
基于长短期记忆网络的工控网络异常流量检测①
2020-09-22 07:45田伟宏李喜旺司志坚
计算机系统应用 2020年9期
田伟宏,李喜旺,司志坚,3
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(国网辽宁省电力有限公司,沈阳 110004)
在大力提倡“中国制造2025”,“工业4.0”的大背景下,我国工业得到了快速发展,并且随着计算机技术在工控系统和工控网络中的应用,逐渐打破了传统工控系统和网络的封闭性,由于大多数工控网络协议在设计之初都没有考虑到安全问题,使得工控系统的网络安全面临着严峻的考验[1].例如2010年的“震网”病毒攻击伊朗核设施,黑客渗透至工业内网后,利用工业控制系统的安全漏洞,改变相关设施的运行参数,降低浓缩铀的成品浓度,最终使得伊朗核工业陷入停滞;2015年的“Blackenergy”病毒造成了乌克兰的大面积停电;2018年俄罗斯黑客入侵美国电网;2019年委内瑞拉全国大面积停电.从这些工控网络安全事件可以看出,黑客已经将触角伸入到工业控制领域尤其是电网,并且瘫痪对方的基础设施也成为了国与国之间的对抗手段,工控网络已经成为了理想的攻击目标.
1 工控网络现状
目前工控网络的安全策略方法主要是边界防护,包括使用网闸、工业防火墙、逻辑隔离等手段[2],其主要特点是偏防御轻检测.如平台硬件和软件加固、关键应用代码审计等;强调集中监控,依靠站内审计系统等.主要不足之处表现为缺乏纵深防御,一旦突破边界防护便很容易进行进一步的侵入.
工业控制系统(Industrial Control System,ICS)中,电力行业应用最为广泛,其中的变电站自动化约占整个ICS 市场的40%.目前智能电网正在逐步取代传统的电力网络,而智能变电站又是智能电网建设的重要环节,是结合了比较先进并且具有高可靠性的智能设备组成的智能化变电站,加强了变电站在无人值守、安全生产和远程监控等方面的综合管理水平.网络和信息化技术的发展给电网的智能化提供了保障,然而更多的研究和应用侧重于信息化引入新功能的实现,对信息化和网络化背景下智能电网的安全性缺乏足够的考虑,尤其是入侵检测方面的安全[3,4].目前,建立有效的入侵检测方案是一项巨大的知识工程任务,系统构建者依靠他们的直觉和经验选择异常检测的统计度量标准.专家首先分析和分类工控网络的攻击场景和系统漏洞,并手动编写相应的规则和模式用于检测入侵.由于开发过程中的手动性和临时性,这种入侵检测方案具有有限的可扩展性和适应性,并且方案的更新既昂贵又缓慢.
随着机器学习的热度不断上升,学术界在网络异常检测方面也提出过很多方法,大致分为两种,分别是传统的机器学习方法和近几年广泛使用的深度学习方法.传统机器学习领域中,具有代表性的方法有基于有监督的例如SVM 的二分类方法[5]和无监督的例如KMeans 的聚类方法[6].有监督的方法例如SVM 在训练模型时需要每个样本都有标签,用于区分样本是否为攻击行为,这种方法的局限性在于在工控网络中很难得到攻击类型完整的数据集;无监督的检测方法以Kmeans 聚类算法为例,通过聚类算法来区分正常流量和异常流量.这种方法的局限性表现为模型的稳定性不够好,依赖训练数据集中正负样本的均衡性.深度学习领域中具有代表性的方法有主题模型方法[7]和卷积神经网络方法[8],主题模型方法将数据包视为文档的词汇,将网络异常行为视为文档的主题,通过流量数据包的语义关系识别主题进而识别出网络异常,这种方法的局限性在于工控网络应用领域广泛,流量数据包即“词汇”也在源源不断的更新中,很难学习到完整的语料库;卷积神经网络方法将流量特征值映射为灰度图,使卷积神经网络学习大量的流量特征灰度图,达到识别异常流量的目的,这种方法的优点是识别准确度高,但是由于需要大量的点积运算,所以识别效率并不高.考虑到工控网络周期性强和流量数据包在时间维度上存在序列关系这两个特性,所以本文提出基于时序预测的异常检测模型.在机器学习领域中,周期性的数据天然适合做时序预测,并且当数据存在序列关系时,连接数据的时间动态关系都比每个时间帧的内容更重要.
