
自动驾驶中基于卷积神经网络的行人检测研究
2020-11-02 02:34杨康陈丽
电脑知识与技术 2020年25期
关键词:卷积神经网络
杨康 陈丽

摘要:针对行人检测中检测精度低和速度慢的问题,文章提出了一种改进的U-NET网络架构。为了提高系统的检测精度,采用了多尺度融合技术来构建多层卷积神经网络(CNN)。为了提高检测速度,改善了网络结构的特征通道数量,减少了大量的计算时间,以满足自动驾驶领域数据处理的实时性。在训练阶段,使用批归一化(BN)算法对每一层的输入数据进行归一化,以加快模型的收敛速度。实验结果表明,改进的网络模型可以在保证一定的检测精度的前提下,提高系统的检测速度,并满足实时性要求。
关键词:行人检测;多尺度融合;卷积神经网络;批量归一化
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2020)25-0022-03
Abstract: In this paper, an improved U-NET network architecture is proposed to solve the problems of low detection accuracy and slow detection speed in pedestrian detection. To improve the detection accuracy of the system, a multi-scale fusion technology is used to build a multi-layer convolutional neural network (CNN). To improve the detection speed, the number of feature channels in the network framework was modified, and a large amount of calculation time was reduced to meet the real-time nature of processing data in the field of autonomous driving. In the training phase, a batch normalization (BN) algorithm is used to normalize the input data of each layer to accelerate the model's convergence speed. The experimental results show that the improved network model can improve the detection speed of the system under the premise of ensuring a certain detection accuracy, and meet the real-time requirements.
Key words: Pedestrian detection; Multi-scale fusion; Convolutional neural network; Batch normalization
1 引言
随着深度学习的发展[1],作为计算机视觉的重要分支[2],行人检测受到了学术界和工业界的广泛关注。在汽车智能驾驶领域具有广阔的应用前景。目前,常用的行人检测算法模型有R-CNN、Fast R-CNN和Faster R-CNN[3],随着网络结构的优化和调整,其检测精度在逐渐增高,但是网络结构随之变得复杂,导致计算量大幅增大,因而其检测速度变慢,无法满足自动驾驶领域的实时性要求[4]。
传统的卷积神经网络由卷积层、池化层[5]、全连接层和分类层组成,网络经过一系列的卷积和池化操作后,输入图像被映射为固定大小的特征向量。最后,分类器基于输入特征向量执行图像的分类。全卷积神经网络(FCN)是在卷积层的特征图上执行上采样操作,可以有效地保留图像的空间尺寸信息,并对图像进行精确分割[6]。
