
面向用户隐私保护的联邦安全树算法
2020-10-18 12:57张君如赵晓焱袁培燕
计算机应用 2020年10期
张君如,赵晓焱,2*,袁培燕,2
(1.河南师范大学计算机与信息工程学院,河南新乡 453007;2.教学资源与教育质量评估大数据河南省工程实验室(河南师范大学),河南新乡 453007)
(*通信作者电子邮箱zhaoxiaoyan@htu.cn)
0 引言
随着各种新型增强宽带业务的蓬勃发展,网络流量急剧上升,大量用户线上和线下行为数据也日益完善。这些数据的深度挖掘与合理利用可以帮助运营商和服务商有效预测用户下一步的行为,并且更好地指导产品的优化以及业务的精细化运营。在现有行为预测研究中,大多数学者运用K-means聚类[1]、深度森林[2]等传统机器学习方法来完成对用户的个性化产品推荐或者情景感知等服务。例如,Salehinejad等[3]提出了一种以购买信息、忠诚度等作为变量的回归神经网络顾客行为预测模型;Baumann 等[4]利用Python 中的Network X 框架生成的特征信息来构建用户行为预测模型。但是,传统机器学习方法的高性能都是基于大规模数据库的支持,而现实情景中很难实现大规模用户数据的集中训练,原因主要有两个方面:一方面从个人层面来说,个人数据存在不当收集和用户隐私泄露等问题;另一方面从企业层面来说,由于行业竞争、隐私政策等问题,在现实生活中想要把分散在不同公司或政府组织中的数据集进行整合几乎是不可能的,或者是需要巨大成本。因此,传统人工智能架构应用场景严重受限。如何在不泄漏数据隐私和保障信息安全的前提下完成大规模数据训练成为当前学术界热议的话题。
在此背景下,谷歌率先提出的联邦学习技术应运而生。作为端侧人工智能的算法,联邦机器学习[5]具有保护数据隐私、运行可靠性高等优点,逐渐成为模型训练的发展趋势之一。联邦学习利用各参与方对本地的数据进行处理,通过控制各方之间通信与运算交替更新模型参数,使得在己方数据不泄漏的情况下,尽可能保证所得模型与将数据聚合一方的非联邦模型之间的差距足够小。例如,文献[6]中提出了一种对模型量化压缩的计算方法来实现联邦学习;文献[7]设计了一系列协议来实现分类和回归树保护隐私的功能,并证明其具有一定安全性和高效性;文献[8]中提出联邦学习FATE(Federated AI Technology Enabler)框架,通过设计一种SecureBoost算法来解决隐私保护下的多方参与与数据共享问题,并通过实验证明该算法与其他非联合梯度树增强算法近似准确;文献[9-11]考虑到模型上传云端所花费的时间,采取迁移学习的方法对模型特定层进行训练从而压缩模型上传的通信成本,完成模型训练;文献[12]中提出了一种保护隐私的Federated Forest 机器学习算法,允许在具有相同用户样本但属性集不同的不同区域的客户上共同训练学习,并证明了该算法可以减少通信开销;文献[13]利用随机线性分类器(Random Linear Classifier,RLC)作为联邦学习中的基本分类器,达到简化隐私保护协议的目的。但是上述对联邦学习体系的研究存在两个值得关注的问题:第一,实际应用问题。对联邦学习的研究和实验大多是以理想情况为前提,没有考虑在多方参与情景下可能出现的风险和问题,缺少在现实场景下对联邦学习算法的仿真和验证。第二,算法效果问题。联邦学习在多方数据的训练上仍然存在通信成本高和训练效果差等问题,即如何有效提升联邦学习的运行效率和算法准确率也是当前联邦学习值得研究和探讨的方向。
