
基于LSTM 神经网络的电商商品销售预测方法
2020-11-25 02:40:26柯苗黄华国
福建技术师范学院学报 2020年5期
柯苗, 黄华国
( 福建水利电力职业技术学院信息工程系, 福建永安 366000 )
在电子商务的飞速发展的今天, 智能手机以及电子支付也随之兴起, 人们消费购物习惯的改变, 在很大程度上影响了传统的供应链运行模式, 其维度主要体现在资金流, 信息流和产品流. 如何将三者有效结合, 需求预测起到了关键性作用, 而需求预测是大多数企业最难解决的应用性问题.
企业大量的线上营销数据在当前主流电商平台通过查询软件均可查看, 但大多数电商企业往往无法有效运用后台数据来辅助商业决策, 需求预测仍是许多企业面临的重大挑战. 电商零售的销量预测, 与天气、温度、雨量、股票等相似, 都是个时间序列的预测问题. 由于数据存在着季节性、动态性和周期性的特征,数据序列往往是非线性的, 使得用统计学时间序列模型的传统方法较难解决跨性能的多时间序列问题, 而机器学习的方法非常灵活, 可以通过预测商品的销量来辅助商业决策, 可建立各类特征模型解决问题, 但是这些工作需要特定领域的专业人员, 人工特征工程费时、费力,限制了这项技术的推广.
深度学习技术, 相对于传统技术而言, 可以自动将有效特征从大量的原始数据中抽取出来, 因此经过深度学习而建立的模型, 其使用性更强[1].LSTM 时间递归神经网络, 在预测和处理时间序列的间隔和延迟相对更长的重要事件具有合适性的特征, 最近几年, 此特征在许多的相关领域的应用中表现突出[2]. 文章在LSTM 网络的基础上, 探讨电商销售预测模型,建立有效简便的LSTM 网络模型. 实验中采用TensorFlow 框架下搭建LSTM 网络模型, 利用网店的历史数据, 进行分析预测, 将真实值和预测值进行对比.
1 LSTM 的结构和原理介绍
1.1 RNN( 循环神经网络)
长短期记忆神经网络也称为循环神经网络[3].RNN 在用于时间序列预测中使用频率高, 是一种预测和处理系列数据的专用神经网络[4].RNN神经网络结构及展开, 如图1 所示, 表示了一个循环的神经元, 在图中, 右侧展开图是按照时间的先后顺序将循环神经网络的计算图展开, 其中Xt所代表的是t 时刻的输入,St所代表的是t 时刻的记忆, 而Ot所代表的是t 时刻的输出, 由此可得出, 当下时刻的输出Ot取决于St-1的记忆时刻和当下时刻的输入Xt, 可将此序列数据依次导入循环神经网络RNN 的输入层, 由此可见,RNN 最擅长的是解决与时间有关联的问题. 但是辅助RNN 决策的主要还是最后输入的信号( 即对最后输入的信号记忆最深), 找之前的信号会随着时间的推迟而变得强度越来越弱, 辅助的作用越来越低. LSTM就是为了解决记忆的距离太短这个问题而产生的.

图1 RNN 神经网络结构及展开
1.2 LSTM( 长短期记忆神经网络)
与传统的循环神经网络相比,LSTM 对内部的结构进行了更加精心的设计, 加入了输入门、遗忘门以及输出门三个门和一个内部记忆单元, 具体结构如图2 所示, 结构图中Xt表示t 时刻神经细胞的输入,ht表示t 时刻神经细胞的状态值. 图中三个大框表示细胞在不同时序的状态, 将t 时刻神经细胞单独放大绘制出来的大图如图3 所示. 在图中, 细胞中带有符号 “δ” 小框代表激活函数为sigmoid 的神经网络层, 依次组成遗忘门, 然后是输入门和输出门, 带有符号 “tanh” 小框代表激活函数为tanh 的前馈网络层.
1.3 LSTM 结构及功能实现
从图3 可知,LSTM 当Xt和上一状态传递下来的ht-1进行向量拼接乘以权重矩阵得到四个状态函数和输出分别如下:

其中, it, ft,ot通过前面的sigmoid 激活函数转换成0 到1 之间的数值, 而构成门控单元,而 gt则是将结果通过tanh 激活函数转换成-1到1 之间的数值作t 时刻输入细胞的候选状态值.
1.3.1 忘记功能
主要完成对上一个节点输入ct-1状态值进行选择性的忘记. 具体是用公式2 计算得出的结果ft作为忘记门控, 用来控制上一个状态ct-1哪些需要忘记.

