
基于LDA-FCM方法的Web服务发现聚类性能分析
2020-10-20 05:34冉冉徐立波曲睿婷夏雨
计算技术与自动化 2020年3期
关键词:聚类
冉冉 徐立波 曲睿婷 夏雨


摘 要:为提高Web服务发现能力,需要进行Web数据的优化聚类处理,提出了基于LDA-FCM方法的Web服务发现聚类方法。利用LDA模型进行Web服务发现资源数据的重组和自适应调度,以提取Web服务发现的数据资源特征。依据数据特征确定其相似度,在FCM算法中,通过相似度计算隶属度,从而确定聚类中心,多次迭代后,实现Web服务发现聚类。实验结果表明,所提方法复杂度较低,具有较好的聚类精度,聚类执行时间较少,其查全率与查准率均较高。
关键词:LDA模型;Web服务;聚类;模糊C均值算法;隶属度;数据相似度;服务发现
中图分类号:TM7659 文献标识码:A
Performance Analysis of Web Service Discovery
clustering Based on LDA-FCM Method
RAN Ran?,XU Li-bo,QU Rui-ting,XIA Yu
( State Grid Liaoning Information and Communication Company,Shenyang,Liaoning 110006,China)
Abstract:In order to improve the ability of Web service discovery,it is necessary to optimize the clustering of Web data,and a clustering method of Web service discovery based on LDA-FCM method is proposed. The LDA model is used for the reorganization and adaptive scheduling of Web service discovery resource data in order to extract the data resource characteristics of Web service discovery. According to the data characteristics,the similarity is determined. In the FCM algorithm,the membership degree is calculated by similarity,so as to determine the clustering center. After many iterations,the Web service discovery clustering is realized. The experimental results show that the proposed method has low complexity,good clustering accuracy and less clustering execution time. The recall rate and precision rate are high.
Key words:Latent Dirichlet Allocation model;Web service;clustering;fuzzy C-means algorithm;degree of membership;data similarity;service discovery
為进一步提高Web资源的自动调度能力,需要进行Web服务发现聚类处理,构建Web服务资源数据的自适应分类和调度模型,进行Web数据的优化分类,满足人们的个性化服务需求[1]。在大数据环境下,进行Web资源数据的聚类处理。根据Web资源的图片、声音、数据和文本信息等属性,进行Web资源的聚类分析[2],研究Web服务发现聚类方法,在提高Web资源优化调度和服务能力方面具有重要意义,相关的Web数据发现方法研究受到人们的极大关注[3]。
