
基于售后服务记录的卡车动力转向系统漏油分析与预测
2020-09-24 03:18蒋国璋张翼翔李公法
武汉科技大学学报 2020年5期
蒋国璋,张翼翔,向 峰,李公法
(1.武汉科技大学冶金装备及其控制教育部重点实验室,湖北 武汉,430081;2.武汉科技大学机械传动与制造工程湖北省重点实验室,湖北 武汉,430081;3.武汉科技大学精密制造研究院,湖北 武汉,430081)
卡车的动力转向系统(以下简称“动转系统”)普遍采用液压助力转向(HPS),车辆在行驶时将发动机的一部分能量供给动转系统,帮助驾驶员控制卡车转向,其本质属于一种液压传动系统。相较于固定工作环境下的液压系统,卡车动转系统所面临的工作条件更为复杂多变,并且由于工作性质原因,很难对其工作状态进行有效监测,因此在系统发生漏油初期往往不易察觉,得不到及时维修,导致漏油程度严重恶化。
目前卡车制造企业对于漏油问题的解决方案是由售后服务人员对故障车辆进行维修,并根据现场情况在售后服务记录中通过自然语言对漏油情况进行描述,再通过车辆的编号追溯生产制造信息。维修人员通常只从动转系统自身角度对漏油原因进行分析,无法从历史案例中找出与漏油相关的规律,也无法从生产、装配等环节去分析漏油原因。而企业的售后服务记录是对车辆漏油情况的详细文本描述,包含大量案例,从中分析出漏油产生的原因将有利于企业对生产技术进行改进,同时根据历史案例数据建立预测模型,可以对卡车漏油情况进行预测,以避免更严重的漏油事故发生。
对蕴含在售后服务记录中的大量信息进行数据挖掘的一个有力工具是情感分析(sentiment analysis)。情感分析又称为评论挖掘,它通过自然语言处理(natural language processing, NLP)等技术获取文字记录者对所记录事件的评价和态度[1],目前主要包括基于情感词典的方法、基于机器学习的方法以及基于深度学习的方法。基于情感词典的方法以情感词典中收录词语的情感极性和强度信息作为情感倾向的主要判断依据[2-4],但是构建领域情感词典的工作较为复杂,且词典的准确性也会影响到分析结果。基于机器学习的方法需要人工构造特征,再通过支持向量机(SVM)等机器学习算法进行分类[5],所构造特征的质量直接影响到分类准确性,且构造特征需要领域知识,要耗费大量人力和时间。
随着深度学习技术的发展,越来越多的研究者将其应用到情感分析上。Kim[6]对卷积神经网络(convolutional neural network, CNN)模型进行了调整,将其应用于文本分类任务。Wang等[7]在CNN模型的输入层和池化层加入注意力机制,使模型对文本中的重要词语更加关注。