
基于FPGA集群的脉冲神经网络仿真器设计
2020-10-15 08:32张鲁飞张新伟郁龚健刘家航柴志雷
计算机工程 2020年10期
李 康,张鲁飞,张新伟,郁龚健,刘家航,吴 东,柴志雷,
(1.江南大学 物联网工程学院,江苏 无锡 214122; 2.数学工程与先进计算国家重点实验室,江苏 无锡 214215)
0 概述
随着新一代信息技术的快速发展,计算能力和数据处理速度得到大幅提升,人工智能已经进入大规模实用阶段,但深度学习还存在解释性差、通用智能水平弱等局限性[1],限制了人工智能的发展。而摩尔定律放缓、登纳德缩放定律失效,使得能效问题日益成为计算机系统发展的重要制约因素。而人脑是由多达1011个神经元和1015个突触组成的复杂网络系统,虽然其功耗只有20 W,但学习和认知能力却超强[2]。因此,世界各国纷纷启动脑科学计划[3-5],国内清华大学、北京大学、复旦大学等高校已相继成立研究平台开展类脑研究[6-7],希望通过解析大脑机理,发展类脑计算,克服深度学习的不足。类脑计算的基础是脉冲神经网络(Spiking Neural Network,SNN),SNN被誉为第三代人工神经网络[8],具有时空可模拟性、突触可塑性和支持脉冲编码等特点,相比第二代神经网络(如反向传播网络),在具备生物合理性的同时可达到更高的能效比。
目前,研究人员已提出多种支持脉冲神经网络的仿真器用于研究大脑机理和探索类脑计算系统,如NEST[9]、BRAIN2[10]和NEURON[11]等,这些仿真器均运行于通用处理器平台,虽然具有灵活性强、精度高等特点,但同时存在功耗高、仿真速度慢的缺点[12]。因此,寻找合适的脉冲神经网络硬件平台为神经科学家提供大规模的脉冲神经网络仿真和大脑皮层仿真服务成为亟待解决的问题[13]。现有主流解决方案采用专用集成电路(Application Specific Integrated Circuit,ASIC)、图像处理器(Graphics Processing Unit,GPU)、现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)作为脉冲神经网络仿真器的硬件平台[14]。其中,FPGA是一种强灵活性、高性能和低功耗的可编程逻辑器件。与研发周期较长、灵活性较差的ASIC及能耗高的GPU相比,FPGA更适合作为脉冲神经网络仿真器的硬件平台,其目前已得到广泛应用。文献[15]利用Maxeller Java的高层次综合(High-Level Synthesis,HLS)工具,采用时分复用、神经元模块并行计算的硬件架构,提出一种能够支持6块FPGA板卡的脉冲神经网络仿真器NeuroFlow。文献[16]利用开放运算语言(Open Computing Language,OpenCL)工具,设计基于FPGA且支持单精度浮点神经元计算模型的脉冲神经网络加速器。但上述两种脉冲神经网络仿真器并不兼容主流的脉冲神经网路仿真器接口,开发难度较大。
在众多脉冲神经网络仿真器中,NEST仿真器应用最广泛,其更加关注神经网络系统的动力学、规模及结构而不仅是单个神经元模型的精确形态,还可用于模拟不同规模的脉冲神经网络,如哺乳动物的皮质层微电路模型等[17]。文献[18]提出基于OpenCL且提供GPU加速服务的NEST仿真器,但其能耗较高。因此,本文设计一种支持FPGA集群的NEST仿真器,重点分析了NEST仿真器、漏电流整合放电(Leaky Integrate and Fire,LIF)神经元模型和皮质层视觉仿真模型[19]。
1 脉冲神经网络仿真器
