
极限梯度提升和长短期记忆网络相融合的土壤温度预测
2020-11-24 01:43李清亮蔡凯旋耿庆田刘光洁孙明玉于繁华
光学精密工程 2020年10期
李清亮,蔡凯旋,耿庆田,刘光洁,孙明玉,张 嵛,于繁华
(长春师范大学 计算机科学技术学院,吉林 长春 130032)
1 引 言
土壤温度作为大气和陆地表面水热循环共同作用的结果,是地球科学多个领域的重要变量,如气象学[1-2],农业[3-4]和环境科学[5]等。目前土壤温度的测量过程过于复杂[6-7],无法在大部分区域提供监测点。因此,准确地土壤温度预测具有显著应用价值。然而土壤温度的时空变化受多种环境因素影响[8],给土壤温度的准确预测带来巨大挑战,同时也使其成为具有深远意义的科学问题。目前基于机器学习的数据驱动经验模型是土壤温度预测一个重要的研究领域[2]。
近年来,随着机器学习技术迅速发展,已在多种领域成功应用[9-11]。其中基于机器学习的数据驱动模型在土壤温度预测中也取得了一定成果,最常见的有:人工智能神经网络(Artificial Neural Network, ANN)[12-14]、支持向量回归(Support Vector Regression, SVR)[15-16]、极限学习机(Extreme Learning Machine, ELM)[1-2]。ANN由于可以模拟人脑组织结构进行推理的特点,已被广泛应用于多种预测领域。在土壤温度预测中,Mihalakakou等人[12]基于ANN模型取得了较好的预测性能。Kisi等人[13]指出土壤浅层预测时径向基神经网络(Radial Basis Neural Network, RBNN)相比广义回归神经网络(Generalized Regression Neural Network, GRNN)、多层感知机(Multilayer Perceptron, MLP)和线性回归(Linear Regression, LR)预测模型展示了更优的预测性能。支持向量回归(SVR)预测模型是由支持向量分类器(Support Vector Machines, SVM)发展而来,在土壤温度预测中发挥了重要作用。Delbari等人[16]在伊朗地区的测试中,证明了SVR预测模型可以成功应用在土壤温度的预测。Feng等人[1]在中国陕西省的测试中,通过比较GRNN、反向传播神经网络(Back Propagation Neural Network, BPNN)、随机森林(Random Forests, RF) 和ELM的预测模型,发现ELM预测模型的预测能力最高。
