
基于Python 图像处理技术的水质评价应用
2020-10-30 05:49杜琰琪
科学技术创新 2020年31期
杜琰琪
(安徽公安教育研究院,安徽 合肥230031)
1 Python 图像处理
Python 诞生于20 世纪90 年代初,是一种解释型、面向对象、动态数据类型的高级程序设计语言,因其具有较强的可移植性、可扩展性和丰富的代码库受到程序员的喜爱,在图像处理、数据统计和可视化表达等领域有着广泛的应用。在图像处理方面常用的包有CV2、PIL、Pillow、Pillow-SIMD。
2 需求分析
在水产养殖中,水质是至关重要的,需要时刻对水质进行监测,传统方式是由专家或有经验的由人进行评判,但这种方式,对个人经验要求很高,也会存在主观性偏差,因此重复性和推广性有一定的局限。我们希望根据水质图片,利用自动化手段,根据专家经验再结合机器学习算法、计算机视觉、数字图像处理等技术设计一个在线的水质监测系统,搭建一个模型对输入进来的图片进行水质类别的一个判断。
3 水质评价分析
通过历史样本数据,通过机器学习,数据分分析,把不同水质样本的特点探究、总结出来形成一个模型,当新样本进入模型后,模型能对新样本进行预测。具体流程如图1 所示:
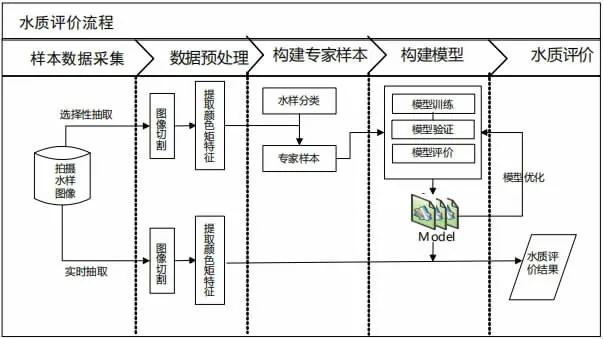
图1 水质评价分析流程
3.1 数据预处理图像切割
通过PIL Image.open()函数将图片转换为像素矩阵,r,g,b=im.split()将每个像素分成三个颜色通道,r_d=np.asarray(r) 取出各通道像素值。以图片的左上角为顶点,向右为横轴,向下为纵轴,设原始图像的大小是M*N,则截取宽从第到第个像素点,高从第个像素点到第个像素点的子图像。则提取的是水样图像中央101*101 像素的图像。原始图像和截取后子图像如图2 所示。

图2 截取图像对比
3.2 构建专家样本
图像的特征主要包括:形状特征、空间关系特征、颜色特征、纹理特征等。与几何特征相比,颜色特征表现出较强的鲁棒性,对于物体的大小和方向均不敏感。本应用中由于水色图像是均匀的,故主要关注颜色特征[2]。
根据图片反映出来的水色,引入专家知识将水质类别分为五类如表1,不同颜色代表不同的水质。

