
融合TextRank算法的中文短文本相似度计算
2020-10-19 10:14卢佳伟
电子科技 2020年10期
卢佳伟,陈 玮,尹 钟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
文本相似度计算是自然语言处理任务中的一个重要课题。提高文本相似度的准确性是提高文本处理后续任务准确度的关键所在。
目前大部分计算相似度的方法都会使用到基于向量空间模型(Vector Space Model,VSM)的方法[1]。传统方法只考虑了词语的频率,仅采用词频逆文档频率(TF-IDF)的方法对文本进行处理,得到一个由TF-IDF值表示的矩阵。该矩阵通常存在着很大的稀疏性,且这种计算方法所参考的是词语在文本中出现的频率。因此,该模型只包含了统计信息而忽略了文本中词与词之间的语义关联度[2]。文献[3]基于知识库和语料库来分析词语之间的语义相似度,最终提高了相似度算法的准确性。文献[4]计算出关键词加权的文本相似度,然后通过提取句子的主干成分对传统基于语法语义模型的方法进行改进,得到文本主干的语义相似度,最后对这两种相似度进行加权。文献[5~6]提出基于统计的文本向量特征之间存在相关性的观点,可以通过词汇语义信息表示,以此来改进相似度算法。从以上相关研究可以看出,语义相似度逐渐成为文本相似度研究的倾向重点。
随着深度学习技术的发展,很多研究人员将词向量应用到各种自然语言处理任务中并且取得了理想的效果。利用Word2vec模型将文本信息转化为向量矩阵,通过计算向量空间的距离来表示文本语义上的相似度。文献[7]采用Word2vec模型在中文语料上进行关键字提取的研究获得了不错的效果。文献[8]使用Word2vec来计算词语之间的相似度,将其作为TextRank的新的权重节点来提升关键字提取的性能。近年来, ELMO、GPT和BERT这些词向量预训练方法被相继提出,其中BERT模型在NLP的11个任务中刷新了成绩,取得了惊人的效果。BERT的模型架构是一个多层双向的转换编码器,与其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示模型,通过使用双向信息来关联上下文从而提升效果[9]。
综上所述,本文提出一种新的文本相似度计算方法,在融合改进的TextRank关键字提取算法的同时,分别采用Word2vec与Bert词向量技术来对文本进行预处理,并且测试不同的距离计算公式以选取最优的模型。通过对比其他算法可知,融合了TextRank与Bert词向量的相似度计算方法获得了良好的效果。
1 改进的文本相似度计算方法
本文提出一种新的文本相似度检测方法,即融合关键字提取技术与词向量方法的文本相似度计算。该方法首先对文本进行分词、去停用词的过滤处理,随后使用关键字提取算法将文本的特征信息提取出来,也就是将文本的语义信息保留并除去冗余信息。然后,采用词向量技术构建词向量空间。最后通过不同的向量距离公式计算文本之间的相似度。
1.1 TF-IDF提取算法
词频(Term Frequency,TF),即在文本中词语的出现次数。然而在文本中出现次数较多的词并不一定是关键词,因此通常会构建一个调整系数来确定一个词的常见度,该权重为逆文档频率(Inverse Document Frequency,IDF),它的大小与一个词的常见程度成反比。得到TF和IDF之后,两个值的乘积即为TF-IDF值,其计算如式(1)和式(2)所示。TF-IDF值越高则表示该词在文本中的重要性越强。
(1)
(2)
该计算通常会对IDF做平滑处理,从而使语料库中没有出现的词也可以得到一个合适的IDF值。如式(2)所示,分子、分母及整体式子都加1,以此来降低矩阵的稀疏性。上述两式相乘即为TF-IDF值。TF-IDF算法具有简单快速的特点,但是单纯依靠“词频”来评判一个词的重要性显然是不够的。
1.2 改进的TextRank算法
