
云计算环境中HDFS数据块存储策略研究
2020-11-02 02:36袁爱平陶志勇邓河陈为满
电脑知识与技术 2020年26期
袁爱平 陶志勇 邓河 陈为满
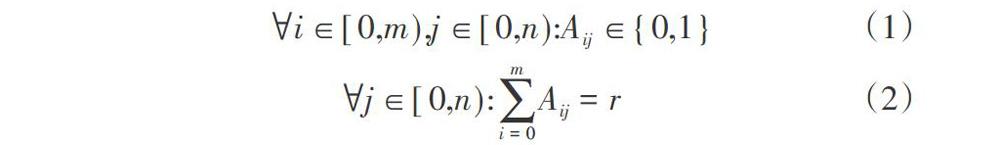
摘要:HDFS(Hadoop Distributed File System)以流式数据访问模式存储超大文件,具有高可靠性、高扩展性、低成本等特性,已广泛运行于商用硬件集群中。但在云计算系统中,由于采用了虚拟化技术,文件存储时如采用HDFS默认的存储策略,将带来数据可靠性的下降。本文通过对HDFS存储方法的改进,提出了一种充分考虑云环境中虚拟机存储位置的数据块存储策略,避免了多个数据块副本存储在同一台物理机器上。实验结果证明,该方法均衡了数据块在物理节点中的存储,提高了系统的可靠性。
关键词:云计算;HDFS;位置感知;数据存储
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2020)26-0033-03
Abstract: HDFS (Hadoop Distributed File System), which stores large files in streaming data access mode, has the characteristics of high reliability, high scalability and low cost, and has been widely used in commercial hardware clusters. However, in the cloud computing system, due to the virtualization technology, if the default storage strategy of HDFS is used in file storage, the data reliability will be reduced. Through the improvement of HDFS storage method, this paper proposes a data block storage strategy that fully considers the storage location of virtual machine in cloud environment, avoiding multiple data block copies stored on the same physical machine. Experimental result shows that this method balances the placement of data blocks in physical nodes and improves the reliability of the system.
Key words: cloud computing; HDFS; location awareness; data storage
随着信息技术的快速发展,各种应用系统正在以前所未有的速度产生出大量的数据,怎样对这些数据进行高效处理已成为人们迫切关注的问题。Google公司研究提出了MapReduce并行计算模型和方法,以简单方便地完成大规模数据的编程和计算处理。受到Google公司MapReduce思想的影响,开源系统Hadoop也在内部实现了MapReduce计算框架,以一种可靠、高效、可伸缩的方式处理海量数据。Hadoop不要求集群中的机器高配置,大部分普通商用服务器就可以满足要求,它通过提供多个副本和容错机制来提高集群的可靠性。为了满足大数据应用对资源的动态需求,将大数据系统部署到云计算平台中已成为目前的一种趋势。云计算平台资源分配灵活,能够实现“按需获取”,方便了广大中小型企业或者个人对大数据应用的使用。
1 HDFS存储系统