其中,黄媛提出一种基于标签推荐的服务聚类方法[4],利用标签推荐形式分析API服务聚类集合,以Web2.0为研究对象,在API服务数据集进行操作实验,以此为基础,提出服务聚类方法。肖巧翔等[5]提出基于Word2Vec和LDA主题模型的Web服务聚类方法,将Wikipedia语料库实行扩展,利用Word2Vec进行信息收集,将收集的结果按LDA主题模型实施文档描述,完成Web服务聚类。
针对上述情况,提出了基于LDA(Latent Dirichlet Allocation)-FCM(Fuzzy C-Means)的Web服务发现聚类方法,实现Web服务发现聚类优化。
1 基于LDA模型的Web服务资源数据特
征提取
LDA(Latent Dirichlet Allocation)模型可推断出Web服务中的不同资源数据、文档的主题状况,预测资源数据的分布状况,而Web服务中使用到的资源数据、项目文档等均可以用来Web服务发现聚类,为用户的提供搜索功能。为了实现在大数据环境下的分布式Web服务资源数据聚类,实现Web服务发现聚类分析,提出运用LDA结合FCM方法进行聚类研究。
1.1 LDA模型构建
首先构建Web服务发现数据的LDA模型,其为一种非监督的机器学习算法,该种算法可以将Web服务发现数据的主要内容分为三类[6],分别为:词、文档、主题,可用来识别海量Web服务中的隐含数据信息。这种运用LDA模型分类处理Web服务资源数据,有效地过滤与用户搜索目标无关的Web服务,减少Web服务匹配次数,缩短Web服务发现的执行时间。主要方法为:
设分布式Web服务发现资源数据信息为Pi∈P(i = 1,2,…,m),根据上述分析,构建Web服务发现数据的LDA模型,如图1所示。
目前,用户搜索Web服务时,往往是输入用户自身需要的功能名称,搜索引擎根据用户键入的请求,给出满足用户要求的Web服务。其中,搜索引擎主要依靠标签对Web的搜索服务进行功能划分,这种划分下,极易造成资源浪费。如若一个资源可以用做不同的功能,但其只划分到最常用功能中,则导致该资源的其他功能浪费,还有一些隐蔽资源,如该项资源数据具有某项功能,用户只搜索该功能,但该项资源数据的篇名或文件名并非该项功能,导致目前的搜索方法很难查询到。而本文构建使用的Web服务发现数据LDA模型,将Web服务的数据资源划分为三类,分别为:词、文档、主题,这种划分不论用户在搜索关键词、功能、模糊主题甚至固定的文档题目等,均可以高效搜索到目标内容,扩大了可搜索到资源的数目,避免资源浪费,提高检索效率。同时,将Web服务资源进行有效分类后,可以提高其重组精度,对资源重组,如将具有共同含义的词或具有共同研究方向的文档归为一个组合,提供“打包”服务,可为Web服务搜索提供新尝试,为融合调度服务资源数据提供基础。
1.2 Web服务资源数据的调度模型设计
在1.1节中构建LDA模型实现Web服务数据资源的分类后,还需提取不同类别数据资源的特征,以实现最终的聚类目的。其中,考虑到不同资源具有相同功能,即不同的词、文档、主题可能均满足同一个用户搜索请求,为提高资源利用效率,利用关联属性对资源数据进行重组,依据重组结果实现最终的调度模型设计。
假设分布式Web服务资源数据信息存储的节点的属性集为X = {x1,x2,…,xn},Web服务资源数据的关联属性集:
在分布式Web服务资源数据的不同类别层中,采用异构信息库重组方法[7-8],可得分布式Web服务资源数据动态重组的约束参量θ:
其中,β代表数据离散估计参量。根据Web服务发现数据的属性特征以及重组约束参数,对其进行资源数据重组,得到资源数据重组结果为:
对Web服务资源数据进行重组可为数据的自适应调度提供基础[9-10],得到分布式Web服务资源数据自适应调度模型为:
由此完成了自适应调度模型的构建。在海量Web服务资源数据中,若直接提取资源数据的特征,易造成资源数据过多,未归类而导致特征过多,不利于后续应用。故需要先对海量资源数据进行一定的处理,对重组后数据进行自适应调度,可确保在此之后的融合处理及特征提取过程更为简单,降低方法的复杂度,并提高特征提取的准确度。
1.3 Web服务资源数据特征提取
在提取资源数据特征之前,还需要融合处理调度结果,这是由于将数据进行互信息融合,可以提高数据的聚集度,使其具有更优的分类效果,保证不同类别数据特征提取的精度。
将Web服务资源数据调度模型映射到高维空间中,在高维相空间中进行分布式Web服务资源数据的互信息融合性调度,得到融合结果为:
其中,t为当前Web服务资源数据的统计量。数据融合处理实际上是一项信息处理技术,其主要是对数据进行自动的分析、组合或筛选,以实现最终的决策。由Web服务资源数据融合处理结果,得到分布式Web服务资源数据不同类别的特征表示为[12]:
其中,μi、Vi 、Oi 分别代表Web服务发现资源数据中词、文档、主题的特征值;μk代表Web服务资源的动态服务特征分布模糊值。
以上实现了不同类别数据的特征提取,依据这些特征,可计算FCM算法的隶属度。
2 基于FCM算法的Web服務发现聚类
FCM(Fuzzy C-Means)算法是监督机器学习的一种,由于FCM算法的数据集均处于同一个向量空间,而Web服务无法映射到一个向量空间,只能计算它们之间的相似度,然后通过相似度来计算隶属度,从而确定聚类中心。
2.1 隶属度的计算
在1.3节获取Web服务资源数据的特征后,确定分布式Web服务资源数据的相似度为:
根据语义 Web 服务的相似度特点,计算分布式Web服务资源数据指向性特征量:
其中,di代表两个数据之间的欧式距离。由此得到其隶属度函数为:
2.2 聚类中心的确定
在Web服务发现性数据的信息覆盖区域,假设m个Web服务发现的传输数据,分布式Web服务资源数据动态特征分布集在t中的聚类簇为ci,第i个Web服务发现性数据的散乱点集为Ri = (ri1,ri2,…,riD),得到数据关联特征量为:
其中,P(d|t,ci)为ci类分布式Web服务资源发现聚类的分布概率,在统计特征分布模型中[12-14],分布式Web服务资源数据发现聚类的融合特征量为z = {zf 1,zf 2,…,zf r},得到分布式Web服务资源数据发现聚类的目标函数为:
构建分布式Web服务资源发现聚类的关联性决策函数为:
进行模糊C均值聚类的自适应寻优控制,构建Web服务数据的空间聚类模型[15],计算分布式Web服务资源数据指向性特征量vi,vj = ((w1,t1),(w2,t2),…,(wj,tj)),分布式Web服务资源聚类的模糊集为:
其中vi为Web服务发现资源数据的关联系数值。对Web服务发现资源数据的属性进行动态评估,计算公式为:
根据Web服务发现的属性集进行向量量化分解[16-18],得到Web服务发现资源数据聚类的模糊相似度为:
其中:pi,j(t)为分布式Web服务资源数据共享的模糊相关性特征分布集,Δp(t)为分布式Web服务资源数据的模糊决策增量值。用4元组(Ei,Ej,d,t)来表示分布式Web服务资源数据的决策树[19-20],得到的Ei是分布式Web服务资源数据在聚类分岔节点,分布式Web服务资源发现聚类的差异化融合特征量:
式中,m为分布式Web服务资源数据分布的有限数据集,(Yik)2为相似度分布映射,采用模糊C均值聚类,得到优化聚类中心为:
2.3 基于FCM算法的Web语义服务发现聚类
步骤
FCM算法的核心即为隶属度以及聚类中心的确定。算法的具体步骤为:
(1)给定聚类数目、初始化设置隶属度值和聚类中心,确定迭代误差。
(2)对第i次迭代,重新计算隶属度函数,以得到更新后的隶属度函数值。同时,重新优化更新聚类中心。
(3)计算目标函数,并保存结果。