蔡鑫等[8]使用长短期记忆(long short-term memory, LSTM)神经网络模型实现对中国电信官方微博访问用户的情绪分析,克服了传统文本处理方法中容易丢失上下文顺序和词的语义差异的缺陷。邓楠等[9]提出了一种改进的双向长短期记忆神经网络(BiLSTM)模型,在隐藏层加入情感特征抽取模块,改善了文本情感分析效果。基于深度学习的情感分析方法可以弥补基于情感词典和基于机器学习的情感分析方法的不足,但上述模型只能分析一段文字整体所表达的粗粒度的二元情感倾向。为了获取更加精确的情感分析结果,需要对文本所包含的信息进行细粒度分析。细粒度情感分析主要从两方面着手,一是文本区分粒度细化,即针对文本信息的不同方面进行情感分析,从而基于同一段文字获得不同角度的情感倾向[10-12],二是情感强度细化,即将情感划分为更多的层次,从而获得更加准确的情感分析结果[13-14]。以上研究可以为基于描述文本的卡车动转系统漏油程度量化提供参考。
在获得漏油程度量化结果后,结合售后服务记录中的相关生产数据,可对动转系统的漏油问题进行分析预测。目前机械系统故障预测方面的研究成果较多,例如,Zhao等[15]采用小波包分析方法提取液压系统中液压缸的故障特征,实现了对其早期泄露的预测;Prakash等[16]基于深度神经网络模型对液压系统中冷却回路的工作状况进行了预测;Chen等[17]提出了一种无需先验知识的滚动轴承剩余使用寿命的预测方法;徐增丙等[18]设计了改进直接灰色模型,用以预测混凝土泵车摆缸的泄露趋势;韩朝建等[19]采用支持向量机实现对铁路车辆车钩装置运动可靠性的预测;黄魁等[20]提出了一种结合灰色理论和神经网络的预测模型,在雷达发射机的故障预测中获得较好精度。但是以上方法只是基于已有数据特征进行预测,没有深入考虑特征与故障之间的相关性。
本文基于某企业的卡车动转系统漏油问题的售后服务记录,首先采用结合注意力机制的双向长短期记忆神经网络模型(BiLSTM with attention mechanism,Att-BiLSTM)根据漏油描述文本进行漏油程度量化,然后将随机森林(random forest, RF)算法[21]与BP神经网络模型相结合,建立动转系统漏油分析预测模型,并对可能造成漏油的样本特征与漏油程度进行相关性分析,依据其结果,一方面可以指导企业进行工艺改进,另一方面在进行回归预测时可减少无关数据的影响,从而提高模型性能。
1 基于描述文本的动转系统漏油程度量化
1.1 漏油程度量化训练标签
本文采用模糊层次分析法建立漏油程度量化训练标签。首先依据售后服务记录建立卡车动转系统漏油程度评价指标体系,如图1所示。
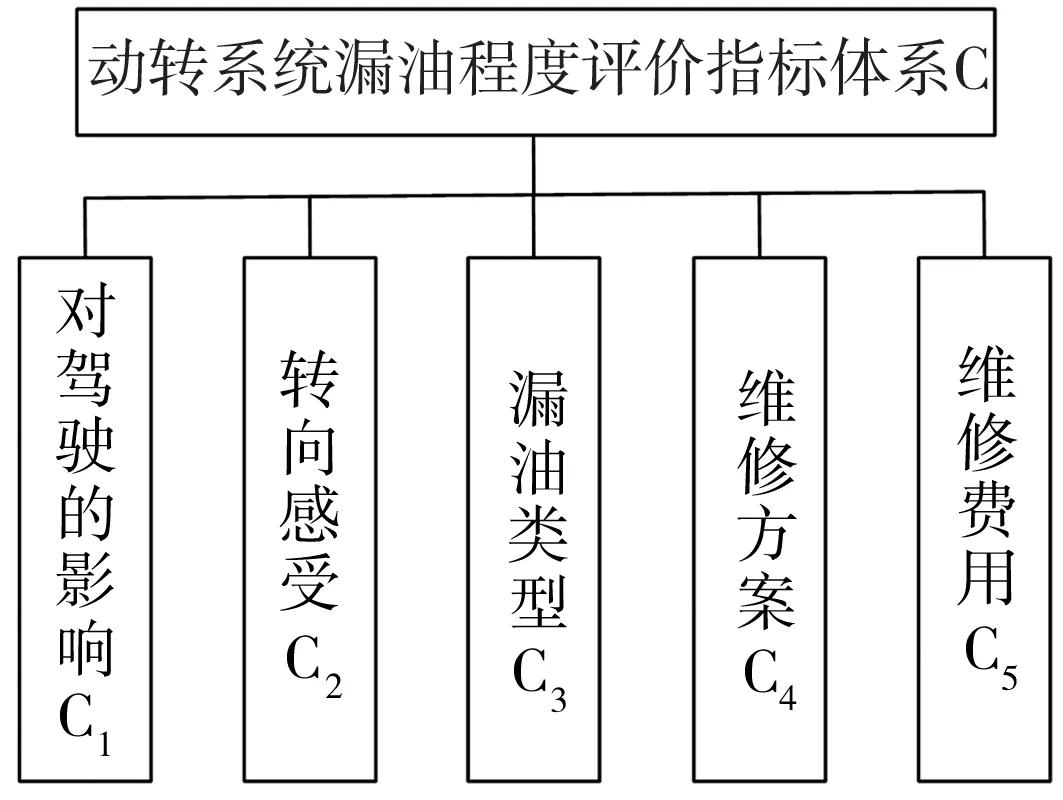
图1 漏油程度评价指标体系Fig.1 Evaluation index system for oil leakage