然而,在前人研究主要基于ANN,SVR和ELM等方法实现土壤温度预测。缺少其他机器学习算法如极限梯度提升(XGBoost)和长短期记忆网络(Long Short-Term Memory, LSTM)等研究。XGBoost是基于梯度下降方法,将多个弱分类器融合成一种强分类器,这种加强学习能力的模式,使XGBoost在多种领域的预测研究得到广泛应用[17-19]。同时,具有记忆细胞的LSTM模型既可以学习其短期行为,也可以学习其长期行为。这种模式使LSTM在模拟自然系统时非常有用[20-22]。同时土壤温度的影响因素很多,如太阳辐射、大气温度等,同时基于机器学习针对影响因素重要性的量化评价并结合预测模型的方式并未展开研究。事实上预测模型中不同影响因素的组合对预测能力有很大影响。
本文将在中国长白山和海北区域进行测试,首先基于XGBoost计算土壤温度预测中每个影响因素的重要性,然后将影响因素依据重要性大小依次进行组合并作为预测模型的输入,其中本文尝试基于LSTM作为预测模型。最后根据不同组合的预测性能选择最优的影响因素。
2 数据与方法
2.1 研究区域概况
本文在中国东北部吉林省长白山地区(41°41′N,127°42′E至42°51′N,128°16′E)和中国西北部青海省海北地区(31°36′N,86°35′E至39°19′N,103°104′E)进行了测试。 在FLUXNET(https://FLUXNET.fluxdata.org/)上下载了半小时尺度的三年数据(2003年1月1日至2005年12月31日),其影响因素分别为大气温度、相对湿度、太阳辐射、蒸汽压、风速、降水量和风速,其中土壤温度是在土壤深度为5 cm时观测得到。长白山和海北都是我国重要的生态自然保护区。长白山地区以是种植业为主的农业地域类型,发展商品谷物农业,主要种植大豆、玉米、冬小麦及谷子(小米)等。海北属高原大陆性气候,太阳辐射强度大,日照时间长,日夜温差大,有利于油菜、青稞、马铃薯及蔬菜等种植业的发展。并且土壤温度对这些资源的生长有很大影响,因此,土壤温度预测对这些生态资源的保护和管理具有重要意义。
2.2 土壤温度预测框架
