
基于改进YOLO的公路路网视频并发检测及应用
2020-11-20 03:20成玉荣陈湘军杜晨浩胡海洋
实验室研究与探索 2020年10期
成玉荣, 陈湘军, 杜晨浩, 胡海洋
(江苏理工学院计算机工程学院,江苏常州213001)
0 引 言
公路是国家经济动脉,通过信息化手段实时掌握公路网通行状态,对于公路网日常养护管理与公众出行信息发布都具有重要意义。
近年来,深度卷积神经网络[1]在计算机视觉目标检测任务上取得了巨大的成功,通过计算机视觉方法在现有监控网络中实现公路网状态的实时监测,可以充分挖掘利用已有视频资源,具备操作简易、维护方便等优势。深度神经网络经过不断发展,网络结构越来越复杂,从5 层的LeNet[2],到8 层的AlexNet[3],再到22 层的GoogleNet[4],甚至到了上百层的ResNet[5],不断提升模型的准确率,然而随着神经网络参数数量不断增大,深度学习面临存储和计算代价高、功耗高等弊端,限制了其在资源受限的平台上使用。
本文提出一种基于网络结构剪枝与模型融合实时并发视频检测方法,通过网络模型压缩,并结合模型量化[6],在几乎不影响精度的条件下,减少计算代价,提升算法推理速度,实现多路监控视频实时并发检测。基于Darknet-53[7]网络剪枝设计改进的少参数网络模型,通过交叉验证训练生成改进YOLO车辆检测模型,在DeepSort[8]目标追踪算法基础上,通过摄像机与车道线的仿射变换,获取像素运动与车流速度的映射关系,使用虚拟线圈方式,实现高速公路断面流量及车速的统计,并生成道路通行状态事件信息,应用于高速公路管理决策与公众出行信息发布。
1 网络剪枝与模型融合
1.1 YOLO目标检测算法
YOLO系列算法是One-Stage 目标检测算法代表之一,YOLOv1[9]提出通过网格划分做检测,通过目标中心点在网格的位置检测目标,显著提升检测速度,YOLOv2[10]在网格约束的基础上应用了anchor[11]机制,通过预设不同尺度的先验框使检测器专注于检测与先验框形状相近的物体,同时采用了batch normalization[12]作为正则化、加速收敛和避免过拟合的方法。
