
基于照片的社交关系可视化方法
2020-10-20 10:05:58陈佳舟陈樟樟秦绪佳
小型微型计算机系统 2020年10期
陈佳舟,陈樟樟,秦绪佳
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
随着社交网络服务的盛行,数以万计的用户每天活跃在社交网络服务中,在网络上创造着丰富的信息,由此构建了一个庞大而复杂多样的虚拟社交网络.在社交网络中,发现社交关系是一个至关重要的问题,涉及到每一个人在社交网络中的自我定位和价值发现.因此,通过分析人们在社交网络服务中的社交行为(发布博文、转发、关注),挖掘社交关系引起了许多学者的关注,其中基于社交网络好友推荐拓展社交关系颇受人们关注.Piao等根据用户兴趣倾向的主题,推荐关注相似主题的用户,以拓展用户的社交关系[1].Zhu等以用户微博文本相似度计算用户之间的相似度以及对其他用户的信任度,来挖掘隐含的社交关系[2].这些方法虽然能挖掘出有意义的社交关系,但构造的社交关系缺少现实的指导,可能存在虚假甚至错误的社交关系.
随着数码相机和智能手机等数码摄影设备的普及,在朋友聚会、活动庆典、学术报告、婚礼等社交活动中,拍摄照片成为其中必不可少的环节,称之为“社交照片”[3].通过人脸识别以及照片中的面部共现的技术,从社交照片中分析人们之间的社交关系是近年来的研究热点.Singla等使用马尔科夫逻辑检测照片中的社交关系,并为关系预测定义了一阶逻辑加以约束[4].Plantié等从代表家庭活动的社交照片中提取社交网络用于帮助构建个人照片集[5].Kim等将照片集作为社交网络分析的来源,分析照片存在的潜在朋友关系,提取人与人之间的强关联关系.从这些研究可以得出在照片中面部共现可能表明面孔之间存在强关联关系[6].即在照片中共现的人脸,在现实社交中存在关系,这可以作为从社交网络服务中获取社交关系的指导.但是,基于照片集的社交网络分析,得出的社交关系都比较简单,且没有对关系做出有意义的解释.这就需要从社交网络服务中提取社交关系以弥补由单一社交照片构建的社交关系的不足.
为此,本文提出一种基于照片的社交关系可视化方法,并结合微博设计实现了一个可视化系统SPVis.本文设计了照片与微博、现实与虚拟相结合的可视化探索,首先,利用人脸识别技术识别社交照片中的人物,并获取识别对象在微博上的社交数据(关注数据,文本数据);接着,利用LDA模型发现微博文本主题并计算微博文本相似度,以此度量识别对象间的相似度;最后,通过可视分析识别对象的关注数据和相似度,挖掘对象间虚拟社交关系的特点,分析对象间现实社交关系更加紧密的潜力.
2 相关工作
本文研究工作涉及社交关系分析及可视化分析.根据针对不同的社交数据类型,可将社交关系分析的相关工作分为两种类型,基于社交照片和社交网络服务这两类工作.可视化分析挖掘人类对于信息的认知能力与优势,将人、机有机融合,借助人机交互高效洞悉大数据背后的信息与规律,是大数据分析的重要方法[7].
基于社交照片的社交关系分析,主要通过观察照片中人物共现的情况,来分析人物间的社交关系.例如,Lewis等根据Facebook用户之间的社交关系,如Facebook好友、照片好友、室友等,分析兴趣爱好的相互影响,报告结果显示,与其他关系相比较,出现在彼此相册中的朋友在喜爱的电影、音乐和书籍中有着高度的相似性[8].Kim等将个人照片集作为社交网络分析的来源,分析照片存在的潜在朋友关系,定义了一种数据结构——人脸共现网络(Face Co-Occurrence Networks,FCON),用于提取人与人之间的强关联关系,并利用FCON推荐可靠的社交朋友.Bo等通过人脸识别算法构建具有照片收集功能的社交网络,并使用社交网络分析方法分析社区属性和个体特征.这些研究都表明在照片中人脸共现可以代表人物之间存在强相关性[9].然而,他们主要利用照片集来解析社交关系,根据照片集中的人脸共现来建立潜在的关系,而且他们所展示出的关系都比较简单,且没有对关系做出有意义的解释.