本研究主要考虑两个问题:(1)对于土壤温度预测时,不同影响因素起到不同作用,这些影响因素或其组合与土壤温度间的关系如何?(2)土壤温度预测是一种时间序列预测问题,哪一种机器学习算法最符合土壤温度时间序列的机制?为了解决上述问题,本文提出XGBoost-LSTM融合模型, 如图1所示。对于多个气象数据来说,不同因素与土壤温度之间的相关性不同。首先基于XGBoost对各个影响因素进行排序。对排序后的影响因素,本文按其重要性依次进行组合作为LSTM模型的输入,找到效果最佳的输入组合,进而基于LSTM模型挖掘土壤温度与其影响因素间的关联,并实现预测。
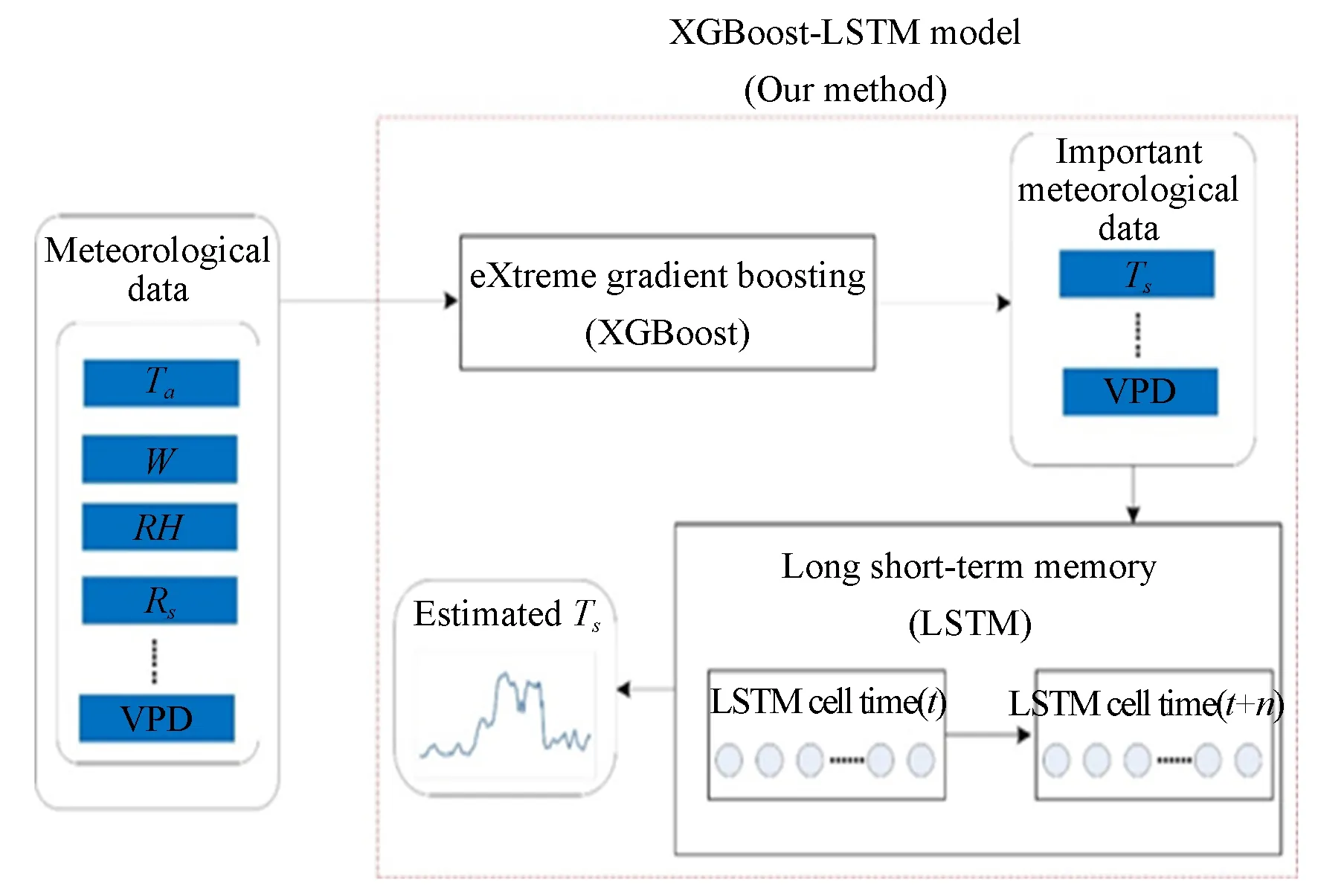
图1 XGBoost-LSTM模型的土壤温度预测流程图Fig.1 Framework of XGBoost-LSTM
2.3 XGBoost模型
XGBoost是一种新的梯度提升机器Boosting算法。Boosting分类器作为集成学习模型,具有将弱分类器转化为强分类器的能力。其核心是将多个准确率较低的决策树模型组合成一个准确率较高的模型,通过不断迭代生成决策树,拟合残差优化目标函数,从而优化预测效果。当XGBoost 模型完成训练,本文针对影响因素在该模型的贡献程度计算其重要性。具体方法如下:先计算特征j在单棵树中的重要程度,即找到与特征j有关的结点,计算该结点分裂前后的平方损失值,损失值越大说明该特征越重要。单个树中特征j的计算方法如下:
(1)
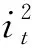
(2)
通过式(1)和式(2)量化每个特征的重要程度后,即可实现特征排序。
2.4 LSTM模型
LSTM是一种重要的递归神经网络模型,具有记忆细胞的LSTM既可以学习土壤温度与其环境因子之间的短期行为,也可以学习其长期行为。
图2说明了LSTM的结构,其工作流程如下式所述:
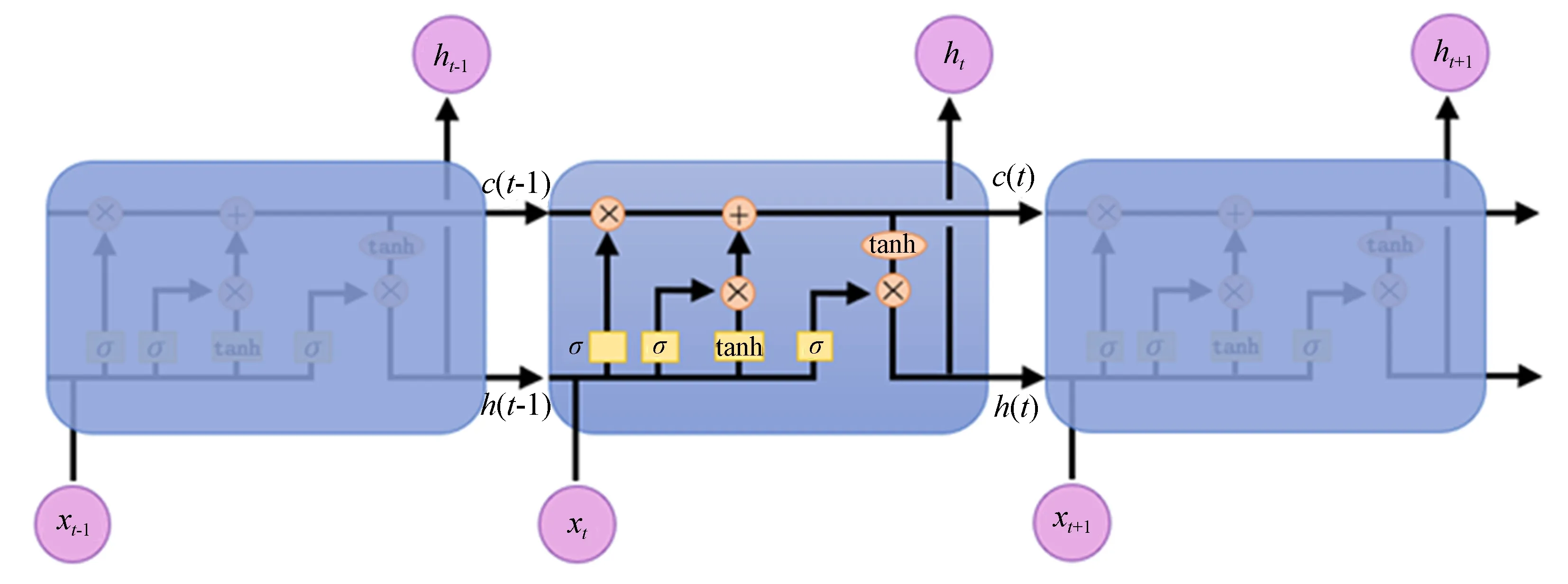
图2 LSTM流程图Fig.2 Structure of LSTM
i(t)=σ(Wihh(t-1)+
Wixx(t)+Wicc(t-1)+bi),
(3)
f(t)=σ(Wfhh(t-1)+
Wfxx(t)+Wfcc(t-1)+bf),
(4)
c(t)=f(t)⊗c(t-1)+
i(t)⊗tanh(Wchh(t-1)+Wcxx(t)+bc,
(5)
o(t)=σ(Wohh(t-1)+
Woxx(t)+Wocc(t)+bo),
(6)
h(t)=o(t)⊗tanh(c(t)),
(7)
(8)
2.5 实验设置