YOLOv3[7]算法流程如图1 所示,采用了ResNet中的残差网络思想设计了Darkent-53 作为特征提取的主干网络,在YOLOv2 的基础上,借鉴FPN[13]的多尺度思想,设计了3 个不同尺度的检测层,并为每个检测层分配3 个先验框。YOLOv3 通过边框回归预测的方式预测物体位置,解决了先验框机制线性回归不稳定的问题。针对416 × 416 的图像,3 个检测层对应的特征映射尺度分别52 × 52、26 × 26、13 × 13,从而能够检测出各种尺度的目标。
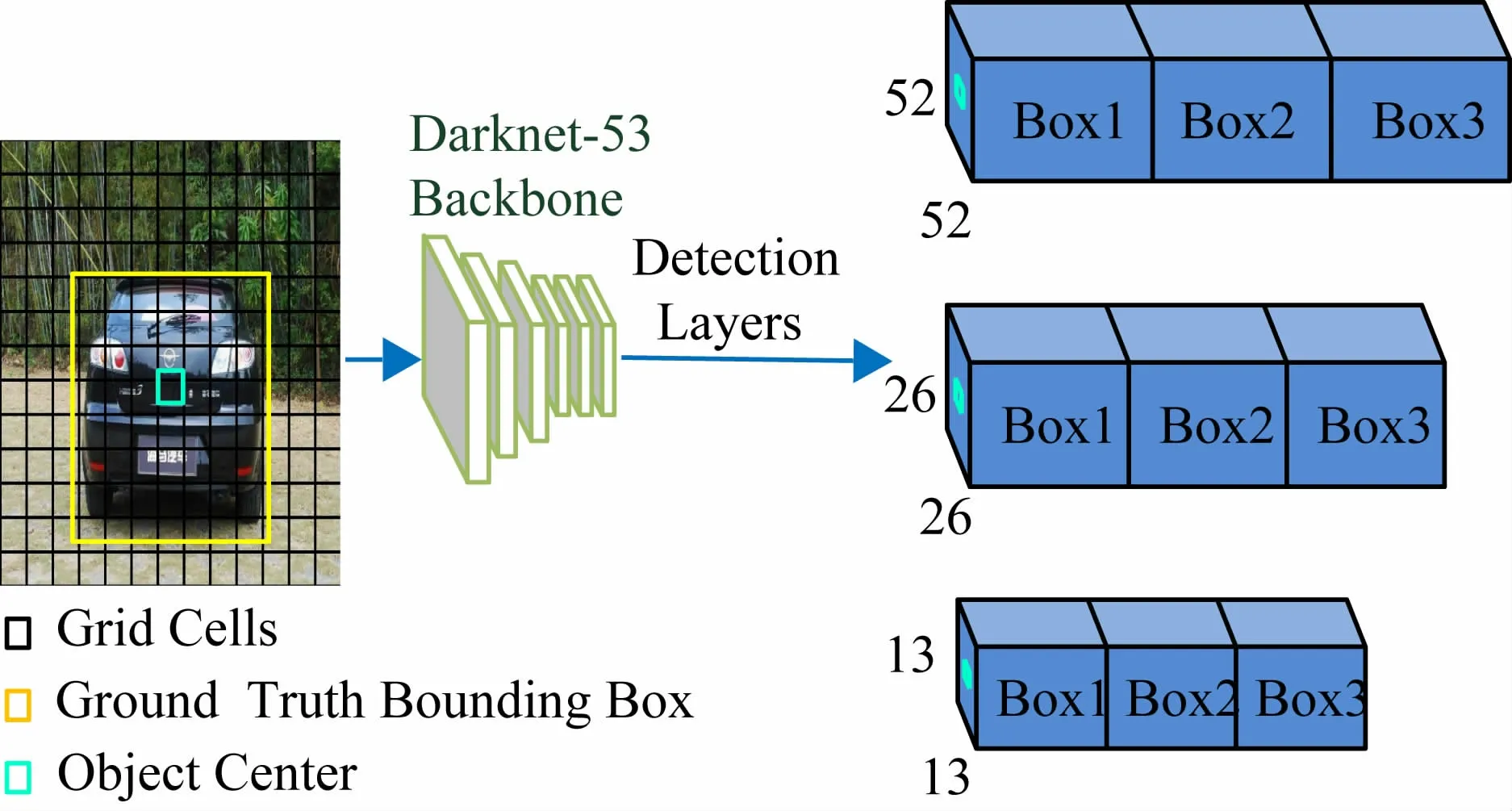
图1 YOLOv3算法流程
1.2 网络剪枝
神经网络模型剪枝是指在对模型检测效果没有太大影响的前提下剔除模型中不重要的参数,再重新微调模型以恢复模型性能的一种方式。本文针对实际工程应用中模型过大,难以实现并发实时检测,提出对YOLOv3 算法的剪枝方案。
Darknet-53 分为5 个主要层次,如图2 所示。本文在该网络结构中间3 个层次中引入层次比例因子α,即通过减少部分网络层次深度减少网络参数。在最后一个层次的神经网络层中引入宽度因子β实现通道剪枝调整模型大小,即使用宽度因子β 控制输出的通道数,使输出通道数由C转变βC。
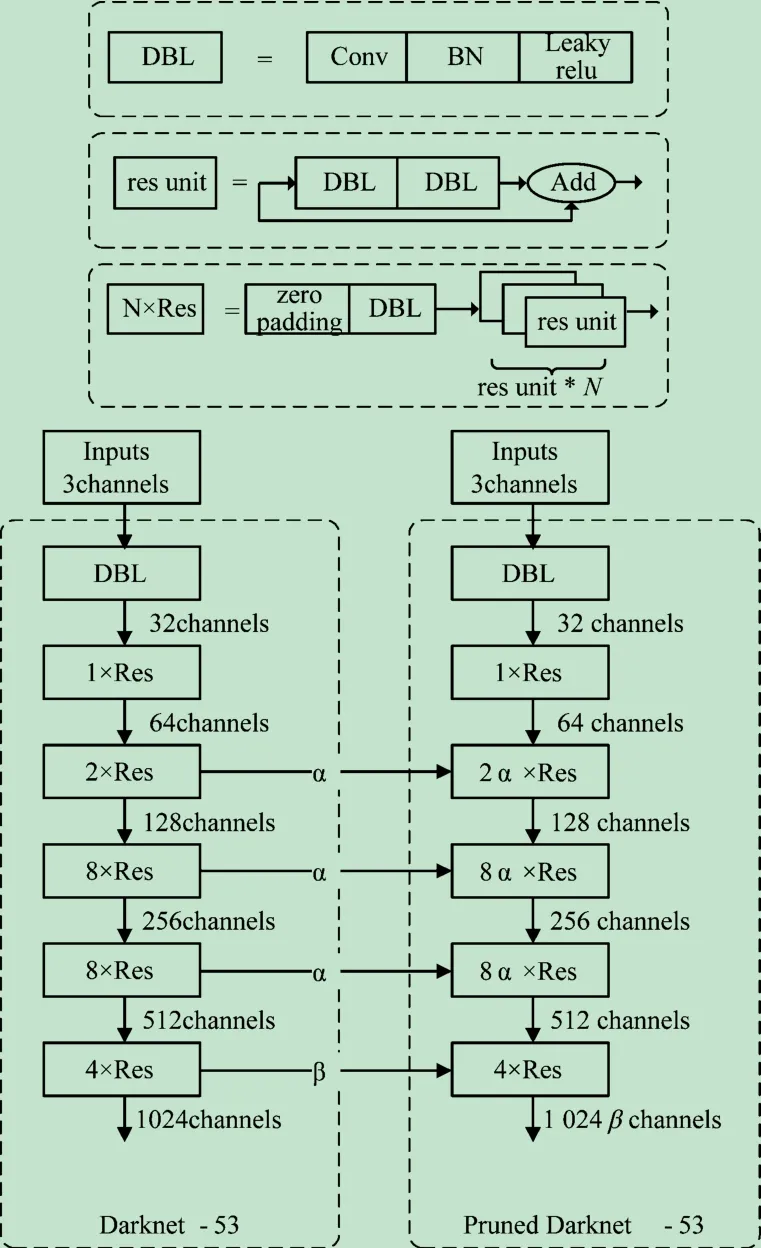
图2 利用比例因子实现层次与通道裁剪
本文采用SCUT-HEAD-B公开数据集在剪枝后的网络中进行试验,该数据集包含2 300 张图片,将其以7∶3的比例随机分为训练样本与测试样本。在英伟达TITAN X 上以层次比例因子α = 50% 与β 分别为100%、75%、50%与25%进行训练,以IoU = 0.5 作为评测指标在不同尺度图片输入的情况下进行验证,记模型格式为S-[α]-[β]-[ImgSize],其中S表示使用的是SCUT-HEAD-B数据集,α与β分别代表层次比例因子与通道宽度因子,ImgSize 