在NEST脉冲神经网络仿真器中,实现了50多种神经元模型和10多种突触模型。突触模型包含静态突触和STDP突触等,神经元模型包含HH(Hodgkin-Huxley)、Izhikevich、LIF等[20],其计算复杂度和生物仿真精度依次降低。由于LIF神经元模型应用广泛且易于硬件实现[21],因此本文选取NEST仿真器中的LIF神经元模型作为FPGA硬件架构的实现。
1.1 LIF神经元模型
LIF神经元是一种电流指数衰减驱动型神经元,其基本原理是将产生脉冲的突触权重累加到突触后电流并进行指数衰减,衰减后的突触电流与膜电位相加得到新的神经元膜电位,如果神经元膜电位大于膜电位阈值便会产生脉冲。NEST仿真器中的LIF神经元模型在原LIF神经元的基础上进行离散化,并增加了外部电流参数和初始化电流参数。LIF神经元模型的计算方法如式(1)、式(2)所示:
Vm(t)=Vm(t-1)×P22+Si_syn_ex(t-1)×
P21ex+Si_syn_in(t-1)×P21in+
(Sie(t-1)+Si0(t-1))×P20
(1)
Vm(t)=Vreset且发送脉冲,Vm(t)≥Vth
(2)
在式(1)中,t为当前时刻,t-1为上一个时刻,Vm为膜电位,Si_syn_ex、Si_syn_in分别为兴奋型电流和抑制型电流,Sie、Si0分别为外部输入电流和初始化电流,P22为膜电位衰减因子,P21ex、P21in分别为兴奋型电流衰减因子和抑制型电流衰减因子,P20为初始化电流和外部电流的衰减因子,所有衰减因子在神经元初始化过程中均已计算完毕。在式(2)中,Vth为阈值电压,Vreset为复位电压。
1.2 NEST仿真器
NEST仿真器中的计算模式包含时间驱动型和事件驱动型,其神经元计算模式采用时间驱动型,即每一个仿真时间步长都会进行神经元计算,突触计算模式采用事件驱动型,即只有产生脉冲才会进行权重更新。除此之外,NEST仿真器中还存在最小延迟机制(如图1所示),其基本原理是在每个最小延迟内,神经元的更新并不会对其他神经元产生任何影响,只有在所有神经元更新结束后才会通过突触将累计的脉冲发送到目标神经元。
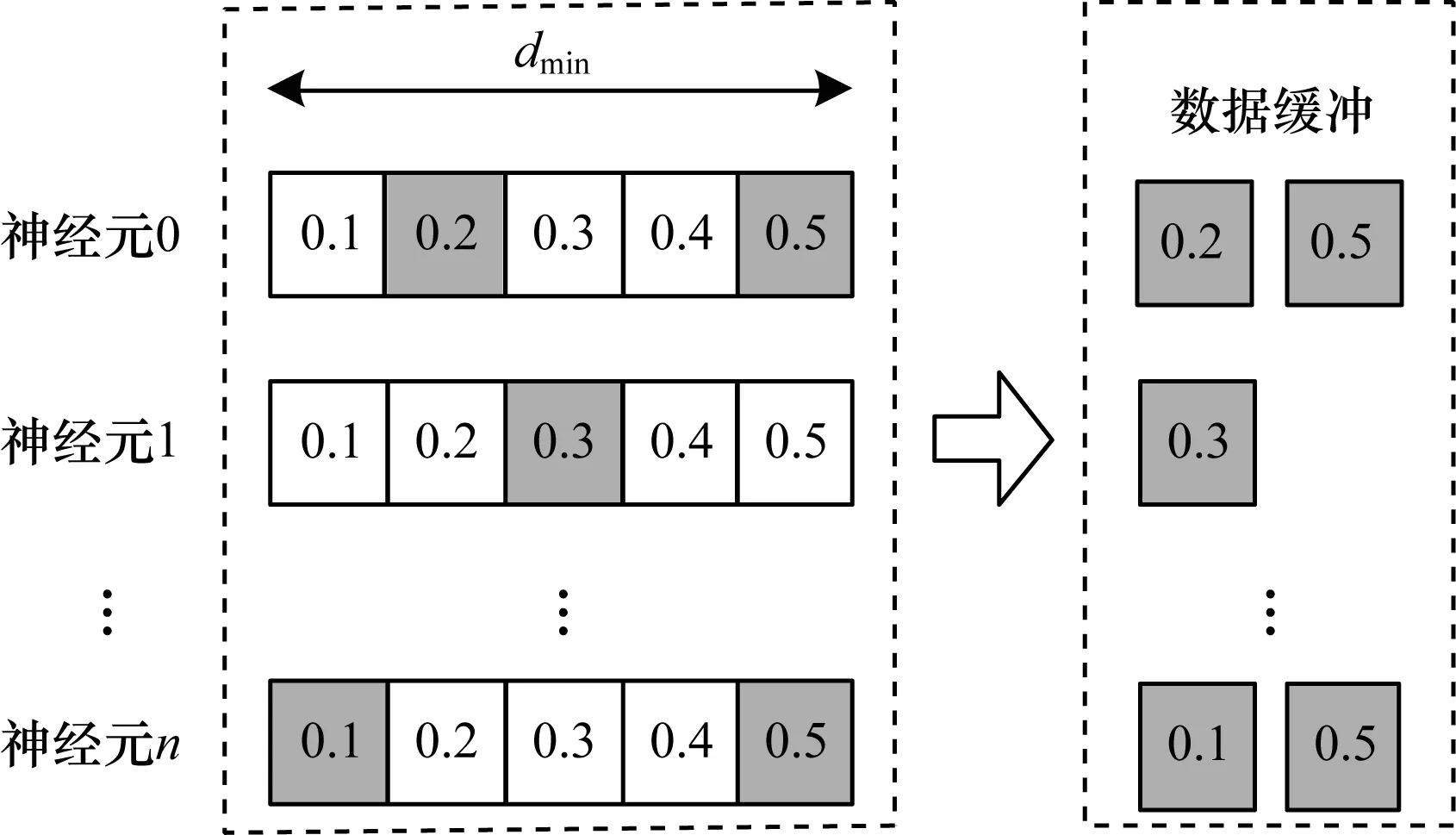
图1 NEST仿真器的最小延迟机制Fig.1 The minimum delay mechanism of NEST simulator
在图1中,dmin为最小延迟,若脉冲神经网络仿真精度为0.1 ms,则dmin为0.5 ms,LIF神经元更新的最小步长也为0.1 ms。在神经元发出脉冲后,将脉冲信息存储到数据缓存。采用最小延迟机制,即增加NEST仿真器中单个神经元的Cache生命周期,可减少大规模系统的通信损耗。另外,NEST神经元更新模块中还存在不应期机制,其基本原理是当神经元发射脉冲后便会处在不应期阶段,不应期阶段的神经元不会更新而只进行不应期计数递减,直至跳出不应期。NEST仿真器中神经元模型更新算法具体如下:
算法1神经元模型更新算法
输入仿真时间和神经元数量
输出脉冲信息和神经元输出
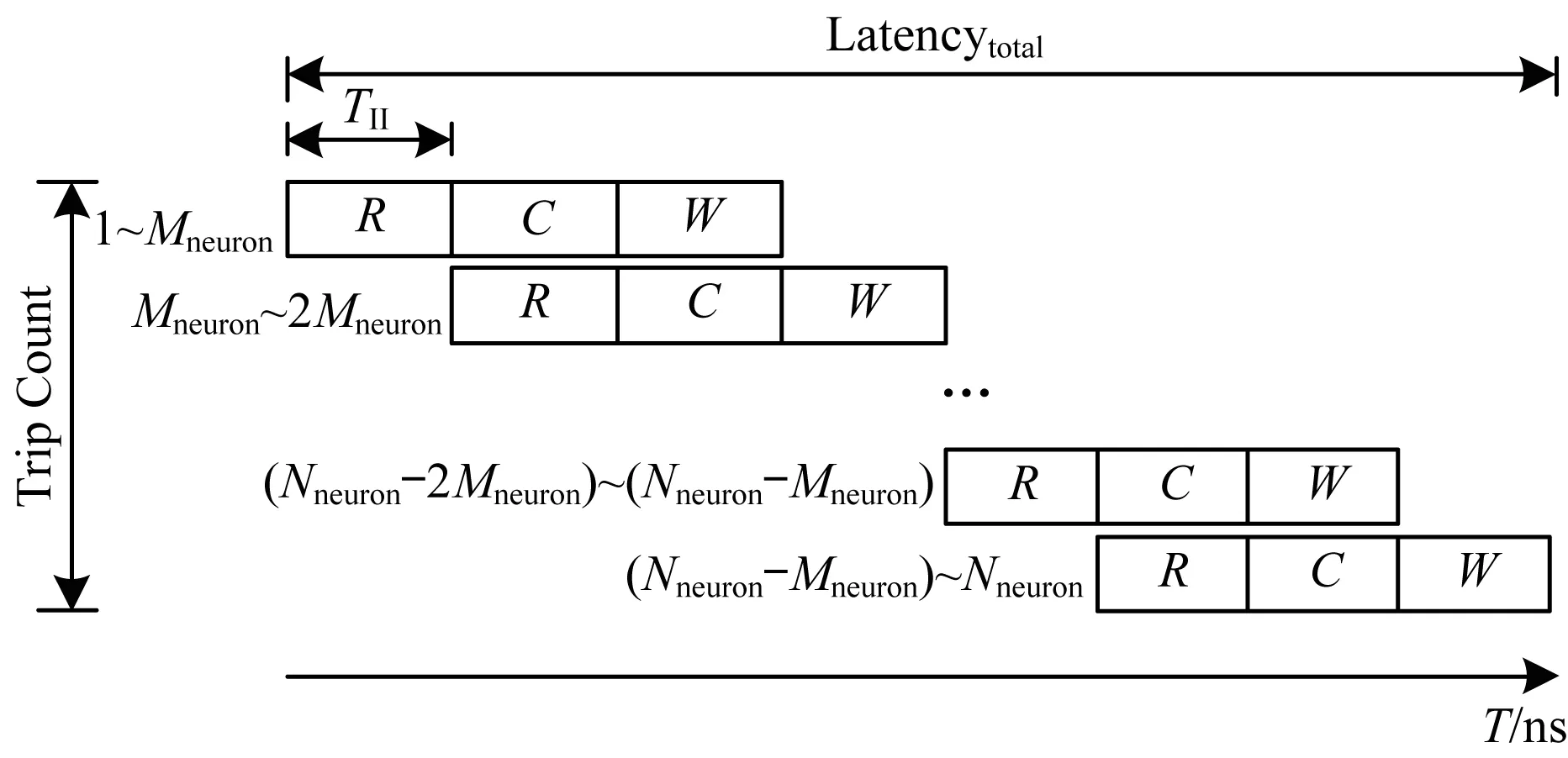
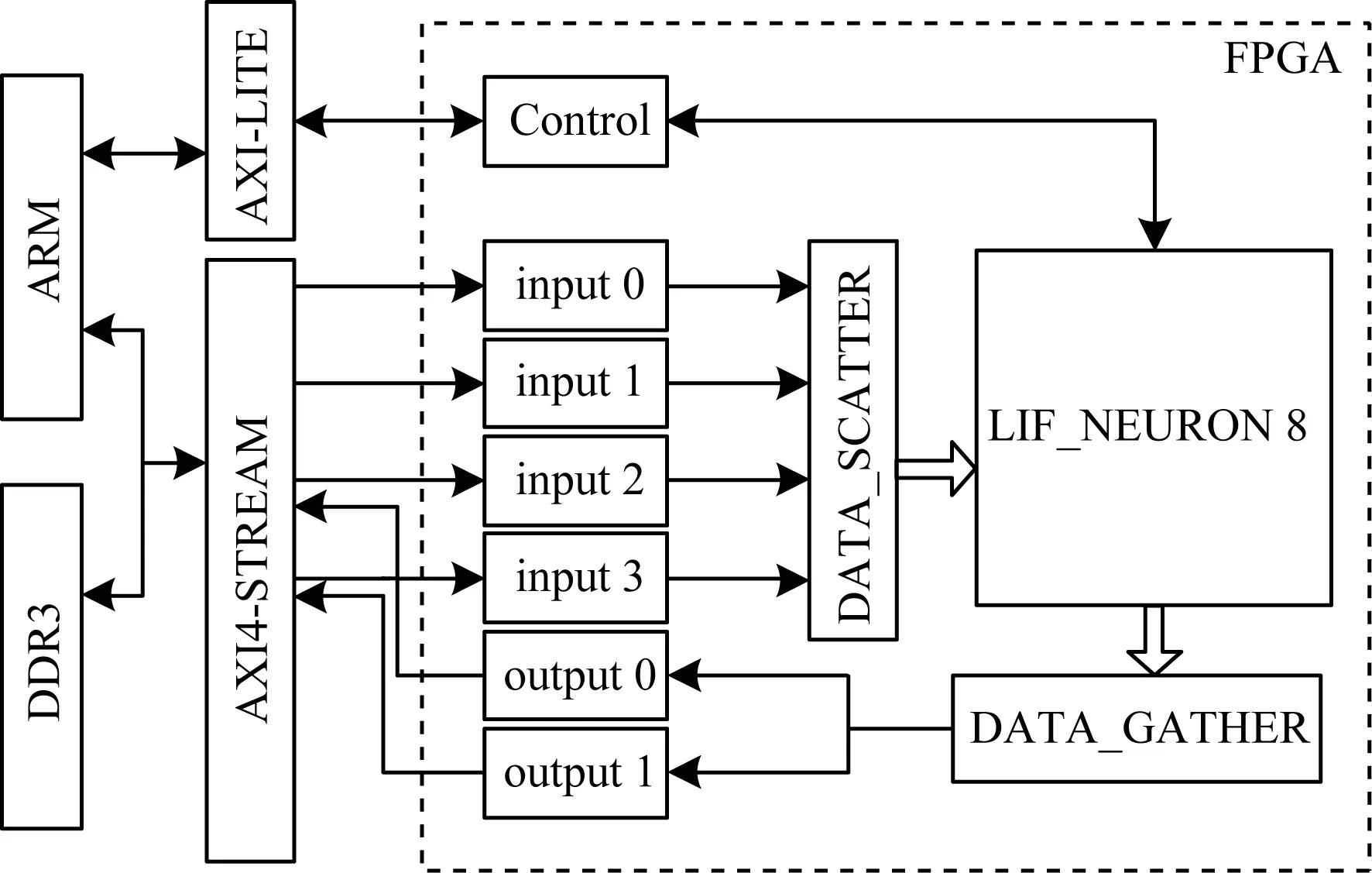
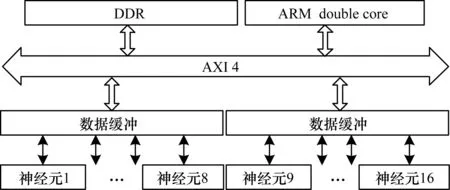
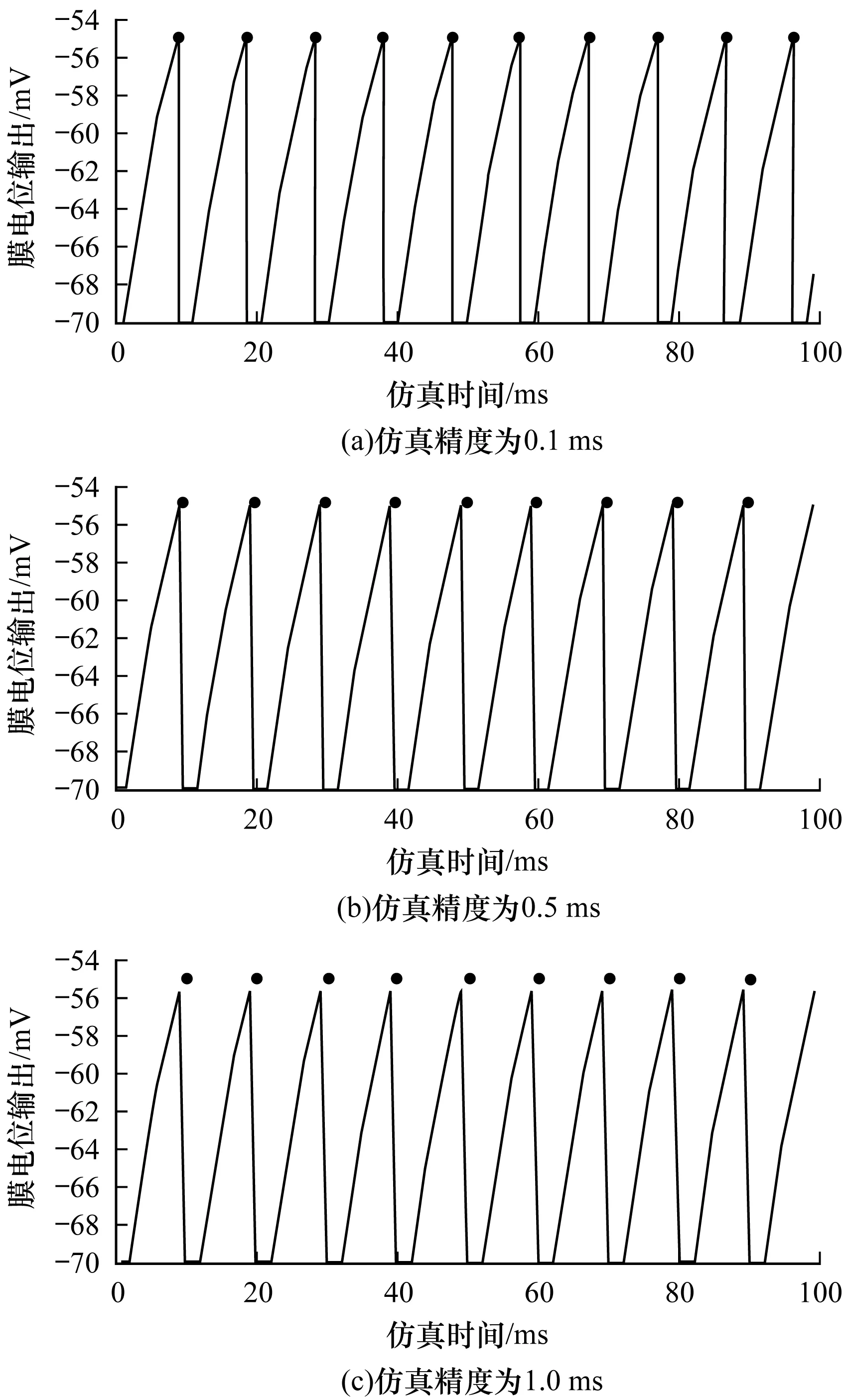
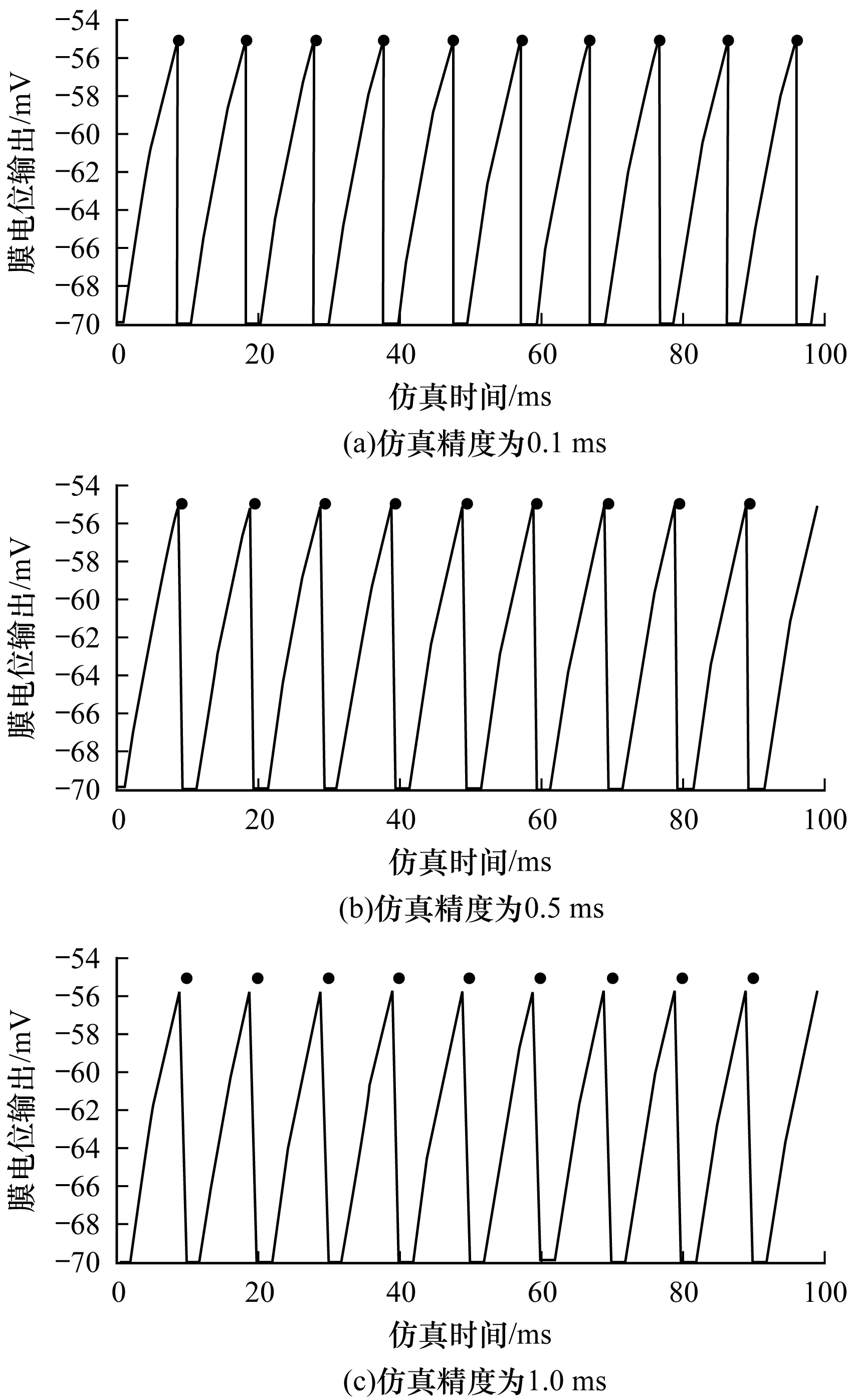
