
基于轮廓编码融合BP网络的图像目标识别方法研究
2020-10-13 09:47孟思明
数码设计 2020年6期
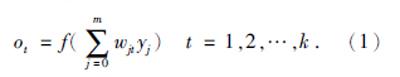


摘要:目标图像轮廓编码算法是一种图像轮廓特征提取的二次转换算法模型,具有较好的稳定性和有效性。本文采用该轮廓编码算法结合BP网络,提出一种图像目标识别方法。算法能大大减少样本图像所需数量,仅需要一个样本图像即可准确快速地识别出与其一致的目标图像,识别率高达100%,在计算速度、抗干扰能力与数据存储上都优于传统的识别方法。
关键词:轮廓编码;目标识别;图像识别;编码链
中图分类号:TP391.41;O157.5 文献标识码:A 文章编号:1672-9129(2020)06-0069-03
Abstract:Targetimagecontourcodingalgorithmisasecondarytransformationalgorithmmodelforimagecontourfeatureextraction,whichhasgoodstabilityandeffectiveness.Inthispaper,thecontourcodingalgorithmcombinedwithBPnetworkisusedtoproposeanimagetargetrecognitionmethod.Thealgorithmcangreatlyreducethenumberofsampleimages,andonlyonesampleimageisneededtoaccuratelyandquicklyidentifythetargetimageconsistentwithit.Therecognitionrateisupto100%,whichissuperiortothetraditionalrecognitionmethodsincomputingspeed,anti-interferenceabilityanddatastorage.
Keywords:contourcoding;Targetrecognition;Imagerecognition;Chaincode
相對于经典的图像识别算法而言,基于轮廓的识别方法可大大减少计算时间,相比于图像区域的识别而言,基于图像轮廓边界的识别方法具有显著的优势,其更容易融合进其它的数值分析技术,如傅立叶变换、小波分析、多尺度分形、神经网络等,还可以定量的将边界轮廓信息进行再处理,得到目标图像的二次特征信息。本文首先对目标图像轮廓编码算法和BP网络进行简要分析,再采用目标图像轮廓编码算法结合BP网络方式,提出一种图像目标识别方法,并通过实验以能突出轮廓编码算法优势的机械工件识别为例分析该目标识别方法的优点和抗干扰性能。
1目标图像轮廓编码算法
目标图像轮廓编码算法①,是基于水平集模型提取图像的特征轮廓进行编码,有效地提取了图像边界的本质信息,且通过将图像旋转的方式,将分割所得图像的边界轮廓进行特定的编码。该算法主要是将获取得到的目标图像边界坐标信息,进行一定的图像转换进而提取出目标图像的轮廓信息矩阵,不但在编码作用上、编码速度及编码思想上与传统的编码算法不一样,而且在图像轮廓特征提取的二次转换上具有独特的作用,能够从多角度提取挖掘出图像边界轮廓的信息。该目标图像轮廓编码算法流程步骤分别如下:
步骤1,基于图像分析模型获取得到目标图像的边界信息,分别为(x,y)系列坐标。
步骤2,将步骤1得到的轮廓边界的坐标值分别归一化在[1,255]之间,剔除图像因绝对相像素点不同造成的影响。
步骤3,将步骤2得到的轮廓矩阵数据转换成uint8格式,便于后续计算处理。
步骤4,将步骤3得到的轮廓矩阵进行灰度化,并将其转换成图像边界的编码矩阵。
步骤5,将步骤4得到的图像边界编码矩阵通过设定相应的阈值进行二值化。
步骤6,为了将图像边界编码矩阵与其它模型算法结合,将步骤5得到的二值化编码矩阵进行排列编码,其排列编码方式可以为横向、列向及斜向。最后绘制出相应的编码链。其中,横向编码是将二值化后的编码矩阵的每一行全部按先后顺序转化为一行。列向编码是将编码矩阵的每一列全部按照先后顺序转化为一行。斜向编码是将编码矩阵的每一对角线数据由右上角至左下角依次全部转化为一行。
2BP神经网络