代表输入图片的宽高,通常为32 的倍数,模型S-50%-25%-416 训练273 个epoch过程如图3 所示,其中召回率(Recall)为正确被检测到的数量与应该被检测到的数量的比值,由图3可以看出在迭代100 个epoch 后,召回率与平均精准率(mAP)均稳定保持在80%左右。
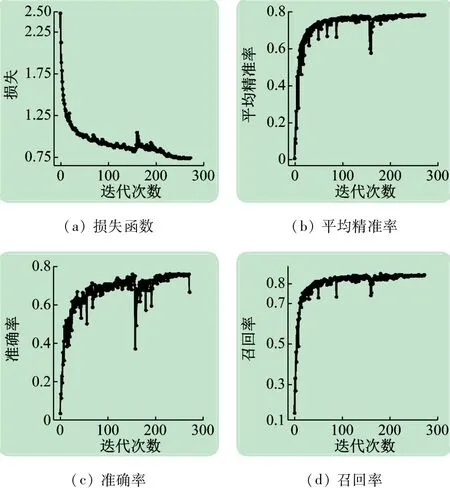
图3 训练过程
表1 给出的是SCUT-HEAD-B 数据集在不同比例因子与检测尺寸下的检测效果,其中Size 为模型权重文件大小,Inference为单张图片推理所需时间。
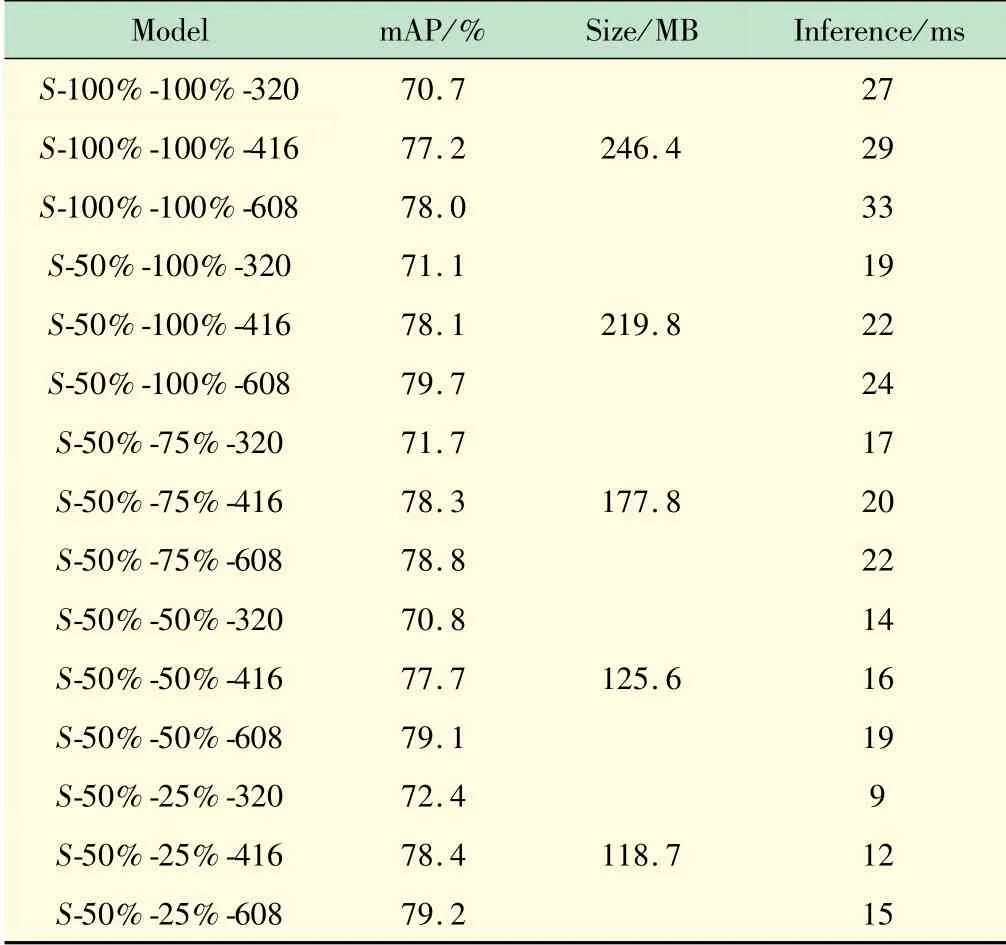
表1 SCUT-HEAD-B数据集训练结果
实验结果表明,深度卷积神经网络适当地压缩网络结构,能取得相当的性能,同时有效地减少推理时间,满足实际场景中的应用。
1.3 模型融合
GoogleNet的Inception[4]模块如图4 所示。该模块使用密集结构来近似一个稀疏的卷积结构,通过采用不同大小的卷积获得不同大小的感受野,卷积核大小分别采用1、3 和5,步长设置为1,padding 分别设定为0、1 和2,便于获得相同维度的特征,最终拼接实现不同尺度特征的融合。此外,为了减少计算量,利用1 × 1 卷积实现降维。

图4 Inception模块
在网络剪枝的基础上,本文将YOLOv3 第1 个检测层中用于深层特征提取的DBL 模块替换为Inception模块,提高特征层间的空间信息交互的同时,也减少了部分网络参数,从而提高模型整体的鲁棒性与推理速度,改进后的网络结构如图5 所示。
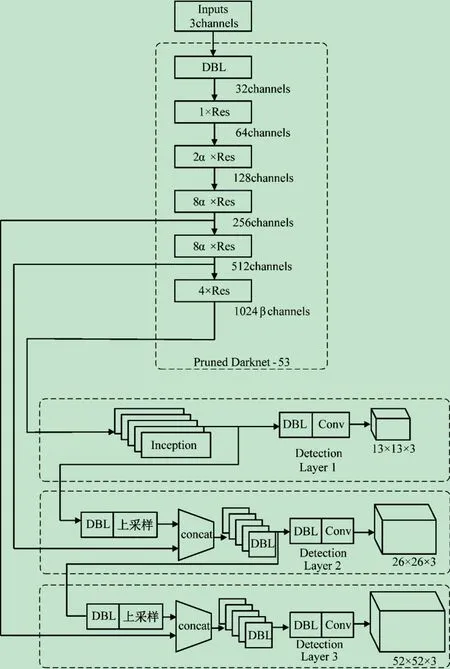
图5 模型融合