因此,为解决以上问题,本文对预测性能较好的Xgboost算法[14]进行分析和改进,提出了一种联邦学习安全树(Federated Learning Security tree,FLSectree)算法,以用户行为预测为应用场景,使得在保护数据隐私的前提下,实现联邦算法在准确率和运行效率上的高质量训练。本文主要工作如下:1)提出一种面向多方的用户行为预测架构,实现联邦学习在现实场景下对数据隐私保护的应用价值;2)提出FLSectree算法,通过联合各参与方共同训练高质量集成树,有效地提升用户行为预测模型中联邦学习算法的准确性和运行效率。
1 用户行为预测架构
为了能够更准确预测用户个人的请求内容,同时实现对用户数据的保护,本文联系用户偏好、位置信息和社会背景[15]这三个方面建立基于联邦学习的用户行为预测架构,完成用户数据在本地的训练。
定义1主动方。联邦学习中提供标签值的一方称为主动方,在联邦学习中占领主导地位,参与较为复杂的决策运算。当然,主动方也可提供参与联合的其余特征集合。
定义2被动方。联邦学习中不提供标签值,只提供特征数据的一方称为被动方,在联邦模型的构建中只参与基础数据的提供,对于最终所预测的标签和树的结构完全不可知。
基于以上分析,本文构建基于联邦学习的用户行为预测架构如图1所示。首先,将用户行为预测的参与方分类如下。
1)被动方A:公共机构(社会背景),如银行、医院等,记录用户身份、性别、教育程度、职业、家庭情况以及收入信息。
2)主动方B:网络运营商(用户偏好),如Youtube、Facebook 等,记录用户的浏览文件和浏览方式。其中浏览文件为预测的标签向量。
3)被动方C:定位软件运营商(位置信息),如HERE、Google Earth等,记录用户浏览位置信息。
其次,由于用户的行为数据分散在不同的运营商中,为保证数据隐私和安全,不将多方数据进行直接交换,而是利用联邦学习在本地架构三方联邦学习系统。考虑到参与方自身训练能力有限,下发支持联邦学习的云服务器协助完成强大的联邦学习过程,其中服务器重点对主动方B 进行监控和保护。最终,在每个运营商本地训练出自己的行为预测模型,实现在保护用户隐私的前提下,联合多方数据达到成功构建用户行为预测模型的目的。
接下来,本文将针对如何实现提出的联邦用户行为预测架构展开讨论,并在传统机器学习算法基础上提出一种新的能够充分保护用户隐私的联邦学习安全树FLSectree 用户行为预测算法。
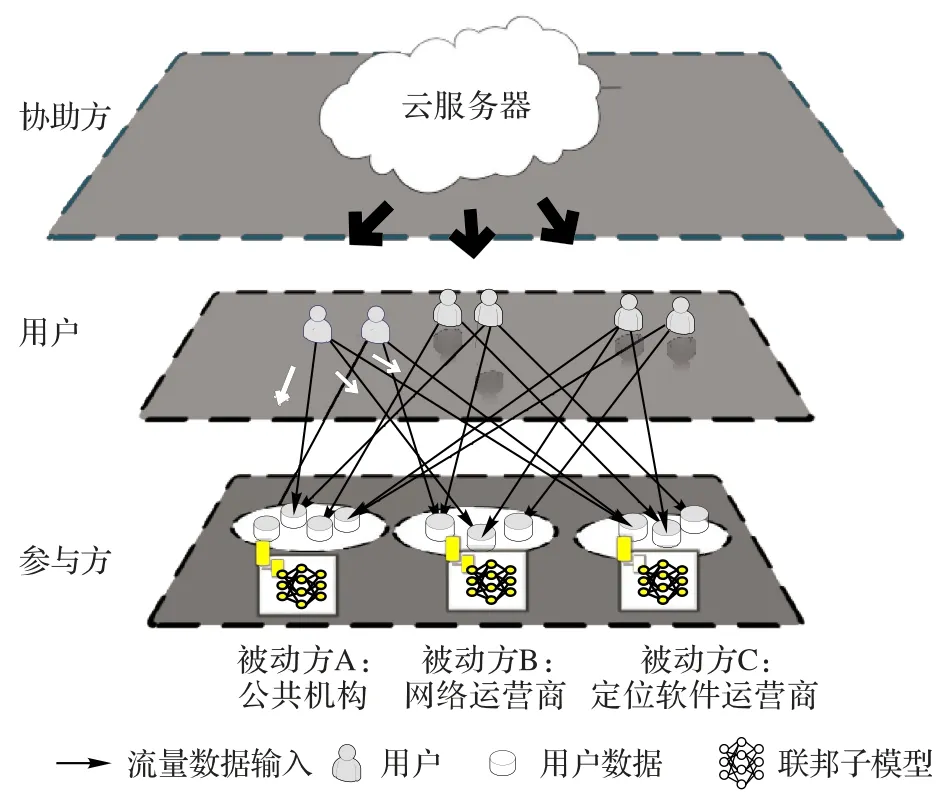
图1 基于联邦学习的用户行为预测架构Fig.1 User behavior prediction architecture based on federated learning
2 本文的FLSectree算法