而本文提出的改进的U-NET网络则是在U-NET网络的基础上,对网络的结构和参数进行适当的改进,利用多尺度融合技术和批量归一化算法,对COCO数据集进行训练,从而实现行人的快速检测与分割。
2 相关工作
2.1 U-NET网络结构
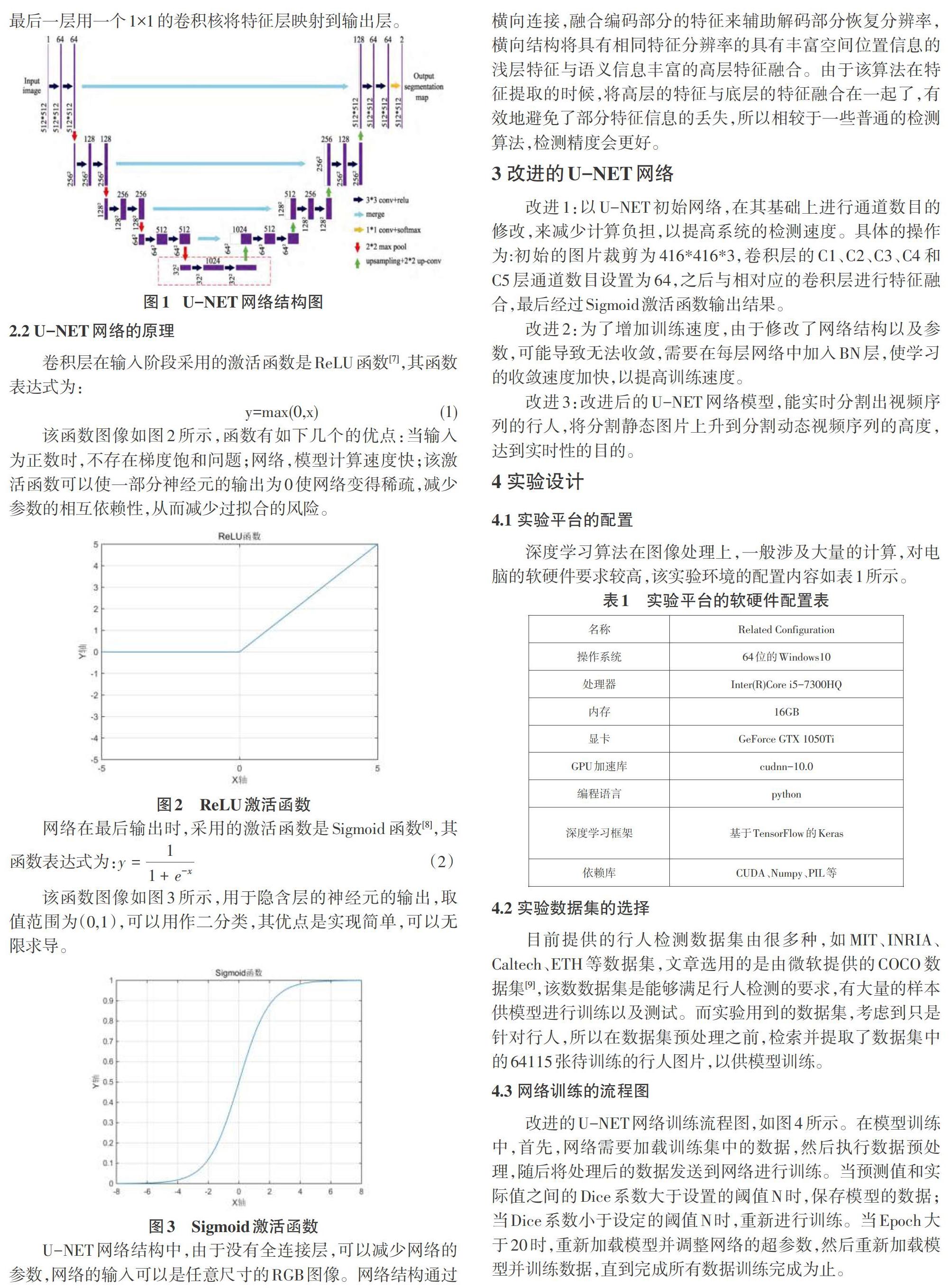
U-NET网络是一个全卷积的网络,由于结构类似于U形,因此称为U-NET网络,该网络由左侧的编码单元和右侧的解码单元组成,U-NET网络结构如图1所示。
在编码单元,使用2个3×3的卷积层,在卷积层后面再加上一个ReLU非线性层,进行下采样过程中,使用2×2的最大池化层,每次下采样后,特征通道数会增加2倍;在解码单元,每一次上采样过程用2×2的反卷积层来实现尺寸的倍增,并且伴随着当前层的特征通道数的减少,然后将编码单元的特征复制到相应的解码单元上,继续用2个3×3的卷积核进行特征的提取,最后一层用一个1×1的卷积核将特征层映射到输出层。
U-NET网络结构中,由于没有全连接层,可以减少网络的参数,网络的输入可以是任意尺寸的RGB图像。网络结构通过横向连接,融合编码部分的特征來辅助解码部分恢复分辨率,横向结构将具有相同特征分辨率的具有丰富空间位置信息的浅层特征与语义信息丰富的高层特征融合。由于该算法在特征提取的时候,将高层的特征与底层的特征融合在一起了,有效地避免了部分特征信息的丢失,所以相较于一些普通的检测算法,检测精度会更好。
3 改进的U-NET网络
改进1:以U-NET初始网络,在其基础上进行通道数目的修改,来减少计算负担,以提高系统的检测速度。具体的操作为:初始的图片裁剪为416*416*3,卷积层的C1、C2、C3、C4和C5层通道数目设置为64,之后与相对应的卷积层进行特征融合,最后经过Sigmoid激活函数输出结果。
改进2:为了增加训练速度,由于修改了网络结构以及参数,可能导致无法收敛,需要在每层网络中加入BN层,使学习的收敛速度加快,以提高训练速度。
改进3:改进后的U-NET网络模型,能实时分割出视频序列的行人,将分割静态图片上升到分割动态视频序列的高度,達到实时性的目的。
4 实验设计
4.1 实验平台的配置
深度学习算法在图像处理上,一般涉及大量的计算,对电脑的软硬件要求较高,该实验环境的配置内容如表1所示。
4.2 实验数据集的选择
目前提供的行人检测数据集由很多种,如MIT、INRIA、Caltech、ETH等数据集,文章选用的是由微软提供的COCO数据集[9],该数数据集是能够满足行人检测的要求,有大量的样本供模型进行训练以及测试。而实验用到的数据集,考虑到只是针对行人,所以在数据集预处理之前,检索并提取了数据集中的64115张待训练的行人图片,以供模型训练。
4.3 网络训练的流程图
改进的U-NET网络训练流程图,如图4所示。在模型训练中,首先,网络需要加载训练集中的数据,然后执行数据预处理,随后将处理后的数据发送到网络进行训练。当预测值和实际值之间的Dice系数大于设置的阈值N时,保存模型的数据;当Dice系数小于设定的阈值N时,重新进行训练。当Epoch大于20时,重新加载模型并调整网络的超参数,然后重新加载模型并训练数据,直到完成所有数据训练完成为止。
4.4 算法的评价指标
算法的好坏需要用合适的评价标准去判断,好的评估标准不仅能客观地评价算法性能,还能够进一步指导算法的改进方向。
由于采用的是改进的U-NET网络,来分割待检测图片中的行人,所以在评价该检测算法指标的时候用Dice系数。
4.5 优化函数的选取
深度卷积神经网络的训练算法有很多种,其优化函数常用的有经典的随机梯度下降法(Stochastic Gradient Descent,SGD)、自适应梯度算法(Adaptive Gradient,AdaGrad)和自适应矩估计算法(Adaptive Moment Estimation)。