1.for (t=0; t 2.for (nneuron=0; nneuron 3.for (lag=from; lag 4.if (ref==0) 5.neuron_compute(); 6.else 7.--ref;} 下文对NEST仿真器中的脉冲发射率、内存需求和计算量进行分析,假设Nneuron为神经元数量、Nsynapse为突触数量、Tsimulation为整个模型的仿真时间。脉冲发射率为1 s内单个神经元发射的脉冲数,计算公式如式(3)所示: (3) 其中,Nspike为所有仿真时间内脉冲的发射数量。 NEST仿真器中脉冲神经网络内存的计算公式如式(4)所示: Smemory=Nneuron×Mneuron+Nsynapse×Msynapse (4) 其中,Mneuron和Msynapse分别为每个神经元和每个突触的内存占用,在NEST中每个LIF神经元至少占用128 Byte内存,每个静态突触共占用8 Byte内存。 NEST仿真器中脉冲神经网络浮点计算量的计算公式如式(5)所示: OPcompute=(OPneuron+OPsynapse)×Tsimulation×Nstep (5) 其中,OPneuron为神经元计算的浮点操作数,OPsynapse为突触计算的浮点操作数,Nstep为单位仿真时间内的仿真步长,OPweight为突触权重累加操作数。NEST仿真器中每个LIF神经元和静态突触计算分别需要14 FLOPS和1 FLOPS。 基于NEST仿真器的皮质层视觉仿真模型处理过程具体如下: 1)图像预处理。对任意分辨率的图像,将图像进行归一化,按原图长宽比缩放至80×80,因为按原图长宽比缩放,所以存在未填充像素部分,而该部分的填充值为0.5。 2)脉冲神经网络仿真。图像尺寸决定脉冲神经网络层规模,分别以预处理后的图像大小的1.00倍、0.70倍、0.50倍、0.35倍建立4个脉冲神经网络层,每个网络层又包含4个尺寸相同的层,分别以π/8、π/4+π/8、π/2+π/8、3π/4+π/8 Gabor滤波后的图像作为输入。脉冲神经网络层的突触连接包含自连接、一对一连接和全连接。NEST仿真器进行仿真后,将脉冲信息作为输出。 3)支持向量机(Support Vector Machine,SVM)分类。脉冲神经网络层的脉冲信息输出经过降采样后,将发射脉冲数映射到一维数组作为输入,并通过SVM分类器进行图像分类。 基于NEST仿真器的皮质层视觉仿真模型参数设置如表1所示。 表1 皮质层视觉仿真模型参数设置Table 1 Parameter setting of cortical visual simulation model 对皮质层视觉仿真模型进行分析得出以下结论: 1)脉冲神经网络的运行时间和计算量占比约为整个皮质层视觉仿真的90%以上。 2)脉冲神经网络的平均脉冲发射率较低。 3)脉冲神经网络中神经元计算量占整个模型计算量的比重较大,神经元计算量约为突触计算量的3万多倍。 本文将以NEST仿真器中神经元计算量占比较大的皮质层视觉仿真模型作为样例对其硬件架构设计进行评估。 本文设计基于FPGA集群的脉冲神经网络仿真器,首先在NEST仿真器的基础上进行重新设计以支持FPGA硬件平台,在保持原始仿真结果准确性的同时对神经元更新算法进行设计并增加FPGA硬件驱动和数据传输模块。然后对LIF神经元计算硬件模块进行设计,提出LIF神经元流水线并行架构,充分利用神经元内并行度和神经元间并行度,增大数据吞吐率和计算并行度,以神经元ID组成的脉冲队列作为输出,有效减少存储空间和数据传输时间。最后采用多线程和多进程的设计,充分利用处理器资源,提高系统并行性和扩展性,增加用户模式,提高系统使用便利度,为大规模类脑计算系统实现提供技术支持。 