
一种基于噪声场景识别与多特征集成学习的活动语音检测方法
2020-10-27 11:45:04张小博
电声技术 2020年6期
田 野,张小博
(中国电子科技集团公司第三研究所,北京 100015)
1 引言
在一段语音信号中往往会存在着停顿、间歇等现象,这些“无声”段与环境噪声叠加,干扰语音处理效果且占用资源。活动语音检测(Voice Activity Detection,VAD)技术的目标是从信号中检测出真正的语音段落而去除这些“无声”部分,从而减轻后续语音信号处理过程的负担。因此,VAD 技术广泛应用于语音编码、自动语音识别以及异常声音检测等系统[1-2]。
鉴于活动语音检测技术的广泛应用需求,近年来研究学者们提出了很多检测方法,大体可以分为无监督类方法与有监督类方法。一般来说,有监督类方法将VAD 问题视为语音与噪声信号的二分类问题,通过事先学习噪声数据,噪声环境下的性能高于无监督类方法[3-4]。
有监督类方法主要由特征提取和分类器设计两个环节构成。在特征提取方面,为了能够有效区分噪声和语音信号的声学特性,研究学者尝试从不同角度提取特征,如能量、过零率、梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)以及模糊熵等,并使用多种特征组合以融合多角度信息[5]。然而,虽然这些特征在特定噪声类型下有效,但由于噪声类型的时变性,针对通用情况设计的特征组合往往难以在动态噪声下表现出稳定的区分能力,而且特征的高维化往往也给后续的分类器使用带来了负担。
在分类器设计方面,针对单一分类器数据建模能力的有限性,近年来发展出集成学习和深度学习方法,通过提高建模的广度和深度提升模型的泛化能力[6-7]。在建模策略方面,有监督类方法对特定类型下的噪声和语音信号进行二分类建模。由于噪声类型的多变性,如何训练得到在多种不同噪声类型下都具有良好区分性的模型分类器设计是重点任务之一。
