
基于Kmeans聚类的XGBoost集成算法研究
2020-11-09 07:29罗春芳张国华刘德华朱定欢
计算机时代 2020年10期
罗春芳 张国华 刘德华 朱定欢


摘 要: 针对分类问题中的模型泛化能力,提出了基于Kmeans聚类的XGBoost基分类器集成算法,以提升整体算法的泛化能力。首先,训练数据集获得多个XGBoost模型;然后,通过Kmeans算法对不同模型的实验结果聚类;最后,对每个分类簇中泛化能力最优的分类器进行集成。在对某公司实际分类问题中应用该算法,结果表明,该算法的泛化能力有很大程度的提升。
关键词: Kmeans聚类; XGBoost; 集成算法; 泛化能力
中图分类号:TP391 文獻标识码:A 文章编号:1006-8228(2020)10-12-03
Abstract: Aiming at the model generalization ability of classification problem, a K-means clustering based XGBoost base classifier ensemble algorithm is proposed in this paper to improve the generalization ability of the whole algorithm. Firstly, training data sets to obtain multiple XGBoost models; then clustering the experiment results of different models with K-means algorithm; finally, integrating the classifiers with the best generalization ability in each cluster. The algorithm was applied to practical classification problems, the results show that the generalization ability of the algorithm is greatly improved.
Key words: K-means clustering; XGBoost; ensemble algorithm; generalization ability
0 引言
近年来,随着数据科学的不断进步,XGBoost(eXtreme Gradient Boosting)算法被商业、网络、股票分析、电子产品等领域广泛应用[1]。XGBoost是一种在梯度提升算法(GBDT)基础上改进的学习算法[2],其特点为复杂度低、并行效果好、计算精度高[3],但其泛化能力有待提升。本文选择Bagging多模型融合思想, 采用多个XGBoost基分类器,使得每个基分类器只拟合部分样本下的部分特征属性,然后用Kmeans聚类,进而提升其泛化能力。
其思路为:首先,抽取样本训练多个XGBoost基分类器模型,然后,采用Kmeans算法聚类多个基分类器模型中的实验结果,最后,集成每个分类簇中泛化能力最优的基分类器。
1 基于Kmeans聚类的XGBoost集成
1.1 Kmeans 聚类算法
Kmeans算法稳定性好,聚类效果佳,而且与数据的输入顺序无关,乱序处理时,可获得同样的结果,可很大程度上避免乱序带来的烦扰,是一种经典的聚类算法[4]。
1.1.1 Kmeans算法思路
先在数据集中随机选取[K]个样本为聚类初始中心点;然后计算其余所有样本与[K]个样本点的欧式距离,比较样本点与[K]个中心点的[K]个距离值,离哪个中心点距离最近就归为哪一类;之后重新计算簇中心点,并且一直重复前面的步骤,直到簇中心点位置收敛时结束。