HDFS是一个以分布式方式存储的文件系统,主要负责数据的存储与读取,它运行于商用硬件集群上,单个 HDFS 集群可以扩展至几千甚至上万个节点[1]。HDFS集群是一个主/从结构的分布式文件系统,有一个NameNode节点和多个DataNode节点。NameNode节点管理文件系统的元数据和控制着外部客户机的访问,DataNode节点则是文件系统的工作节点,它是真正存储数据的地方。为了安全起见,在集群中通常还有一个Secondary NameNode节点,用于备份NameNode中的数据。HDFS和磁盘一样,以数据块作为数据读/写的最小单位,默认为64MB,这样做的目的是最小化寻址开销。用户存储在HDFS中的文件被划分成几个数据块,分布式地存储在DataNode节点上。
HDFS存储数据块的副本时,它会尽量使副本放置在不同机架下面的DataNode节点中,以保证数据的可靠性。当副本数是3时,HDFS的默认存储策略是把第1个副本放在客户端机器上,第2个副本放在与第1个副本不同机架下的节点中,第3个副本放在与第2个副本相同机架下且随机选择的一个节点中。当副本数超过3时,其他副本则会放在集群中随机选择的节点上,不过系统会尽量避免在相同的机架上放太多副本。一旦选定副本的放置位置,就会根据网络拓扑创建一个管线。总的来说,这一方法不仅提供很好的稳定性并实现了负载均衡,包括写入带宽、读取性能和集群中块的均匀分布。
对于同构环境的物理集群,HDFS的默认数据块存储策略能够保证数据的可靠性,而在基于虚拟技术的云计算平台中,同一个物理机器里面会共存多个虚拟机,此时如把虚拟机节点当作物理机节点对待来存储数据,将带来数据可靠性的下降。
2 云中HDFS数据块存储设计
2.1 云中HDFS数据块存储研究现状分析
针对同构环境的数据放置策略不一定适合异构的云计算环境,学者们开展了广泛的研究。Zaharia等人[2]通过对集群计算框架中异常任务的检测优化,提高任务的备份成功率,从而提高云计算环境中数据的可靠性。针对云计算环境中网络资源的共享和竞争等问题,Lei[3] 针对数据块副本分发问题,提出了一种发现虚拟机内聚性的机制,并设计了一种新的基于聚类的虚拟环境副本排列和组合重执行调度技术,减少了任务的响应时间,降低了数据传输成本,而针对云中的节点异构性特点,Geng等人[4]从理论上分析了虚拟环境中的数据分配问题,设计了一种文件块分配策略,实现了更好的数据冗余和负载平衡,提高了应用程序的执行性能。与此同时,在地域异构的云数据中心,Chen等人[5] 建立了最优数据放置问题,提出了一种拓扑感知的启发式算法,构造了抽象树结构的副本平衡分布樹和细节树结构的副本相似度分布树,有效地降低全局数据访问成本,减少了意外的远程数据访问,提高了MapReduce在云数据中心的性能。通过总结可以发现,由于云计算环境的虚拟机节点失效常态化、异构性和虚拟网络拓扑结构多样性等特点,现有的数据存储策略具有一定的局限性。
2.2 感知虚拟机位置的数据块存储策略
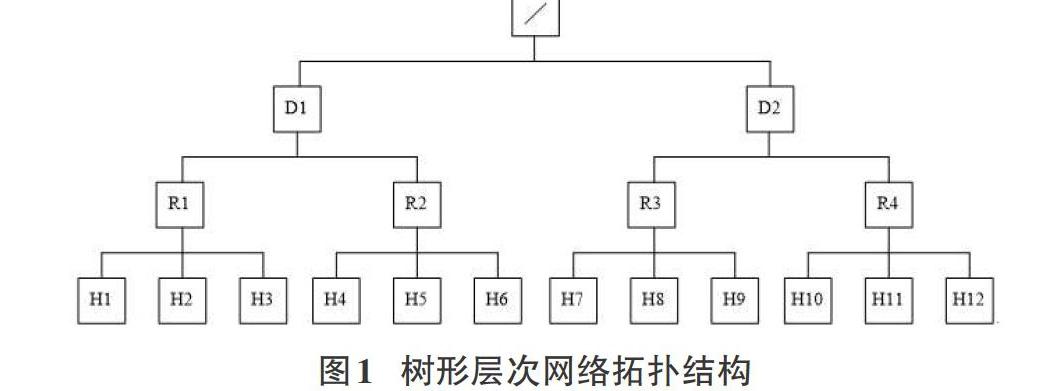
HDFS默认采用机架感知的策略分配数据块的存储位置,它支持树形的层次网络拓扑结构,如图1,其中D表示数据中心,R表示机架交换机,H表示数据存储节点。一个集群可能跨越多个数据中心,而每个数据中心又包含有多个机架交换机,各个物理机器节点位于机架交换机下面。通常情况下,同一个机架交换机的网络传输带宽比跨越不同机架交换机的数据交换带宽要高,即将同一个数据块的多个副本放置到同一个机架交换机内部时,能够减少数据写入和读取的时间,但是,若机架交换机发生故障,则将导致整个交换机内的物理机器不能与外通信,使得机架内部的数据不能被访问[6]。
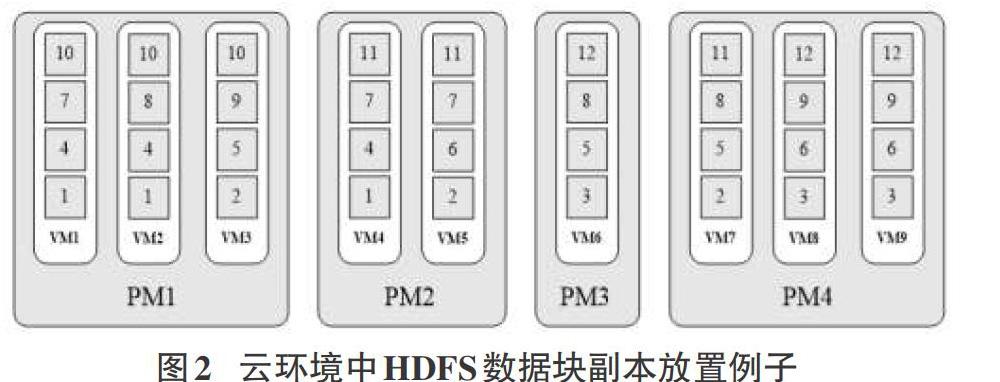
在云环境中,由于一个物理机器中包含多个虚拟机,当某个物理主机发生故障时,主机中的虚拟机节点都将不可用,也就意味着位于虚拟机中的同一个数据块的两个甚至多个副本会同时丢失。以图2为例,当物理机节点PM1发生故障时,位于PM1中的数据块10的所有副本都会丢失,导致文件存储的可靠性降低。
为了避免虚拟机共存对数据可靠性的影响,可以充分利用虚拟节点在物理宿主机中的位置信息来实现更好的数据块分配。定义任意两台虚拟机之间的网络距离如下:
在云环境中,一个Hadoop集群往往含有多个机架交换机,在交换机下面又包括多个物理服务器。假设有m个虚拟机节点存在物理服务器中,表示为(vm1, vm2, ..., vmm)。我们定义一个距离矩阵D标识不同虚拟机之间的网络距离,矩阵大小为m*m,Dij则对应了节点vmi和vmj的网络距离,它们之间的网络距离值如上定义。当客户端向集群写入数据块时,假设文件包含的数据块个数为n,副本的个数为r,则集群需要为每个数据块寻找r个节点位置,总共的位置个数为n*r。对于每个数据块,有可能放置到m个虚拟机节点中的任一个,则n个数据块可能放置的位置个数为n*m。我们定义一个数据块分布矩阵A,其中Aij表示数据块j是否被放置到了虚拟机节点vmi。为了加强数据块可靠性,定义如下的限制条件。
公式(1)限制了每个数据块至多只能有一个副本放置在同一个虚拟机节点中,公式(2)则限制了在m个虚拟机节点中,每个数据块应该有r个不同的副本。
当为某个数据块寻找副本存储位置时,需要查找距离矩阵D,从中找出满足数据可靠性限制条件的节点,作为该数据块的副本存储位置,处理流程如图3所示。
3 实验与结果分析
我们在基于OpenStack的私有云计算平台中构建了一个Hadoop集群环境,Hadoop版本为2.6.4。集群中包括1个NameNode节点和9个DataNode节点,所有节点均被配置为3个虚拟计算核,4GB的内存和50GB的磁盘空间。我们配置了2个千兆机架交换机,一个交换机下配置了3台物理机器,另一个交换机下配置了2台物理机器。我们使用RandomWriter工具生成4GB、8GB和16GB三个不同大小的数据集,并且使用不同的策略(HDFS默认策略和本文提出的优化策略)将它们写入HDFS集群中。在实验中数据块的大小被设置为64MB,副本因子为3。随后我们对不同数据集的数据可靠性指标进行了统计,结果显示采用HDFS的默认放置策略,几乎只有70%的数据块能够实现分配到不同的物理机节点之中,而基于本文提出的存储优化策略,100%的数据块都能被分配到不同的物理机节点中,意味着它们能达到与同构物理环境相同的可靠性,统计结果如表1。
4 结束语
本文通过对HDFS的数据存储和云计算环境中虚拟机资源调度的研究,分析了云环境中影响数据可靠性存储的因素,设计了一种基于位置感知的数据块存储策略,实现了不同副本的隔离放置。最后在OpenStack私有云计算平台通过实验进行了验证,结果表明与HDFS默认的数据块副本放置策略相比,本文提出的优化放置方法能够很好地把数据块副本分配到不同的物理机节点之中,提高了数据的可靠性。
参考文献:
[1] Konstantin S, Hairong K, Sanjay R, Robert C. The Hadoop Distributed File System[M]. In: Proc. of MSST. 2010: 1-10.
[2] Zaharia M, Chowdhury M, Franklin M. J, et al. Spark: cluster computing with working sets[C]//Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, 2010: 10.
[3] Lei L. Towards a high performance virtual hadoop cIuster[J]. Journal of Convergence Information Technology, 2018, 7(6): 292-303.
[4] Geng Y, Chen S, Wu Y, et al. Location-aware mapreduce in virtual cloud[C]//Parallel Processing(ICPP), 2018 International Conference[S.1.]:IEEE, 2018:275-284.
[5] Chen W, Paik I, Li Z. Tology-aware optimal data placement algorithm for network traffic optimization[J]. IEEE Transactions on Computers, 2016, 65(8): 2603-2617.
[6] 徐華. 基于云的大数据处理系统性能优化问题研究[D]. 合肥:中国科学技术大学,2018:55-59.
【通联编辑:梁书】