2.1.1 NEST仿真器神经元计算算法 为消除神经元之间的数据依赖性,有利于硬件的并行计算,设计的神经元计算算法具体如下: 算法2神经元计算算法 输入仿真时间和神经元数量 输出发射脉冲和神经元输出 1.for (t=0; t 2.for (lag=from; lag 3.for (nneuron=0; nneuron 4.if (ref==0) 5.neuron_compute(); 6.else 7.--ref;} 在LIF神经元计算模块中,最小延迟的遍历放置于外层循环,支持在最小延迟的最小步长内完成所有神经元的计算,在未改变原有脉冲神经网络更新机制的条件下,消除了每个神经元之间的数据依赖性。 2.1.2 NEST仿真器中LIF神经元的计算精度 NEST仿真器中LIF神经元变量采用双精度浮点数,为减少数据传输需求与系统内存需求,将LIF神经元中双精度浮点数改为单精度浮点数,更改后NEST仿真器的脉冲发射率及皮质层视觉仿真模型的仿真结果与原来保持一致。使用单精度浮点既保证了NEST仿真器的通用性,又降低了数据传输需求和系统内存需求。 2.1.3 NEST仿真器与硬件平台的数据交互模式 由于LIF神经元的数据无法全部存储到FPGA上,因此将LIF神经元的数据存放到共享内存中,NEST仿真器与硬件平台通过共享内存的方式进行数据交互。为减少频繁的内存读写,在共享内存中申请LIF神经元变量后,初始化时将NEST仿真器中数据传入到共享内存,LIF神经元硬件模块每次通过DMA控制器从共享内存中读取数据和输出数据到共享内存,最大化地减少神经元数据的搬运次数。NEST仿真器中的数据更新算法具体如下: 算法3数据更新算法 输入神经元初始化数据 输出神经元输出数据 1.Initial LIFNeuralDATA(); 2.CopyDatatoShareMemory(); 3.for (t=0; t 4.for (lag=from; lag 5.FPGA_MassUpdateNeuron();//FPGA设备及DMA驱动 6.CopyDatafromShareMemory();} LIF神经元计算模块采用流水线设计来提高吞吐率,如图2所示,由神经元输入缓冲经过一系列乘加运算得到当前的神经元膜电位,如果膜电位大于阈值则会输出结果到神经元输出缓冲,输出的脉冲携带神经元ID,将发出脉冲的神经元ID存储到共享内存,并按照输出顺序排列在一段连续的内存空间中,设置结束标志位为0,若读取到0,则说明本轮神经元更新所发射的脉冲读取完毕。单个神经元计算模块具有4个乘法和2个加法并行单元,充分利用了神经元计算模块的并行性。 图2 LIF神经元计算模块的硬件架构设计Fig.2 Hardware architecture design of LIF neuron computing module 神经元流水线结构如图3所示,包括数据读取R、神经元计算C、数据写回W3个模块。 图3 LIF神经元计算模块的延迟Fig.3 Delay of LIF neuron computing module 整个流水线时延计算公式如式(6)所示: Latencytotal=(TII×RoundDivUpper(Nneuron,Mneuron)+ TIL)/Freq (6) 其中,TII为初始化间隔时间,RoundDivUpper()为向上取整函数,Mneuron为能够支持神经元计算模块的最大并行数,TIL为迭代延迟,Freq为工作频率时钟,Trip Count为循环迭代总数。