咨询相关专家并采用1~9标度衡量评价体系中属性Ci的重要程度,记作IMi。以f(Ci,Cj)表示两个属性间重要程度的对比:
(1)
创建评价指标权重判断矩阵R以获得每个属性的权重:
求得矩阵R的最大特征值λmax,并通过式(2)验证一致性指标CR:
(2)
式中:n为矩阵R的维度;RI为对应维度的平均随机一致性指标。
若CR<0.1,则认为λmax所对应的特征向量Wmax经过归一化后的向量W=(w1,w2,…,wi)T即为评价体系中每个属性对应的权重。运用模糊数学理论,将漏油程度分为5级,即{严重,较严重,一般,较轻微,轻微},其对应的赋值区间为{(1.0,0.8],(0.8,0.6],(0.6,0.4],(0.4,0.2],(0.2,0)}。请相关专家依据售后服务记录,同时参考5级漏油程度评价方法,确定当前车辆每个属性Ci所对应的严重程度,记作向量VC=(v1,v2,…,vi)。根据公式(3)以及5级漏油程度赋值区间即可获得当前车辆的漏油程度:
(3)
式中:E为卡车漏油程度对应的赋值;vi为专家对漏油评价指标体系中第i个属性的严重程度评分;wi为第i个属性的权重。
1.2 漏油描述文本向量化
漏油描述文本是以中文记录的,进行漏油程度量化时,需要将文本处理成神经网络能够运算的数值张量,将每个词以向量的形式输入到神经网络模型。首先要采用分词、去停用词等步骤对漏油描述文本进行预处理,同时因为漏油描述文本中的诸如“故障现象”、“诊断结论”等词语对于漏油程度的量化没有意义,在预处理阶段也将其去除。
文本经过预处理后,再通过Word2Vec训练成词向量。Word2Vec是一种以无监督的方式学习语义知识并将自然语言转换成向量数据的软件工具,图2所示为将一段漏油描述文本处理成向量数据的过程。

图2 漏油描述文本转换为词向量Fig.2 Transformation of description text for oil leakage into word vector
1.3 Att-BiLSTM漏油程度量化模型
漏油描述文本是一种序列信息,且词语之间存在很强的逻辑关联,循环神经网络(recurrent neural networks, RNN)是一种用于处理序列信息的经典算法。LSTM是基于RNN的改进形式,有效避免了RNN训练中出现的梯度消失问题,其核心是单元和门管理机制。
将一段漏油描述文本转换为词向量,记为X={x1,x2,…,xn},将其作为训练特征输入LSTM后,当前单元的输出ht由上个单元的输出ht-1及当前单元的输入xt决定,如式(4)所示。
(4)
式中:σ表示Sigmod函数;Wo为LSTM权值矩阵;Ct为当前单元状态值向量;→表示LSTM的数据流方向;bo为线性系数偏倚。