本文在Intel Core(TM)i7-5820K,3.30 GHz CPU和64 Gb内存的服务器上进行实验。在Pycharm 2018.2.8,tensorflow作为工具实现所有预测模型。整个数据集的前四分之三部分(长白山和海北区域,2003年1月1日 00:00至2005年12月31日23:30阶段的数据,共计52 608个)用于训练(2003年1月1日00:00至2005年4月1日12:30阶段的数据,共计39 456个),其余四分之一部分用于测试(2005年4月1日12:30至2005年12月31日23:30阶段的数据,总共13 152个)。为了验证本文方法的有效性,通过与五种数据驱动预测模型(LR,SVR,XGBoost,BPNN,ELM)作对比,并采用不同的统计评价标准评估模型性能,如均方根误差(RMSE)、平均绝对误差(MAE)、纳什效率系数(NS)、LMI系数和威尔莫特一致性指数(WI),定义如下:
(9)
(10)
(11)
(12)
(13)
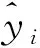
3 分析与讨论
本章节主要对比了LR, SVR, XGBoost, BPNN, ELM 5种预测模型,并基于scikit-learn工具实现所有方法。XGBoost预测模型模型中,通过scikit-learn工具中提供的selection.GridSearchCV函数调整参数,并优化XGBoost模型。其以CART回归树作为XGBoost模型模型的二叉树进行构建、学习率为0.005,叶子上的最小样本数为1,树的个数为800,最大深度为5。BPNN预测模型模型中,定义三层结构(输入层、隐藏层、输出层),以平方误差作为损失函数,采用Adam进行优化,批处理数据量为200,迭代次数为300,学习率为1×10-5。ELM预测模型模型中,利用hpelm工具提供的elm函数对ELM进行建模,初始化三层神经元网络(输入层、隐藏层、输出层),定义隐藏层的sigmoid激活函数,设置节点数为128。通过实验对比,发现上述设置预测结果最好。
3.1 XGBoost-LSTM模型中LSTM结构超参数的测试
本文方法中,影响预测性能的主要超参数有:LSTM神经单元个数、批量数据大小、迭代次数、学习率、影响因素的选取。因此,下面本文将通过预测性能定义最优的超参数。本文方法中,影响预测性能的主要超参数有:LSTM神经单元个数、批量数据大小、迭代次数、学习率、影响因素的选取。