每个时钟周期读取和输出Mneuron个神经元参数,Mneuron取决于每个神经元的参数量和传输数据位宽,Nneuron由NEST仿真器给定的LIF神经元数量决定。 LIF神经元硬件架构的数据流和控制流设计如图4所示。NEST仿真器运行在ARM核,通过AXI-LITE控制LIF_NEURON神经元计算模块,并将神经元总数量通过寄存器输出到LIF_NEURON硬件模块。AXI-STREAM协议由4个DMA控制器实现,通过AXI-STREAM将神经元变量参数写入输入缓冲,利用DATA_SCATTER模块分发到LIF神经元中各个变量,LIF_NEURON神经元更新完成后,经过DATA_GATHER模块写回输出缓冲。本文采用8个LIF神经元并行计算,并通过分时复用的方式读取和更新共享内存中的数据。其中,AXI-STREAM最大数据位宽为1 024 bit,ZYNQ 7030的DDR3 1066f支持2.01 GB/s的数据带宽,LIF神经元计算模块最大带宽需求为1.175 GB/s,满足设计要求。 图4 LIF神经元硬件架构的数据传输设计Fig.4 Data transmission design of LIF neuron hardware architecture 2.3.1 NEST仿真器多线程与多进程设计 为便于大规模脉冲神经网络仿真,NEST仿真器本身支持OpenMP的共享内存多线程技术与支持MPI的分布式内存多进程技术,可适应不同集群平台。 NEST仿真器在脉冲神经网络仿真前建立网络连接。按照平均分配的原则将神经元分配至各进程中的线程,并赋予每个神经元全局ID、线程ID及进程ID,随后根据NEST仿真器中的查找表(Look Up Table,LUT)建立突触,通过突触建立各个进程和线程之间的连接关系,进程中使用MPI消息机制进行神经元之间的脉冲消息传递,每个突触连接包含权重、延迟和目标神经元全局ID。目标神经元用来查找目标节点,延迟用来定义从源神经元(Source neuron)到目标神经元(Target neuron)需要的仿真步长。 NEST仿真器会给每个线程分配接收缓冲(Receiver buffer)和发送缓冲(Send buffer),接收缓冲负责接收所有传入的脉冲信息,发送缓冲负责存放发射脉冲的信息,每个线程都具有相同大小的接收缓冲,每个缓冲中具有相同的数据内容,NEST仿真器通过线程ID从接收缓冲获取相应的脉冲事件数据,然后通过突触连接找到对应的神经元进行脉冲传递。MPI信息交换机制是将进程中的发送缓冲拷贝并发送到其他所有接收进程,NEST仿真器中脉冲发射与接收流程如图5所示,其中,t为当前仿真时间,Tstep为预设的总仿真时间,为仿真步长。 图5 脉冲发射与接收流程Fig.5 Procedure of spiking transmitting and receiving 由于ZYNQ 7030的PS端为ARM A9双核处理器,且支持双线程运行,因此本文设计了2个LIF神经元硬件模块,由ARM端的线程控制LIF神经元硬件模块,如图6所示。多线程采用共享内存方式,使用2个LIF神经元硬件模块同时读写DDR3内存,可充分发挥DDR的带宽优势,但由于线程之间存在上下文切换,因此多线程的加速比不能达到理论最大值。 图6 多线程硬件设计Fig.6 Multi-thread hardware design 如图7所示,T1和T2分别代表线程1和线程2,多进程采用分布式内存方式,每个进程包含发送缓冲和接收缓冲,在脉冲神经网络仿真开始前将网络拓扑结构映射到NEST仿真器,为每个线程和进程分配神经元,发出的脉冲信号通过以太网从发送缓冲发送到接收缓冲。 