但是单向的LSTM只能从前到后地获取上下文信息,而双向长短期记忆神经网络(BiLSTM)在LSTM的基础上加入一个反向的LSTM从后往前获取信息(见式(5)),并将双向信息融合后输出,从而获取全局信息,见式(6)。
(5)
(6)
式中:Ht为当前BiLSTM的输出。
漏油描述文本中的一些关键词语对于漏油程度的判断尤为重要,如“救援”、“沉重”等。本文在BiLSTM模型中引入注意力机制,建立Att-BiLSTM神经网络模型,通过赋予重要词语更高的权重,使模型对这些词语更加关注,从而提高模型训练结果的准确性。
首先将单元输出Ht通过式(7)建立注意力权重,随后通过式(8)将注意力权重归一化到0~1之间,再通过式(9)将注意力权重配置给Ht。最后将A输入到输出层,通过Relu函数输出漏油程度量化结果,如式(10)所示。漏油程度量化过程见图3。
ut=tanh(Ht)
(7)
(8)
(9)
(10)
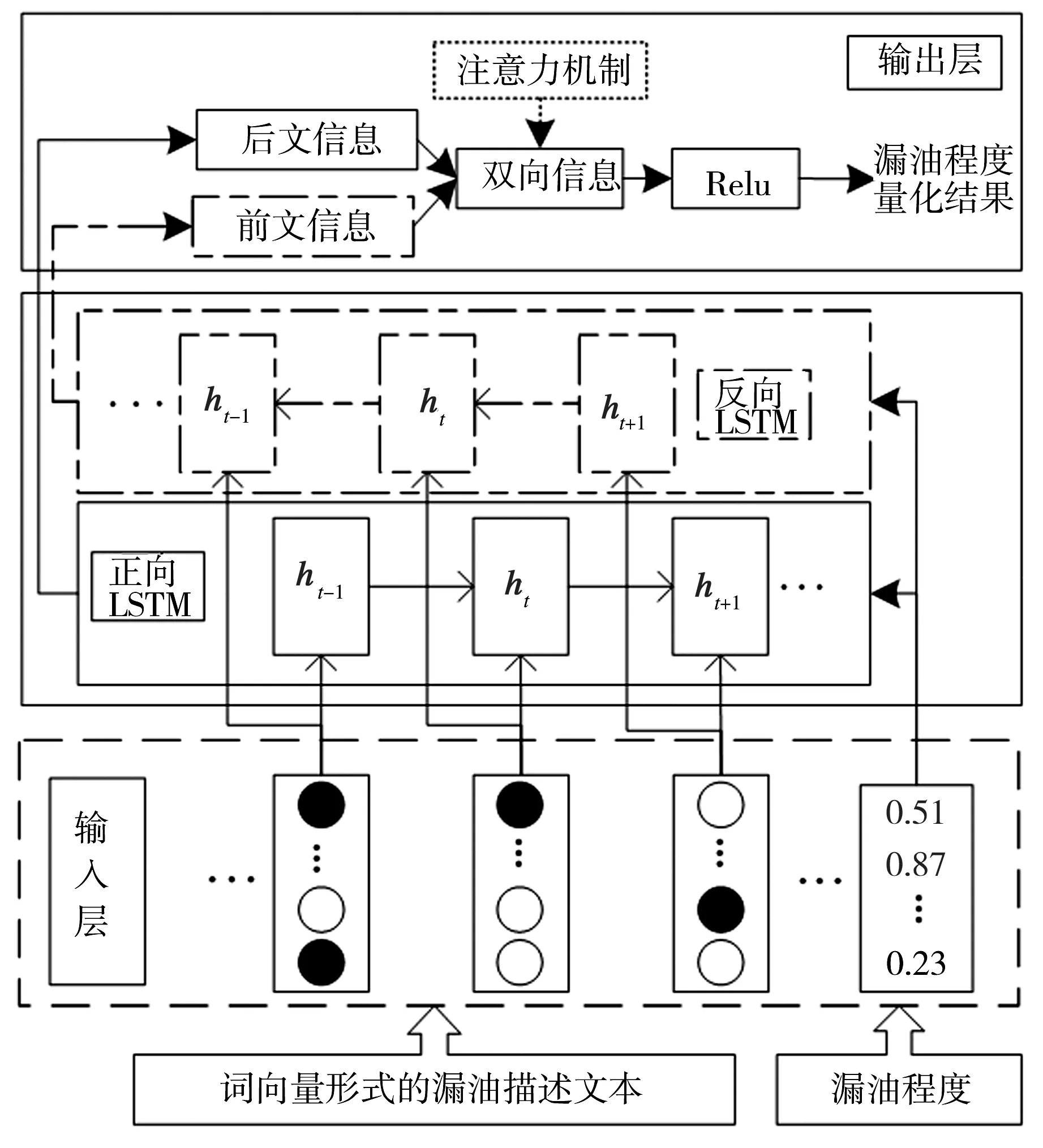
图3 漏油程度量化过程Fig.3 Process of quantifying oil leakage
2 基于RF-BP神经网络的动转系统漏油分析预测
2.1 漏油分析样本数据预处理
根据售后服务记录将漏油程度量化后,结合相关生产信息建立漏油分析样本集,从而进行漏油原因分析及预测。漏油分析样本集中的相关生产信息主要是由售后服务部门的工作人员根据漏油车辆的实际情况在MES、ERP等系统中追溯到的车辆生产信息进行记录,其中不可避免地存在异常数据或缺失值。数据预处理的工作就是把样本集内的数据处理为可以进行预测分析的状态,该阶段的工作质量将会影响到预测分析的效率和准确度。本文按以下步骤对数据进行预处理:①将样本集中记录不完善、缺失甚至错误的项目删除;②使用标准化方法让所有数值都处在0~1之间;③将样本集按照8∶2的比例分为训练样本和测试样本。
另外,样本集中包含一些特征如“车型”、“生产线”等,这些特征对应的字符或数字并无数值上的意义,需要在预处理阶段使用独热编码(one-hot encoding,OHE)对这些特征进行处理,以“车型”为例,OHE处理过程如图4所示。
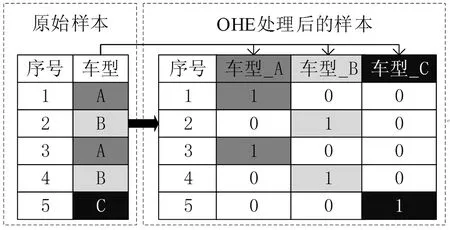
图4 独热编码处理过程Fig.4 Process of one-hot encoding
2.2 基于RF-BP神经网络的漏油分析预测模型
样本集中的各个特征与漏油的相关性并不相同,通过相关性分析,一方面可以找出对漏油问题影响较大的特征,企业应重点关注,另一方面可以在建立回归模型时忽略影响程度较低的特征,降低预测模型的特征维度,从而减少运算资源的浪费,提高预测结果的准确性。