(4)若目标函数结果满足条件,则算法停止;否则,返回步骤(2)。
3 仿真实验实验结果分析
为了验证本方法在实现Web服务发现性聚类的性能,采用Matlab进行实验分析,对Web服务数据采样来自于Pearson Database数据库,调查对象主要包括11个领域内的数据,分别为:Tools,Financial,Enterprise,Messaging,Payments,Government,Science,Social,Commerce,Mapping和Education等11個领域。主要针对Tools领域里的Web服务进行研究。结合分组控制单元(PCU,Packet Control Unit)进行分布式Web服务资源调度,训练样本规模为80,分布式Web服务资源数据的关联维度为5,迭代次数N = 1 000,延迟为13 ms,采样频率为120 kHz,根据上述仿真环境和参数设定,进行了100次模糊聚类实验,以降低初始点选取对聚类结果的影响。将本方法与K-means聚类方法和FCM聚类方法进行对比,对比指标包括执行时间、查全率和查准率。原始的Web服务资源数据时域分布如图2所示。
分析图3得知,采用本方法进行Web服务发现资源数据聚类的特征归集能力较好。
将本方法与K-means算法和单一的FCM聚类算法进行对比,测试聚类时间,得到对比结果见表1。
由表1可以看出,使用本方法的聚类耗时最少。一方面是由于FCM聚类方法本身聚类耗时较短(可由单一的FCM方法耗时较K-means方法耗时少看出),另一方面,在聚类之前首先使用LDA模型对海量资源数据进行分类与重组,这种处理后,过滤掉了与用户搜索目标无关的资源数据,使同时各个类别的数据量明显降低,对各个类别的资源数据进行同时特征提取和聚类,使得提取数据特征更为简单,算法复杂度低,从而缩短了整体的聚类耗时。
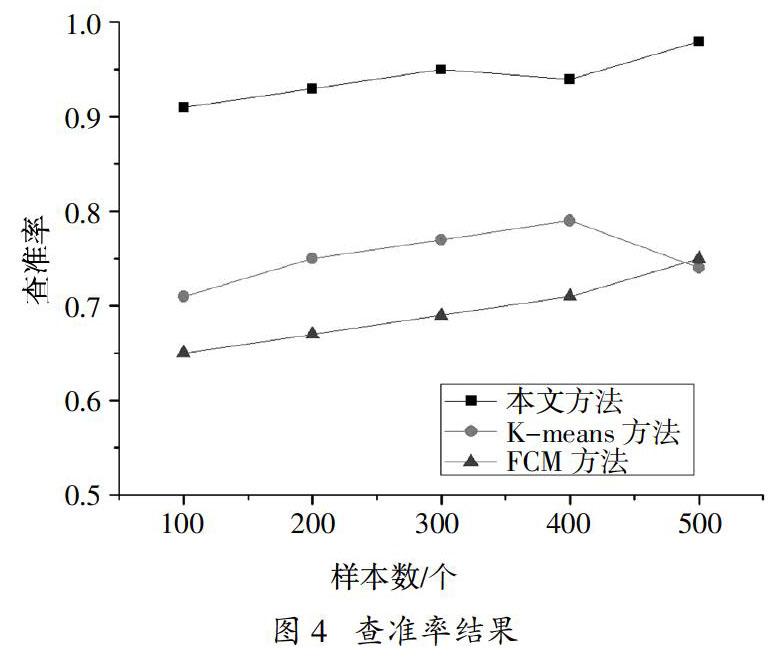
测试不同方法的查准率和查全率,查准率是评价检索出的资源数据是否正确的指标,即为检索出的正确资源数据量与检索出的所有资源数据量的比值。查全率是评价检索方法在整体资源数据中查询是否成功的指标,即为检索出相关的资源数据量与总量的比值。具体的查准率和查全率计算公式如公式(21)和公式(22)所示,得到实验结果如图4~图5所示。
由图4和图5可以看出,本方法进行Web服务资源数据的聚类后,其查准率较高。查全率始终高于其他两种方法,证明了使用LDA与FCM结合后的算法可提高Web服务发现聚类性能。这主要是由于,使用LDA模型对资源数据进行有效分类,按照词、篇名和主题将资源数据分为三类,有利于隐蔽数据的利用和后续资源数据特征的高精度提取,从而求得聚类所需的相似度更为准确,提高最终的Web服务资源数据查准率。而其他两种方法不具有搜索隐蔽性数据的功能,故其查全率较低。但在未来的研究中,可进一步重点研究如何提高Web服务资源数据的查全率。
4 结 论
Web服务聚类是Web服务发现的基础,用户对Web服务资源数据进行查找,能够提高资源数据的利用率和Web服务发现效率。为此,提出了基于LDA-FCM方法的Web服务发现聚类方法。在利用FCM聚类之前,使用LDA方法对Web服务资源数据进行分类处理,以过滤掉不满足要求的数据,同时挖掘发现隐含数据,保证Web服务发现的即时性和准确度。并提取Web服务发现的数据资源特征,解决Web服务无法映射到一个向量空间而导致无法有效求得隶属度的问题,实现Web发现服务聚类。实验发现,运用LDA-FCM方法可以有效提高聚类性能,其具有较单一FCM算法更高的查准率和查全率,且耗时相对较少,说明所提出的算法具有更高的效率和实用性。在未来的研究中,将致力于添加合适的约束参数,以进一步提高查全率。
参考文献
[1] 张祥平,刘建勋,肖巧翔,等. 基于LDA和模糊C均值的Web服务多功能聚类[J]. 中南大学学报(自然科学版),2018,49(12):92-98.