本文将参与方在共同建模过程存在泄露数据隐私风险的参数称为敏感数据。为挖掘联邦学习过程中的敏感数据,实现对数据隐私的保护,本文的FLSectree 算法通过扫描特征索引序列和加密分裂点等方法,减少参与方的通信次数,保证在不降低算法准确率的前提下,完成对参与方的本地模型训练,实现对用户行为的高质量预测。
2.1 算法实现步骤
本文设定损失函数与正则化项之和作为算法的目标函数。为推导出联邦模型构建过程中潜在的敏感数据,同时,实现目标函数最小化,本文对损失函数关于的一阶偏导数和二阶偏导数进行定义,如式(1)所示:

并选取逻辑回归损失,如式(2)所示:
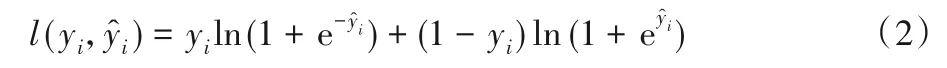
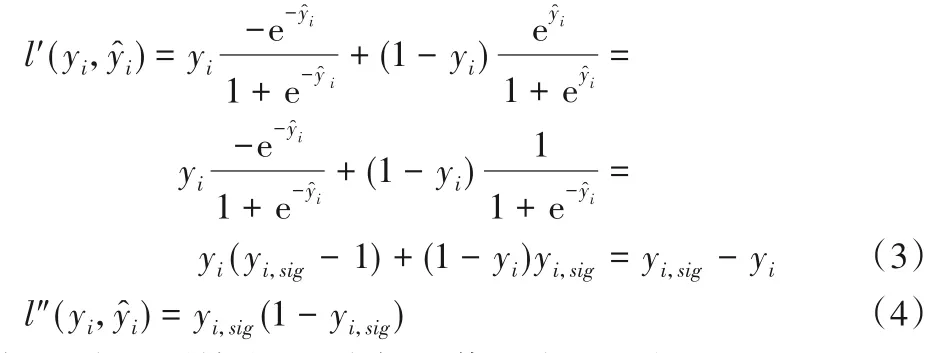
1)确定参与方联邦权利。信息宿主方向各个参与方下发公钥;参与方则划定样本区域,并设定样本交集编号ID={1,2,…,N}对于各个参与方是可知的。
2)将被动方进行特征排序和填充。被动方根据自己所拥有特征集合,根据特征值大小从小到大进行排序,形成其对应ID 编号序列,称为特征索引序列集。每方每个特征序列集一起形成有序特征集,在每组特征序列集中,特征不同值所对应ID之间插入特殊字符α,其中对于缺失值按照独立值处理。被动方将其特征序列集发送给主动方,注意在传送的特征序列集中,只有已协商好的ID编号和特殊字符α,不涉及特征数值的传输,并且此传输过程在整个训练中只涉及一次。
3)主动方进行扫描与分裂。为提取分裂依据,本文采用泰勒公式(5)对第t次迭代目标函数进行二阶展开:

其中:Ω(ft)为正则项;fk为第k棵树模型。从目标函数式(6)可知,其中只有一个变量ft(xi)。为找到一个ft最小化目标函数,主动方对产生的叶子节点进行归组,将属于第j个叶子节点的所有样本xi划入到一个叶子节点样本集中,表示为I={i|q(xi)=j},将树的复杂度式(7)代入式(6)可得:

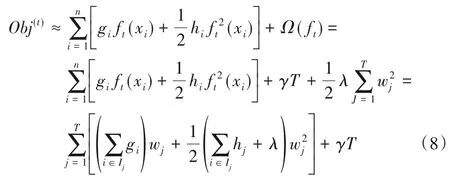
其中:T为叶子节点数;w为叶子权重值;γ为叶子树惩罚正则项;λ为叶子权重惩罚正则项。为进一步简化目标函数,本文做如下定义:

将式(9)代入式(8),得到最终目标函数为式(10),并对目标函数中每个叶子节点j拆解如式(11)所示:

由于Gj和Hj相对于第t棵树可推,则每个叶子节点分值相当于w j的一元二次函数。因为各叶子节点目标子式相互独立,当每个叶子节点分值达到最值时,整个目标函数达到最值。由一元二次函数的最值公式,计算得到当每个叶子节点权重达到时,可达到最优目标函数为:
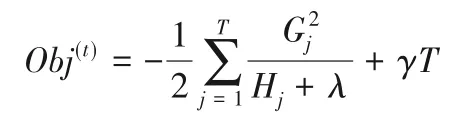
因此,主动方针对不同分裂点,将其ID 编号所对应的gi和hi进行提取,设定节点的划分依据为每次分裂是否带给损失函数的增益,即有增益Gain的定义为:

主动方利用式(12)计算所产生的增益Gain。当主动方对所有特征序列集的所有可能划分节点进行一次扫描后,选取最大Gain值作为分裂点。然后,主动方按照层次遍历法,对每个节点从1 开始进行编号,设编号为leaft(1 ≤leaft≤2max_depth-1)。主动方将对应分裂出的节点编号leaft进行加密,设分裂点处的ID 编号u,特征类别为v,主动方将信息只返回给分裂出该点的相应被动方。接收到信息的被动方根据u和v,找到对应特征中具体值的分裂点,同时注意保留加密后的。