针对上述问题,本文提出基于噪声场景识别与多特征集成学习的活动语音检测方法,构建了噪声类型识别模型和噪声与语音二分类模型。在噪声类型识别方面,提出基于t分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)与集成学习的噪声聚类与分类方法,并采用了集成效果更好的随机森林方法。在语音与噪声区分识别方面,提出基于随机森林的特征选择与分类器构建方法,先识别当前的噪声类型,将动态噪声环境转化为限定噪声环境,进而针对具体噪声类型在高维特征中优选最具有区分性的特征组合并设计模型参数,从而保证了整个检测过程在不同噪声类型下性能的有效性和稳定性。
2 技术实现方式
2.1 相关背景技术
2.1.1 多视角特征提取方法
为了从多个角度获取音频信号间的可区分性信息,提取过零率、MFCC、频谱质心、频谱扩散、谱熵、谱通量、频谱滚边、谐波比、基频、频域能量、带宽以及小波分量特征等共37 维的时频域特征。具体地,在特征计算中采用三层小波分解方法将音频信号分解为8 个小波分量,然后计算每个分量的能量作为特征;同时,对小波分量矩阵进行奇异值分解,取前6 个奇异值作为特征。
2.1.2 t-SNE 特征聚类特性分析方法
t-SNE 方法[8]是一种基于概率的子空间嵌入方法,核心是在高维空间中采用高斯分布而在低维空间中采用“重尾分布”t分布来模拟数据点对间的概率分布情况,从而提高不同类数据间的可分特性,在保留高维数据局部特性的同时,尽可能地保持全局聚类特性。
2.1.3 随机森林分类与特征选择方法
随机森林(Random Forest,RF)是一种采用Bagging 策略的集成学习方法,由若干个决策树基分类器构成集成分类器,分类的最终结果由各个决策树的投票结果共同决定,从而可将多个弱分类器集成为一个强分类器,获得比单一决策树更好的分类性能[9]。
在RF 方法中,每个决策树的训练数据采用Bootstrap 方法从总训练数据集中随机抽取,抽取后剩余的数据称为袋外数据,而通过分类器对袋外数据的分类误差评估各个分类器的性能。此外,可以通过改变袋外数据中某个维度特征的数值来考察识别准确率的变化情况,从而衡量不同维度特征的重要度水平[10],实现特征优选。
2.2 基于t-SNE 与随机森林方法的噪声类型识别方法
为了提高具体场景下语音信号检测的准确率,本文在含噪语音与噪声信号分类前识别当前使用场景中的噪声类别,提出了一种融合了t-SNE 可视化聚类方法和随机森林特征优选与分类器构建方法的噪声场景分类方法,技术实现框图如图1所示。