表1 水质类别
颜色直方图和颜色矩是反映图像特征的两种指标。颜色直方图能简单描述不同色彩在图像中所占的比例,适用于描述难以自动分割的图像和不需要考虑物体空间位置的图像,但对于图像中颜色的局部分布及每种颜色所处的空间位置却无法描述。颜色矩可以表示图像中颜色的分布,包括一阶矩、二阶矩和三阶矩,每种颜色具有R、G、B 三个颜色通道,因此颜色矩具有9 个分量[3]。颜色直方图产生的特征维数一般大于颜色矩阵的特征维数,为了避免过多变量影响后续的分类效果,在本应用中采用颜色矩来表达图像的特征。
采用二阶中心矩的平方根,求标准差,反映了图像颜色的分布均匀性、波动性,r2=rd.std()。
三阶颜色矩:
def var(rd): #求颜色通道的三阶颜色矩
mid = np.mean((rd-rd.mean())**3)
return np.sign(mid)*abs(mid)**(1/3)
3.3 数据提取及模型构建和训练
在Python 环境下通过调用相关函数,首先对采集的水质图像进行数据提取,然后对相应数据建立模型并对模型进行训练,获得水质评价效果。
3.3.1 数据提取过程
通过for 循环把所有照片的特征都提取出来,共获得197 行9 列的二维表数据如图3,部分数据结果如图4 所示。
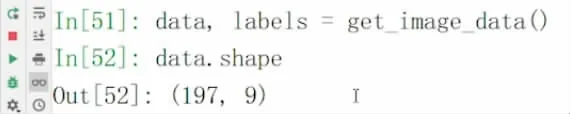
图3 获取数据量
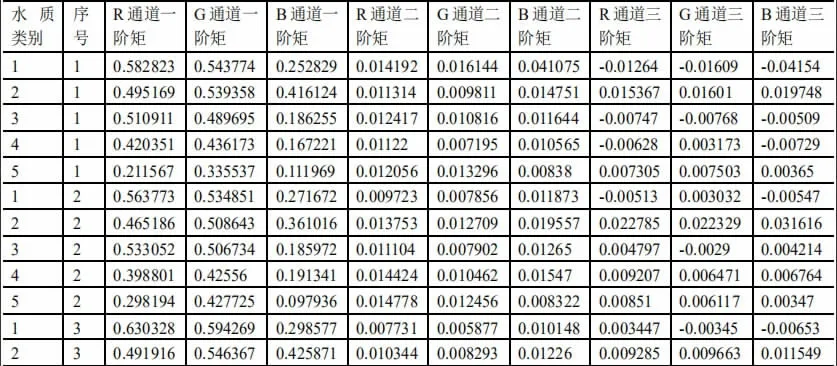
图4 获取的部分具体数据
获取每张图片R、G、B 三通道的三阶矩数据代码如下:
import os, re
from PIL import Image
import numpy as np
path = 'water_images/'
def var(rd): # 求颜色通道的三阶颜色矩
mid = np.mean((rd-rd.mean())**3)
return np.sign(mid)*abs(mid)**(1/3)
def get_img_names(path=path):
file_names = os.listdir(path)
img_names = []
for i in file_names:
if re.findall('^d_d+.jpg$', i) != []:
img_names.append(i)
return img_names
def get_img_data(path=path):
img_names = get_img_names(path=path)
n = len(img_names)
data = np.zeros([n, 9])
labels = np.zeros([n])
for i in range(n):
img = Image.open(path+img_names[i]) # 读取图片数据
M, N = img.size # 像素矩阵的行列数
region = img.crop ((M/2-50, N/2-50, M/2+50, N/2+50)) # 截取图像的中心区域
r, g, b = region.split() # 分割像素通道
rd = np.asarray(r) # 将图片数据转换为数组
gd = np.asarray(g)
bd = np.asarray(b)
data[i, 0] = rd.mean() # 一阶颜色矩
data[i, 1] = gd.mean()
data[i, 2] = bd.mean()
data[i, 3] = rd.std() # 二阶颜色矩
data[i, 4] = gd.std()
data[i, 5] = bd.std()
data[i, 6] = var(rd) # 三阶颜色矩
data[i, 7] = var(gd)
data[i, 8] = var(bd)
labels[i] = img_names[i][0]
return data, labels
3.3.2 模型构建与评价
抽取80%作为训练样本,剩下的20%作为测试样本,进行模型训练和模型的验证,模型在测试集样本上的精度为0.925,如图5 所示,基本满足实际应用需求。

图5 模型精度
模型构建与评价main 文件的主要代码如下:
from data_process import get_img_data # 导入数据预处里的函数
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
data, labels = get_img_data() # 数据预处理
data_train, data_test, labels_train, labels_test = train_test_split (data,labels, test_size=0.2) # 将专家样本拆分为训练集和测试集
dtc = DecisionTreeClassifier() #调用决策树分类器
dct.fit(data_train, label_train) # 模型训练
dct.score(data_test,label_test) # 模型性能评估
joblib.dump(dct,'dct_water_rec.m') # 将训练好的模型保存下来
model_new=joblib.load('dct_water_rec.m')
model_new.predict(data_test)
结束语
根据水质图片,利用图像处理技术和相应模型,在Python 环境下实现了水质的自动评价,正确率为92.5%,能实现预期功能,后期如需提高正确率,需要对模型进行优化。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
建材发展导向(2021年9期)2021-07-16
红领巾·萌芽(2019年8期)2019-08-27
建材发展导向(2019年10期)2019-08-24
电子制作(2018年14期)2018-08-21
北京航空航天大学学报(2017年4期)2017-11-23
知识文库(2017年21期)2017-10-20
中学生数理化·七年级数学人教版(2017年2期)2017-03-25
CHIP新电脑(2016年3期)2016-03-10
国外科技新书评介(2014年12期)2015-01-05