图7 多进程硬件设计Fig.7 Multi-process hardware design 每个进程节点配备单独的DDR3内存,可增加整个系统的内存容量并提供更高的计算性能,但同时需要考虑多节点的通信问题。本文中NEST仿真器的皮质层视觉仿真模型具有脉冲发射率低和神经元更新计算需求大的特性,其通信数据计算公式如式(7)所示: Mcommunication=(Nspike/Nmpi+Nthread×dmin)× (Mgid+Moffset)×Nmpi (7) 其中,Nthread为预设的SNN仿真器线程数,Nmpi为预设的NEST仿真器进程数,dmin为最小延迟,Mgid为发出脉冲的全局ID变量,Moffset为脉冲偏移变量,由于全局ID和脉冲偏移均为双精度浮点变量,因此Mgid和Moffset总数据量为16 Byte。 2.3.2 用户编程模式 NEST仿真器加入动态加载比特流来配置FPGA模块,用户可根据需求选择是否使用FPGA硬件加速模块。FPGA集群的每个进程都可通过NEST仿真器动态加载比特流,并且可根据神经元类型加载不同的神经元硬件模块,提高用户使用FPGA集群的便利性。 如图8所示,运行NEST仿真器,在初始化阶段判断是否需要FPGA硬件加速模块,如果不需要则直接在双核ARM A9上运行,如果需要则根据神经元类型自动下载相应的FPGA比特流,并通过NEST仿真器控制多线程和多进程调度以及FPGA与DRAM的数据交互,单个线程内实现8个LIF神经元并行计算的硬件设计,同时采用流水线架构,当前轮次仿真输入复用上一轮仿真的输出。利用OpenMP多线程编程、MPI消息传输机制和以太网通信实现计算节点与计算节点之间的脉冲传递。 图8 基于FPGA集群的脉冲神经网络仿真器整体架构Fig.8 Overall architecture of spiking neural network simulator based on FPGA cluster NEST仿真器:NEST 2.14.0版本,GCC 5.0编译器,Python 3.5。 皮质层视觉仿真模型:最小延迟dmin为1 ms,仿真精度为0.1 ms,总生物仿真时间为50 ms,神经元数量为48 904,突触数量为355 516。 FPGA设计软件:Xilinx FPGA设计集成工具(Xilinx Vivado 2018),高层次综合工具(Xilinx Vivado HLS 2018)。 CPU:Intel Xeon E5-2620,8个核心,内存为128 GB DDR3。 ARM:ARM A9处理器主频为667 MHz,2个核心,内存为1 GB DDR3。 FPGA集群系统:FPGA集群包含8个Xilinx ZYNQ 7 030节点,每个节点包括PS端的ARM A9双核处理器系统和可编程逻辑端(PL)的FPGA器件,FPGA时钟频率为100 MHz,FPGA板卡之间基于TCP/IP协议并采用1 000 Mb/s网络带宽的以太网进行通信。 针对单个LIF神经元硬件模块进行仿真,设置仿真精度为0.1 ms、0.5 ms、1.0 ms,输入恒定电流为700 pA,仿真时间为100 ms,分别对原始NEST仿真器与基于FPGA的NEST仿真器进行结果测试,原始NEST仿真器LIF神经元实现结果如图9所示,基于FPGA集群的NEST仿真器LIF神经元实现结果如图10所示。 