
基于聚类算法的人力资源管理优化讨论
2020-11-24 12:15苏韧伟王昭刘斐袁可刘军株洲时代新材料科技股份有限公司
消费导刊 2020年41期
苏韧伟 王昭 刘斐 袁可 刘军株洲时代新材料科技股份有限公司
一、引言
随着经济社会的发展和国际形势的变化,诸多国际化制造业企业在人力资源的竞争已经进入了白热化,传统制造业的人才结构变化也随之加速。同其他资源一样,能否将人力资源合理分配给若干需求端,使需求端的相关业务所需岗位胜任能力与人才素质合理匹配,提升人均劳效,进一步合理管理控制成本提升资源利用率,并获得企业绩效最大化是制造业的一大挑战。
数字化与信息化发展在制造业中已经逐步延伸到人力资源管理方向,人力资源管理人员积累了大量的数据。如何从如山如海的数据中提取有用的信息,并将其高效运用到人力资源日常管理的六大模块,成了其亟待解决的问题。企业人力资源战略规划及相关决策通常以人力资源分析为基础,数据挖掘可以为人力资源分析提供坚实的支持;基于分类识别有用的模式和规则,可进而分析并解决在人力资源六大模块实操中遇到的问题。聚类分析,作为数据挖掘的重要分支,可以通过分析数据的相似性把大型数据集合分类,使得在同一类里面的数据尽量相似,而不同类中的数据又尽量相异,从而得到较好的分类族群(陈倬,2016)。本文将根据T公司人才资本管理系统中的数据特性,考虑人力资源管理的对象以及发展趋势,以KMeans++和DBSCAN两种聚类算法为例,对应用场景进行讨论。
二、聚类对象与数据特征分析
本文探讨的聚类对象,即制造业人力资源管理的优化需考虑的人力资源管对象,也就是制造业企业发展所需要的劳动力。对聚类特征的选取需要考虑制造业人力资源的发展方向,以便尽可能锁定关键族群及其特征,这些特征也是人力资源管理优化过程中需要考虑的重要因素。
本文我们主要考虑以下四个发展方向:(1)首先,制造业对高素质高文化层次人才需求显著增加,这迫使人力资源管理的主观能动性逐步增强;(2)其次,日益复杂的外部环境和激烈的人才竞争必然导致人员流动性增强,从而增加企业人力资源管理的时间成本以及货币成本;(3)然后,劳动价值的清晰和模糊性同时在制造业得以体现,清晰是来自于明确的工作时间和产品价值,模糊则是由于设计、工艺、质量和部分高水平管理人员的劳动价值转化成经济价值和发展价值并不直接且周期较长。(4)最后,关键岗位、核心岗位以及特殊技能的优质人才的稀缺问题在传统制造业较长时间内仍然会趋于严重,人才向快销、电商以及金融等行业的流动意向给制造业招募和保留优质人才造成诸多困难,这一形势很难在短时间内扭转。制造业作为劳动力密集型产业,蓝领人员占比较大;另一方面,家庭乃至社会经济条件的变化,也使得劳动力市场和企业内部的劳动力供需关系更复杂多变。合理的分类才能使得接下来的比较行为较为合理的结论,劳动力的分类和比较是人力资源管理制度适宜性有效性评估的基础。通过对劳动力大数据进行分析,促进劳动价值提升是必然的趋势。我们认为,聚类特征的选取应带着发展的眼光,落点制造业人力资源管理的持续优化。
通过对T公司已经在运用的人力资源管理系统平台的现有数据研究,我们认为数据大致分为三类:第一类是以薪资、工作年限、福利、工时为代表的数值类等;第二类是属性类,如性别、学历学位、资质证书、工种、年度绩效类等;第三类是文本类,比如研究方向、籍贯、业绩评价、毕业专业和院校等。通常在数据分析过程中要将文本类数据标成属性产生概念分层,也就是转化成第二类数据。第一类数据、 编码后第二类数据、转化编码后第三类数据均可以执行聚类。
三、参数选取与应用讨论
之所以选择聚类算法在人力资源管理做应用场景探讨,在于其在电信、金融以及电子商务等行业客户画像有着广泛的应用基础,诸多场景可以参考比对(刘光榕等,2016;郭松,2018)。老话说:“物以类聚,人以群分”,聚类可以将相似的人群用不同维度的特征数据进行划分,不仅可以根据划分结果帮助决策者形成一个人力资源情况的系统性图谱,也可以进一步观察簇内人群的特征。科学的分类人群能够帮助决策者有针对性的制定人力政策。聚类算法不需要过多的、稳定的先验经验,其具备描述性和普适性,对管理结构改进的提示作用也较为明显。
(一)KMeans++