TextRank算法是一种基于图论的排序算法。它的基本思想主要来源于谷歌的PageRank算法,通过把文本分割成若干组成单元(单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序,仅利用单篇文档本身的信息即可实现关键词提取[10]。
TextRank的模型一般由一个有向有权图G=(V,E)来表示,V表示图的节点,E表示图的边。图中任意两个节点Vi与Vj之间边的权重为Wij,用于表示两个节点之间边连接的重要程度。对于一个给定的点Vi,lnVi为指向该点的点集合,Out(Vi)为Vi指向的点集合。点Vi的得分定义如式(3)所示。
(3)
其中,d代表阻尼系数,一般取值为0.85,其意义在于能够表示当前节点向其他任意节点跳转的概率,同时能够让权重稳定地传递至收敛[11]。
在关键字提取的过程中,候选关键词的边是由共现关系决定的,而共现关系又由共现窗口window影响。该窗口表示每次最多出现w个词语,通过每次向右滑动一个窗口来建立词语间的共现关系。在改进的算法中,本文将窗口window数量提升至5个,即考虑某关键词的周围10个词语的共现关系,同时引入Word2vec词向量来表征两个节点词,进一步增强关键词与关键词之间的相关性,改进的计算式如式(4)所示。
(4)
原式(3)中Wij即为点i与j组成的边对应的权重值。考虑到词语的Word2vec词向量之间的关系,可以通过计算两个词向量之间向量矩阵的余弦距离,增加一个权重来进一步反馈出节点词之间的相关性。如式(5)所示,Rvi、Rvj分别代表两个词的向量矩阵,cos函数计算参考式(6)。
w2vij=cos(Rvi,Rvj)
(5)
通过加入词向量相关性系数权重,改进了TextRank算法在词汇语义关系上的不足,使得提取出的关键词更加能够突出某个事件,比如在一段文本中有3个词汇,分别为科比、湖人、骑士。显然前两者之间的词向量关系是大于后两者的(在维基百科的词向量训练中,科比、湖人这两个词语一般是频繁同时出现的)。因此科比、湖人两个词之间会有更高的相关性。在一段文本中,整体提取的关键字相关性增长后会更有利于文本主题信息的挖掘,从而能更好地计算文本相似度。
1.3 Word2vec词向量
Word2vec主要采用词袋模型(Continuous Bag-of-Words,CBOW)和跳字模型(Skip-Gram)两种模型。CBOW模型和Skip-Gram模型都是在霍夫曼树的基础上实现的。霍夫曼树中非叶节点(子节点)储存的中间向量的初始化值为零向量,叶节点所对应的单词的词向量是随机初始化的。跳字模型是由当前词语来预测上下文的概率,而词袋模型则是根据上下文来预测当前词语的概率。算法开始时,每一个单词都是一个随机N维向量,经过神经网络的训练之后,通过建立词袋模型或跳字模型获得每个单词的最优向量,随之也就建立起词向量空间。对于处理文本而言,Word2vec是当下尤为关键的一个技术[12]。
CBOW是根据上下文的词语预测当前词语出现概率的模型。如图1所示,该模型总共分为3层:INPUT层、PROJECTION层、OUTPUT层。
INPUT层表示某个词周围n个窗口大小的词的词向量。n为2时,则表示当前词的前后2个词。借助Huffman树,PROJECTION层的值沿着Huffman树持续进行logistic分类,其间不断修正各中间向量和词向量,最终处理完所有节点到达叶节点结束流程,完成w(t)的词向量输出。
Skip-Gram模型也由INPUT层、PROJECTION层、OUTPUT层构成,二者相比只有细微的不同。跳字模型的输入是当前词的词向量,输出为当前词周围n个窗口的词向量,即通过当前词来预测周围的词。如图2所示,同样构建Huffman树来完成词向量的表示。
本文依据Word2vec的模型方法,采用的是CBOW来训练中文维基百科的语料,最终得到352 217个维度为300的词向量。
1.4 Bert词向量