[2] 赵一,李昭,陈鹏,等. 一种面向领域的Web服务语义聚类方法[J]. 小型微型计算机系统,2019,40(1):83-90.
[3] 杜胜浩,钱晓捷. 基于刻面与本体标识的语义Web服务发现方法[J]. 计算机工程,2018,44(8):230-235.
[4] 黄媛. 一种基于标签推荐的服务聚类方法[J]. 计算机与数字工程,2017,45(06):133-136.
[5] 肖巧翔,曹步清,张祥平,等. 基于Word2Vec和LDA主题模型的Web服务聚类方法[J]. 中南大学学报(自然科学版),2018,49(12):85-91.
[6] CAO B,LIU X,LIU J,et al. Domain-aware mashup service custering based on LDA topic model from multiple data sources[J]. Information & Software Technology,2017,90:40-54.
[7] 陆佳炜,马俊,陈烘,等. 一种面向全局社交服务网的Web服务聚类方法[J]. 计算机科学,2018,45(3):204-212.
[8] WU Qing-qiang,KUANG Yi-chen,HONG Qing-qi,et al. Frontier knowledge discovery and visualization in cancer field based on KOS and LDA[J]. Scientometrics,2019,118(3):979-1010.
[9] 黄蓉. 基于聚类分析的数据挖掘方法研究[J]. 山东农业大学学报(自然科学版),2017,48(1):100-103.
[10] BUKHARI A,LIU Xu-min. A Web service search engine for large-scale Web service discovery based on the probabilistic topic modeling and clustering[J]. Service Oriented Computing & Applications,2018,42(3):1-14.
[11] 刘一松,朱丹. 基于聚类与二分图匹配的语义Web服务发现[J]. 计算机工程,2016,42(2):157-163.
[12] 田浩,樊红,杜武. 基于用户社群关系的Web服务发现研究[J]. 通信学报,2015,36(10):28-36.
[13] ILAHI R,ADMODISASTRO N,ALI N M,et al. Dynamic reconfiguration of Web service in service-oriented architecture[J]. Advanced Science Letters,2017,23(11):11553-11557.
[14] 唐妮,熊慶宇,王喜宾,等. 基于位置聚类和张量分解的Web服务推荐算法[J]. 计算机工程与应用,2016,52(15):65-72.
[15] 闫莉莉,程刚. 基于共词聚类分析的国外知识密集服务研究热点分析[J]. 现代情报,2015,35(8):22-27.
[16] 姚瑶,王战红,石磊. 一种基于页面聚类的 We b概念化建模新方法[J]. 微电子学与计算机,2015,14(1):156-160.
[17] CHEN F,LI M,WU H,et al. Web service discovery among large service pools utilising semantic similarity and clustering[J]. Enterprise Information Systems,2015,11(3):452-469.
[18] RAMASAMY R K,CHUA F F,HAW S C,et al. Web Service discovery for cloud-based mobile application using multi-level clustering and QoS-based ranking[J]. International Journal of Software Engineering & Knowledge Engineering,2016,26(07):1077-1097.
[19] 申利民,陈真,李峰. 考虑数据变化范围的Web服务服务质量协同预测方法[J]. 计算机集成制造系统,2017,23(1):215-224.
[20] 陈婷,刘建勋,曹步清,等. 基于BTM主题模型的Web服务聚类方法研究[J]. 计算机工程与科学,2018,40(10):1737-1745.
猜你喜欢
计算机与网络(2021年20期)2021-12-18
科学与生活(2021年19期)2021-10-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电机与控制学报(2019年5期)2019-10-21
软件导刊(2018年9期)2018-12-10
软件(2017年6期)2017-09-23
计算机应用(2016年10期)2017-05-12
电子技术与软件工程(2016年23期)2017-03-06
商情(2016年50期)2017-02-28
电子技术与软件工程(2014年18期)2014-11-05