D.E.Rumelhart和J.L.McCelland为主的研究小组在1986年第一次提出BP(BackPropagation)神经网络,是目前人脸表情识别技术中使用最广泛的人工神经元网络。BP算法将学习过程划分为正向传输信号和逆向传输误差两个过程。信号传输环节中,输入层每个节点获取信号的输入,信息通过中间层处理后就传输到输出层每个节点来处理,全部完成后通过输出层得到处理后的结果。如果结果不满足预期的输出时,就会进到误差传输环节。这个环节中误差按照某种形式从传输层出发传输到隐层以及输入层,传输过程中对每层的所有单元的权限进行修改,保证误差可以梯度式的降低。这样的正向传输信号和逆向传输误差的环节会不断往复,一直到网络得到的误差控制在预期的范围中。信号和误差传递的环节中,每一层权值不断的调节过程就是神经网络学习训练过程。标准BP网络的结构包含输入层、隐层以及输出层。输入向量为X=(x1,x2,…,xn)T,隐含层的输出向量为Y=(y1,y2,…,yn)T。输出层的输出向量为O=(o1,o2,…,ok)T,期望输出向量为:d=(d1,d2,…,dk)T。vij表示输入层第i个节点与隐层第j个节点的权值,wij表示隐层第i个节点与输出层第j个节点的权值[1]。
对于输出层:
对于隐含层:
当网络输出与期望输出不相符时,存在的输出误差用E表示:
如果输出误差E不符合既定的ε或迭代次数低于预定的值时,按照一定的规则来调整各层权值vij和wij从而降低误差E,一直到E低于ε或者和达到指定的迭代次数。将此时的权值和阈值固定下来,完成网络的学习环节。BP算法的流程描绘如下:
步骤1,初始化每个神经元的权值和阈值,输入训练样本和对应的预期输出。
步骤2,得到隐层和输出层中每个神经元的输入与输出。
步骤3,计算得到网络的输出误差和每层的误差信号。
步骤4,修正各层神经元权值及阈值。
步骤5,计算网络误差,若误差达到精度要求,训练结束,否则返回步骤2。
通過图像预处理、特征提取等等准备工作后,设计一个分类器,对输入的特征进行分类,实现对图像目标的识别。BP神经网络应用在机械工件识别中,通常使用标准的三层架构,利用Purelin线性函数作为隐层到输出层的激活函数,输入层到隐层的激活函数采用Sigmoid函数。隐层节点的数量按照经验公式(4)来设定。
式中,m为输出节点的个数,n为输入节点的个数,a为1~10之间的常数。
3基于轮廓编码融合BP网络的图像目标识别实验分析
本节所有的实验,均在IntelI7-4712HQ2.30GHzCPU,NVIDIA610M显卡,8GB内存和MATLABR2011b实验环境下完成。
3.1识别模型的建立及分析。由于目标图像轮廓编码流程对于图像旋转所得的编码匹配较差,或者说对于图像旋转后的识别能力较弱。因此为了克服该编码链所存在的缺点,针对性的需要对图像进行旋转校正后,才能进行其图像边界轮廓的编码。故轮廓编码链与模式识别模型之间的桥梁就是图像的校正。由于BP神经网络所具有的特点,同时为了后续模型的比较,这里选取的模式识别模型系统以BP神经网络为核心。故本文所设计的目标图像轮廓编码与神经网络模型融合的图像识别实验,选择的识别对象是各种比较相似的不同机械工件,其流程步骤如下(见图1):
步骤1,模板图像的旋转。本文主要利用霍夫变换检测图像的轮廓直线部分。通过旋转图像,将模板图像与待识别图像统一方向。该步骤主要为了后续图像分割所得的轮廓边界编码链进行预处理。
步骤2,模板图像的分割与图像轮廓的提取。本文基于LCV模型进行分割图像,并提取出图像的边界轮廓,为后续边界轮廓编码使用。
步骤3,模板图像轮廓的编码。将步骤2得到的轮廓边界采用本文提出的特征编码处理方式进行整理。
步骤4,待识别的图像旋转。该步骤与模板图像旋转步骤一致。
步骤5,待识别图像的分割与图像轮廓的提取。该步骤与模板图像的分割与图像轮廓的提取一致。
步骤6,待识别图像轮廓的编码。该步骤与模板图像轮廓的编码步骤一致。
步骤7,将步骤6获得的各类型图像编码特征作为BP神经网络的输入信息,从而训练BP网络,得到智能化识别的神经网络模型。最后将训练好的BP神经网络模型对其它测试图像进行识别。
本文以各种比较相似的不同工件为例进行算法的识别分析。其各种工件图像如下图1所示。其通过霍夫变换获取的两水平方向的校正模板图像及编码链结果分别如下图2与图3所示:
由于以上图像类别数较少,故采用横向编码的方式进行编码。且编码参数设定为统一图像像素为20*50大小,阈值系数为0.9。其中通过以上的各图像编码链已经可以看出各类图像的编码链存在较大的差异。将以上8条编码链作为BP神经网络的输入信息。并以A,B,C,D类作为网络最终识别的输出信息,其中网络设定的训练参数:第一层节点数1000个,第二层节点数50个,网络目标误差1.0*e-8,网络训练函数trainrp;网络收敛结果参数:网络训练数21次,网络训练时间9秒,网路收敛误差1.26*10-8,网络拟合优度为1。