2.3 基于随机森林的含噪语音与噪声分类识别方法
活动语音检测的核心是有效区分含噪语音信号与噪声信号。不同噪声下含噪语音与噪声的区分性特征不尽相同,采用统一的特征和分类模型难以在不同噪声下都取得良好的识别结果。因此,本文提出针对不同的噪声类型优选不同的特征组合并训练特定的识别模型,从而提高算法模型在不同环境下的适应能力,技术实现框图如图2 所示。
3 案例分析
在本文的案例分析中,语音信号随机选自数据集THCHS-30[11],共30 条不同说话人的音频,男女生各15 条。噪声信号选自NOISEX-92 标准噪音库,共6 种噪声作为分析对象,分别是白噪声(white)、餐厅内噪音(babble)、工厂内噪声(factory2)、小汽车内噪音(volvo)、坦克内噪声(m109)和战斗机噪音(f16)。
3.1 基于t-SNE 聚类分析与随机森林的噪声分类识别
3.1.1 时频域音频特征提取
对6 种噪声信号先统一重采样到8 kHz,然后以20 ms 为帧长、10 ms 为帧移进行分帧,并提取37 维的时频域特征。这些特征的维度与特征名称的对应关系如表1 所示。
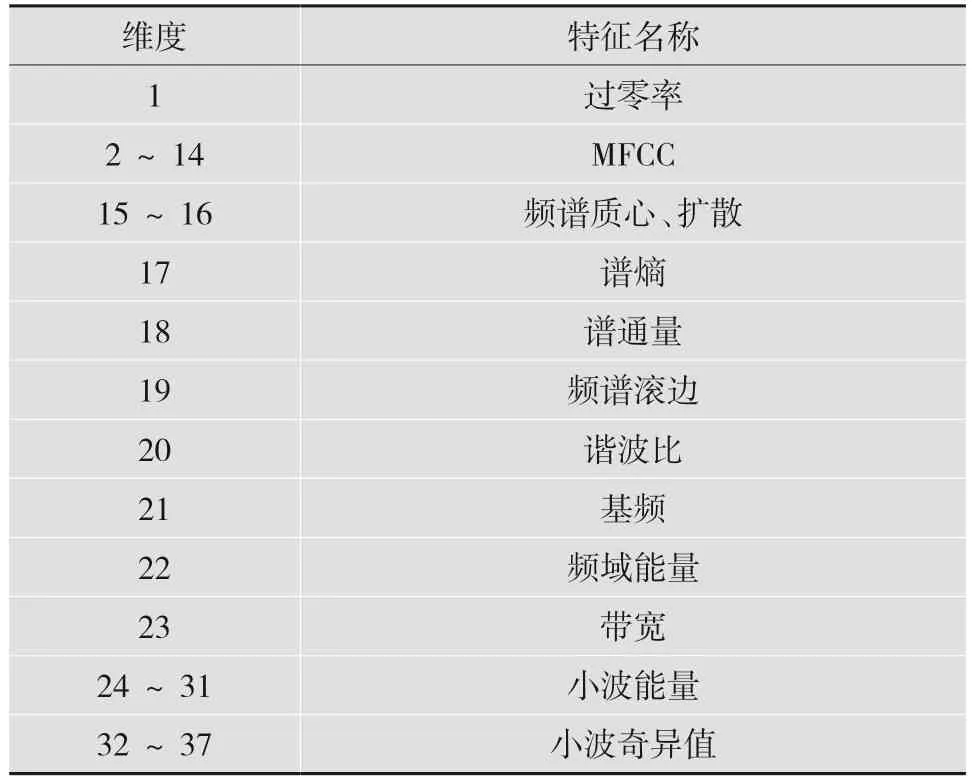
表1 音频特征维度及特征名称对应关系列表
3.1.2 噪声聚类分析
对6 种噪声的特征进行t-SNE 可视化聚类分析,结果如图3 所示。可以看出,这6 种噪声形成了4 个聚类群。其中:babble、factory 和m109 的噪声特性相似,可以视为一类噪声;而volvo、f16、white 独立成类。后续对这4 种类别的噪声进行分类识别即可。
3.1.3 噪声分类模型的训练和测试
基于特征优选结果,抽取训练和测试数据各4×1 500 组。训练中采用5-fold 交叉验证和模型参数网格搜索方法,确定最优参数:树的个数为20,最大深度为9,最小叶子数为1。而后进行5 次训练,平均训练准确率为99.81%,测试准确率为98.97%。可见,该分类器具有良好的噪声识别准确率和对未知测试数据的泛化能力。
3.2 基于随机森林的含噪语音与噪声信号分类识别
3.2.1 时频域音频特征提取