基于社交网络服务的社交关系分析,主要根据人们在社交媒体上的社交行为(发布博文、转发、关注等),来分析人际间的社交关系.Piao等利用LDA模型挖掘Tweet文本的主题词以及主题词上的概率分布,找出用户兴趣倾向的主题,推荐关注相似主题的用户,以拓展用户的社交关系.Zhu等以用户微博文本相似度为似然函数,使用K-means聚类对微博用户聚类,得到社交圈并计算用户间的相似度及信任度,以此挖掘出隐含的用户社交关系.Yin等根据数据分析,发现超过90%的用户关注关系由已有的好友建立[10].Chen等发现基于社交网络用户间的关注关系对于同属一个社交圈的用户扩展社交关系具有很强的指导意义[11].Miao针对微博媒体分析人物数据的特点,挖掘用户的密友、校友和同事等,识别话题、挖掘兴趣等[12].Wang从微博数据中抽取用户主题,结合用户之间关注关系,对用户进行相似度计算,通过聚类检测出隐含的社交关系[13].根据社交行为分析所得的社交关系,虽然具有具体而有意义的解析,但虚拟网络中存在的多样性和不确定性,可能存在虚假甚至错误的社交关系.
由上述的工作中存在的不足,本文利用现实社交与虚拟社交的结合,通过识别一张照片中的人脸,结合识别对象在微博上的社交行为,构建对象间真实而又具体的社交关系,并通过可视化的方式探索分析对象间的关系.
3 SPVis系统概述
本文提出的SPVis可视化系统如图1所示.SPVis系统主要由人脸识别、数据采集与预处理、社交关系网络构建和可视化分析4个模块组成.

图1 SPVis系统架构图Fig.1 Architecture of SPVis visualization system
人脸识别模块的功能主要为:1)检测照片中的待识别人脸;2)提取待识别人脸的特征值;3)匹配待识别人脸的特征值和特征值库;4)获取识别人脸的个人信息.
数据采集与预处理模块的功能为:1)通过个人信息,从微博中爬取对象的关注数据和微博文本数据;2)对微博文本数据进行清洗,删除错误或重复数据;3)对文本数据进行中文分词,以用于主题提取.
社交关系网络构建模块的功能可分为:1)根据识别的人脸构建Ⅰ级社交关系网络;2)将Ⅰ级社交关系网络结合关注数据构建Ⅱ级社交关系网络;3)运用LDA主题模型提取文本主题,并进行主题相似性分析;4)结合文本主题相似性构建Ⅲ级社交关系网络.
基于以上的数据处理,本系统设计了以下视图:1)关系网络视图,利用节点链接方式对社交关系网络进行可视化,用户在视图中了解识别对象间社交关系的构成,通过交互探索社交关系的特点;2)关系网络3d视图,通过三维视角可视化社交关系网络,丰富对社交关系的探索;3)个人信息视图,可视化识别对象个人的关注信息;4)共同关注信息图,可视化识别对象间共同关注的信息.
4 基于照片的社交关系构建可视化
本文设计实现了SPVis可视化系统,意在通过识别照片中的人脸,并结合微博,实现现实社交与虚拟社交关系的融合,可多层次展现出人物间的社会关系,分析对象间关系更加紧密的潜力.
4.1 人脸识别
人脸识别是从数字图像或视频帧中识别人的技术,主要是根据人的脸部特征信息与数据库中的人脸进行比较来识别的.通过摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像检测和跟踪人脸,进而对检测到的人脸进行脸部识别.本文利用开源的跨平台软件库Dlib,实现人脸检测与识别.对于人脸检测、人脸识别,Dlib提供了基于深度学习的算法,利用训练好的人脸关键点检测器和人脸识别模型得到人脸面部特征,并通过检测欧氏距离的近似值来识别人脸.