图9 原始NEST仿真器LIF神经元实现结果Fig.9 LIF neuron implementation results of the original NEST simulator 在图9和图10中,直线表示膜电位输出值,黑点表示NEST仿真器在某个仿真时间内存在脉冲发射,对比原始NEST仿真器和基于FPGA集群的NEST仿真器单个LIF神经元以恒定电流输入的脉冲仿真结果,可以看出:在单个神经元仿真中,本文实现的LIF神经元硬件模块与原始NEST仿真器的仿真结果保持一致,不存在精度损失,达到了理想结果。 图10 基于FPGA集群的NEST仿真器LIF神经元实现结果Fig.10 LIF neuron implementation results of cluster NEST simulator based on FPGA 针对皮质层视觉仿真模型的脉冲层进行仿真,分别得到原始NEST仿真器和基于FPGA集群的NEST仿真器的皮质层视觉仿真模型的脉冲层结果,仿真时间为50 ms,选取80×80大小的网络层输出结果,如图11和图12所示,其中黑点表示NEST仿真器中某个神经元在某个仿真时间内产生了脉冲,对原始NEST仿真器脉冲仿真结果与基于FPGA集群的NEST仿真器脉冲仿真结果进行对比,其脉冲输出结果保持一致。通过对比多次实验结果和不同层的脉冲输出结果证明本文基于FPGA集群的NEST仿真器在脉冲神经网络仿真时可保证仿真结果的准确性,并得到正确的输出结果。 图11 原始NEST仿真器脉冲结果Fig.11 Spiking results of the original NEST simulator 图12 基于FPGA集群的NEST仿真器脉冲结果Fig.12 Spiking results of NEST simulator based on FPGA cluster 本文NEST仿真器中神经元计算模块采用单精度浮点数据,与原NEST仿真器的神经元计算模块双精度浮点数据相比,在皮质层视觉模型仿真图像分类的准确率和脉冲发射率方面并无差异,结果如表2所示。 表2 皮质层视觉仿真模型性能分析Table 2 Performance analysis of cortical visual simulation model 在基于NEST仿真器的皮质层视觉仿真模型中,预设dmin=1,平均脉冲发射率为3.84 spike/s/neuron,总的仿真时间为50 ms,神经元数量为48 904,总的脉冲发射数为9 389,本文设计采用8个FPGA节点,单个节点最大支持2个线程,根据式(7)计算得出总的MPI通信量为0.143 MB。本文应用1 000 Mb/s以太网,即每秒钟传输125 MB数据,由于MPI传输时间的理论值约为1.1 ms,但MPI存在频繁启动问题,因此随着节点的增加,MPI所占时间也不断增加,如表3所示。 表3 不同规模FPGA集群的MPI性能测试Table 3 MPI performance test of FPGA clusters of different scales FPGA资源包括LUT、LUTRAM、触发器(Flip-Flop,FF)、BRAM(Block RAM)和DSP。单个FPGA节点中2个LIF神经元硬件模块的资源利用率情况如表4所示。 表4 单个FPGA的资源利用率Table 4 Resource utilization of a single FPGA 本文设计并实现基于FPGA集群的NEST脉冲神经网络仿真器,以皮质层视觉仿真模型为例,分别对比Xeon E5-2620(8 core)和ARM A9(2 core),其性能评估结果如表5所示。 