KMeans是一种典型的划分聚类算法,它用一个聚类的中心来代表一个簇,该算法只能处理数值型数据。KMeans++是基于KMeans对初始点的选择有改进的最优聚类竞争的算法(Arthur D.,etc.,2007)。用Python执行该算法需要给出聚类个数,最大迭代次数和算法运行次数等参数等。用KMeans++对人力资源管理领域做数据挖掘较为友好的原因在于:1)结果可解释性强,特别是对于上述第一类数据,数值型数据。2)重要参数为K值,即聚类个数。执行的时候考虑残差平方和SSE和轮廓系数Average Silhouette Score的同时,还考虑管理模式的适配、管理资源的可达性等问题(图1)。例如我们可以以部门数量作为聚类个数,分析部门内人员的相似程度以及部门间人员的差异程度。3)算法效率高,聚类效果尚可,故而对商业智能的动态展示较好,进而帮助管理者做一些即时的决策。4)对初始点的改进使得获得全局最优解的可能性大大增加,减少分类不恰当导致决策失误的可能。5)采用数据标准化可以化解一部分类别数据不均衡、方差大的问题,适用于多维度数据分析。6)对错误值敏感,且有类似的改进方法,如K-Medians或K-Mediods,可以辨别出某类和某维度的代表人员乃至簇内差异。
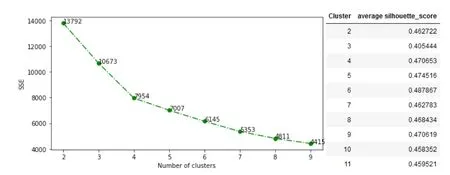
图1:残差平方和和轮廓系数图
(二)DBSCAN
DBSCAN算法是一种典型的基于密度的聚类算法,采用空间索引技术来搜索对象的邻域,引入了“核心对象”和“密度可达”等概念。该算法从核心对象出发,把所有密度可达的对象组成一个簇(Ester M .,etc.,1996)。在Sklearn库执行DBSCAN需要输入的主要参数包括:邻域半径eps,邻域样本数阈min_samples,以及最近邻域度量参数metric。最近邻域度量参数metric的选择一般是考虑属性特征和之间的关联,一般选取欧式距离。我们也可以根据情况选择马氏距离,通过把方差归一化使得特征之间的关系更加符合实际情况,比如年龄与薪资之间的关系。不同于Kmeans++算法,当不知道要分几类或者对聚类簇的形态没有偏倚的时候可以使用DBSCAN,且算法效率同样较高。
对于EPS和min_samples参数的选择方法,建议首先计算数据对象间的距离得到距离矩阵Dist(n×m)(公式1),对距离矩阵将行向量进行升序排序,得出每行是相应数据点到其他所有点距离的一个排序。绘制距离值的概率密度分布曲线和距离每个数据点最近的第i个距离值的升序曲线。进而,根据拐点建议eps。在拐点对应的eps之后,其聚类和噪声检测结果趋于稳定。最后,我们根据已确定的eps值,再计算每个数据点i的局部密度值,再得出每个数据点i距离更高密度点的距离δi,用每个点δi和ρi的函数的关系帮助选择min_points(公式2)(宋金玉等,2019)。
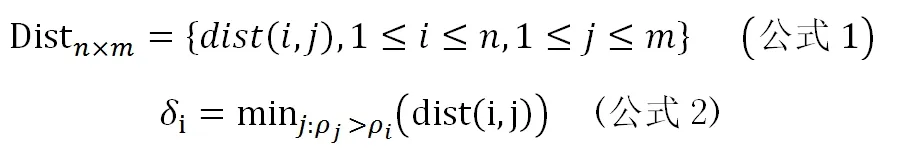
上述方法虽然可以根据数据集的统计学特征和图表可视化协助参数选择,但仍然需要人力资源管理人员根据经验判断聚类结果是否合适。值得注意的是,DBSCAN可以在聚类的同时发现异常点。而异常点恰恰是人力资源管理需要特别关注的,我们希望留住的稀缺能力人员在聚类图谱中恰恰很可能在异常点里。同时,对于较大的分类簇,我们可以进一步细化其特征描述,然后匹配业务需求制定培训、绩效管理甚至外包等策略。
四、结论
数据作为一种越来越重要的生产因素,已经渗透到当今每一个行业和业务职能领域。人力资源管理作为制造业的一个必不可少的职能,亟需摆脱“数据丰富,信息贫乏”的状态。本文阐述的两种聚类算法虽然不是从技术方向考虑分类人群最优的算法,但不失为当下较为适宜的选择。两种算法在面对不同的数据集,业务场景以及分析目标具备一定的互补作用,且都对分析指标的权重比较敏感。分类方式的优化对于将人力资源管理放在战略地位的制造业企业至关重要,可以帮助其人力资源管理体系的持续改进,为企业提供更多的人才解决方案。
猜你喜欢
商品与质量(2021年43期)2022-01-18
大众投资指南(2021年23期)2021-12-06
口腔护理用品工业(2021年4期)2021-11-02
中国外汇(2019年19期)2019-11-26
现代园艺(2018年2期)2018-03-15
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国卫生(2016年10期)2016-11-13
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