在测试LSTM神经单元个数时,首先定义迭代次数为200次,批量数据大小为200次,学习率为1×10-4,选取大气温度、相对湿度和蒸气压。在(30,50,100和150)中分别测试LSTM神经单元个数;同时选择最优的LSTM神经单元个数后,再从(50,100,150,250,300,350,400,450,500)中选择批量数据大小;其次从(100,200,300,400,500,600,800,1 000,1 100,1 200)中选择迭代次数;再从(1×10-3, 1×10-4, 1×10-5)中选择学习率。最后等上述参数均选取最优之后,本文LSTM预测模型的最优结构随之确定。进而针对影响因素的选取进行测试,首先基于XGBoost算法计算所有影响因素(大气温度、相对湿度、太阳辐射、蒸汽压、风速、降水量和风速)的特征重要性,并依据重要程度从高到低进行组合,依次输入LSTM预测模型中,并测试哪些组合对土壤温度的预测更有帮助。其中LSTM预测模型输入特征中的输入维度(input_size)为影响因素的个数;历史数据序列的长度(time_step)定义为7。本文首先以长白山区域进行实验,不同LSTM神经单元个数(LSTM_size)、批量数据大小(batch_size)、迭代次数(train_epoch)和学习率(e)的预测结果分别如表1~表5所示(表中加粗数值为最优结果)。从表1可知,参数取值不同,预测模型的预测能力也不一样。首先LSTM神经单元个数过多,预测模型将过拟合,降低预测模型学习气象数据的泛化能力,同时个数太少,预测模型将遗失重要信息并无法有效挖掘土壤温度与其影响因素间的关联,因此LSTM_size=50时,预测性能最好(RMSE=2.413,MAE=1.893,NS=0.921,WI=0.980,LMI=0.740);从表2可知,若迭代次数太小,预测模型无法收敛于最优值,而迭代次数太大,将明显出现过拟合现象,预测性能将不会提升, 因此train_epoch=1 100时,预测性能最好(RMSE=2.234,MAE=1.756,NS=0.932,WI=0.983,LMI=0.759);同理,从表3可知批量数据主要控制着训练过程一次处理样本的信息,过小将导致预测模型难于收敛,过大将导致预测模型性能无法达到最优, 因此batch_size=400时,预测性能最好(RMSE=2.392,MAE=1.875,NS=0.922,WI=0.981,LMI=0.743);最后从表4可知学习率是控制训练过程中每一次逼近最优值的步长,过小容易选入局部最优,而过大将无法逼近最优值并在最优值附近不断徘徊。因此当LSTM_size=50,batch_size=400,train_epoch=1 100,e=1×10-4时性能最佳,进而通过确定上述参数,本文得到了最优的LSTM预测模型结构。