使用伯克利数据集中提取出的车辆目标数据对模型进行预训练,该数据集包含70 000 张图片用于训练,10 000 张图片用于验证,数据样本如图6 所示。结合交叉验证机制训练车辆检测模型,选取验证效果最好的权重作为训练COCO数据集中车辆数据的初始权重并进行finetune[14]训练,记模型格式为C-[α]-[β]-[ImgSize]-[DT],其中C 表示使用的是COCO 数据集,α 与β 分别代表层次比例因子与通道宽度因子,ImgSize为输入图片宽高,DT(data type)为模型参数的数据类型,分别在模型参数为32 位浮点数和16 位浮点数的情况下测试模型,实验结果如表2 所示。

图6 伯克利数据集样本

表2 模型量化结果对比
实验结果表明,在不影响检测精度前提下,模型量化能够有效提高推理速度。
2 系统设计与实现
2.1 系统实现流程
高速公路视频分析系统实现流程如图7 所示,具体步骤如下:读取高速公路监控视频;提取车道线,根据车道线标准物理长度进行透视变换计算,生成变换矩阵,获得垂直俯视视角下像素与物理距离的对应关系;基于车辆目标检测,实现车辆跟踪;基于车辆目标跟踪与像素距离位移,实现车辆计数与测速,并判断道路是否发生拥堵、车辆超速等事件,并自动生成预警信息和取证录像。

图7 高速公路视频分析系统实现流程
2.2 透视变换
透视变换是将图像投影到一个新的视平面,也称作投影映射。透视变换通过二维空间到三维空间的转换,获得新的二维空间的映射,相对于仿射变换,它提供了更大的灵活性,可将斜视角的四边形区域映射到垂直视角的矩形区域。透视变换通过矩阵乘法实现,一般使用3 × 3 矩阵实现,如下式所示(矩阵的前两列实现了线性变换和平移,第3 列用于实现透视变换):
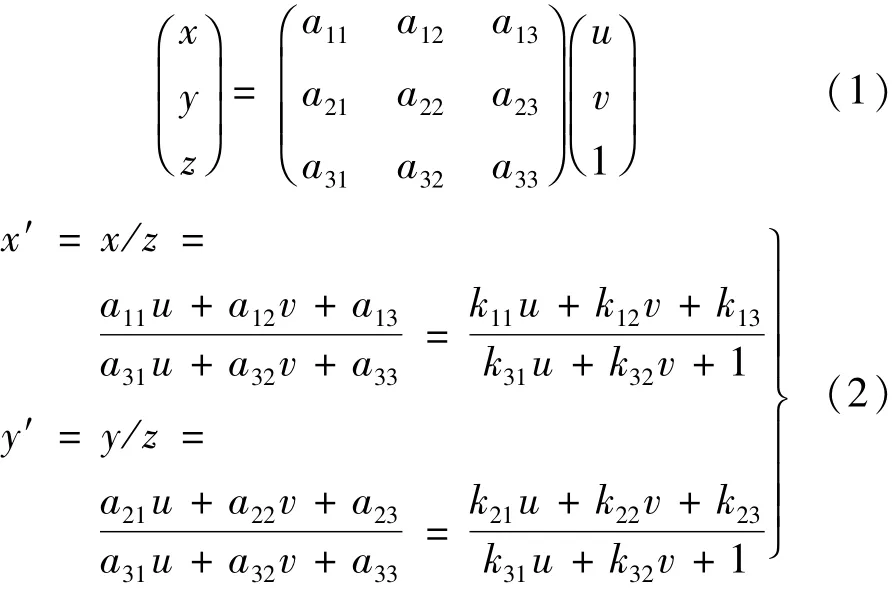
式中:(x,y,z)为中间变量;(u,v)为变换前的坐标;(x′,y′)为变换后的坐标。透视变换有8 个未知数,因此透视变换矩阵只需待变换四边形区域与目标四边形区域对应顶点的四组点便可求解。