
Reinforcement Learning Based Data Fusion Method for Multi-Sensors
2020-11-05 09:36TongleZhouMouChenandJieZou
Tongle Zhou,Mou Chen,,and Jie Zou
Abstract—In order to improve detection system robustnessand reliability, multi-sensors fusion is used in modern air combat. In this paper,a data fusionmethod based on reinforcement learning is developed for multi-sensors. Initially, the cubic B-spline interpolation is used to solve time alignment problems of multisource data. Then, the reinforcement learning based data fusion(RLBDF)method is proposed to obtain the fusion results. W ith the case that the priori know ledge of target is obtained, the fusion accuracy reinforcement is realized by the error between fused value and actual value. Furthermore, the Fisher information is instead used as the reward if the priori know ledge isunable to be obtained. Simulations results verify that the developed method is feasible and effective for the multi-sensors data fusion in air combat.
I.In t roduction
AFTER several decades of development,modern m ilitary technology has become increasingly mature and is w idely used in air combat.In particular,the application of artificial intelligence technology,such as stealth aircraft leads to more complicated air combat environments[1].To obtain reliable and effective information in such environments,multi-sensors systemsare used for data processing.Compared w ith single sensor systems,multi-sensors system can improve system robustness,increase the detection range and ensure detection accuracy by data fusion.However,in the process of target detection,measurement data is affected by the sensors noises and disturbances in the surrounding environment,whichmay result in error and a certain percentage of outliers[2].Therefore,data fusion technologies are employed to solve this problem in air combat,and lay a foundation for decisionmaking.
In recent years,multi-sensors data fusion methods of air combat have undergone rapid development due to boosts in sensor data acquisition and computer calculation capabilities.An unscented Kalman filter algorithm was introduced in[3],which investigated the problem of estimation of the wheelchair position in indoor environments w ith noisy measurements.Reference[4]presented a sequential fusion estimation method for maneuvering target tracking in asynchronous w ireless sensor networks.In[5],an assistant system of sub-station based on multi-sensors networks were studied through the improvement of evidence theory based fusion algorithm in a smart sub-station,and multi-sensors information fusion was realized.A complete perception fusion architecture based on the evidential framework was proposed in[6]to solve the detection and tracking ofmoving objects problem by integrating composite representation and uncertaintymanagement.In[7], to dealw ith counter-intuitive results may come out when fusing the highly conflicting evidence,a method based on a new belief divergencemeasure of evidence and belief entropy was developed for multisensors data fusion.An improved method w ith priori know ledge based on reinforcement learning techniques was proposed in[8]for air combat data fusion.Whereas some of the above-mentioned works may lack timeliness and reliability,or require a great deal of prior know ledge,the actualair combat is constantly changing,and prior know ledge is hard to obtain.On the other hand,air combatenvironments are difficult to describe w ith accurate mathematicalmodels.Under such cases,the developed reinforcement learning method can be employed to solve these problems.As one of the most active research areas in artificial intelligence,reinforcement learning has great advantages in solving learning and optim izing problems[9]–[11].Hence,reinforcement learning can improve the intellectualization of air combat data fusion systems by interacting w ith the air combat environment.As a field, reinforcement learning has progressed tremendously in the past decade,and has been w idely used in fields such as autonomous driving, humancooperativemanipulations,mobile edge caching and physical human-robot interaction [12]–[20].
Multi-sensors data fusion is a processwhich dealsw ith the association,correlation and combination of data based on information from multiple sources to achieve refined target information estimates.In this paper,the reinforcement learningmethod is used to improve the data fusion system of air combat.The main contributions lie in the follow ing aspects:
1) A data pre-processing method is raised before data fusion,which could solve the time alignment problem.
2)To improve the accuracy of data fusion systems,a data fusion approach based on reinforcement learning is designed w ithout priori know ledge by multi-sensors weight adjustment.
The structure of this paper is organized as follows.Section II formulates the problem.The data pre-processingmethod is studied in Section III.The reinforcement learning based data algorithm is introduced in Section IV.In Section V,we provide the simulation results.Finally,the conclusion is drawn in the last section.
II.Problem Descr iptions
As previously mentioned, the modern air combat environmenthas become increasingly complicated because of high-tech military technology.To improve the performance of information fusion systems,integrated space-air-ground information system are employed in modern air combat[21].Generally, the three types sensors consist of space-based platform sensors,air-based platform sensorsand ground-based platform sensorswhich are used to simultaneously detect the same target.The schematic diagram of integrated space-airground information systemsare shown in Fig.1[8].