1.1.2 Kmeans算法步骤
⑴ 选点:从样本中随机选取[K]个样本作为初始中心点;
⑵ 归类:计算其余样本与[K]个样本点的欧氏距离并比较,将样本与距离最近的中心点归为一类;
⑶ 计算:重新计算簇中心点,一直重复前面的步骤, 直到簇中心点的位置收敛时结束。
1.2 XGBoost算法
XGBoost是由Tianqi Chen等2015年提出,在GBDT基础上,加入目标函数的二次泰勒展开项和模型复杂度的正则项[5],使得目标函数与实际数据相差更小,达到减少数据误差,提高预测准确度的一种算法。该方法计算精度高,并行效果好,具有很好的解释性,在工业界中得到了广泛的应用。具体思路如下:
1.3 Bagging集成
Bagging是经典的集成学习方法[6],是通过综合多个弱学习器的学习结果,共同完成同一个学习任务的过程。其集成原理为:有放回重复抽取[N]个样本集,每个样本集中有[M]个样本,分别训练[N]个学习模型,从而获得[N]个弱学习器[7]。
其具体算法如下:
⑴ 在原数据集中有放回任意抽取[M]个样本,共进行[N]次,获得具有[M]个样本的[N]个样本集;
⑵ 将[N]个样本集分别对应训练成[N]个弱学习模型,得到[N]个弱学习器;
⑶ 将[N]个弱学习器输出结果对应投票,得到最终分类结果。
1.4 基于Kmeans聚类的XGBoost基分类器集成算法
为了在采用XGBoost提升模型精度的同时,进一步提高模型泛化能力,本文融入了Kmeans和Bagging的思想,提出了基于Kmeans聚类的XGBoost基分类器集成算法,具体流程如图1所示。
算法具体步骤如下:
① 对训练集[D]有放回任意抽取[M]个样本,获得具有[M]个样本的样本集;
② 训练基分类器[hn],得到样本的训练结果;
⑷ 将步骤⑶中的[N]个基分类器的结果用Kmeans聚类,选出每个分类簇下的最佳基分类器;
⑸ 对选出的多个最佳基分类器的输出结果根据简单投票法投票,输出最终预测结果。
2 实验结果与分析
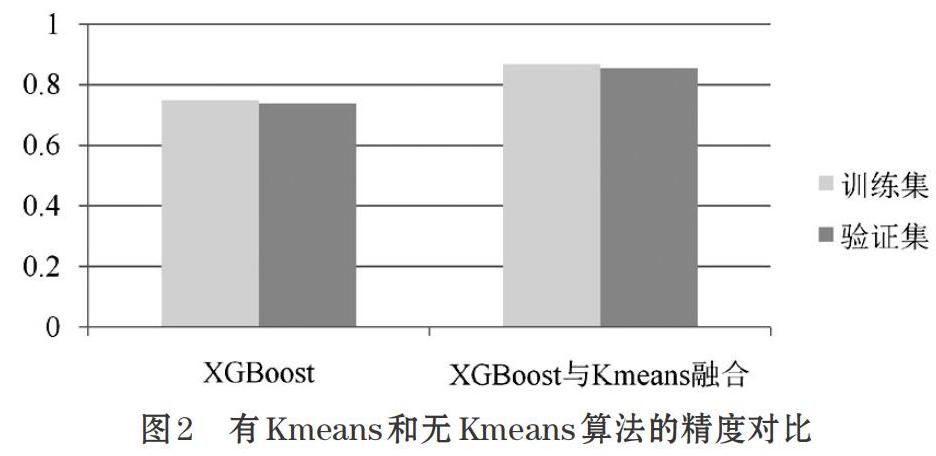
本文数据集样本量为689945个数据,共有51个特征。对数据进行分类后,所得预测结果精度对比如图2所示。
从结果可知,通过多XGBoost模型集成的数据经Kmeans聚类后,整体的泛化能力得到了提升。
3 结束语
文中提出的基于Kmeans聚类下的XGBoost集成算法研究,采用多个XGBoost基分类器,每个基分类器只拟合部分样本下的部分特征属性增加其差异性,从而提升整体算法的泛化能力。通过实验结果可知,Kmeans聚类的XGBoost集成算法在提高训练精度的同时提高了算法的泛化能力。
参考文献(References):
[1] 蒋晋文,刘伟光.XGBoost算法在制造业质量预测中的应用[J].智能计算机与应用,2017.7(6):58-60
[2] 谢冬青,周成骥.基于Bagging策略的XGBoost算法在商品购买预测中的应用[J].现代信息科技,2017.1(6):80-82
[3] 王燕,郭元凯.改进的XGBoost模型在股票预测中的应用[J].计算机工程与应用,2019.55(20):202-207
[4] 魏杰.基于K-means聚类算法改进算法的研究[J]. 信息通信,2018.5:14-15
[5] 徐樹乔.基于XGBoost的Bagging方法的电信客户流失预测应用研究[D].华南理工大学硕士学位论文,2019.
[6] 元慧,王文剑,郭虎升.一种基于特征选择的SVM Bagging集成方法[J].小型微型计算机系统,2014.35(11):2533-2537
[7] 蒋芸,陈娜,明利特,周泽寻,谢国城,陈珊.基于Bagging的概率神经网络集成分类算法[J].计算机科学,2013.40(5):242-246