图2 LSTM 神经网络

图3 放大的神经网络单元
1.3.2 选择记忆功能
针对输入的Xt做选择性的记忆, 而当下输入的具体内容, 是由公式4 计算得出的结果g t来表示。而所要选择的门控信号则是由公式1计算得出的it控制.
将上面两部分得到的结果相加就是公式5,得到传输给下一个状态的ct.
1.3.3 输出功能
LSTM 输出当前的状态ht. 主要是通过ot和tanh 激活函数对ct进行缩放控制, 使其具有长时期的记忆功能.
2 LSTM 网络模型的搭建
2015 年11 月,Google 将TensorFlow 在GitHub 上开源, 是Google 用于数据流图的数值计算开源软件库, 其已经成功地实现了深度学习算法, 实现异构分布式系统上大规模高效率的学习[5].
Keras 是在TensorFlow 基础之上封装的API, 这些API 以模块的形式封装了TensorFlow的诸多小的组件, 可以大大降低了编程难度. 用户可以方便地将API 构建的模块按需求进行排列就可以设计出各种神经网络, 方便理解和使用, 节省搭建新网络的时间.Keras 以模型为其核心技术, 一共拥有两种模型, 包括函数式模型和序贯模型, 其中函数式模型在各种实验中应用较为广泛, 而序贯模型则是相对于函数式模型的一种特殊情况[6]. 本实验, 通过采用函数式模型, 结合多层次LSTM 网络模型的搭建,分别对同一商品不同的SKU 进行预测性分析,最后采用均方根误差(RMSE) 对模型的预测性能评价指标的实验结果进行比较及修正.
3 实验及其结果分析
文章选取实验对象的订单数据来源于某箱包公司的电商销售数据, 选择箱包销售数据的原因在于箱包不受季节等因素影响, 相对来说SKU 种类比较稳定, 不会出现频繁变化的现象,收集来的数据方便进行训练及验证.
该公司成立于2009 年, 是集设计、开发、生产和销售为一体的专业化时尚休闲自创品牌的生产商和销售商, 共有200 多种产品类目, SKU 数量达到500 多个. 近年来, 公司的经营状况在箱包行业排名中呈上升趋势, 面对越来越多的销量和较多的SKU 数量, 是否可以准确地预测网络销量成为网络销售中的重要环节,特别对于备战 “双十一” 等电商活动起到了关键的作用. 而公司内销售量大的SKU, 其历史销售数据相对完善, 如果能通过这些完善的数据, 对SKU 今后的销量做一个较为准确的预测,这将给公司今后的运作和发展提供非常大的帮助[7]. 因此, 文章的实验对象选取了此公司在天猫商城中销量排行靠前的一款潮牌双肩包的SKU, 数据集为生意参谋提取的近两年原始日志数据( 共 500 条), 每条数据包括商品的销量SALE( 此双肩包的日销售数量)、价格PAY( 此双肩包的当日销售价格)、浏览次数PV( 进入此双肩包销售页面的日访问量或点击量, 用户多次打开或刷新, 该指标值累加)、浏览人数UV( 进入此双肩包销售页面的独立访客, 同一访客进入该指标值会进行去重计算)、展现量( 当用户搜索相关关键词时, 此双肩包展示的次数) 等诸指标数据与实际销量进行相关分析. 两年的原始日志数据共500 条, 笔者取其中的400 条, 作为LSTM 时间递归神经网络模型的训练样本, 剩下的100 条则用于测试训练结果, 检验神经网络模型的准确性.
实验训练流程按照下载数据、数据预处理、数据特征提取、数据归一化、模型的训练、微调参数、预测销售量等几步完成[8], 如图4 所示.
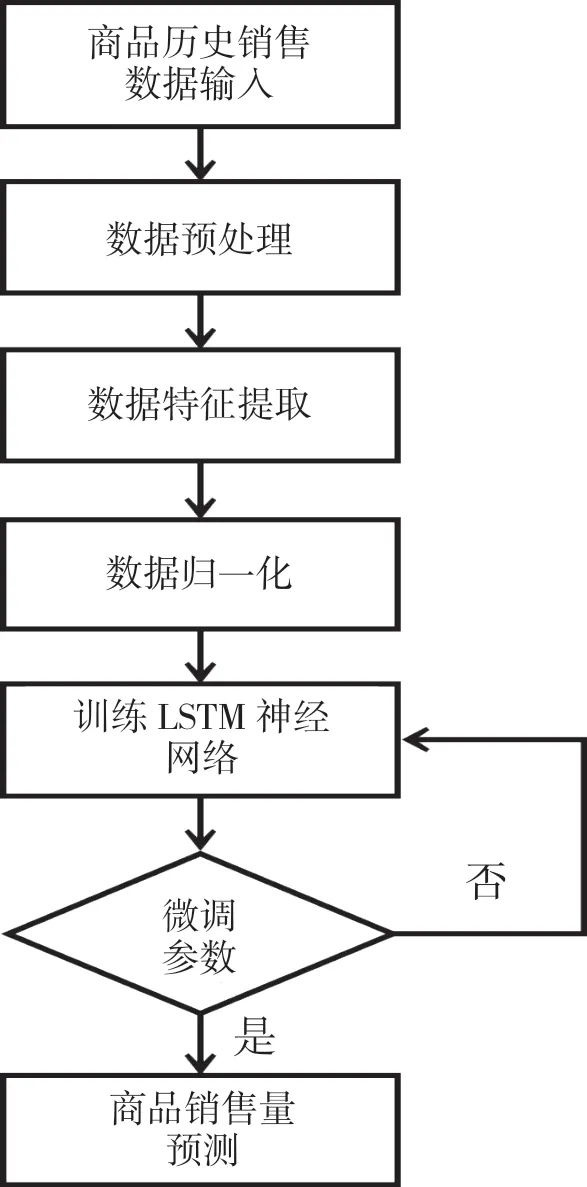
图4 实验流程图
3.1 数据输入
将商品销售数据转换为CSV 文件, 文件的第一列为时间点, 在同一个时间点上还有商品的销量(SALE)、价格(PAY)、浏览次数(PV)、浏览人数(UV)、展现量等5 个数据. 使用TFTS读入CSV 文件的代码为图5 所示.
3.2 数据预处理
数据预处理是为了降低噪音数据对选取的400 条训练数据的影响, 将选取的训练数据中的乱码和空值进行清洗并处理, 处理后的输入数据, 需要符合监督学习数据的要求[9].