本文利用训练好的人脸关键点检测器以及基于ResNet人脸识别模型,以320位明星的个人照片集为数据源,检测照片中的人脸,并保存其人脸特征数据及标签(中英文姓名),构建人脸特征模板库,以文本格式记录.
在人脸识别过程中,通过人脸检测可以检测出在社交照片中的所有人脸,再计算所检测到的人脸特征数据与人脸特征模板库中特征数据间的欧式距离,通过阈值筛选距离最小者为识别结果,记录其人脸标签并从已构成的个人信息检索出相应的微博ID用于后续步骤.若检测出照片中的人脸并成功识别,则标记出人脸的位置并记录对应人脸的个人信息;若在人脸识别结果中出现未标记人脸的情况,则表示该人物的人脸信息未录入人脸特征模板库中或该照片中此人物的脸部存在遮挡或角度不当使得无法提取人脸特征.
4.2 获取关系数据
微博数据大致可分为微博博文数据、用户信息数据、社交关系数据.其中微博博文数据包括微博的内容、微博发表时间、转发数、评论数、点赞数、是否是长微博、是否是转发的微博、源微博的URL等,用户信息数据包括用户ID、昵称、个人简介、性别、微博发表数,粉丝数,关注数等,社交关系数据包括关注者的用户ID、昵称以及关注类别、被关注者的用户ID及昵称.本文获取的微博数据主要为微博博文数据和社交关系数据中的关注者数据.
本文采用Ajax数据爬取的方法获取数据,以微博手机端为数据获取平台,通过特定的请求地址,向服务器请求数据接口,数据以json格式返回.通过id、container_id、page这三个参数来调节对微博博文数据和社交关系数据的不同请求.id代表微博用户的ID,通过输入不同用户的微博ID,可以向服务器请求不同用户的微博数据.container_id是获取微博博文数据时需要的参数,从各用户的微博主页中获取.page表示微博博文数据按照页数顺序获取,每页的微博博文数量最多为10篇.关注者数据主要是通过id参数向服务器请求获得,而关注者数据分为有分组标记和未分组标记两种.其中有分组标记的关注者数据,需要通过不同的分组tag获取相应的关注者数据,分组大致为“美妆”,“体育”,“电影”,“综艺”,“娱乐”,“朋友”等,其中分组的亲密程度为“朋友”<“娱乐”<其他.获取到的微博文本数据和关注者数据都以xlsx格式保存.为提高爬虫速度,采用多线程的方式进行微博爬虫,开启3条线程进行爬虫,同时为避免反爬机制设置一定延时,实验结果显示基本实现每个对象的爬虫时间为2分钟左右.
4.3 用户相似度计算
如果两个用户发布的微博文本有着相似主题,则说明这两个用户可能有相似的价值取向,因而能有更多的共同话题,社交关系也能更加紧密.由微博文本相似性来度量用户相似性,若文本的主题越接近,它们的联系越紧密,则用户之间的相似度就越高,反之如果主题越疏远,则用户相似度越低.
首先,使用基于textRank方法的jieba分词对微博文本进行分词[14];然后通过LDA主题模型提取微博文本主题,LDA在提取主题时会考虑到文档中的语义信息[15];最后,使用Jensen-Shannon散数的倒数来衡量文本与文本之间的主题相似度,如公式(1)所示:
(1)
其中,vi,vj表示微博文本的主题概率分布.
4.4 社交关系网络构建
根据社交环境不同可以分为现实社交和虚拟社交.现实社交顾名思义就是指在现实世界中人与人之间的直接交际往来,例如聚会、学术报告、活动庆典等.虚拟社交是以虚拟技术为基础,人与人之间的交往是以间接交往为主,通过社交网络服务平台进行人际交流.