我国高速公路标准车道线相邻间距为15 m,选取间距为15 m 方向与车道线垂直的两条线与边界线的交点作为待变换区域的顶点坐标,选取(0,0)(220,0)(220,96)(0,96)作为透视变换后平面上对应的各顶点坐标,即长为220 个像素点宽为96 个像素点的矩形区域,计算获得透视变换矩阵,并将透视变换矩阵应用于原图像上目标区域,效果如图8 所示。根据跟踪与像素对应关系,目标在变换后的垂直俯视图中移动1 个像素单位对应的实际距离为0.156 25 m。

图8 透视变换效果
2.3 车辆目标检测
从高速公路摄像头读取监控视频流作为加载完权重网络的输入,逐帧进行检测,将3 个尺度预测的张量拼接生成一个维度为(1,10 647,8)的张量,其中1 表示当前batch为一张图片,10 647 代表3 个尺度预测框的总个数,8 代表中心点坐标、宽高、目标置信度得分、三类车辆(小汽车、卡车、公交车)的可能性得分,10 647 个框中存在大量冗余框,通过设置置信度阈值与交并比阈值,基于非极大值抑制算法去除无效的检测框[15]。首先将目标置信度得分低于阈值的框全部去除,在剩余的框中取出置信度最高的框,此框为检测到的一个目标,计算它与其他所有框的交并比,去除交并比大于交并比阈值的框,重复上述操作,非极大值抑制算法如下所示:
输入 B,S,Nt
输出 D,S
1.B ={b1,b2,…,bN},S ={s1,s2,…,sN}
2.begin
3.D ←{}
4.while B ≠empty do
5. m ←argmax S
6. M ←bm
7. D ←D∪M;B ←B - M
8. for biin B do
9. if iou(M,bi)≥Ntthen
10. B ←B-bi;S←S-si
11. end
12.end
13.return D,S
14.end
其中:B 为检测框的集合;S 为对应框置信度的集合;D 为符合要求框的集合;Nt为交并比阈值。首先获取目标框中置信度最高的框的索引,取出该框并将该框纳入集合D,将剩余目标框与其依次计算交并比,若高于交并比阈值则将当前目标框剔除,重复上述操作,直至B为空集,抑制前后效果如图9 所示。

图9 非极大值抑制算法检测效果
2.4 车辆目标追踪
