
基于城市共享单车流动大数据下停放点设置与投放数量研究
2020-11-09 07:28刘江涛
科学与财富 2020年25期
关键词:数据挖掘
刘江涛


摘要:针对共享单车风靡各大城市,给人们带来了出行方便,但也带来乱停放、废弃车辆占道堆积的城市治理难题。因此,我们组决定以共享单车为基础,借助云计算和大数据平台,进一步对大数据经济模式下共享单车使用情况进行分析,利用Python软件,运用K-Means聚类算法和建立PERT网络图计算安置单车数量。让共享单车成为我们生活出行便利工具,达到实时路况分析,出行道路最优化设计。
关键词:数据挖掘;K-means聚类算法;PERT网络图
0. 引言
近年来,我国的共享经济行业蓬勃发展,正成为推动国民经济快速和可持续增长的巨大引擎。其中,共享单车更是风靡各大城市,但也带来乱停放、废弃车辆占道堆积的城市治理难题,且安置十分不规律在管理上浪费大量资金[1]。但是,共享单车的用户数量却年年上升,必将面临更加严重的管理问题,如何安置共享单车流动大数据下停放点设置与投放数量成为目前迫在眉睫的问题[2][3]。因此,K-Means聚类算法和建立PERT网络图应用研究共享单车流动大数据下停放点设置与投放数量是十分具有意义的[4]。
1. 数据的获取与处理
1.1 数据的获取
本文的数据来源于天池平台数据实验室,由3 月12日到6 月18日的共享单车在线运行数据中抽取的用户使用数据构成。原始的数据集共10231条共享单车用户操作记录,包括起始位置,骑行时间、路线,终止位置等信息,涉及到5432个用户和8916个行驶路线,用户数据经过脱敏且真实可靠。
1.2 数据的处理
在对数据的清洗过程中,发现存在只有点击行为且点击次数很多的用户,推测为爬虫用户,属于噪声数据,予以剔除,具体为点击次数大于200且无移动,支付行为。清洗后的数据集包括9843个用户的操作记录。
2. 基于K-means聚类算法构建共享单车区块
2.1 研究思路
基于哈啰单车在线运行数据中抽取的用户行为数据样本,结合业务逻辑从海量样本数据集中提取量化指标,运用Python数据挖掘软件、K-Means聚类分析数据挖掘方法进行多次聚类分析,采用wss方法得出各个方面最佳的聚类数K,实现哈啰单车的区间划分。
2.2 哈啰用户位置特征提取
基于大量数据提取所有用户的经度(CLi)和纬度(PAi)的位置数据。
2.3 模型原理
对于多维数据集,K-means聚类算法确定K个中心点,将每个数据点分配到离它最近的中心点,将数据集划分为K个类簇,分配原则为使数据点到其指定的聚类中心的的平方的总和即
最小,然后重新计算每类中的点到该类中心点距离的平均值,继续分配每个数据到它最近的中心点直到所有数据点不再被分配或是达到最大的迭代次数。
2.4 采用wss方法获取K值图
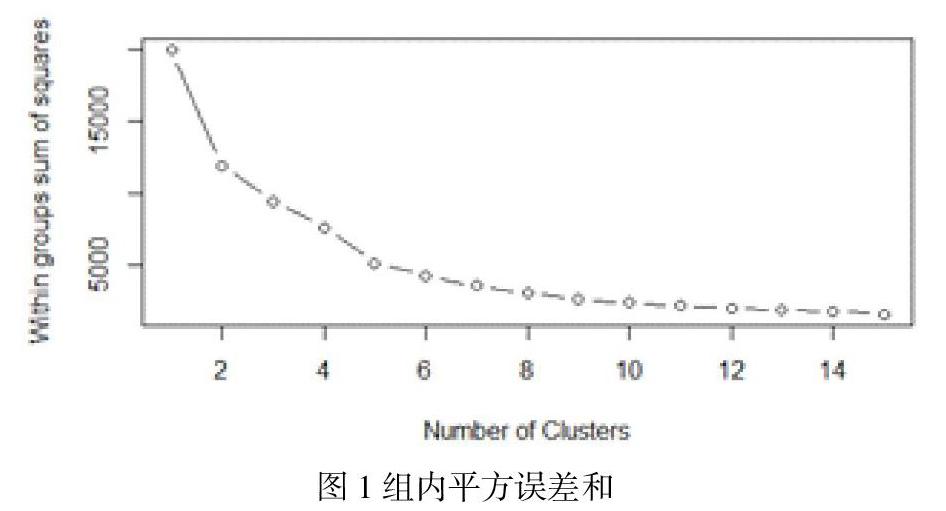
以和 作为聚类指标,基于K-means聚类分析过程,采用wss方法获取最佳K值,运用R软件作出组内平方误差和——拐点图。
从图1 看出,当K值大于等于4 时,随着K值的增大,类中总的平方值对聚类数量的曲线趋于平缓,说明K值越大,其簇内差异(Inertia)指标是越来越小的。即当K值为样本量时,Inertia指标是可以取到0,这并不代表模型的效果越来越好了。
2.5 轮廓系数获取最佳值K
样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均离;样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中的所有点之间的平均距离。根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。
样本的轮廓系数计算为:
很容易理解轮廓系数范围是(-1,1),其中值越接近1 表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。当轮廓系数为0 时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。可以总结为轮廓系数越接近于1 越好,负数则表示聚类效果非常差。如果一个簇中的大多数样本具有比较高的轮廓系数,则簇会有较高的总轮廓系数,则整个数据集的平均轮廓系数越高,则聚类是合适的。如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的,聚类的超参数K可能设定得太大或者太小。运用Python软件进行K-means聚类分析,得出聚类结果表1 运用Python软件進行K-means聚类分析,得出聚类结果表1。
从表1 可以看出,随着K的增大,指标一直在不断的变小,总组内平方误差和在一直减小,但是轮廓系数也在一直减小,即在增加K值时,通过总组内平方误差和是无法判断K的取值。在通过轮廓系数的下降率与总组内平方误差和的下降率的比较,选择K=4 时,是聚类质心的最佳值。
2.5 K取值分析
从图2 可以看出,数据集被分为4 簇,即全体用户被分为4 类。
根据选取的地理位置进行共享单车区块聚类分析,得到结果表2。
从表2 可以看出,共享单车区块被分为4 类。可以从图表中很容易看出,共享单车的使用群体大多是大学生一类的年轻人,且在地理位置上有明显的优势,大学基本都集群在同一区域,且大学生活动较为频繁,在每个聚类的质心设置共享单车区块利于管理和维护。
3. 基于建立PERT网络图计算安置单车数量
3.1 研究思路
基于共享单车区块提取海量哈啰用户行为数据即每个周期时刻每个共享单车区块中哈啰单车的流出量和流进量。利用PERT网络图计算安置单车数量。
3.2 模型原理
3.2.1 结点(事件):图中的圆,表示每个周期流入结点的共享单车数量,流出节点的共享单车数量。3.2.2周期时段:选取共享单车骑行时间为周期时间,则对于每个用户而言每个安置点的数量是动态平衡的。
3.3 模型建立和求解
建立4×4的四阶矩阵,矩阵每一行表示周期时段每个安置点流出到其他安置点的数量。对于数量矩阵举行PERT网络迭代,直到矩阵不再发生变化,迭代结束,实行共享单车流动的动态平衡。
3.4 迭代后矩阵及安置点哈啰单车数量
运用lingo软件对矩阵进行迭代,得到稳定后的矩阵1。
由矩阵1 可知,安徽财经大学东校区西门安置点应该安排79辆共享单车,龙湖春天西街应该安排55辆共享单车,蚌埠学院(北侧)应该安排40辆共享单车,安徽科技学院应该安排56辆共享单车。
4. 结语
本文基于大量的哈啰单车在线运行数据,将哈啰用户区块化,共享单车区块化的设置管理和维护。采用数据挖掘和大数据分析方法,运用K-Means聚类算法对共享单车区块化分类,以便更好的应用PERT网络图,从而计算每个区块化的节点流出共享单车数量,对于每个节点在一个周期内的流出量进行PERT网络图算法迭代计算出动态平衡时,每个节点的流出量和流入量。从而得到每个节点最佳的安放共享单车的数量。
参考文献:
[1] 张健.基于分布式的共享单车定位算法的研究[D].南京邮电大学,2019.
[2] 刘思嘉,杜雅楠,伍金铭,丁亭亭.移动互联背景下共享单车运营管理研究[J].市场周刊,2019(11):145-146.
[3] 付亚金.共享单车运营与管理中的政府责任研究[D].南昌大学,2019.
[4] 刘文钦.基于DEA方法的共享单车投放区域综合效率研究[D].上海外国语大学,2019.
作者简介:
劉江涛(1998——)男,汉族,安徽铜陵人,安徽财经大学统计与应用数学学院,2017级本科生,信息与计算机科学专业
本文属安徽财经大学大学生创新训练项目《基于城市共享单车流动大数据下停放点设置与投放数量研究——以蚌埠市为例》(编号:201910378039)阶段性研究成果,指导老师:朱家明。
本论文属于安徽财经大学大学生创新训练项目项目,项目编号:201910378039,指导老师:朱家明。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
中国中医药信息杂志(2016年7期)2016-12-01
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
河南科技(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
智能系统学报(2013年1期)2013-01-28