社交照片作为现实社交活动的记录,直接可以映射出人们在现实世界中存在着社交关系,但是他们之间存在着怎么样的关系,是否有相同认识的人,是否有相同的兴趣爱好,这些我们并不能从照片中获取.而社交网络服务平台作为人际交流的媒介,可以记录下人们在社交过程中的各种行为,通过数据挖掘可以从中获取许多信息,以弥补从社交照片中获取得到的社交关系的不足.本文主要研究将现实社交与虚拟社交结合,构建多层次的社交关系,以分析社交关系的可发展性.
本文通过三个不同层次构建社交关系.Ⅰ级社交关系构建:若在人物A和人物B同时出现在一张社交照片中,那么认为人物A和B之间存在联系.该联系为现实关系,是作为整个社交关系网络的基础,视为强关联关系;Ⅱ级社交关系构建:在I级社交关系的基础上,结合已识别的人物A和B的关注人信息构建社交关系;Ⅲ级社交关系构建:在II级社交关系的基础上,结合微博的文本数据,通过对微博文本相似度的计算,若微博文本相似度越大,则表明用户相似度越高,人物之间的隐性关联越紧密.
本文的社交关系以Ⅱ级社交关系为主体,I级社交关系为基础,III级社交关系为辅助而构建.在构建II级社交关系时,若人物A关注人物B,那么人物A与人物B间存在(A,B)的直接联系.若人物之间的直接联系有标签,则标注为具体的关注类别.若人物A和人物B同时关注人物C,那么人物A和人物B之间存在(A,C,B)的间接联系,人物C为他们联系的纽带,联系的紧密程度即人物之间共同关注的数量,共同关注的数量越多,人物之间的间接联系越紧密.
4.5 社交关系网络可视化
图分析是揭示数据中复杂关联关系的一种有效手段,而可视化通常为该过程的核心组成部分[15-17].本文使用节点链接的方式对社交照片中识别对象的社交关系进行可视化.如图2(a)所示,社交关系主要由照片中直接获取的强关联关系即I级社交关系,结合微博关注关系构建成II级社交关系,再加上用户相似度信息构成.图2中以人脸照片为填充的节点表示为中心节点,即社交照片中识别出的人脸,较大的节点为分组节点,较小的节点为关注者节点,边表示节点间的联系.在关系网络视图中,不同粗细的线段表示了不同的层次,越粗就表示越底层,而用户相似度由中心节点间的线段粗细来表示,线段越粗表示用户相似度越高.
在二维平面上展示的关系网络由于节点过多,可能会存在边交叉繁乱,关系较少的节点会聚集在一起,影响交互效果.由此,本文引入了3D的节点链接图,在三维空间中可以通过旋转、拖拽,调整不同的视角来观察、探索关系网络.如图2(b)和图2(c)所示,3D视图中节点由小球构成,小球若可点击则表示该节点存在子节点,可展开或收回其子节点,若小球不能则表示小球为末节点.若小球之间存在直接连接的闭合环,则为中心节点.

图3 个人信息视图Fig.3 Personal information view
由于在节点链接图中个人的关注者信息由节点的形式表现,无法直观的了解个人关注者的数量以及各个分类占比,本文使用分区图来对其进行可视化.如图3所示,中心为社交照片识别的人物,第二层为关注者的分组,该分组由微博关注数据的分组标签构成.个人信息视图将每个对象所有分组情况展现,同时可以获取每个分组的比例以及分组中具体的关注者.如图中何炅的总关注数量为647,其中占比最大的娱乐分组为总数的68.3%;李小冉的电影分组中有赵宝刚、杨阳、李潇等人.

图4 共同关注信息视图Fig.4 Common concern information view
为了深入分析识别对象间社交关系的紧密性及可发展性,本文通过打包图可视化方法展示对象间共同关注信息.如图4(a)所示,用大圆包含识别对象的所有共同关注,用中圆包含该对象与其他任一对象的共同关注,用小圆包括不同类别的共同关注.以何炅为例,图4(b)为何炅的共同关注信息视图,其中何炅与谢娜之间的共同关注人数为275,何炅与李小冉之间的共同关注人数为23.为细化共同关注信息,将对象间的共同关注分类,如图4(c)所示,“娱乐”分类在何炅与谢娜的共同关注人数中占最大比重有204人.