先用6 种噪声对纯净语音进行加噪处理,信噪比分别为10 dB、5 dB、0 dB 和-5 dB。然后,将数据统一重采样到8 kHz,以20 ms 为帧长、10 ms 为帧移分帧,并提取37 维的时频域特征。
3.2.2 面向含噪语音与噪声分类任务的特征优选
在4 种信噪比下,特征优选结果如表2 所示,其中10 dB、5 dB、0 dB 下的top10 特征基本一致,合并在一起;而-5 dB 下的特征与前3 者差异较大,单独列出。因此,在各类噪声场景下,在10 dB、5 dB、0 dB 下采用同样的特征组合并训练统一的模型,而对-5 dB 单独训练模型。
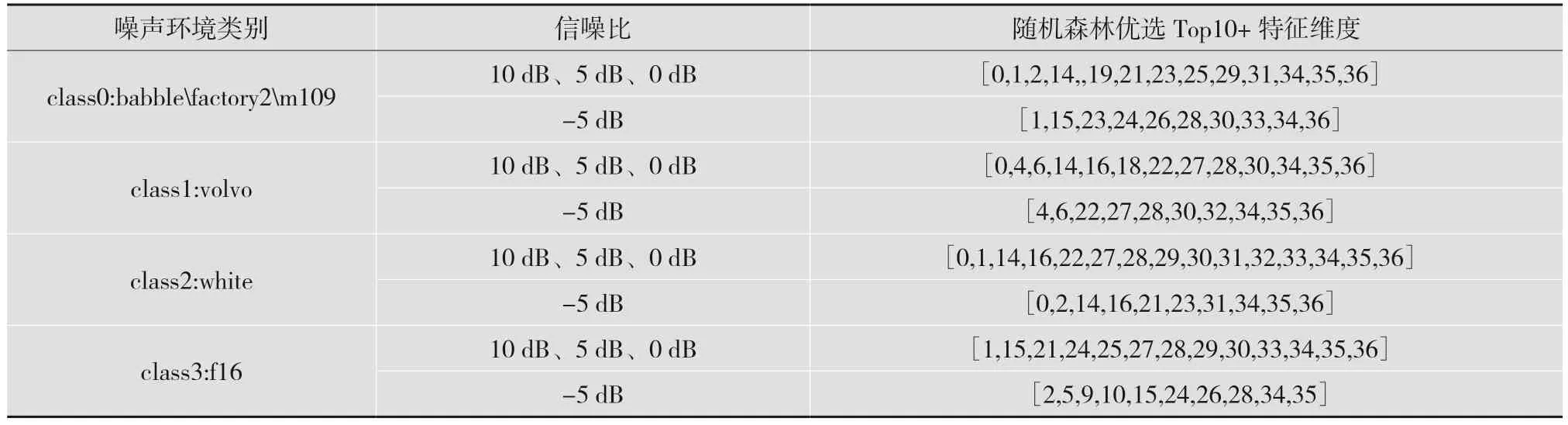
表2 不同噪声环境下含噪语音与噪声分类的特征优选结果明细表
3.2.3 含噪语音与噪声分类模型的训练和测试
基于特征优选结果,抽取训练和测试数据各2×1 500 组样本。为了验证RF 分类的优势,同时训练了SVM 和两层MLP 模型,且都采用网格搜索方法进行参数调优。识别准确率如表3 所示。可以看到:在不同噪声类型和噪声强度下,RF 分类器的识别准确率都是最好的,而SVM 分类器和MLP 分类器的识别效果相当;对于不同噪声类型,在信噪比不低于5 dB 的情况下,RF 分类器的准确率可达到95%以上;当信噪比降低到-5 dB 时,准确率普遍下降很多,此时应该结合降噪算法保证语音检测的准确率。
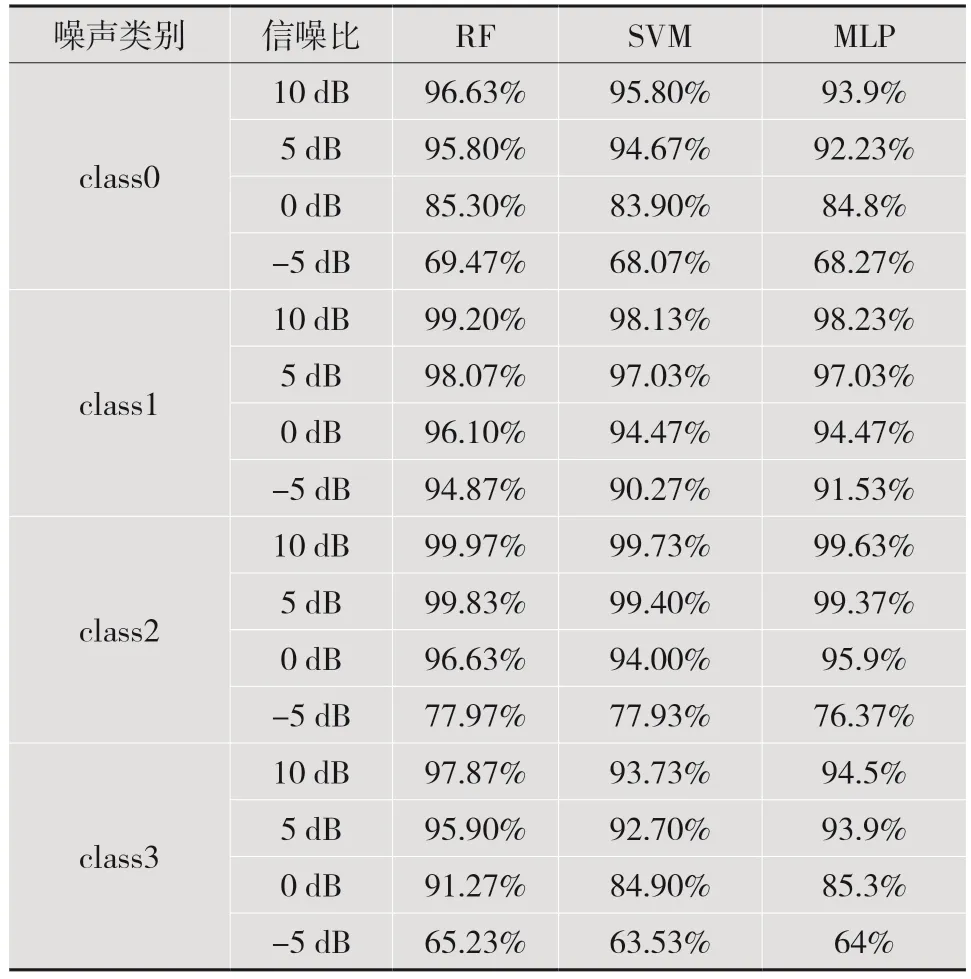
表3 不同噪声环境不同信噪比下不同分类器的识别结果列表
4 结语
针对多噪声场景下的活动语音检测任务,提出了一种基于t-SNE 与随机森林的噪声场景识别方法,将动态噪声环境转化为特定噪声环境,并针对不同噪声特点优选音频特征、定制化训练模型,提高了整套方法在不同噪声类型、不同噪声强度下应用性能的稳定性,提升了活动语音检测的准确率。在本文方法基础上,可考虑语音信号自身存在的停顿、喘息等特点,后续还可以通过设定最短有效语音长度和最短静音长度等门限机制来进一步提高端点检测的准确率。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