BERT是一种新的语言表示模型,它使用Transformer的双向编码器表示。与之前的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。BERT提出一种新的预训练目标,即遮蔽语言模型(Masked Language Model,MLM)来克服标准语言模型的单向性局限。MLM随机遮蔽模型输入中的一些Token,目标在于只通过遮蔽词的语境来预测其原始词汇ID。与从左到右的语言模型预训练不同,MLM目标允许表征融合左右两侧的语境,以此来训练出一个深度双向Transformer[13]。具体的结构图如图3所示。
BERT模型输出词向量的方式如下图4所示,对于每一个输入的词,它的表征包括Token Embeddings、段落表征(Segment Embeddings)和位置表征(Positions Embeddings)。其中每一句话使用CLS和SEP作为开头和结尾的标记,单个段落文本使用一个Segment Embedding。最终的词向量输出结果为这3个Embedding层拼接而成。
在之后的仿真实验中,本文采用了官方预训练好的中文BERT模型来对文本进行向量化处理,每一个测试文本生成的矩阵维度为768维。
1.5 相似度距离计算
经过向量化处理之后,接下来则进行文本的相似度计算。在此之前,研究人员已经提出了很多用于处理文本向量距离的计算方法,本文主要采用余弦距离和欧式距离这两种方法来计算相似度。
1.5.1 余弦距离
余弦距离是使用余弦公式来计算文本间的向量距离,通过计算向量之间的夹角大小来判断这两个向量的相似度,它与向量各个维度的相对大小有关系,不会受到各个维度的直接数值影响。对于向量空间中的两个点X和Y,其余弦距离如式(6)所示。
(6)
余弦的夹角取值为[-1,1],因此需要对余弦距离计算式进行归一化[14]。这里采用式(7)将其阈值范围归一化到[0,1]。
d1=0.5+0.5×cos(X,Y)
(7)
1.5.2 欧氏距离
欧式距离(以下简称em)是一种非常基本的距离运算公式,实际上也就是在空间中的两个点的距离量度,和两个点的坐标信息有关。对于X和Y这两个点欧氏距离如式(8)所示。
(8)
同样欧氏距离也需要对其进行归一化,即进行如式(9)所示处理。
d2=1/(1+em(X,Y))
(9)
最后,将以上两种距离取平均值作为新的距离计算式,平均距离(以下简称mean),平均距离计算如下
d3=(d1+d2)/2
(10)
本文使用式(7)、式(9)和式(10)进行文本相似度距离的计算,通常在计算时需要一个阈值来进行判定。参考以往研究人员的经验,本文将阈值设定为0.7,即超过0.7阈值的两个文本认定为相似文本,反之则为不相似文本。
2 实验与分析
本文实验环境为:Windows10 Inter Core(TM)i5-7200U CPU @2.5GHz,使用Python3.5版本语言,采用 jieba分词工具包以及Github开源项目肖涵博士的Bert-as-service包。所有实验数据均提前采用分词过滤词的预处理[15]。
2.1 数据集
目前国内外还没有专门的中文文本相似度检测的公共测试集。文献[16]中采用了人工标注的50对中文语句作为数据集。文献[4]中也通过采用200对从知网、百度、Google等平台构建的句子来进行仿真实验。本文采用人工的方法构建了400对语句,共计800篇新闻文本,分别来自各大新闻门户网站,包括娱乐、体育、军事等新闻的数据,由实验室成员精心标注分析,其中200对为相似文本,另外200对不相似。
同时本文选用THUCNews数据集的新闻短文本进行测试。THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。该数据集分为体育、财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐等10个类别。本文在此10类数据集上分别选出1 000篇共计10 000篇新闻短文本作为测试集。
2.2 评估标准