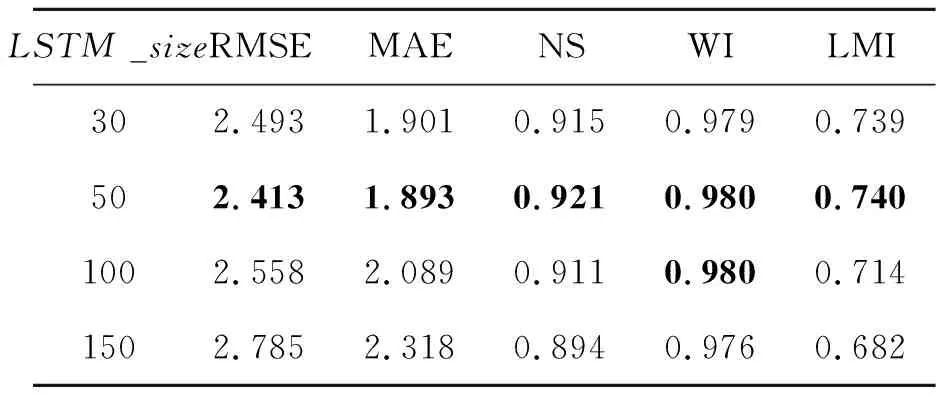
表1 不同LSTM神经单元个数在长白山气象站的预测结果
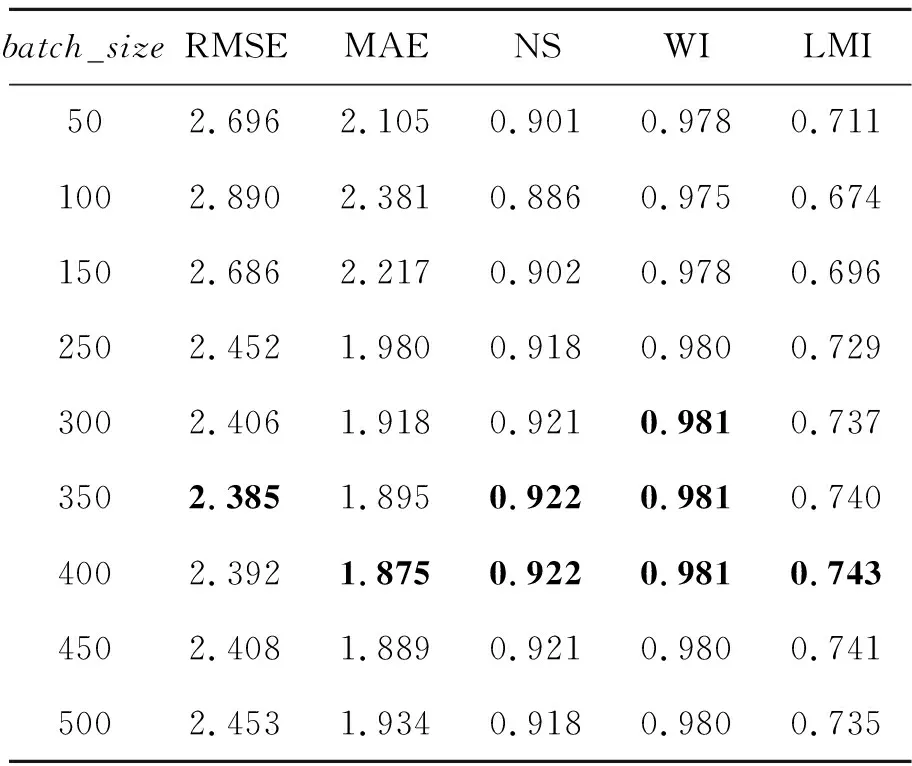
表2 不同批量数据大小在长白山气象站的预测结果
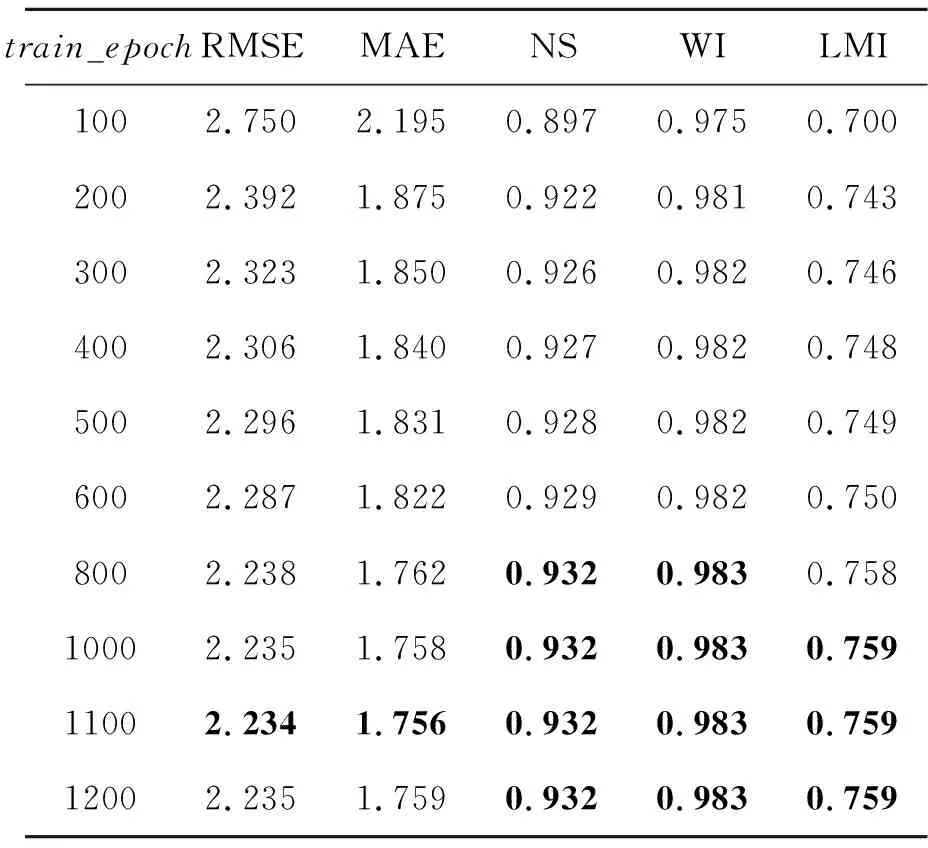
表3 不同迭代次数在长白山气象站的预测结果
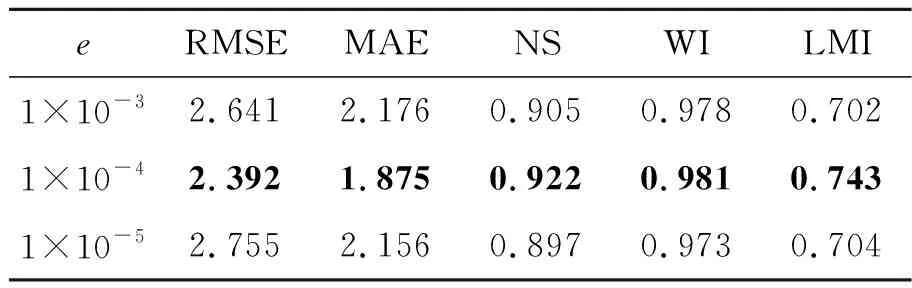
表4 不同学习率在长白山气象站的预测结果
3.2 XGBoost-LSTM选取影响因素
得到最优LSTM预测模型结构后,然后分析影响因素的组合对预测能力的影响,XGBoost-LSTM预测模型的整体的数据处理流程如图3所示。首先根据2.3节XGBoost部分计算所有影响因素的重要性,如图4所示。同时在XGBoost模型计算影响因素重要性的过程中,分别对XGBoost模型训练中学习率、树的个数为800和树的最大深度所对应的平方损失减少值进行分析,以选取最优参数,对比结果如表5所示。 当学习率为0.005,树的个数为800,最大深度为5时,平方损失减少值最优(-0.078 481)。
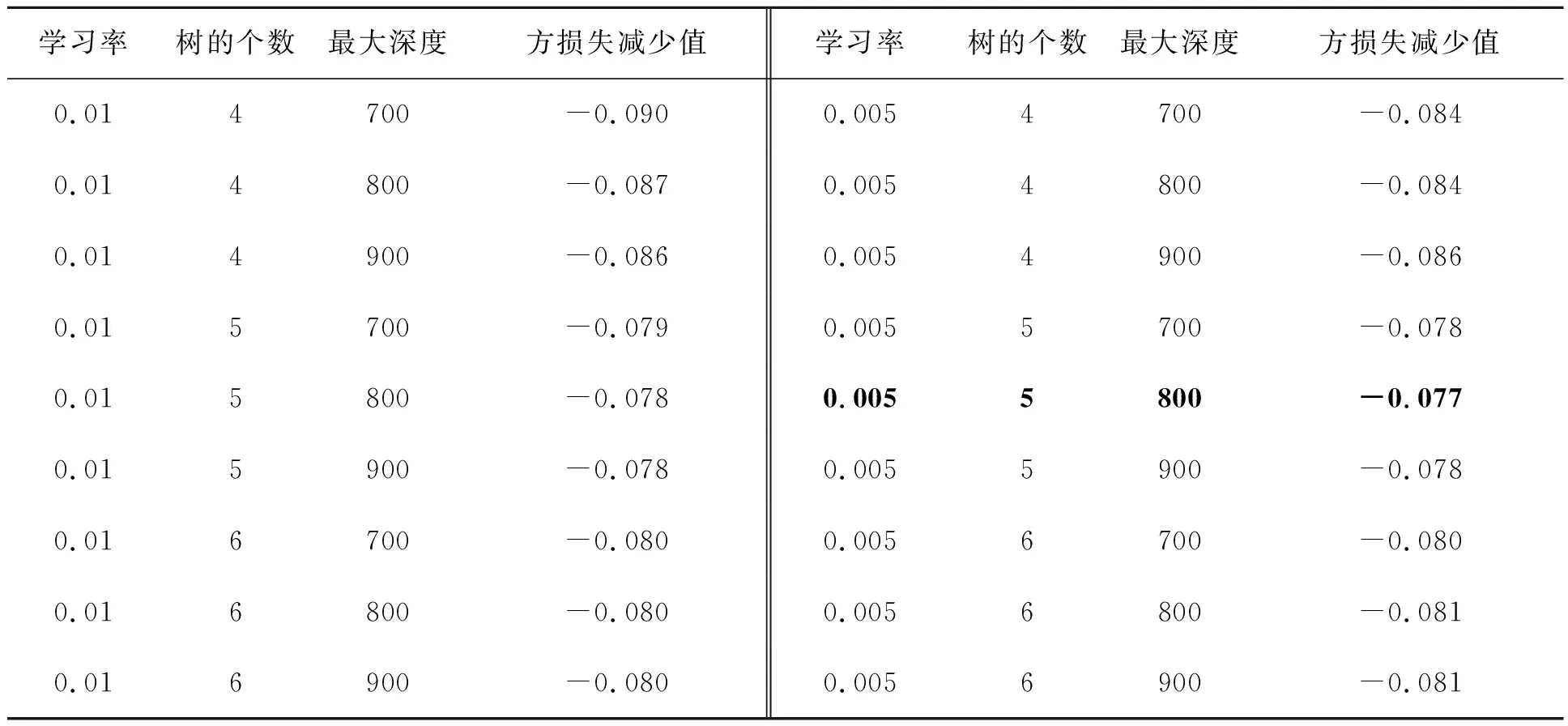
表5 不同参数的XGBoost模型性能对比
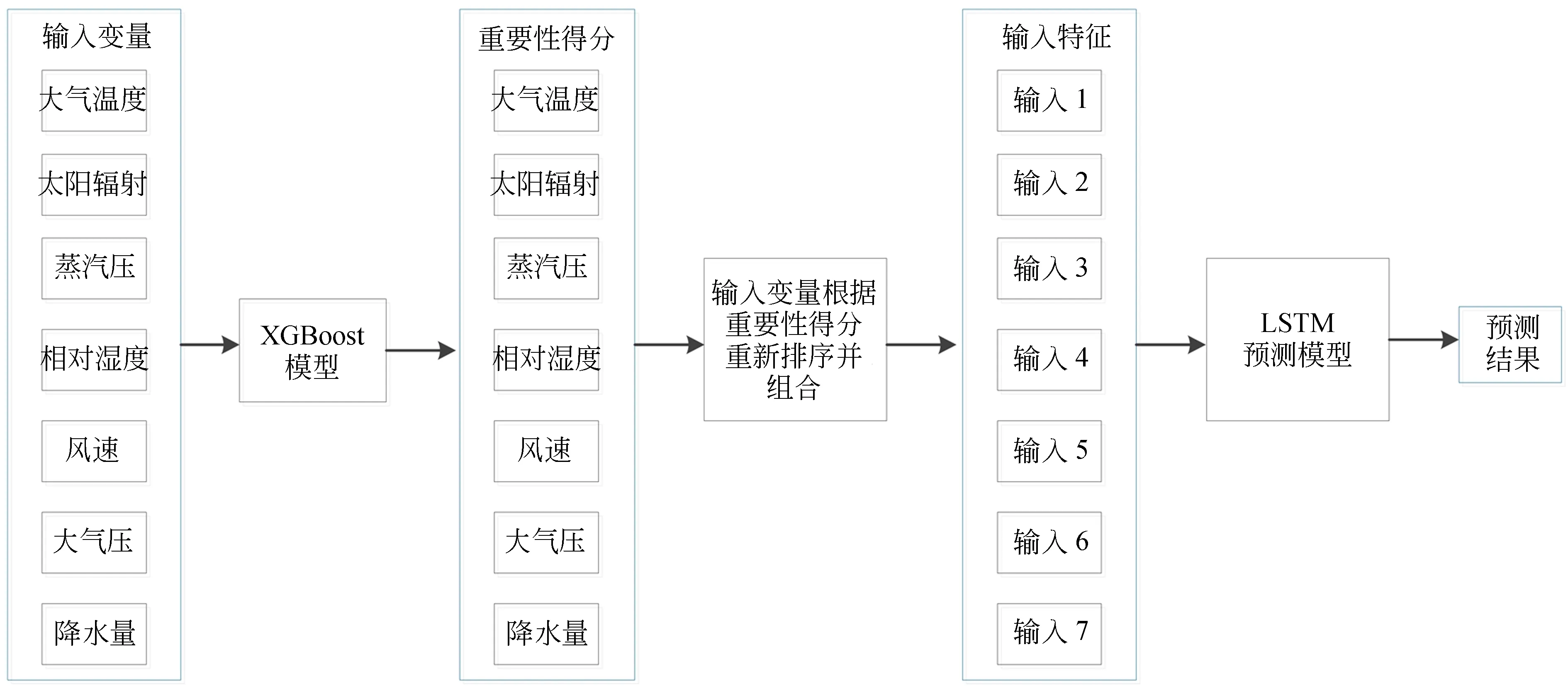
图3 XGBoost-LSTM整体流程Fig.3 Framework of XGBoost-LSTM model
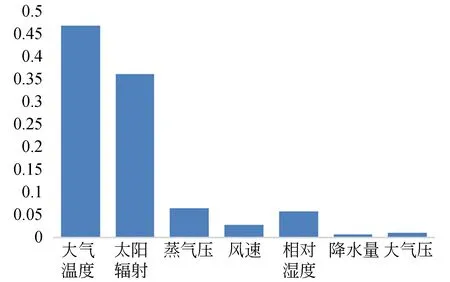
图4 影响因素重要性得分Fig.4 Weight of the meteorological inputs
最终通过实验可知,影响因素重要性由高低排序如下:大气温度、蒸汽压、太阳辐射、相对湿度、风速、大气压和降水量。然后根据影响因素重要性,通过逐步组合生成7种预测模型输入:大气温度(输入1),大气温度+太阳辐射(输入2),大气温度+太阳辐射+蒸汽压(输入3),大气温度+太阳辐射+蒸汽压+相对湿度(输入4),大气温度+太阳辐射+蒸汽压+相对湿度+风速(输入5),大气温度+太阳辐射+蒸汽压+相对湿度+风速+大气压(输入6),大气温度+太阳辐射+蒸汽压+相对湿度+风速+大气压+降水量(输入7)。
