)H(k)′Si(k)-1为卡尔曼增益;Pi(k|k-1)、Si(k)分别为目标i的协方差矩阵和残差协方差矩阵;vji(k)为有效量测j与目标i之间的残差。
多目标跟踪场景中,不断有车辆在道路场景中出现或消失,航迹进而也会发生变化,因此需要对航迹进行管理。多目标跟踪中主要有试探性航迹和确认航迹,航迹被确认前属于试探性航迹。在一次测量中,首先将量测信息与已有航迹进行关联,若没有相关性,则判断是否要开始新的试探性航迹。当航迹没有量测与之关联时,认为该目标从场景中消失,删除其航迹。
为了在跟踪过程中适应目标数量的变化,本文将数据关联过程中来源于噪声的量测定义为新的试探性航迹。同时采用了M/N测试方法[15],当一个试探性航迹在N次测量中出现至少M次时,将其确认为确认航迹,从而保证了新目标能够被及时发现,同时避免了噪声的干扰。本文中取N=4,M=3。
5.2 航迹管理
为了更加方便地管理航迹,本文设计了目标年龄模块,用于表示目标的跟踪时间。每当正确跟踪到同一车辆目标时,该目标的年龄增加1。当目标消失时,该目标年龄变为0,且不再显示其航迹。多目标跟踪的过程如图8所示。
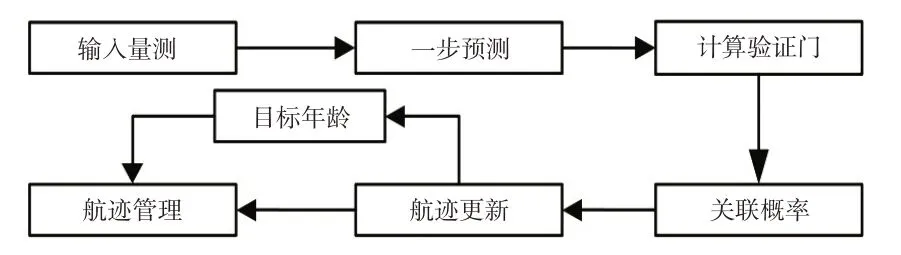
图8 多目标跟踪过程
6 仿真结果
本文分别在仿真场景和真实场景下对所设计的算法进行验证。在仿真场景下对3 个目标在不同时刻的运动状态进行模拟。其中场景1模拟了杂波环境中3个目标的直线运动,且运动过程中存在轨迹交叉。场景2模拟了杂波环境中2个目标的转向运动和1个目标的直线运动,在运动过程中同样存在轨迹交叉。真实场景采用KITTI数据集,同时对所提出的车辆目标识别方法进行验证。
6.1 仿真场景验证