表5 在CPU、ARM和ARM+FPGA平台上的性能评估Table 5 Performance evaluation of CPU,ARM and ARM+FPGA platforms 本文实现了基于FPGA集群的NEST仿真器,在计算能效方面,其单个节点能效是ARM A9的30倍,是Xeon E5-2620的56.10倍;FPGA集群的能效是Xeon E5-2620的43.93倍,是ARM A9的23.54倍。在计算速度方面,单个节点速度是ARM A9的33.21倍,是Xeon E5-2620的1.97倍;FPGA集群的速度是ARM A9的208倍,是Xeon E5-2620的12.36倍。 根据本文得到的FPGA集群性能及加速比,基于FPGA集群的NEST仿真器在皮质层视觉仿真模型中,随着FPGA节点数目的改变,节点间的性能预测结果如表6所示。 表6 不同规模FPGA集群的性能预测Table 6 Performance prediction of FPGA clusters of different scales 由表6可知,在16个FPGA节点内,总时延随着节点数的增加而减少,当节点数超过16个时,MPI通信将成为整个FPGA集群的瓶颈,随着节点数的增加,整个系统时延也不断上升,能效比不断降低。因此,为实现更大规模的脉冲神经网络,下一步的工作重点为MPI网络通信的优化与改进。 本文提出一种基于FPGA集群的NEST脉冲神经网络仿真器,采用流水线设计提高吞吐率,使用多线程和多进程设计充分利用处理器资源,提高系统并行性、扩展性以及使用便利性。实验结果表明,NEST仿真器在计算速度和能效方面均有较大幅度的提升,其为神经科学家提供了速度更快、能耗更低的脉冲神经网络仿真平台。为进一步提高基于FPGA集群的NEST仿真器的通用性,后续将针对Izhikevich、HH等类型的神经元计算模块进行设计,通过优化网络传输性能,实现支持更大网络规模的脉冲神经网络仿真器与类脑计算平台。1.3 基于NEST仿真器的皮质层视觉仿真模型

2 基于FPGA的NEST仿真器硬件架构设计
2.1 支持FPGA硬件架构的NEST仿真器设计
2.2 LIF神经元计算模块的硬件架构设计

2.3 支持FPGA集群的NEST仿真器多节点设计

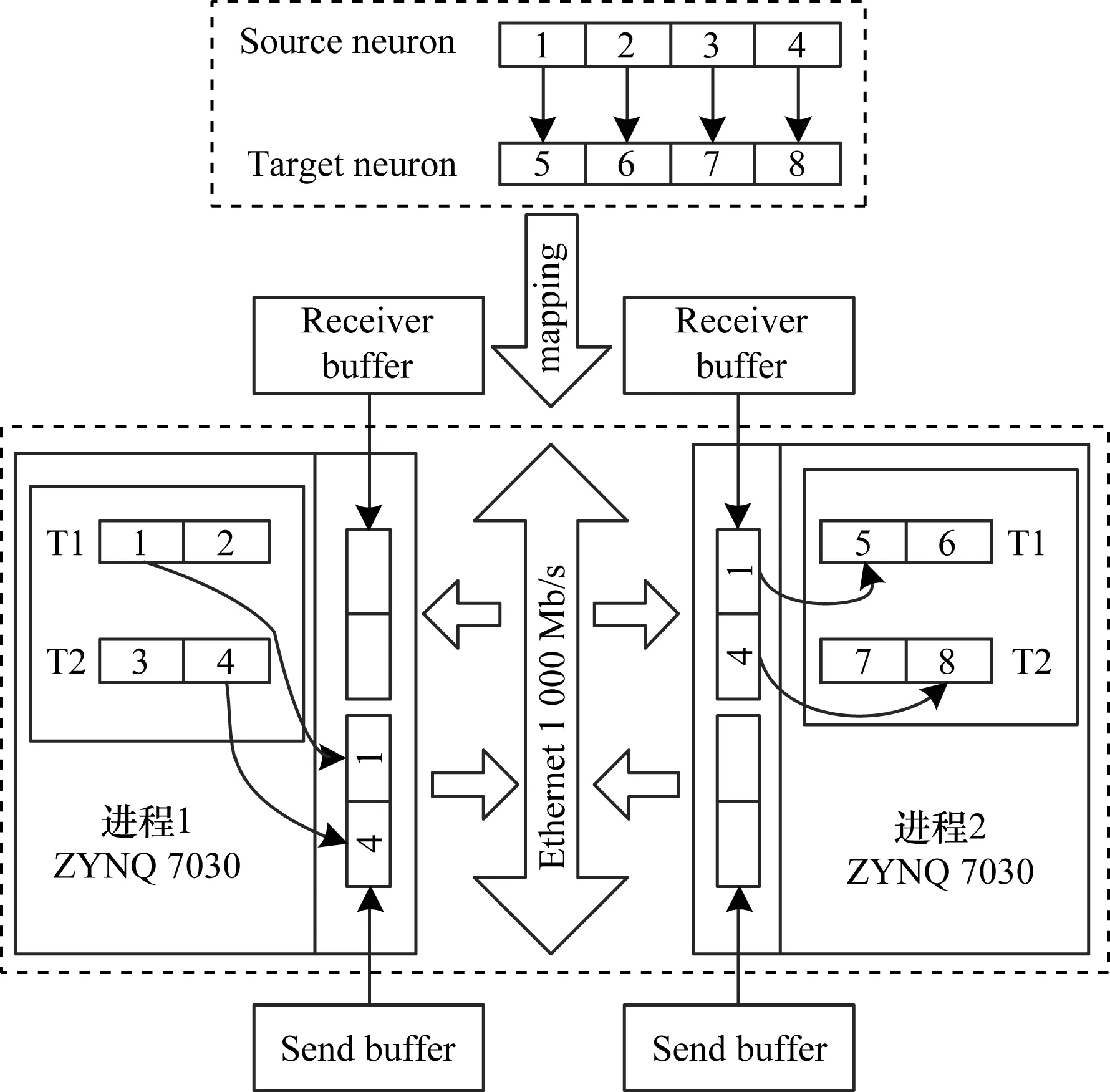
2.4 基于FPGA集群的NEST仿真器总体架构设计
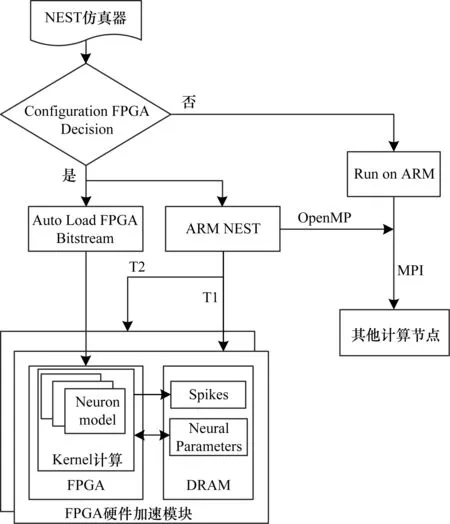
3 实验结果与分析
3.1 软硬件环境设置
3.2 LIF神经元硬件模块实验结果分析
3.3 皮质层视觉仿真模型的脉冲层实验结果分析

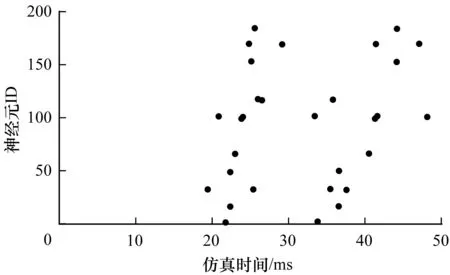
3.4 皮质层视觉仿真模型性能分析

3.5 FPGA集群节点间的数据传输分析

3.6 FPGA资源利用率分析

3.7 基于FPGA集群的NEST仿真器性能评估

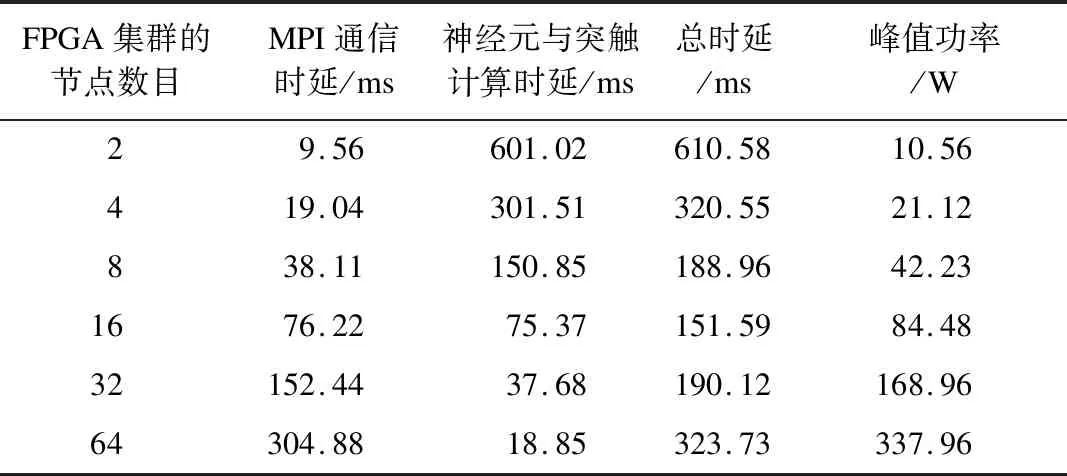
3.8 不同规模FPGA集群的性能预测
4 结束语
猜你喜欢
世界科学技术-中医药现代化(2021年10期)2021-03-02小资CHIC!ELEGANCE(2021年46期)2021-01-11睿士(2020年11期)2020-11-16中国计算机报(2020年9期)2020-03-25军事运筹与系统工程(2019年4期)2019-09-11电子制作(2018年11期)2018-08-04铁路计算机应用(2018年4期)2018-05-03中国交通信息化(2017年3期)2017-06-08知识就是力量(2017年2期)2017-01-21通信电源技术(2016年5期)2016-03-22