Fig.1.The schematic diagram of integrated space-air-ground information system.
Due to the influence of sensor noise and air combat environment uncertainty,data detected by multi-sensors systems can not be directly used.In order to obtain optimal results,data fusion technologies are employed before air combatdecision-making.Hence,the objective of this paper is divided into two parts.The first part is to design a curve fitting algorithm to solve the time alignment problem.The second part is to design the state,action and reward of reinforcement learning and decide the optimal weightof each sensor based on reinforcement learning.
The flow diagram of the reinforcement learning based data fusion (RLBDF)system isshown as Fig.2.
III.Data Pre-processing

Fig.2.The flow diagram of RLBDFsystem.
In air combat data detection systems,due to advanced sensor varieties,the sample interval of integrated space-airground information system,including space-based platform sensors,air-based platform sensorsand ground-based platform sensors,are different[22].To obtain fusion results,it is indispensable to allow the data of different sample intervals to be unified in the same time space.Consequently,the time alignment should be considered before data fusion.In this paper,an approach based on cubic B-spline interpolation curve fitting is developed.The discrete observations detected by sensors w ith different sample intervals are fitted as a corresponding continuous curve.On that basis,the air target information atanymoment can be calculated according to the fitted curve.
The schematic diagram of a B-spline interpolation curve fitting isshown in Fig.3[23].
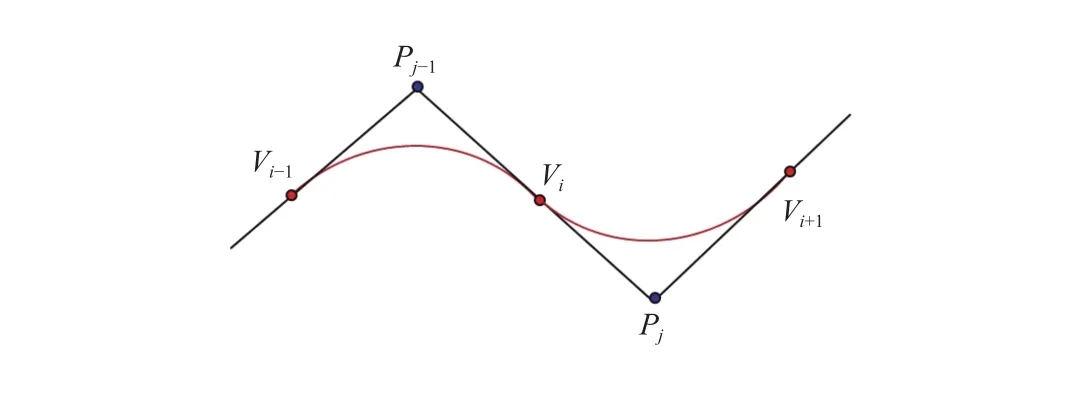
Fig.3.The schematic diagram of B-spline interpolation curve fitting.

On thisbasis,consider the boundary condition [24]

IV.Rein for cement Lea rning Based Da ta Fusion
The above stage solves the time alignment problem and the obtained fitted curves provide the basis for fusion of air combat.Then,the RLBDF method is studied in this section.During the reinforcement learning process,the system takes actions and makes a corresponding reward or punishment from the environment.The objective is to choose the optimal action w ith maximum reward by repeated attempts.The relationship between data fusion and reinforcement learning aremainly by the follow ing three stages[26]:
1)The target information is detected by the multi-sensors and a reinforcement signal is received by data fusion system.
2)The data fusion system takes a possible action related to the current observation and producesa reward.
3)The data fusion system makes a new fusion and updates theaccumulated reward.
A general structure for an air combat RLBDF system is shown in Fig.4.
Generally,due to theuncertainty of air combat,it isdifficult to find a model to describe air combat environments.-learning is a model-free form of reinforcement learning.Hence,in this paper,-learning algorithm is used to implement the reinforcement learning data fusion.The goal is to find the action which maxim izes reward to obtain the optimal fused value.
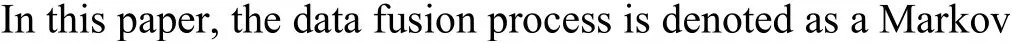
Fig.4.A general structure for air combat RLBDF system.