4)主动方根据此次分裂后的左右节点实例空间,对将每个特征序列集中的对应的相应实例空间进行提取,重复以上步骤,直到叶子节点产生,同时主动方计算相应叶子权重w。当达到设定的最大深度max_depth后,整棵树构建完成。
算法1 FLSectree训练过程。

FLSectree 训练结束后,预测过程较为简单,预测样本将公钥下发给主动方和被动方。被动方判断所拥有预测样本的特征信息,得到判断结果result leaft∈{L,R},即归属左子节点或右子节点。被动方对自己拥有的所有分裂节点判断结果和加密节点编号进行汇总发送给主动方。主动方解密后代入已知树结构中,得到最终预测结果。
算法2 FLSectree预测过程。

从集成树构建上来看,不需要通过被动方参与计算gi和hi,主动方就可以完成对最佳分裂点的求解。从隐私保护上来看,只有主动方gi和hi直接涉及标签值yi的获取问题。在整个构建过程中,主动方完全把握对gi和hi的使用权,而其余参与方只能参与特征值数据的提供,对于所预测标签完全不可见。因此,该集成树在一定程度上是安全的。
2.2 联邦问题应对机制
为了应对联邦学习中可能出现数据掩蔽、参与方退出以及数据量过大而导致训练时间过长等问题,本文设定在FLSectree 构建过程中,分配一个不偏向任意一方的轻量级服务器,由用户对其进行直接管控,协助联邦各方完成训练,并且设定一个有效的问题应对机制对联邦学习中的参与方进行规范和约束,从而增强算法的健壮性,保证训练正常进行。本文提出的联邦问题应对机制具体如下:
1)参与各方的数据不统一。FLSectree 算法考虑两种解决方法:第一,数据量相差过大时,考虑选取重合部分最多的交集参与训练,对于空缺值按照缺失值处理;第二,如果数据量相差较少,则直接按照缺失值处理。
2)主动方在训练过程中退出。如果主动方拒绝参与本轮训练,则用户可以寻找其他认可的主动方或者用户信任的轻量级服务器替代完成分裂点的增益计算。
3)被动方在训练过程中退出。如果某个被动方要求掩蔽部分节点不参与训练,则将其掩蔽特征值作为缺失值处理,如果某个被动方要求退出所有节点的训练或掩蔽率到达设定阈值,则收回对其下发的公钥,忽略它在本次FLSectree 中构建的节点即可。
4)主动方在推断过程中退出。要求将主动方训练好的模型直接返回给信息宿主,用户可以选择其他可信任的主动方或者信任的轻量级服务器协助完成剩余推断,且退出的主动方不再参与下轮训练。
5)被动方在推断过程中退出。如果该被动方的节点分裂走向在FLSectree 推断过程恰好没有影响,则直接回收该被动方公钥,并将其从联邦方中删除;如果缺失该被动方无法完成推断,则要求该被动方将其训练完毕的半模型返回给用户信任的轻量级服务器完成剩余结果的推断。
6)参与联合的任意一方无法负担其运算量。当数据量过大或计算流量过多时,参与方运算缓慢导致联邦系统出现问题时,由用户信任的服务器协助各方完成部分计算,保证每个参与方的训练能够有效完成,从而优化架构的整体运算能力。