5 SPVis系统的交互设计和探索
本文中所使用的实验数据均来源于网络,人脸特征模板库由共约320个明星主要为大陆明星和台湾明星构成,并以他们的姓名、微博ID构建基本的个人信息库.
在实验过程中,以明星的社交照片为输入数据,通过人脸识别技术识别出照片中的人脸,通过匹配数据库获取相应识别对象的微博ID,用以实时的微博数据获取.
微博数据获取主要包含关注人数据、微博文本数据.其中,关注人数据主要包括关注人姓名、关注人微博ID、关注类别.本文主要通过这两种微博数据构建人物关系网络,首先,通过识别对象的关注人信息,判断对象之间是否相互关注,是否存在共同的关注人物,构建出基础的人物关系网络.然后,通过分析微博文本的相似度,判断对象之间的相似性,以分析对象关系更加紧密的可能性.
获取关系数据后,在进行主要的可视化处理前,对数据需要进行一些处理.在关系挖掘前,由于获取到的数据均以列表的形式存储的,为了便于进行人物关系网络的挖掘工作,需要先对数据进行关系的网络化处理.首先将每个人物具体抽象为一个节点,而每个节点可以具有自己的属性信息,如姓名、微博ID等.如果对象与另一个对象间存在较多共同关注人,则说明两对象间的关系较为紧密,且关系再发展的潜力较大.
系统的交互主要分为以下几个部分:1)照片文件上传,应用于人脸识别功能,上传所需识别的社交照片,以识别人脸获取人物信息;2)平移和缩放,应用于社交关系视图,用以支持用户按照不同尺度缩放、查看可视化界面;3)节点筛选,应用于社交关系视图,用于支持用户筛选出所需查看的关注分组,点击关系图中的其中一个分组,可展示出该分组的关注者对象并以表格的方式载入到页面下方,以及与其他分组是否存在信息重叠的情况;4)分区变焦,应用于个人信息视图和共同关注视图,用于用户根据不同焦点来查看个人信息和共同关注信息;5)焦点节点,用于3D社交关系视图,用以用户选择不同的节点为中心视角来观察可视化界面;6)节点扩展,用于3D社交关系视图,点击节点可以扩展或收缩节点;7)边长控制,用于3D社交关系视图,通过滑动条调节各层次的边长长度,方便用户观察.
为了更好地解释系统的探索流程,本文在下面描述一个使用场景.假设某用户A希望了解某社交活动上何炅、谢娜、李小冉之间的社交关系,他想通过SPVis系统得到一些信息.首先他通过SPVis界面上传一张此社交活动上这些明星的合照,系统通过与人脸数据库的信息匹配,获取相应的微博ID用以爬取其微博数据.
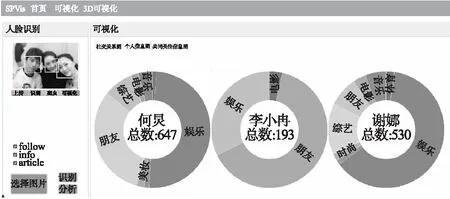
图5 系统主界面图Fig.5 Diagram of system main interface
SPVis系统的主界面显示如图5所示,SPVis主要提供了4种不同的可视化视图:社交关系视图、个人信息视图、共同关注信息视图、3D社交关系视图,如图2-图4所示.在个人信息视图中,用户A发现李小冉的关注人数只有193个,且对比何炅与谢娜的关注分组,李小冉的关注分组也较少,由此推测李小冉可能较少进行微博社交,且对微博社交关系并不紧密.何炅与谢娜的关注人数比较相近,关注分组相似,并且各分组占总关注人数的比例也大致相同,可以推测何炅与谢娜的相似度较高,微博社交比较频繁,他们之间的社交关系比较紧密.