The reinforcement learning method is used for weight updating.The system can adapt the weights for each observation.In summary, three components are defined:states,actionsand reward of reinforcement learning.
A. Data FusionWith Priori Know ledge


Algorithm 1Q-learning for data fusion w ith priori know ledge in air combat Input:The observations of multi-sensors,,initial weights, the actual value of target ,the maximum number of iterationsimages/BZ_30_353_2460_420_2498.pngand the error threshold ;Output:The optimalset of weights,fused data;images/BZ_30_910_2363_943_2396.pngimages/BZ_30_971_2363_1079_2396.pngimages/BZ_30_1098_2363_1135_2396.pngimages/BZ_30_786_2422_815_2447.png images/BZ_30_779_2472_808_2497.png1:Initialize w ith random weights,images/BZ_30_908_2561_1030_2602.pngimages/BZ_30_1040_2561_1087_2602.png ,set parameters and of air combat data fusion system;images/BZ_30_421_2564_500_2598.pngimages/BZ_30_842_2573_888_2602.pngimages/BZ_30_453_2623_474_2648.pngimages/BZ_30_547_2615_563_2644.png2:for toimages/BZ_30_442_2662_555_2699.pngdoimages/BZ_30_332_2665_394_2694.png 3:Initialize state ,images/BZ_30_604_2712_1054_2753.png;images/BZ_30_561_2724_586_2749.png4:while doimages/BZ_30_435_2766_602_2799.png5:action in state;images/BZ_30_378_2824_444_2849.png images/BZ_30_671_2824_696_2849.pngimages/BZ_30_555_2874_580_2899.pngimages/BZ_30_725_2866_750_2895.png6:Take action ,observe (next available state ),images/BZ_30_364_2913_655_2951.png;images/BZ_30_1070_2866_1095_2895.png7:images/BZ_30_378_2967_1086_3017.png8:, optimal weights that maxim ize and in stateimages/BZ_30_377_3029_411_3054.pngimages/BZ_30_439_3029_547_3054.pngimages/BZ_30_547_3029_622_3054.pngimages/BZ_30_1150_3020_1250_3054.png images/BZ_30_436_3079_457_3104.png images/BZ_30_583_3079_608_3104.png9:optimalnew state ,images/BZ_30_763_3118_863_3155.png;images/BZ_30_378_3129_432_3150.pngimages/BZ_30_715_3129_744_3150.png

10:end while 11:end for 12:return ,images/BZ_30_1555_360_1663_397.png;fused data .images/BZ_30_1503_371_1536_396.png images/BZ_30_1663_371_1700_396.png images/BZ_30_1882_371_1907_396.png
B. Data FusionWithout Priori Know ledge


Using the new reward definition,the data fusion w ithout actual value algorithm is summarized in Algorithm 2.What needs to be pointed out is that the state definition and action definition are sim ilar to the data fusion w ith actual value algorithm.