最后基于LSTM预测模型对对上述7组合进行测试,以找到最优的影响因素组合,如表6所示。根据实验可知,以大气温度、太阳辐射和蒸汽压3种组合作为输入,可以得到更好的预测结果。
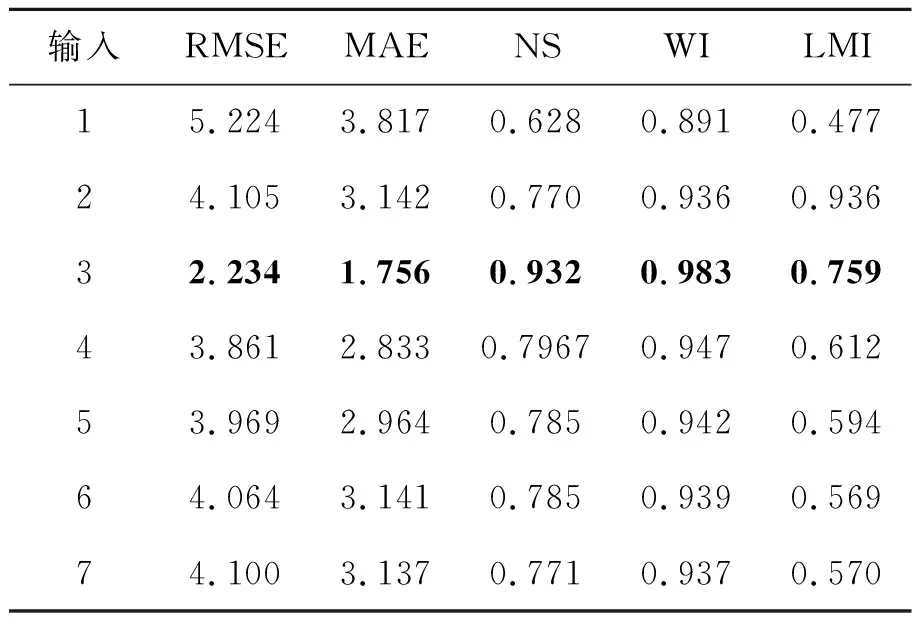
表6 不同输入组合的预测结果
3.3 不同数据驱动模型的对比
图5展示了在长白山区域,本文方法与目前常用的5种数据驱动模型的散点图对比。从图5可知,本文方法得到的土壤温度预测值(y)和观测值(x)之间的线性关系(y=0.980 6x+0.210 7)更接近理想线(y=x),同时相比其它数据驱动模型也得到了最高的R2(R2=0.934 2)。需要注意的是LR模型虽然具有最高R2,但其线性关系相较于其他数据驱动模型具有较大差距。因此表明本文方法在长白山区域预测效果最好。图6展示了海北区域散点图对比结果。其中,ELM预测模型预测结果相比本文模型更接近于线性关系,但由于其在长白山的表现一般,表现出其不稳定性。综合两区域散点图的线性关系可知,本文方法效果最佳。
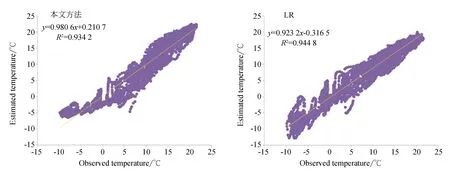
图5 长白山区域温度预测值与真实值的数据驱动散点图Fig.5 Scatterplots of the estimated and observed values of temperature(℃) using the data-driven models for Changbai Mountain metrological station
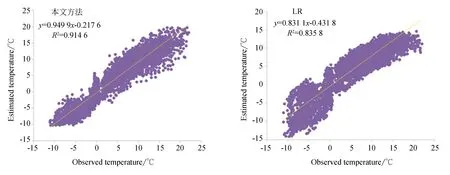
图6 海北区域温度预测值与真实值的数据驱动散点图Fig.6 Scatterplots of the estimated and observed values of temperature (°C) using the data-driven models for Haibei Mountain metrological station
表7和表8指出了不同数据驱动模型在长白山和海北区域性能数据统计对比。可知,本文方法在长白山站点得到的RMSE,MAE,RAME都比其他数据驱动模型的值小,同时WI,LMI的值最高。在海北站区域中,ELM预测模型的RMSE值优于本文方法,但NS,LMI出现异常结果。其原因可能是ELM是一种随机选择隐层权值的神经网络结构,这种随机性使预测模型训练时产生非最优解,从而影响预测结构[1]。综上所述,本文方法在不同站点的土壤温度预测中都优于其他数据驱动模型。