3 实验与结果分析
本文联合不同机构和企业数据对FLSectree 算法在用户行为预测中的效果进行仿真实验。为测试本文算法的有效性,采用Outbrain在560个网站上发布7亿不同用户的20亿页面浏览量数据集(https://www.kaggle.com/c/outbrain-clickprediction),提取编号 为234、236、515、2 191、2 861、452、4 099、4 154 共8 种页面作为兴趣预测标签,同时选取对应美国加利福尼亚州、美国科罗拉多州、美国北卡罗来纳州、加拿大曼尼托巴省、加拿大不列颠哥伦比亚省、加拿大魁北克省共6 种浏览位置和电脑端、手机端、平板端3 种浏览方式,共计2 231 条记录作为本次实验数据集。由于个人身份信息不易获取,本文采用韩国延世大学(Yonsei)研发部署的移动监控系统LifeMap(http://lifemap.yonsei.ac.kr)对用户平均6 个月在韩国首尔的移动性数据,根据用户经常出现的场景及位置的语义信息,仿真产生公共机构方所持有的数据。基于本文提出的用户行为预测架构,向不同机构分配相应数据集,实验环境设置三台(8 GB RAM,Intel Core i7-6500u CPU,Windows 10)机器模拟三个不同的机构,设置一个处理器为CentOS 7.3的轻量级服务器作为协助方。实验程序由Python和Matlab共同完成。随机提取不同机构对应数据集中100、500、1 000、1 500、2 000 条记录分别实验,同时选取前70%作为训练集,后30%作为测试集进行交叉验证。实验设定FLSectree 训练参数中,学习率eta=0.1,树的最大深度max_depth=5,迭代次数num_bound=5,分类个数num_class=8,正则项λ=1.0,损失函数采用逻辑回归和softmax做多分类预测结果。
为验证提出的FLSectree 算法的有效性,本文以准确率(ACCuracy,ACC)作为评价指标,在不同样本数量的情况下,将不考虑隐私保护情景下,完全将所有数据集中在一个中心位置的三种传统的分类预测算法,即集中式的随机森林(Random Forest,RF)算法,支持向量机(Support Vector Machine,SVM)算法和Xgboost 算法,同样采用联邦思想SecureBoost 算法[8],以及只有主动方一方训练的Xgboost 算法与FLSectree 算法在准确率的对比,实验结果如图2 所示。结果表明,集中式Xgboost 算法与FLSectree 算法完全重合,并且在整个过程中本文算法FLSectree 的准确率明显优于其他预测算法。当样本数量为100 时,FLSectree 准确率为0.733;当样本数量增加至2 000 时,FLSectree 准确率接近0.9,相较于文献[8]提升了9.09%。这是因为SectreeBoost 算法在加密过程中,为不泄露信息对节点构建进行限制,导致预测精度有所降低。而FLSectree 算法在训练过程中采取特征序列扫描和分裂的方法对集成树的节点进行无损分裂,故FLSectree 算法不会对算法参数造成损失。从整体来看,由于FLSectree 算法在目标函数中加入了正则项,从而提高了算法的泛化能力,相较于传统的SVM、RF 算法分别提升了55.45%和9.52%。从特征选择上,单方的Xgboost算法的准确率远远低于联合后的算法,这说明多方联合预测用户行为的有效性。