建立RF-BP分析预测模型如图5所示。先通过RF算法获得各个特征的变量重要性(variable importance measure, VIM),再将VIM大于阈值的特征输入BP神经网络进行回归预测。
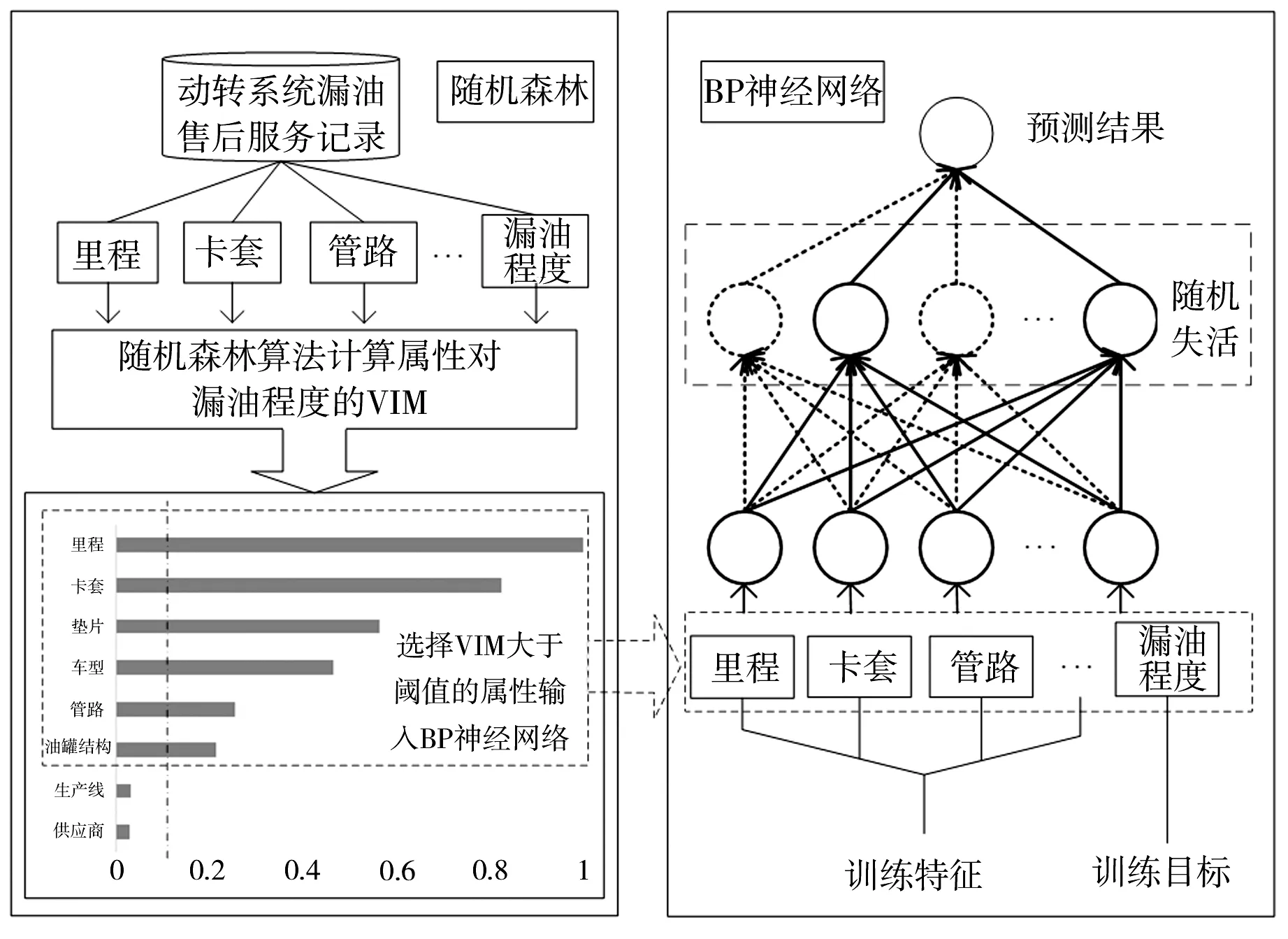
图5 RF-BP神经网络分析预测模型Fig.5 Analysis and prediction model based on RF-BP neural network
2.2.1 计算特征VIM
随机森林算法在分析数据时,通过随机置换各变量的值并计算置换前后袋外数据(OOB)的错误率来确定每个特征的VIM,其计算公式为:
(11)
式中:N为随机森林中决策树的个数;errOOB1it为变量置换之前第t棵树的错误率;errOOB2it为变量置换之后第t棵树的错误率。
2.2.2 预测漏油程度
BP神经网络是用于回归预测的经典模型,将VIM大于阈值的特征输入BP神经网络进行漏油程度预测训练。以平均绝对误差(MAE)和平均相对误差(MAPE)作为模型预测性能的评价指标:
(12)
(13)
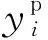
3 实例分析与模型验证
以某卡车制造企业提供的2017年1月到2019年4月的售后服务记录作为实验数据集,共包含635个数据样本。数据分析环境为Python 3.7.3,主要采用Sklearn、Pandas、Numpy等工具及以GPU版TensorFlow为后端的深度学习框架Keras,操作系统为Windows 10专业工作站版。
3.1 动转系统漏油程度量化计算
漏油程度量化属于有监督学习,先要建立训练集。采用模糊层次分析法对训练集中的漏油描述文本建立训练标签需要较大的人力消耗,因此综合考虑其有效性,将训练集设置为200条漏油描述文本。
首先请专家根据动转系统漏油程度评价指标体系(图1)确定评价权重系数,并建立权重判断矩阵R:

计算出矩阵R的最大特征值为5.291,并求得一致性指标CR=0.065<0.1,则其对应的特征向量W=[0.8616,0.4346,0.2177,0.1352,0.0548]T即为5个评价指标的权重。
然后请专家根据漏油程度评价指标体系,分别对当前车辆的各个相关属性进行评分,再通过式(3)计算出这200条漏油描述文本对应的漏油程度以建立训练集。
随后,对训练集进行预处理,通过Word2Vec进行向量化,再将词向量矩阵输入Att-BiLSTM 模型进行训练。对模型加入随机失活(dropout)以避免训练出现过拟合[22],并通过早停法(early stopping)在模型学习率降低或即将陷入过拟合前结束训练。