本文首先对增加了M/N测试方法和目标年龄模块的JPDA 算法进行仿真验证。场景1和场景2中均假设目标1和目标2同时出现,目标3分别于5 s和7 s后出现,随后目标2消失,目标1和目标3继续运动。场景1中3个目标的跟踪过程、估计误差和年龄曲线如图9所示。
当一个试探性航迹在连续4次跟踪中出现至少3次时,就被确认为确认航迹,开始显示航迹并记录目标年龄。从图9c中可以看出:目标1和目标2的试探性航迹在第3 s 时被确认并开始跟踪其航迹和记录年龄值;第5 s开始出现的目标3的试探性航迹在第7 s时被确认并开始跟踪其航迹和记录年龄值;第10 s 时目标2 消失,其年龄值变为0 且不再记录其航迹。当目标出现或消失时,该算法能够及时对航迹进行管理,具有较强的鲁棒性。从图9a 和图9b 中可以看出,目标1~目标3 的最大位置估计误差分别为0.27%、0.35%和0.12%。在杂波环境中目标位置的估计误差非常小,基于JPDA 算法的多目标跟踪算法依然能够保持较高的跟踪精度。
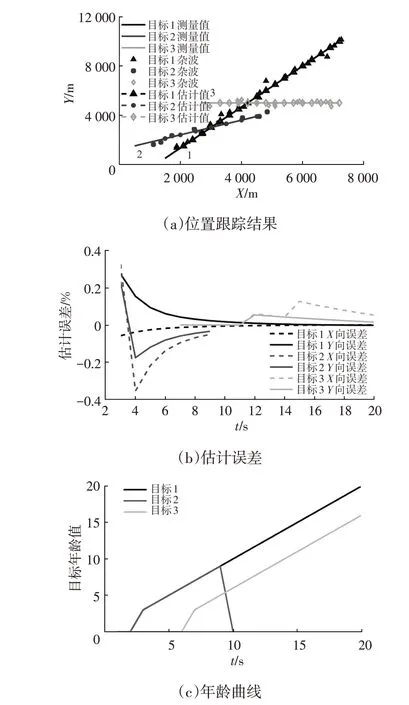
图9 仿真场景1验证结果
场景2 中3 个目标的跟踪过程、估计误差和年龄曲线如图10 所示。从图10c 中可以看出:目标1 和目标2的试探性航迹在第3 s时被确认,其年龄值开始增长;第7 s 开始出现的目标3 的试探性航迹在第9 s 时被确认,其年龄值开始增长;第17 s 时目标2 消失,其航迹被删除且年龄值变为0。当场景中目标数量发生变化时,该算法能够及时对航迹进行更新。从图10a和图10b中可以看出,目标1~目标3 的最大位置估计误差分别为7.8%、8.1%和3.2%。在周围环境中有杂波干扰、目标的运动过程出现交叉的情况下,基于JPDA 算法的多目标跟踪算法依然能够以较高的精度跟踪目标的运动过程。