机器学习中常用的模型性能评估方法为召回率(Recall,R)、准确率(Precision,P),仅凭这两项还无法整体评估出算法的性能,还需要引入F1值,F1的评估定义如式(11)所示。
(11)
2.3 实验结果分析
在进行相似度检测前,还需要对提取的关键字数量进行测试,提取关键字的数量将会影响到算法的性能。由于本研究所选取的文本均为新闻文本,篇幅不长,所以设置文本提取的关键字测试字数为6、7、8、9、10、11、12、13、14、15。按照设置的关键字数在人工构建的400对新闻短文本上使用TF-IDF算法(TI)、TextRank算法(TR)以及改进的TextRank算法(Imp-TR)上进行仿真实验,主要在Word2vec词向量模型上进行测试,实验结果如图5所示。
从图5中可以看出,各个组合算法模型的F1值都在随着关键字提取数的增加而上升,但是在达到数量10之后,曲线开始变得平滑且部分模型的曲线出现下滑现象,说明关键字提取的字数对模型产生了影响,具体的算法模型数值参考表1。结合图5和表1,在接下来的THUCNews数据集上将关键字提取数设置为10。
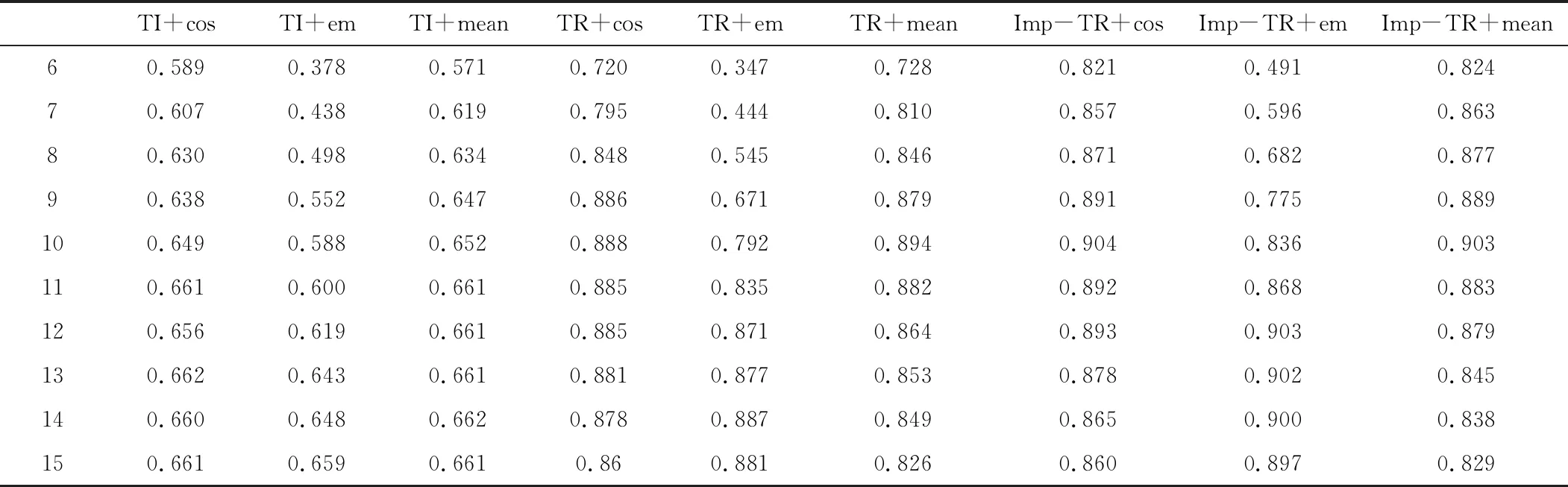
表1 基于关键字提取数量的算法模型F1值表
表2展示了不同相似度算法模型在人工选取数据集的准确率、召回率、F1值。W2v表示Word2vec词向量,括号内数字表示获得最佳性能的关键字提取字数。

表2 人工选取数据集测试结果
从表2中可以看出,词向量距离计算式、关键字提取方法的引入和关键字提取字数都对模型最后的结果产生了影响。因此初步可以得出如下结论:(1)对比传统的VSM向量空间结合TF-IDF矩阵的模型,本文提出的新相似度检测方法效果更好;(2)采用关键字提取算法之后,相似度检测的F1值得到了显著的提升,并且在3种提取算法中,改进的TextRank算法性能稍稍领先;(3)3种距离计算式对模型的影响效果不大,但是使用cos余弦距离计算式有略微优势。
仅在小样本上得出如上结论显然是不够充分的,因此接下来在THUCNews大数据集上再次进行了仿真实验,并且使用Word2vec和BERT两种不同的词向量预训练方法进行对比。实验结果如表3和表4所示。

表3 THUCNews数据集测试结果-Word2vec

表4 THUCNews数据集测试结果-BERT
从表3和表4中可以看出,采用改进的TextRank算法的模型在大数据集上依然取得了较好的效果,进一步说明了本文所提改进的文本相似度算法的有效性。基于Word2vec的模型获得了0.88的F1值得分,而在BERT模型上获得了最好的效果,F1值提升到了0.932,同时其他采用BERT模型的方法都有着不错的效果提升,相比于Word2vec,BERT预训练词向量方法有着更加出色的效果。
3 结束语
文本提出了一种新的文本相似度计算方法,融合了关键字提取算法与词向量表征模型,采用3种不同的距离计算式计算文本相似度。其中,通过改进TextRank算法提高了关键字提取的效果,并通过引入Word2vec和BERT两种预训练词向量方法超越了传统的VSM向量空间模型。本研究在小样本测试集上测试出关键字提取最佳字数后,在大样本THUCNews数据集上再进行所有模型的仿真实验。最终,BERT+Imp-TR-cos(改进的TextRank算法结合余弦距离公式与BERT词向量)的组合模型获得了最佳的F1值效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华人时刊(2022年1期)2022-04-26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
动漫界·幼教365(大班)(2019年10期)2019-10-28
小学生导刊(2018年34期)2018-12-18
思维与智慧·上半月(2018年11期)2018-11-30
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