设计5组实验对Att-BiLSTM模型的性能进行验证,实验中采用的对照组模型描述如下:
(1)用于情感分析的卷积神经网络模型CNN[6]。
(2)引入注意力机制的卷积神经网络模型Att-CNN[7]。
(3)基础的长短期记忆神经网络模型LSTM。
(4)引入注意力机制的长短期记忆神经网络模型Att-LSTM。
(5)双向长短期记忆神经网络模型BiLSTM。
分别对Att-BiLSTM及以上5个对照模型进行训练,结果如表1及图6所示。
由表1和图6可见,LSTM模型在漏油程度量化时比CNN模型具有更好的性能,这是因为在处理自然语言这种序列数据方面,LSTM因其记忆能力而表现更佳。同时,CNN和LSTM在引入注意力机制后,模型精度都得到了提升,表明部分词语对于漏油程度量化十分关键,模型对这部分关键信息进行关注而获得了更高的准确率。另外,相较于单向的LSTM,BiLSTM的精度也得到提升,表明双向信息的获取有利于更加准确地量化漏油程度。总之,与其他5种模型相比,Att-BiLSTM模型在漏油程度量化上具有充分的优势。表2为部分训练样本基于Att-BiLSTM模型的漏油程度量化值与模糊层次分析结果的对比。
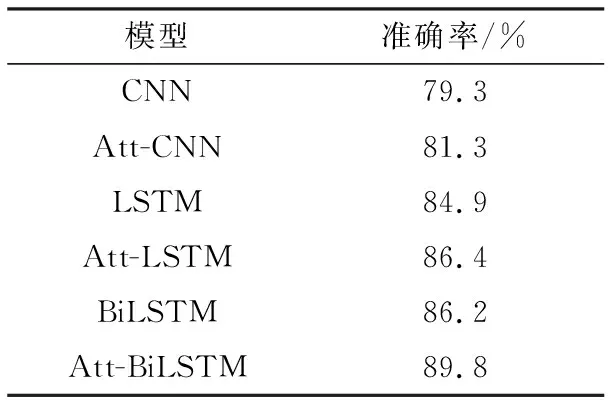
表1 不同模型的漏油程度量化准确率Table 1 Accuracies of quantifying oil leakage by different models
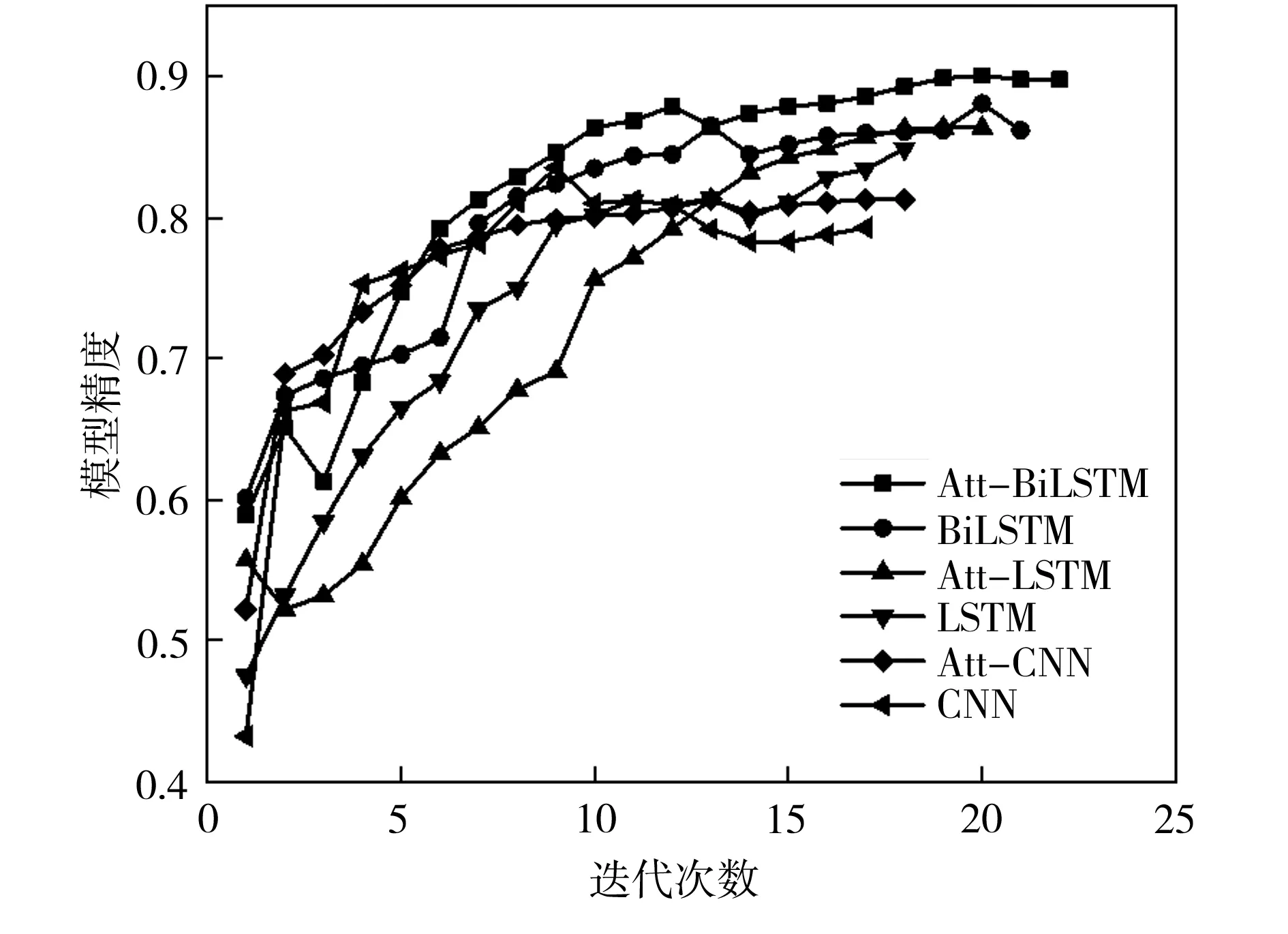
图6 不同模型在训练过程中的精度对比Fig.6 Accuracy comparison of different models during the training
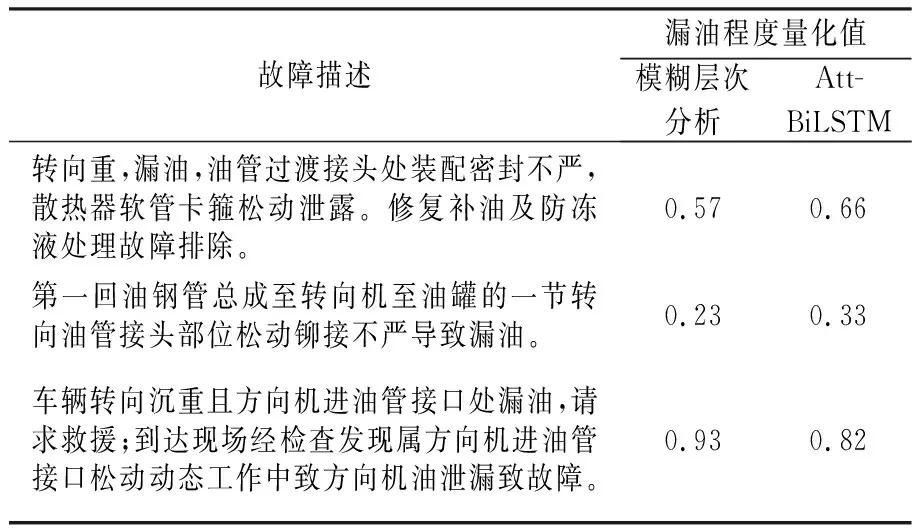
表2 部分训练样本的漏油程度量化结果Table 2 Results of oil leakage quantifying for some training samples
将本次实验数据集中的所有漏油描述文本均输入Att-BiLSTM模型进行漏油程度量化,并对漏油程度分布及其售后服务费用进行统计,结果见图7。
由图7可见,根据5级漏油程度进行区分,有大量卡车的漏油程度为“严重”等级,所产生的售后服务费用占漏油所致总损失费用的67.65%。严重漏油不仅造成卡车制造企业大量的经济损失,同时对卡车驾驶而言也是巨大的安全隐患。
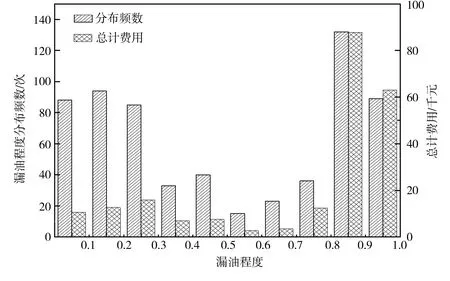