通过射线法判断视频流中每1 帧图片检测到的目标中心点坐标(x,y)是否在标定区域内,射线法即以该点为顶点做一条射线若射线穿越多边形边界的次数为偶数时,则在多边形外部,若穿越多边形边界次数为奇数时,则在多边形内部,从而筛选出标定区域内的车辆目标。将标定区域内检测到的车辆目标图像块作为一个重识别卷积神经网络输入,最终输出一个128 维的特征向量,计算与跟踪物体之间的马氏距离,当两者距离小于特定阈值时则表示两者关联,
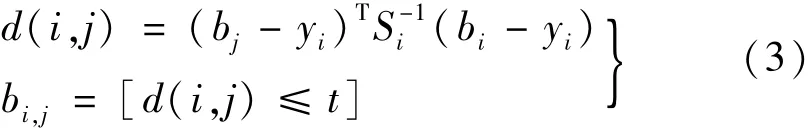
式中:bi与yi分别是当前帧检测到的目标与关联帧中追踪目标对应的特征向量;t为阈值,当两者的马氏距离≤t时则表示两者为同一目标,将同一目标在通过该区域过程中中心点坐标存储在各自的列表[(x1,y1),(x2,y2),…,(xn,yn)]中。
2.5 车辆计数与测速
当区域内出现新目标时,计数器自动加1。利用上述求得的透视变换矩阵将原图片中追踪到目标的中心点(x,y)映射到透视变换后的平面中(x′,y′),通过变换后的目标中心点横坐标值所在区间判断其属于哪个车道,当变换后的目标中心点接近虚拟检测线时,通过该目标对应列表中坐标的个数获取帧数N,监控摄像头设定的帧率为25 f/ s,计算通过该区域所需的时间,利用列表中纵坐标的最大差值获取该目标经过的像素距离Sp,单位像素的实际距离0.156 25 m,计算得出当前目标速度为
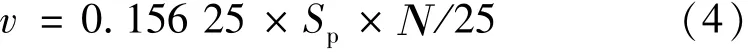
通过截面断点车道平均车速计算,可实时获取道路通行状态,实现缓行或拥堵事件检测,也可实现个体车辆超速取证,系统自动生成事件录像和超速取证图像,通过Web系统发布实现自动事件检测功能。
3 试验效果
基于本文改进后的YOLOv3 构建了高速公路视频分析系统,系统在江苏沿海高速连云港与南通路段进行试运行测试,实验条件如下:
软件环境 Ubuntu 18.04,Python3.6.8,OpenCV3.4.1,Pytorch1.1。