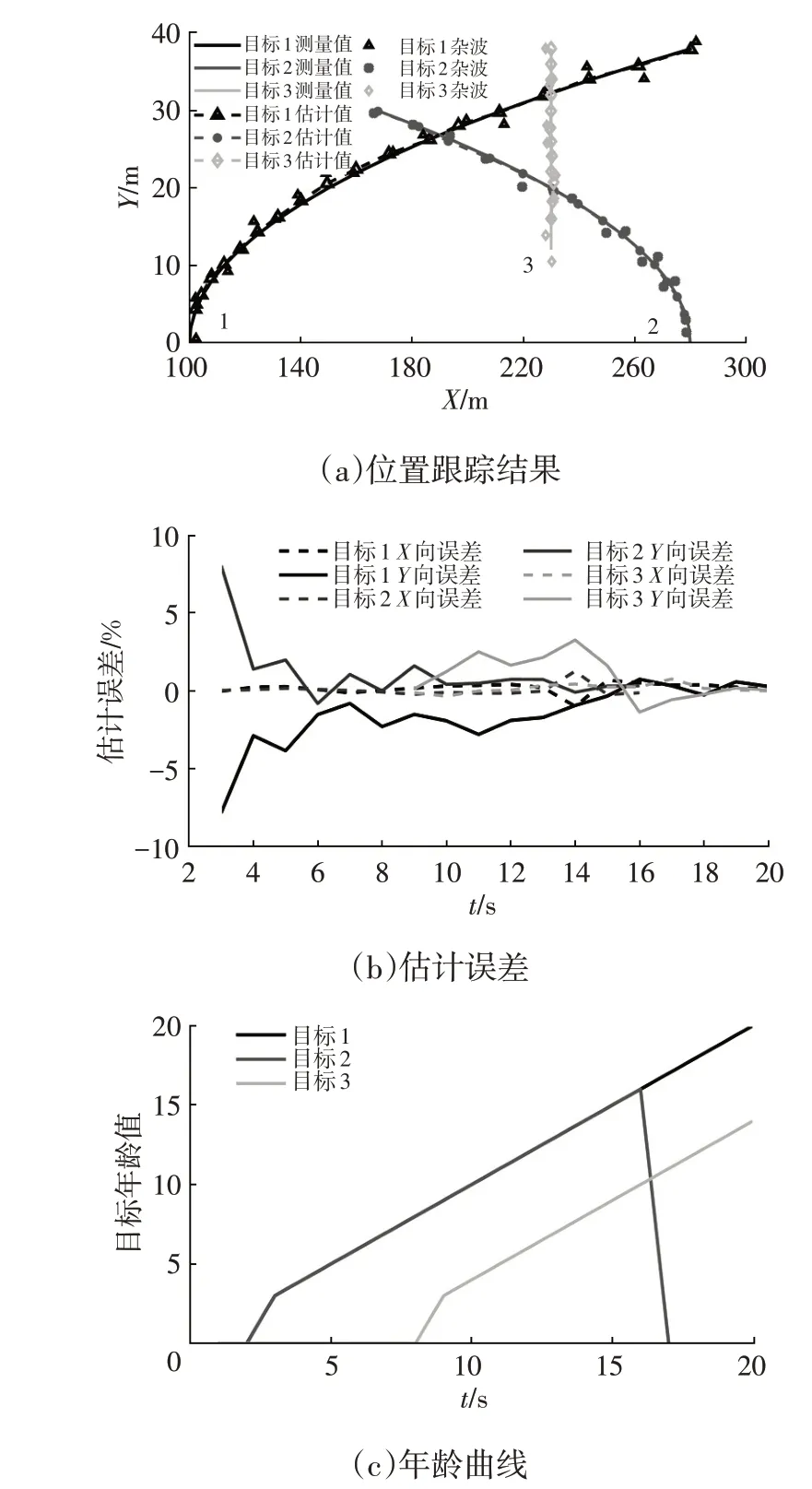
图10 仿真场景2验证结果
6.2 真实场景验证
本文利用真实场景下的KITTI 数据集对所提出的方法进行验证。以激光雷达为原点,规定自车纵向向前为x轴正方向,驾驶员横向向左为y轴正方向。根据《城市规划定额指标暂行规定》的有关要求,一般车道的宽度为3.5 m 或3.75 m。因此本文选择自车纵向向前60 m,左、右各10 m 的范围作为激光雷达和相机的检测范围。首先对激光雷达采集到的点云数据进行聚类处理,得到障碍物位置和坐标信息,同时对相机采集到的图像进行车辆目标的识别。然后利用2 种传感器的坐标标定关系融合车辆目标的信息。最后对检测到的车辆目标采用基于JPDA算法的多目标跟踪算法和目标年龄模块进行跟踪。数据集中一组数据的目标年龄曲线如图11所示。其中每一条增长的曲线都代表一个车辆目标被跟踪,年龄值超过40时仍用40表示。当目标车辆驶出识别范围时,其年龄值变为0并不再跟踪其航迹。
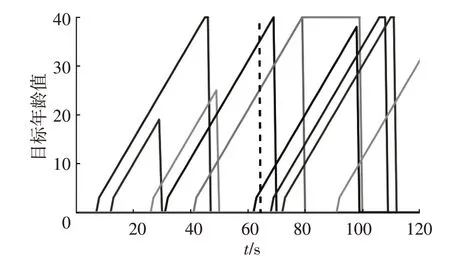
图11 目标年龄曲线
在仿真过程的第11、26、27、61、90和91帧中出现漏检现象,导致航迹滞后确认,在第46、79、108和111帧中出现漏检现象,导致航迹提前结束。车辆目标的识别和跟踪综合精度达到91.8%。图11 中第63 s 时刻车辆目标的识别和跟踪结果如图12所示。
以激光雷达测量的坐标为基准对场景中1 号车的纵向和横向估计距离进行误差分析。目标车辆的跟踪结果及其纵向和横向估计距离的误差分析如图13所示。

图12 第63 s时车辆目标的识别与跟踪结果