图7 漏油程度分布及售后服务费用Fig.7 Distribution of quantified values of oil leakage and the after-sales service costs
3.2 动转系统漏油分析预测
找到动转系统漏油的原因将有利于卡车制造企业解决漏油问题,节省售后服务成本,提高卡车安全性能。卡车动转系统漏油不仅涉及到设计、制造、管理等方面,也有客户使用习惯及保养维护等方面的原因。漏油问题的相关特征说明见表3。

表3 漏油相关特征说明Table 3 Description of oil leakage related features
通过查阅该企业内部与漏油问题相关的资料,发现企业曾对垫片、卡套、管路及油罐结构进行过工艺改进。为了验证工艺改进效果,将改进前后所生产车辆的对应特征用布尔值表示,改进节点前记为0,改进节点后记为1,同时将前述根据2017年1月到2019年4月的售后服务记录所计算出的漏油程度量化值作为训练目标加入数据集中,建立漏油分析样本集,表4所示为样本集中的部分训练样本。
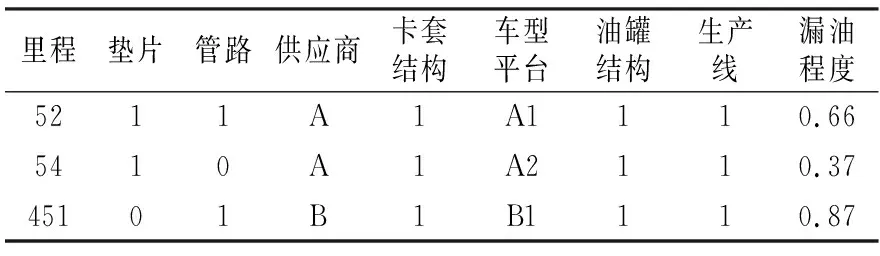
表4 部分训练样本Table 4 Part of the training samples
将样本集进行预处理后通过RF-BP神经网络模型对漏油程度进行分析预测。首先基于随机森林算法计算相关特征的VIM,结果见图8。
由图8可知,车辆行驶里程是与漏油相关性最强的特征,同时该企业对部分结构的工艺改进起到了较好的作用,而且车型平台也是一个比较重要的特征,因此该企业在后期生产中对车型平台进行优化升级也会进一步改善漏油问题。另外,生产线和供应商这两个因素对漏油几乎没有影响,说明企业上游供应商的品控较为可靠,而且企业内部的生产线之间也无差异。将RF-BP神经网络的特征选择阈值设置为0.1,在对漏油程度进行预测时忽略生产线和供应商这两个VIM很小的特征。
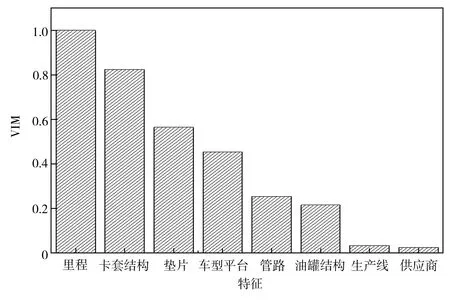
图8 各个特征的VIM值Fig.8 VIM values of various features
分别采用GM(1,1)[23]、SVM[19]、BP神经网络模型及本文提出的RF-BP神经网络模型,根据漏油分析样本集对卡车动转系统的漏油程度进行预测,部分预测结果如表5所示。
由表5可知,总体来看,BP神经网络及RF-BP神经网络模型的预测结果与实际漏油程度的拟合度较好,而GM(1,1)与SVM模型的预测结果则出现了较大的偏差;GM(1,1)模型的误差值出现较大波动,而其他3种模型的误差值相对较为稳定;4种模型中,RF-BP神经网络模型的误差及其波动是最小的,表明通过该模型预测的漏油程度相对更加可靠。
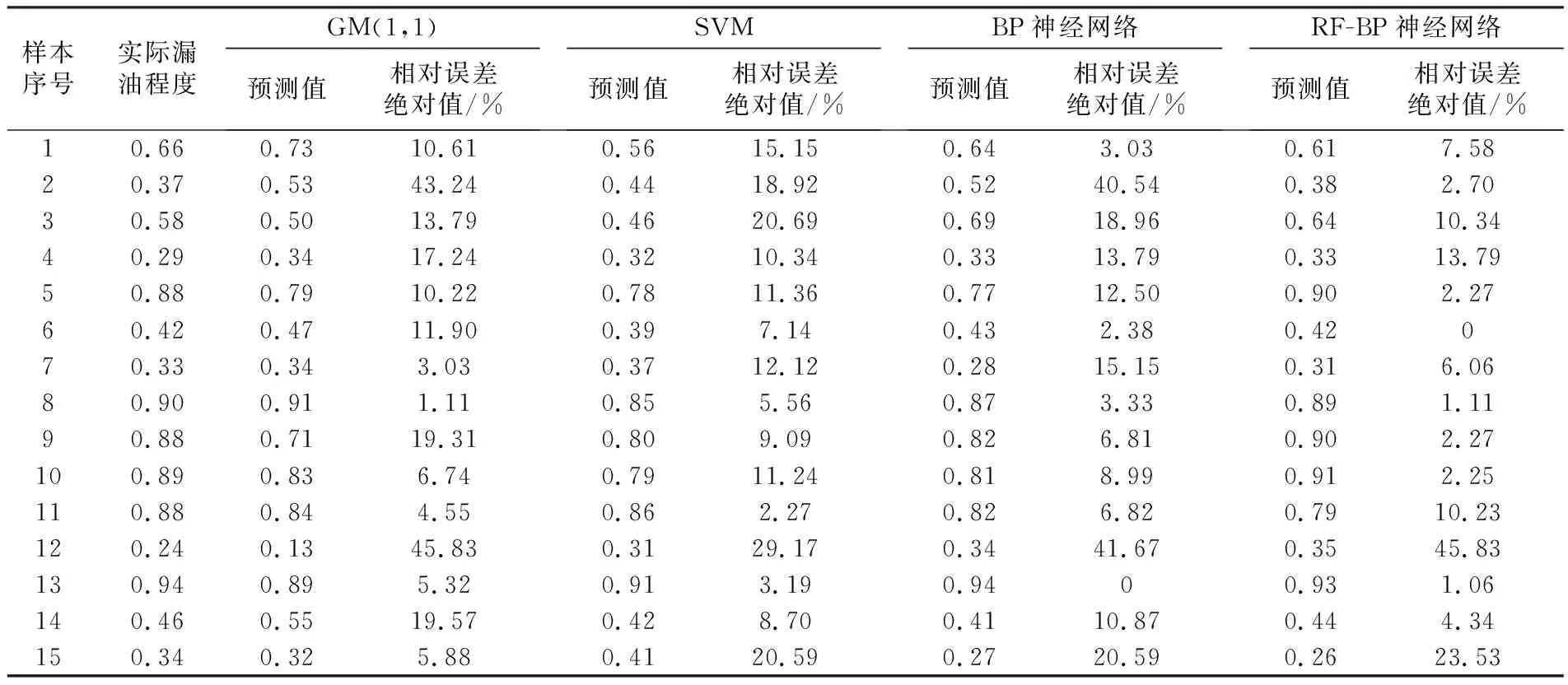