图5 使用TFTSD 读入CSV 文件
3.3 数据特征提取
影响商品销量有多个特征要素, 在决策时往往要了解每个特征要素对结果的影响程度,因此需要对特征进行评判. 特征评判方法有很多, 在本试验中, 因变量是数值型区间变量,它期望值与多个自变量之间具有线性关系, 所以特征提取的数学模型选用线性回归算法, 多元线性回归算法公式如公式7 所示:

公式7 中x1x5是影响商品销量的特征数据, 也就是提取的商品销量SALE、价格PAY、浏览次数PV、浏览人数UV和展现量这5个数据,而通过算法的模型训练所得出的a1...a5,c 为模型系数, 其中c 为随机的误差项.
3 .4 数据归一化
其主要目标是减少量纲给计算
带来的影响, 对数据进行处理, 将其值限定在[0,1] 之间, 这样可以加快算法的收敛速度. 归一化的具体计算方法, 如公式8 所示,公式中的MaxValue 和MinValue 分别是对应对每一字段数据的最大值和最小值, x 是字段数据具体数值, y 则是数据归一化的最终结果[10].

在本实验中, 由于Relu 作为实验中的激活函数, 所以在Pandas 中使用MinMaxScaler 函数时, 首先要将数据集转换到[-1,1] 之间, 才能进行实验.
3.5 LSTM 模型
模型定义代码如图6 所示,num_feartures=6表示每个时间点上观察值是一个5 维的向量,num_units=128 表示使用隐藏层为128 大小的LSTM 模型.
3.6 图表展示预测结果