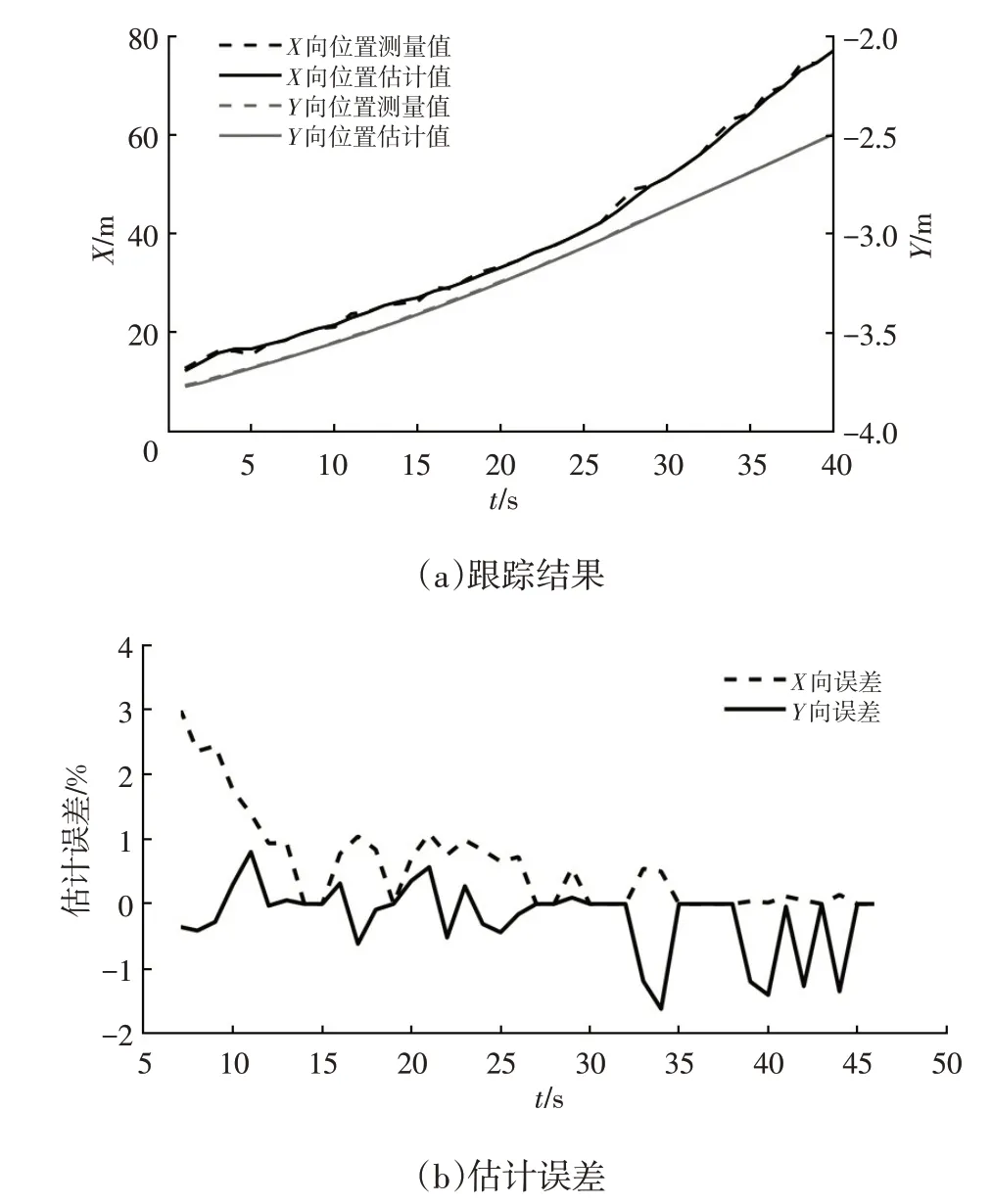
图13 1号车的跟踪结果和估计误差
从图13中可以看出:1号车在x方向上的最大估计误差为3%,在y方向上的最大估计误差为1.6%,该算法在真实场景中对车辆目标的识别和跟踪精度较高。当传感器出现误测导致数值跳动时,该算法依然能够精确地估计目标的运动,使之趋近于真实值。当场景中目标数量发生变化时,该算法也能够及时地更新当前目标数量和航迹,在真实场景下的鲁棒性较强。
7 结束语
本文设计了一种基于三维激光雷达和单目相机的信息融合框架。基于三维激光雷达的点云数据及单目相机的图像信息,快速准确地识别出道路车辆目标,并获得了车辆目标的尺寸、坐标等丰富的目标信息。基于JPDA 算法的多目标跟踪算法,可在杂波环境中对多车辆目标进行有效跟踪,且当场景中目标数目发生变化时,该算法能够及时更新航迹信息,具有较强的鲁棒性。本研究没有考虑自车两侧和后方的车辆目标的识别与跟踪,在下一步研究中将侧重于基于多激光雷达和多相机的传感器信息融合,得到更加丰富的全道路车辆目标信息。
猜你喜欢
航空学报(2022年9期)2022-10-14
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
农业工程学报(2022年4期)2022-04-24
计算机仿真(2021年2期)2021-11-17
汽车观察(2021年8期)2021-09-01
科技研究·理论版(2021年20期)2021-04-20
计算机与网络(2020年19期)2020-12-04
动漫界·幼教365(中班)(2020年3期)2020-04-20
创新作文(1-2年级)(2019年4期)2019-10-15