表5 不同模型的预测结果对比Table 5 Comparison of prediction results by different models
为进一步验证模型的性能,将上述4种训练完成的模型分别应用于该企业2019年5月及2019年6月的售后服务记录数据集,分别包含48个及46个数据样本。以MAE及MAPE作为指标进行评价,结果如表6所示。由表6可见,在对漏油程度进行预测时,BP神经网络模型相较于GM(1,1)及SVM具有明显的优势,说明在面对大量的历史数据时,深度学习模型的数据驱动方式能够提供更好的预测性能;而且BP神经网络模型在结合了随机森林算法后,其预测精度又有提升,说明在去除部分VIM值较低的特征后,减少了无关数据对模型的干扰,使其更加关注于重要特征,模型的性能也因此得到了改善。总之,RF-BP神经网络模型不仅在预测精度上具有优势,还可以计算出不同特征的VIM,可用于指导企业进行工艺优化,改善动转系统漏油问题,同时RF-BP神经网络模型的性能在2019年5月及6月的数据集上并未出现明显的波动,表明该模型也具有较好的泛化能力。

表6 不同模型在3个数据集上的性能比较Table 6 Performance comparison of different models tested on three datasets
4 结语
本文提出了一种基于企业售后服务记录的卡车动转系统漏油分析预测方法。首先采用自然语言情感分析的方法建立Att-BiLSTM模型,针对售后服务记录中的漏油描述文本进行漏油程度量化。该模型从漏油描述文本的两个方向全面获取信息,并通过引入注意力机制使模型对文本中的关键词语更加关注,取得了比其他模型更好的效果。然后结合漏油程度的量化结果,建立RF-BP神经网络分析预测模型,通过计算数据集中各个特征的重要性,分析出了卡车动转系统漏油的主要影响因素,据此对漏油趋势进行预测,取得了较好的预测精度。企业可通过预测模型对下线车辆的漏油情况进行预测,及时提醒用户对车辆进行维护,从而避免严重漏油问题的发生,可为企业和用户节省大量费用。
猜你喜欢
锦绣·中旬刊(2022年1期)2022-05-16
家庭影院技术(2021年5期)2021-07-21
意林(2021年2期)2021-02-08
科学与财富(2020年15期)2020-07-04
汽车观察(2018年12期)2018-12-26
汽车维修技师(2017年1期)2017-06-27
儿童故事画报(2017年4期)2017-05-26
商用汽车(2016年11期)2016-12-19
中国质量万里行(2015年8期)2015-11-03
汽车与新动力(2014年5期)2014-02-27