社交关系视图通过三个层次来展示,分别为中心人物、关注分组、关注者,如图6(a)和图6(b)以及图2(a)所示.中心人物关系,由识别社交照片所得的强关系构成,其关系紧密程度由识别对象间的用户相似性决定.在中心人物关系视图中,三人中谢娜和李小冉的相似度较高,可见她们在微博中所发布的信息较为接近,由此可以推测她们之间的个人爱好或者价值取向较为相似,她们之间可能存在更多共同话题,她们的社交关系可以更加紧密.关注分组关系视图所展示的信息与个人信息视图较为相似.从社交关系视图与3D社交关系视图中,用户A发现何炅、谢娜、李小冉之间在微博上有互相关注,而且他们之间存在许多共同关注.

图6 不同层次的关系视图Fig.6 Relationship between different levels
共同关注信息视图中的可视化信息能够指导用户A在社交关系视图和3D社交关系视图的交互.在共同关注信息视图中,何炅、谢娜、李小冉的共同关注人数比例与他们个人关注比例基本相同.在李小冉的共同关注人数中,她与谢娜和何炅的共同关注人数分别为27、23,占关注人数的1/10左右,由此可以看出李小冉与何炅和谢娜的交集并不密切,且亲密程度相似.通过谢娜和何炅的社交关系网络,李小冉的社交关系可以进一步拓展,可以结交更多的朋友.谢娜与何炅之间的共同关注人数较多,有275人,占总关注人数的1/2左右,其中“娱乐”分组的共同关注人数最多,由此得出谢娜和何炅的交友倾向比较接近,他们之间关系的亲密程度较李小冉更为紧密,但他们之间通过彼此的社交关系拓展个人社交较为困难.
在共同信息关注视图中,共同关注者在不同的对象关注列表中分组不同.通过在社交关系视图和3D社交关系视图交互,发现李小冉“朋友”分组的关注者中存在最多分组的共同关注,有谢娜的“大V”、“综艺”、“时尚”等和何炅的“美妆”、“综艺”、“朋友”等.何炅的“娱乐”分组中,存在204个与谢娜的“娱乐”共同关注,20个与李小冉的“娱乐”共同关注;谢娜的“娱乐”分组中,存在204个与何炅的“娱乐”共同关注,2个“朋友”共同关注,21个与李小冉的“娱乐”共同关注,由此得出何炅与谢娜的相似性很高.
根据SPVis系统提供的信息,最终,用户A推测李小冉与何炅和谢娜的社交关系并不紧密,但可以通过与何炅和谢娜存在的共同关注拓展她的社交.李小冉与谢娜的个人爱好或价值观较为接近,她们之间的社交关系更具有发展性,可以更加紧密.何炅与谢娜的社交圈存在较多相似性,且社交圈的交集较多,他们的社交关系可能较为紧密,但难以通过彼此的社交圈拓展社交关系.
6 总 结
本文设计实现了一个基于照片的社交网络可视化系统SPVis,使用社交照片结合社交网络服务探索人物之间的社交关系,构建多层次的社交关系网络.SPVis首先对社交照片进行人脸识别,构建以人脸共现为标准的强社交关系.其次,通过微博爬虫,从微博中获取所识别对象的微博数据,其中包括微博文本数据和关注者数据.通过微博关注者数据,在强社交关系的基础上添加虚拟社交关系.然后,利用LDA主题模型提取微博文本的主题,通过计算微博文本主题的相似度,增加人物之间的隐性社交关系.本文构建了现实社交和虚拟社交结合的社交网络,并通过可视化方式,将抽象的数据具象化,结合不同交互以分析人物之间的虚拟社交特点以及对现实社交关系再发展的影响.
猜你喜欢
Chinese Physics B(2021年10期)2021-10-28 07:01:38
妈妈宝宝(2019年7期)2019-07-05 09:16:38
文苑(2018年17期)2018-11-09 01:29:38
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
第二课堂(初中版)(2016年11期)2016-12-01 20:20:50
南都娱乐周刊(2016年30期)2016-08-25 19:45:57
时代人物(2015年6期)2015-06-12 03:24:43