硬件环境 CPU:Intel Xeon E5-2620 v3 @ 2.40 GHz六核;内存:DDR4 64 GB;GPU:Nvidia GeForce GTX TITAN X。
实际场景应用效果如图10 所示。
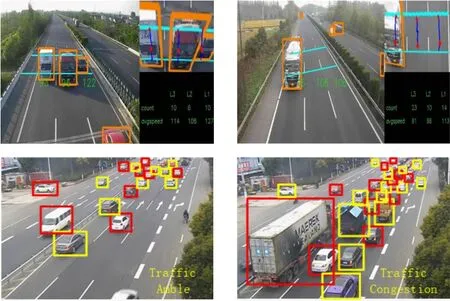
图10 高速公路境景应用效果图
传统的基于监控视频的车辆测速与计数方法有背景差分法与Harris角点法[16],背景差分法利用序列图像中的当前帧与背景图像做差分检测运动车辆目标,Harris角点法利用Harris算子对车辆目标进行角点特征检测。截取1 h高速公路监控视频进行车辆测速与计数检测效果对比实验,实验结果如表3 所示,本文基于改进YOLOv3 构建的车辆测速计数方法相较于传统视频测速计数方法具有更好的测速精度与计数准确率。

表3 改进YOLOv3 车辆测速计数方法与其他方法比较
取一段高速公路监控视频对改进前后的YOLOv3模型检测性能进行测试,实验结果如表4 所示。本文基于改进后YOLOv3 实现的高速公路视频并发检测应用,在几乎不影响精度的条件下,并发量与检测帧率大大提高,完全能满足实际运用的需求。

表4 模型改进前后性能比较
YOLOv3 具有一个轻量化模型Tiny-YOLOv3,该模型参数量少检测帧数高,但由于检测精度较低,不能够满足实际场景中工程应用的需求。
4 结 语
实际应用中,能够精准地检测出车辆目标、车流量与速度检测准确率高,能够满足现实应用场景需求。但也表现出一些问题:较小目标检测效果一般,模型的计算量仍然高于移动端以及部分嵌入式设备的算力。后期将进一步进行网络剪枝、模型量化,以及使用深度可分离卷积替换标准卷积模块的实验,希望能够在对精度影响不大的条件下,减少模型计算量,提高推理速度,使模型的整体性能能够满足实际工程中并发的需求。
猜你喜欢
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-03-16
阅读与作文(小学低年级版)(2016年12期)2016-12-22