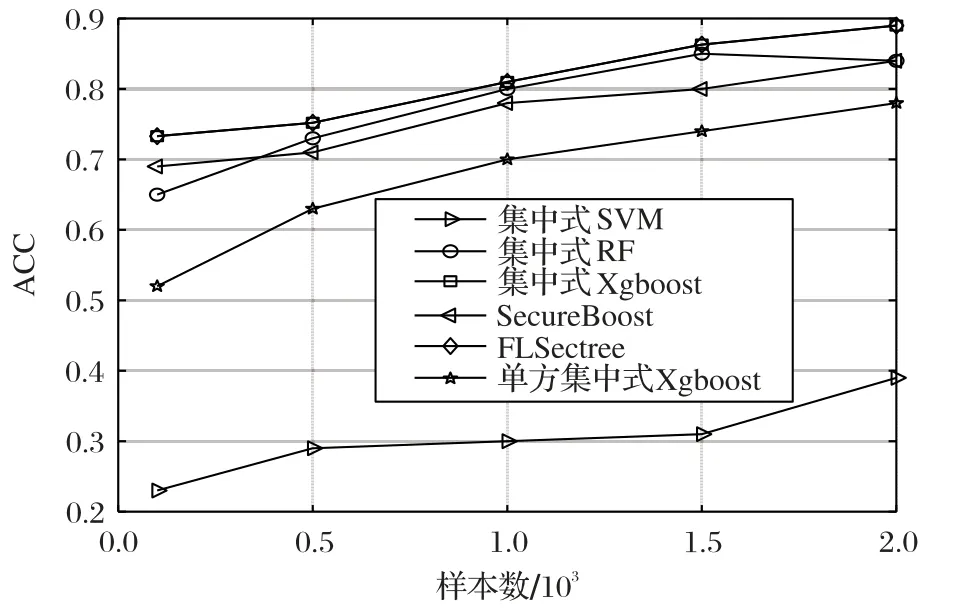
图2 不同样本量下不同算法准确率Fig.2 Accuracy of different algorithms with different sample sizes

图3 不同样本量下不同算法的运行时间Fig.3 Running times of different algorithms with different sample sizes
为验证FLSectree算法的运行效率,本文对FLSectree算法轻量级服务器协助、集中式Xgboost 算法、文献[8]中提出的SecureBoost算法在不同样本数量上完成所有训练的运行时间进行对比,实验结果如图3 所示。从图3 可以看出,除了数据量为变量,其他算法参数均相同。可以看到,SecureBoost算法的运行时间随数据量的增多急速上升,这是因为SecureBoost算法在每次寻找最佳分裂点时,都要对gi和hi进行同态加密并且要求主动方与被动方进行一次通信,对于每一次拆分其通信时间为2*z*d*ct,ct表示密文的大小,z表示与要拆分的节点关联的实例数,d是被动方保留的特征数。尽管后来提出用存储桶映射特征值,但这个通信成本仍然存在,特别是当分裂点过多时,会导致其总通信时间呈线性增长。而本文提出的FLSectree 算法在样本数量增多时,也没有出现运行时间陡然上升的情况,这是因为,从通信成本上来讲,在FLSectree算法的联邦学习过程中,主动方与被动方只进行1 次同步通信,大大减少了参与方之间的通信次数,进而减少了通信过程中不必要的响应时间。从计算成本上看,也省去了每次分裂都要对gi和hi加密和解密的时间。尽管主动方在对实例空间进行贪心分割时,会造成计算成本有所上升,但是算法所节约出的通信成本远远大于计算成本。因此,本文算法比SecureBoost 算法运行时间降低了87.42%。从图3 还可以看出,集中式Xgboost算法的运行时间远远低于其他联邦学习算法,这是由于集中式Xgboost算法是在一个位置对参与方的融合数据进行训练,不需要参与方进行通信,这也反映出通信成本确实是联邦学习耗费时间的关键因素。同时,实验还对有无服务器协助进行对比,发现设置服务器后,本文算法运行时间减少了9.85%,表明在部分情况下,特别是数据量较大时,服务器的协助对提高FLSectree 算法的运行效率有较为明显的作用。由联邦问题应对机制的设定可以看出,训练过程中参与方的掩蔽可能会对准确率有所影响,推断过程中参与方的退出可能会对运行时间有所影响。为进一步证明构建的FLSectree 算法的健壮性,分别模拟算法在训练和推断过程中,当被动方和主动方以不同比率执行掩蔽和退出操作时,本文算法在准确率和运行时间方面的变化情况,运行结果如图4~5所示。
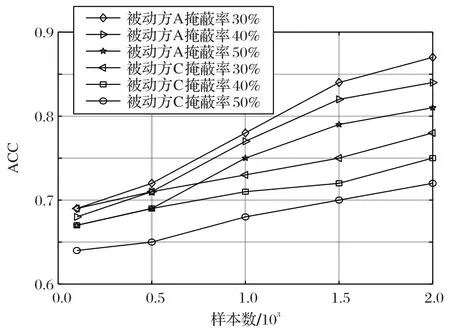