在卷积神经网络中,而对于深度学习来说,需要的训练集较大才能训练出优秀的网络模型。实验采用的COCO数据集属于庞大的行人数据集,对于庞大的数据量,一次迭代过程来加载整个训练集,会加大显卡的计算负荷,其次,计算需要很长的时间,降低了网络的收敛速度。
为了解决这个问题,提出了基于动量的优化算法,最终采用Adam优化函数[10],Adam是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络的权重。
Adam算法有如下几个优点:(1)有高效的计算,所需的内存少,适合解决大规模数据和参数的优化问题。(2)超参数能直观的解释,因为Adam是给每个参数计算不同的更新速率的方法,经过偏置校正后,每次迭代的学习率都有一个确定的范围,使得参数比较平稳。(3)有惯性保持的效果,因为该算法记录了梯度的一阶矩,即以前的所有梯度与当前梯度的平均,使每一次更新时,上一次更新的梯度与当前更新的梯度不会相差过大,因而梯度会平滑且稳定的过渡,可以广泛应用于不稳定的目标函数的优化。
5 结论
改进后的U-NET网络,在训练完从训练集提取出来全部的64115张行人照片后,在训练过程中,损失以及训练的准确率曲线如图5所示。
图中曲线反映了在训练集和测试集中损失的变化和准确率的变化。由训练以及测试结果可得:在训练集中,该网络模型经过训练后,准确率达到0.953,在测试集中,准确率也可以到达0.928;在训练集中,损失函数无限接近于0,但是在测试集中,损失函数在0.1附近。
下图为改进的模型训练后检测行人并分割的几组照片,检测结果如图6所示。
实验结果表明:改进后的模型检测单张照片的时间约为0.38秒,有时检测速度会突破到0.1秒以内,与普通的U-NET网络相比,检测单张照片的时间缩短了很多(普通U-NET模型检测时间约为1秒),所以改进后的网络结构保证了检测精度的情况下,确实提高了系统的检测速度。
参考文献:
[1] LeCun Y,Bengio Y,Hinton G.Deep learning[J].Nature, 2015,521(7553):436-444.
[2] Viola P,Jones M J.Robust real-time face detection[J].International Journal of Computer Vision, 2004,57(2):137-154.
[3] Ren SQ,HeKM,Girshick R,etal.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[4] 王若辰.基于深度学习的目标检测与分割算法研究[D].北京:北京工业大学,2016.
[5] 李旭冬,叶茂,李涛.基于卷积神经网络的目标检测研究综述[J].计算机应用研究,2017,34(10):2881-2886,2891.
[6] Wang W G,Shen J B,Shao L.Video salient object detection via fully convolutional networks[J].IEEE Transactions on Image Processing,2018,27(1):38-49.
[7] 王红霞,周家奇,辜承昊,等.用于图像分类的卷积神经网络中激活函数的设计[J].浙江大学学报(工学版),2019,53(7):1363-1373.
[8] 刘长征,张磊.语音识别中卷积神经网络优化算法[J].哈尔滨理工大学学报,2016,21(3):34-38.
[9] 余胜,陈敬东,王新余.基于深度学习的复杂场景下车辆识别方法[J].计算机与数字工程,2018,46(9):1871-1875,1915.
[10] 董洲洋,徐卫明,庄昊,等.深度学习的BP神经网络在GNSS水准拟合中的应用[J].海洋测绘,2019,39(5):26-29.
【通联编辑:唐一东】
猜你喜欢
科技创新与应用(2017年5期)2017-03-16
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