将以上训练好的智能系统用于图像识别,其中针对103个工件样本的识别情况为:正确识别参数为103,错误识别0个,识别率达到了100%。
其中将本文的识别算法在MPEG与PLANE数据库的图像识别结果,并与文献[2]给出的其它几个比较主流的识别模型算法进行比较。其结果如下表1所示:
表1几种识别方法在MPEG与PLANE数据库的识别率
FD+SVMZM+SVMHMME+MLHMMC+MLHMME+WtL本文方法
MPEG数据库94.29%92.14%80.00%92.14%97.62%98.47%
PLANE数据库99.52%89.05%78.52%99.05%99.05%99.52%
3.2识别模型的抗干扰分析。为了说明图像边界轮廓的编码与神经网络算法相融合的图像识别能力。针对性地对其进行部分干扰识别的分析。其中重点讨论待识别的图像存在严重的噪声干扰的识别效果。
当图像存在噪声时,往往全局像素的编码链方式基本全部失效。因为图像的噪声已经是图像像素的一部分。故识别出图像的可能性基本没有。
然而对于轮廓边界的编码链方式进行图像的识别过程。其关键的一步是能提取出图像的关键边界轮廓。也就是说,当噪声存在时,只要能得到图像的轮廓边界,则问题便可以解决。然而对于图像的轮廓边界的获取,水平集模型中的LCV模型能够有较好的抗噪声能力。因此,对于含有噪声的图像识别,依然可以完美的进行。以下通过含有高斯噪声的图像识别实验,其结果如下图4所示:
图4人工添加噪声后的图像识别。(a)待识别原图像。(b)图像校正及LCV模型分割边界结果。(c)所获取图像的边界轮廓。(d)轮廓边界编码的链结果。
将以上含有人工噪声图像所得到的轮廓边界编码链作为神经网络的输入。其检验结果如下图5所示:
由图5含高斯噪声的图像识别测试实验我们可以看出,只要提取出工件图像的轮廓边界,并以横向编码方式得到其编码链作为神经网络的输入信息,网络对于图像的识别结果均正确。故本文的图像轮廓编码链融合神经网络的图像识别对与含有噪声的图像依然能够进行识别。
4总结
通过以上针对性的分析,我们可以得出,本文的图像轮廓编码融合神经网络模型的图像识别效果存在以下三个优点:
第一,由于将图像经过校正后获取其边界轮廓并进行了编码,故算法整体所需的样本数量仅仅只需要一个,完全改善了传统的图像识别算法所需的样本数量大的缺点。
第二,对于图像全局像素神经网络模型的图像识别方法,本文将图像轮廓编码与神经网络算法相融合完美地改善了模型的鲁棒性及计算速度。
第三,对于传统的图像匹配算法,往往当图像含有较为严重的噪声时,图像识别能力大大下降。而本文的识别算法关键的一步是能提取出图像的轮廓,也就是说,即使噪声存在时,只要能得到图像的轮廓边界,则问题便可以解决。而水平集模型中的LCV模型能够有较好的抗噪声能力。故针对含有噪声的图像识别,依然可以完美的进行。
采用本文的目标识别方法,僅仅只需要一个该类型模板图像,便可识别出与之一样的图像类型。图像模板数量大大减小,不但提高了识别过程的速度,更加使得识别过程得以高效率高精确度地进行。同时通过针对不同图像的边界轮廓的特定编码,可以使得不同图像在任意的方向与角度,或者多单元组合的图像中依然得以识别。即识别过程的抗干扰能力较强。
注释:
①孟思明,一种创新的目标图像轮廓编码算法研究,广州,2016
参考文献:
[1]XiaojuanWang,YanpingBai,BPNetworkBasedonHandwrittenDigitalImageFeatureExtraction,AdvancesinAppliedMathematics,03(2),104~111,2014
[2]NinadThakoor,JeanGao,SungyongJung,HiddenMarkovModel-BasedWeightedLikelihoodDiscriminantfor2-DShapeClassification,IEEETransactionsonIamgeProcessing,16(11),2707~19,2007
猜你喜欢
国际商业技术(2022年4期)2022-04-21
科技视界(2019年31期)2019-12-02
数码世界(2019年6期)2019-09-09
中国信息技术教育(2019年2期)2019-01-28
计算机应用(2016年10期)2017-05-12
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
中国信息技术教育(2016年21期)2016-12-05