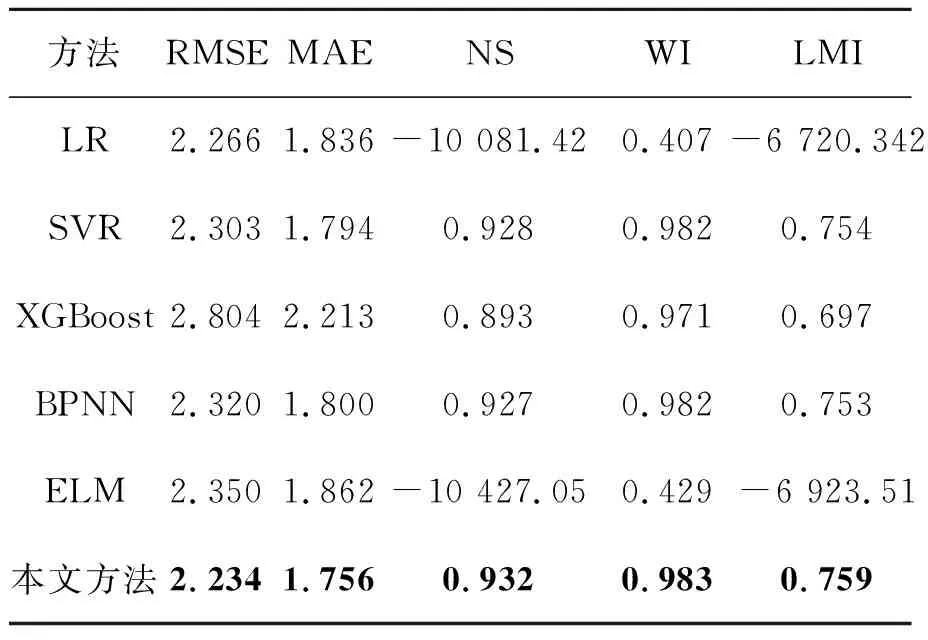
表7 长白山地区不同数据驱动模型的性能对
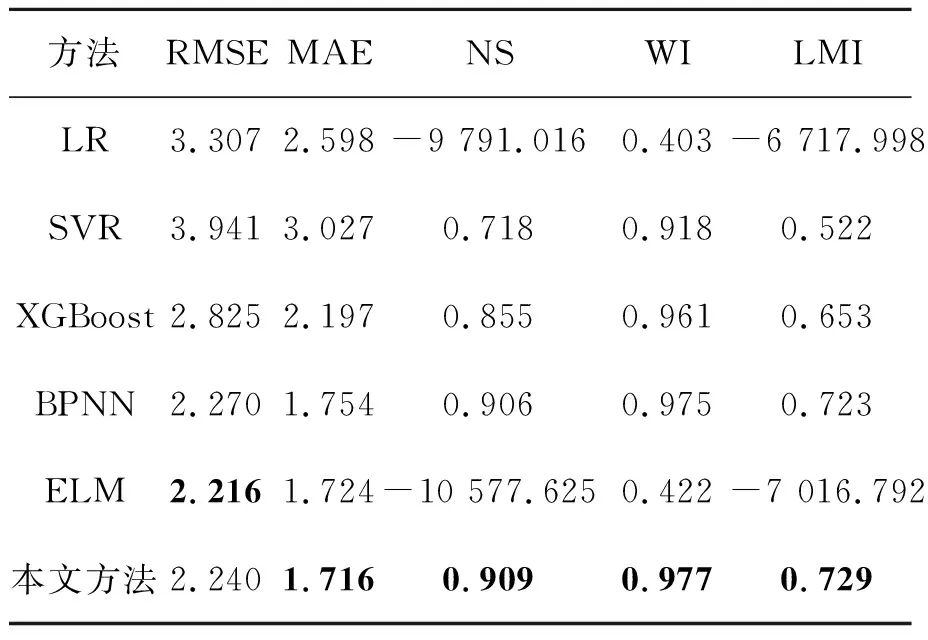
表8 海北地区不同数据驱动模型的性能对
4 结 论
然而,在前人研究主要基于ANN、SVR和ELM等方法实现土壤温度预测。缺少其它机器学习算法如极限梯度提升(XGBoost)和长短期记忆网络(LSTM)等研究。XGBoost是基于梯度下降方法,融合多个弱分类器成为一种强分类器,这种加强学习能力的模式,使XGBoost在多种领域的预测研究得到广泛应用。同时,具有记忆细胞的LSTM模型既可以学习其短期行为,也可以学习其长期行为。这种模式使LSTM在模拟自然系统时非常有用。同时土壤温度的影响因素很多,如太阳辐射、大气温度等。但基于机器学习针对影响因素重要性的量化评价,并结合预测模型的方式并未展开研究。事实上,预测模型中不同影响因素的组合对预测能力有很大影响。
本文将在中国长白山和海北区域进行测试,首先基于XGBoost计算土壤温度预测中每个影响因素的重要性,然后将影响因素依据重要性大小依次进行组合并作为预测模型的输入,其中本文将尝试基于LSTM作为预测模型。最后根据不同组合的预测性能选择最优的影响因素。通过实验结果表明本文提出的预测模型与目前土壤温度中常用的数据驱动模型,在预测结果散点图和准确度统计结果的对比中,均表现出更高的精确度。
然而由于FLUXNE采集数据限制,本文主要针对白山和海北区域中5 cm土壤深度进行实验。不同的土壤深度和更多的观测站点对预测模型性能的影响需要进一步研究。同时在实验过程中发现,不同损失函数的使用导致预测结果不同,因此针对损失函数改进对预测能力的影响是必要的。
猜你喜欢
猪业科学(2021年3期)2021-05-21
学生天地(2020年34期)2020-06-09
辽金历史与考古(2019年0期)2020-01-06
水土保持研究(2019年6期)2019-10-19
中国畜牧杂志(2019年3期)2019-01-11
辽宁林业科技(2017年4期)2017-06-22
浙江大学学报(工学版)(2016年2期)2016-06-05
西南石油大学学报(自然科学版)(2015年4期)2015-08-20
中国工程咨询(2015年8期)2015-02-16
植物营养与肥料学报(2011年2期)2011-10-26