Algorithm 2Q-learning for data fusion w ithout priori know ledge in air combat Input:The observations of multi-sensors,,initial weightsand the maximum number of iterationsimages/BZ_31_923_862_990_899.png;Output:Theoptimalset of weights,fused data;images/BZ_31_923_815_956_848.pngimages/BZ_31_987_815_1095_848.png images/BZ_31_1095_815_1132_848.png1:Initialize w ith random weights,,set parameter and of air combat data fusion system;images/BZ_31_423_966_502_999.pngimages/BZ_31_848_974_894_1003.pngimages/BZ_31_915_974_1036_1003.pngimages/BZ_31_1048_974_1094_1003.pngimages/BZ_31_476_1025_497_1050.pngimages/BZ_31_569_1016_586_1045.png2:Initialize state,images/BZ_31_539_1063_980_1104.png;images/BZ_31_495_1075_520_1100.png3:for toimages/BZ_31_442_1114_555_1151.pngdoimages/BZ_31_332_1117_394_1146.png 4:action in state ;images/BZ_31_340_1176_407_1201.png images/BZ_31_634_1176_659_1201.png5:Take action ,observe next available state and calculate according to(17); images/BZ_31_535_1226_560_1251.pngimages/BZ_31_1014_1218_1039_1247.png images/BZ_31_354_1277_375_1302.png6:images/BZ_31_340_1319_1057_1369.png7:images/BZ_31_343_1369_377_1406.png,images/BZ_31_397_1369_506_1406.png optimalweights thatmaxim ize and in state ;images/BZ_31_506_1381_581_1406.pngimages/BZ_31_1072_1372_1185_1406.png images/BZ_31_354_1431_375_1456.png images/BZ_31_501_1431_526_1456.png8:optimal new state ;9:end forimages/BZ_31_340_1481_403_1506.pngimages/BZ_31_686_1481_715_1502.png10:return ,images/BZ_31_459_1571_567_1608.png;fused data .images/BZ_31_407_1582_440_1607.png images/BZ_31_567_1582_605_1607.png images/BZ_31_787_1582_812_1607.png
Remark 1:The data fusion system receives data from different sensors and broken sensors may lead to two conditions.If broken sensors can not detect the target,then the data fusion system also can not receive the data,and works w ith the data received by other available sensors.If the broken sensors receive the dataw ith large errors,in the reinforcement learning process, the action that decreases the broken sensors weights w ill be selected.Hence,the percentage of those broken sensors in fused data w ill be decreased.
V.Simu la tion Resu l ts
In this section,the simulation results are given to validate the performance of the RLBDFalgorithm.
It is assumed that four radars are used to simultaneously detect the same target RCS information and the time interval of each radar may be different.The actualvalue of target RCSs0=5.55m2.The time intervalof radar1,radar 2, radar 3 and radar 4 areT1= 1.0 s,T2= 0.8 s,T3= 1.2 sandT4= 1.5 s.
The simulation observations(target RCS information/m2)areshown in Tables I– IV.
The results of curve fitting based on cubic B-spline interpolation areshown as Figs.5−8.
Then,in the continuous fitted curve,the value of target information can be calculated at any moment.
We chooset1=5.0 s,t2=10.0 s,t3=15.0 s andt4=20.0 s,the corresponding fitted value are shown in Table V.radar 3 and radar 4,is the fused value of target RCS that the possibleaction isperformed.


TABLE I The Obser va tions of Radar 1

TABLE II The Obser va tions of Radar 2

TABLE III The Observations of Rada r 3

TABLE IV The Observations of Rada r 4

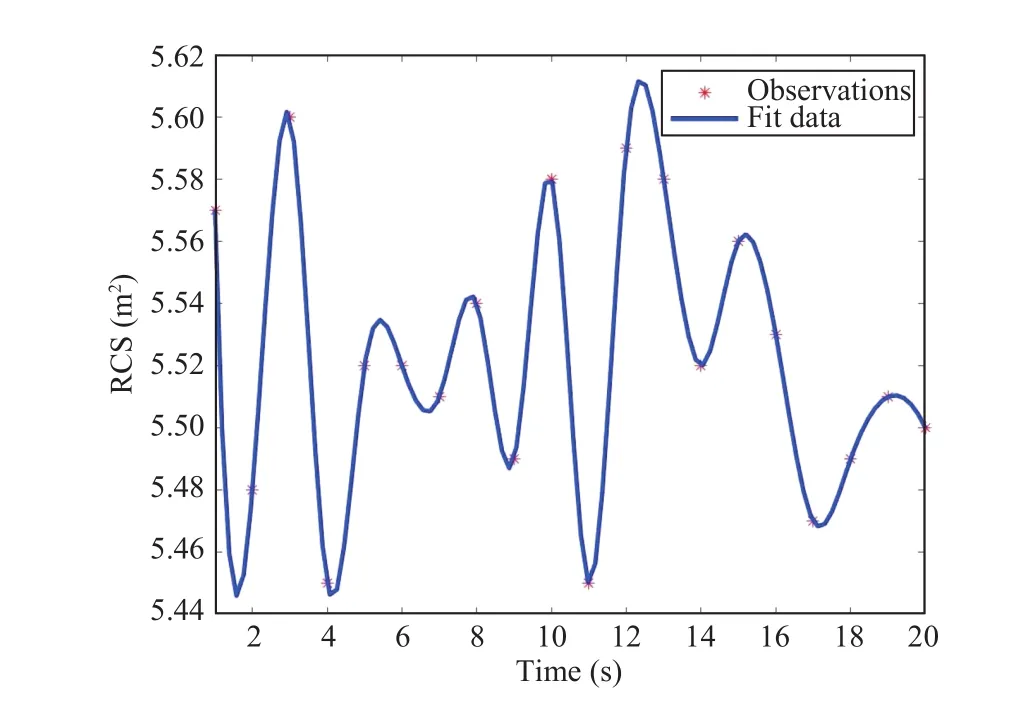
Fig.5.The curve fitting result of radar 1.