图6 LSTM 模型
最后使用Matplotlib 的pyplot 模块完成结果的可视化任务, 最后运行结果如图7 所示. 图中前400 步是训练数据,400 步之后为预测值. 由图可见LSTM 模型在训练前50 步的训练过程中模型的拟合值与实际的原始数据还有较大的差距, 经过100 步的训练这两值已经非常相似, 此实验结果说明LSTM 神经网络模型在提取问题的主要特征上相对准确, 能高效地进行整体训练, 具备有效的训练方法. 从实验结果中还可以看出, 在训练计算中, 局部数据未影响到其预测值, 并未产生梯度消失的现象,在200 步的训练后, 模型的拟合值与原始数据已经基本相同, 此现象说明模型的拟合度比较好, 这样400 步之后的预测数据就相对更准确,证明这个多层的 LSTM 网络模型技术复杂程度小且预测性能高效准确.
3.7 与自回归模型(AR) 模型表现对比
自回归模型, 也简称AR 模型, 在统计学上是一种作为时间序列模型处理的基本方法,AR 模型是采用一定的数学模型来对一个随机序列进行相似性描述, 这个随机序列是预测的对象通过时间的推移, 而逐渐形成的数据序列[11]. 这个模型被系统识别后, 便可通过时间序列所包含的过去数值和现在数值, 去预测未来的数值.AR 模型是如今最常见具有平稳性的时间序列模型之一[12]. TensorFlow1.3 版本引入了一个Time Series 模块(TensorFlow Time Series,TFTS) . TFTS 提供了一套基础的时间序列模型API. 提供包含AR、LSTM 在内的多种预测模型.
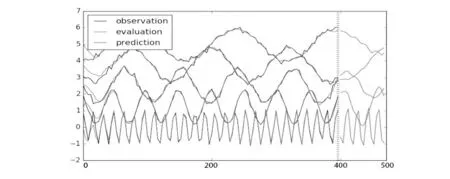
图7 LSTM 预测销售数据

图8 使用AR 模型预测销量值
使用TensorFlow 的TFTS 提供的AR 模型对数据进行训练, 再经过验证最后预测出将来的数据, 实验中, 整个训练的长度选取了500 个数据序列, 在输入 “初始观测序列” 时, 实验使用前30 个数据序列, 通过这一动作计算出之后10 步的数值. 接着, 实验会再取30 个数值, 其中包括上一个步骤中预测计算出来的10 个数值, 得到新的预测值, 这个新的预测值又会成为下一个步骤的输入数据, 以此类推, 实验中最后预测了100个时间点. 实验结果如图8 所示. 图中观察到的值、模型拟合值及预测值分别用蓝、绿及红色标识, 从图中可以看出, 前400 步模型原始观测值的曲线和模型拟合值非常接近, 说明模型拟合得比较好,400 步之后的预测也合情合理, 但是AR模型不适用非稳定时间序列, 模型输出数据的光滑程度不高, 尤其是无法在同一时间处理多个时间序列. 相比LSTM 神经网络模型优点在于可支持大量的原始数据输入, 自动抽取数据的有效特征, 且一个模型适用于多个时间序列.
所以LSTM 神经网络模型与AR 模型相比在输入数据的组织形式、网络的结构、训练方法的效率及有效性和预测的准确性等方面相比都具有更大的优越性.
4 结论
对于电商企业来说, 需求预测是大多数企业日常经营时最普遍和重要的应用问题, 文章探讨了深度学习技术在时间序列预测理论依据, 将商品销量预测归纳为多变量时间序列的预测问题,使用某电商网店的历史销售数据, 详细介绍了在TensorFlow 框架下搭建LSTM 网络模型的方法, 模型运算得到的销量预测结果准确直观. 文中还与使用AR 模型这种常用的时间序列预测模型的运算结果进行比较, 得到LSTM 网络模型具有数据输入简单方便, 在网络的结构、训练方法的效率和有效性以及预测的准确性等方面都具有更大的优越性.
文章所建立的基于LSTM 神经网络的电商商品销售预测模型, 数据输入简便, 模型技术简单,具有比其他预测模型更高的精度. 通过神经网络深度学习的方法可分析挖掘商品特征属性之间的关联系数, 还能直观地展示商品的销量与其关键信息影响程度, 研究结果对企业改善营销决策和合理的库存管理具有重要的指导意义.
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
当代水产(2021年7期)2021-11-04 08:17:32
电子制作(2019年19期)2019-11-23 08:42:00
汽车观察(2019年2期)2019-03-15 06:00:12
现代企业文化(2018年13期)2018-06-09 08:22:23
重型机械(2016年1期)2016-03-01 03:42:04
家用汽车(2016年4期)2016-02-28 02:23:37
大连工业大学学报(2015年4期)2015-12-11 04:06:52
机电信息(2015年28期)2015-02-27 15:57:42
海军航空大学学报(2015年4期)2015-02-27 13:45:47