图4 训练过程中被动方掩蔽程度对准确率的影响Fig.4 Impact of passive masking degree on accuracy during training
图4描述了在训练过程中被动方A 和被动方C,即公共机构和定位软件运营商掩蔽对精确度的影响。从实验结果可以看出,定位软件运营商的掩蔽对精确度的影响更大一些,这可能是因为用户行为与位置之间的相关性更强造成的。并且,当两方的掩蔽率分别在到达50%和30%之前,本文算法准确率都能保持在0.8 以上。这是因为,FLSectree 算法相对于传统的Boosting 算法有一个明显的优势,通过缺失值在左右节点分配后的增益情况,对节点进行分裂,即对缺失值能自动学习分裂方向,极大程度上减小缺失值对算法的损失。因此,如果对掩蔽率阈值有较为合理的设定,能够很好地减缓预测准确率的下降。
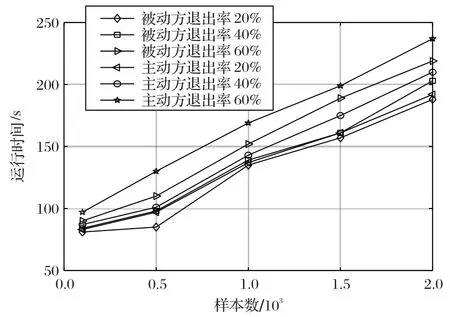
图5 推断过程中被动方和主动方退出对运行时间的影响Fig.5 Impact of passive and active exits on running time in inference process
图5 描述了在推断过程中主动方和被动方以不同程度的退出对运行时间的影响。实验结果表明,主动方和被动方不同程度的退出虽然会导致运行时间有所增加,但是整体增大幅度不超过9.58%,属于可接受的时间范围。这是因为设定的轻量级服务器可以有效承担测试任务,从而促使推断过程能够继续进行。而且从实验中可以看出,由于主动方存储整个树结构以及相应节点的加密信息,主动方的退出相对于被动方更影响运行时间,因此在向服务器交接时,往往会花费更多的通信成本。而被动方由于只是存储一些特征节点信息,在交付时通信时间较短,故其退出对运行时间影响较小。并且由于被动方部分节点信息不一定参与到联邦树的构造上,因此较低程度的退出对运行时间的影响较小。
4 结语
本文针对联邦学习中准确率和运行效率较低的情况,提出了一种无损失的FLSectree 算法,解决了在用户行为预测场景下保护数据隐私的问题。实验结果表明,FLSectree 算法与非联邦的Xgboost算法运行结果一致,有效提高了在用户行为预测场景下联邦学习算法的运行效率。在接下来的工作中,将挖掘更多刻画用户行为的特征数据,如用户轨迹中的时空特征、个人偏好等因素,进一步提升用户行为预测效果;也考虑将FLSectree 联邦算法应用于更广泛的领域,同时将联邦思想应用于更多机器学习算法,进一步推进在人工智能时代下联邦学习对大数据隐私的保护。
猜你喜欢
计算机研究与发展(2022年10期)2022-10-14
网络安全与数据管理(2022年1期)2022-08-29
天津外国语大学学报(2021年1期)2021-03-29
家庭影院技术(2020年10期)2020-12-14
VOGUE服饰与美容(2020年5期)2020-09-03
会计之友(2019年1期)2019-03-06
价值工程(2018年21期)2018-08-29
中国房地产·学术版(2016年7期)2016-10-21
俄罗斯问题研究(2013年1期)2013-03-11