Fig.6.The curve fitting result of radar 2.

Fig.7.The curve fitting result of radar 3.


Fig.8.The curve fitting result of radar 4.

TABLE VI The Actions in RLBDF System W ith Four Rada rs

TABLE V The Fit ted Data of Th ree Sensor s at Fixed Time
The system learning by the reward of each state and the corresponding state of maximum reward is selected as state.
The simulation results of weight selection are shown in Table VII.
To evaluate the performance of the proposed method,we compare the follow ing strategies:
1) Random:This algorithm serves as the baseline by just selecting theweights foreach time random ly.It does not need any information from theobservationaldataset.
2) EEM(Expert experience method):This algorithm determ ines theweightsby utilizing the expert’sknow ledge.
3) BE(Bayesian estimation):The fused data is obtained by mathematical statistics in this algorithm.According to the prior know ledge and probability distributions, themaximum likelihood estimator is the desired fused data [32].
4) RL with priori know ledge:This is the reinforcement learningmethod developed in Section IV, which uses the error between fused data and actual value to guide us select the weights.
5) RL without priori know ledge:This is also the reinforcement learning method developed in Section IV.The difference is the priori know ledge is not needed; the Fisher information is instead used as the reward of reinforcement learning.
The simulation results of data fusion is shown in Tables VII and VIII.The fused data curve and error curve are shown in Figs.9 and 10.
From the simulation results,it is illustrated that the weights of multi-sensors have influence on the accuracy of data fusionsystem.Through weights adjustment of multi-sensors,the available fused value can beobtained.Additionally,compared w ith other algorithms,the RLBDF algorithm has better fusion results and less error.Themain reason is that reinforcement learning develops fusion strategies according to observations.From the observations of four radars,it is obvious that the measure performance of radar 3 isbetter than radar 1,radar 2and radar 4.Thus,the weight of radar 3 makes up a greater percentage in the data fusion results.The results verify the effectiveness of the developed method under the conditions w ith or w ithout the priori know ledge in air combat multisensorsdata fusion.

TABLE VII TheWeigh t of Four Sensors a t Fixed Time

TABLE VIII The Fit ted Data of Fou r Sensors at Fixed Time

Fig.9.Fused data curve.
VI.Conc lusion

Fig.10.Error curve.
To improve detection system robustness and dependability,multi-sensors fusion is used inmodern air combat.Due to the diversity of multi-sensors function,the data detected bymultisensors can not be directly used.In this paper,to solve the time alignment problem,a cubic B-spline interpolation is employed to obtain a fitting curve based on observations before data fusion.Then,theRLBDFmethod is proposed.The data fusion system takes actions(weight adjustment)to reach different states(different fused value).The reinforcement signal is provided by the error between observations and actual value in the cases w ith priori know ledge.If the priori know ledge can not be obtained,the reward is designed by Fisher information.The simulation result shows that reinforcement learning technology can overcome the shortcom ings of traditional methods which depend on subjective experience excessively and improve the accuracy of data fusion system in air combat.
 IEEE/CAA Journal of Automatica Sinica2020年6期
IEEE/CAA Journal of Automatica Sinica2020年6期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Parallel Control for Optimal Tracking via Adaptive Dynamic Programming
- Sliding Mode Control for Nonlinear Markovian Jump SystemsUnder Denial-of-Service Attacks
- Neural-Network-Based Nonlinear Model Predictive Tracking Controlof a Pneumatic Muscle Actuator-Driven Exoskeleton
- Single Image Enhancement in Sandstorm Weather via Tensor Least Square
- Understanding Nonverbal Communication Cues of Human Personality Traits in Human-Robot Interaction
- A Behavioral Authentication Method for Mobile Based on Browsing Behaviors