本文以ICS 中的典型代表电力系统网络作为研究对象,变电站自动化以及调度自动化使用IEC60870-5-104 远动通信规约(Telecontrol equipment and systems-Part 5-104,IEC104)控制协议[9,10].通过对东北电力公司某子网的交换机进行端口镜像,采集一段时间内的流量并进行104 规约的解析,统计检测流量的特征,包括从物理层到传输层的TCP/IP 协议内容和应用层的应用规约控制信息(Applying Protocol Control Information,APCI)内容.数据集采集完成后,本文采用在时序预测领域使用最广泛且模型效果不错的长短时记忆网络(Long-short Term Memory Network,LSTM)进行流量时序预测并检测异常流量.LSTM 是一种改进之后的循环神经网络(Recurrent Neural Network,RNN),可以解决RNN 无法处理长距离依赖的问题和训练模型时梯度消失的问题.考虑到网络流量的派生属性中存在时间流量属性和机器流量属性,其中机器流量属性是为了识别某种攻击,例如探测漏洞行为,需要考虑之前的若干个连接,所以使用LSTM可以更加全面和精准的识别出由多个连续数据包发起攻击引起的流量异常现象.
2 LSTM 网络模型设计
工控网络尤其是电力系统的网络使用场景单一,在网络安全运行的情况下,流量数据表现平稳,并且具有周期性,一旦网络发生异常,流量就会产生较大的波动,具体表现为流量各个维度的数值相较于历史数据发生突变,不再符合周期性的特点.基于工控网络流量平稳和周期性强的特点,本文提出使用LSTM 网络模型对工控网络的流量数据进行时序预测[11-14],在网络正常运行的情况下,可以认为模型的预测值为正常值,当某一时刻的实际值偏离预测值较大,即认为网络出现异常.
2.1 异常流量检测流程
检测流程分为两个阶段,第一个阶段是解析流量数据包构建有效特征,第二个阶段是LSTM 网络模型的离线训练过程和在线检测过程.第一阶段在电力SCADA 系统中通过镜像端口的方式采集通信流量,对采集到的数据包进行深度包解析,针对104 规约数据包,除了要解析常规的源地址、目的地址、源端口、目的端口、标志位和连接时间等基本信息,还要解析长度为6 个字节的APCI,里面包含了控制电路的操作信息.对解析到的字段进行整合并重新构造出模型输入需要的特征,除了采集流量构造出的特征,构建时序模型还需要加入滞后历史特征,即模型需要用多长时间的输入去预测下一时刻的数值.第二阶段在模型离线训练完成后,即可部署线上环境,对电力通信网络进行异常流量预测并实时报警.
2.2 特征构造
如图1所示,第一阶段包含从流量中提取特征,并构造有效特征两部分,流量分为两部分,第一部分是离线采集的流量,主要用于模型训练,第二部分是源源不断的在线流量.从流量中解析出同TCP/IP 协议一样的字段和104 规约中的APCI 字段.解析字段分为3 类,第一类为9 个内部属性,这些属性是从网络数据包的头部中提取得到,例如连接的持续时间(duration),连接的协议类型(protocol_type),包含http、ftp、smtp 和telnet 等70 种网络服务类型(service)等;第二类为内容属性,这些属性是从网络数据包的内容区域中提取,例如从应用规约数据单元中提取的信息体、数据单元标识和104 规约报文变长帧中的APCI;第三类为派生属性,这些属性的计算考虑了之前的连接,细分为时间流量属性和机器流量属性,时间流量属性考虑过去2 秒内发生的连接,例如到同一目标IP 地址的点击总和(count),到同一目标端口号的连接总和(srv_count)等字段.对以上38 个字段构建时间统计特征,构建方法分为计数(count)、占比(percent)和均值(average),共构造出12 个有效特征.例如“相同主机”特征,检查过去2 秒内与当前连接具有相同目标主机的连接,统计连接的数量,再计算与当前连接具有相同服务的连接百分比、不同服务的百分比、SYN (泛洪)的百分比以及REJ(拒绝连接)的百分比.对于诸如报文内部属性中的网络服务类型等的非数值型特征,需要对其进行独热编码(one-hot)转换为数值型特征用于模型的输入.
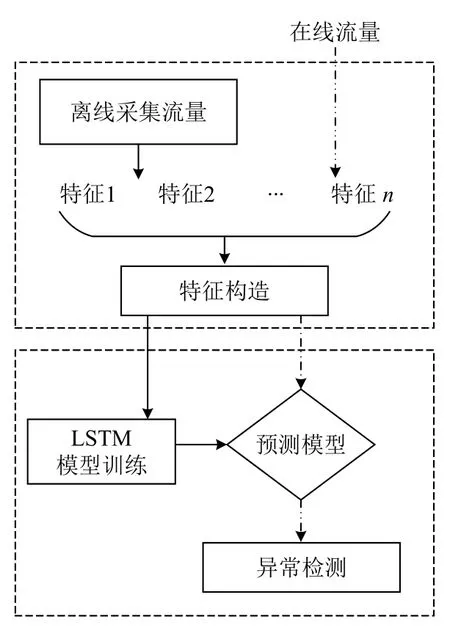
图1 异常流量检测流程
2.3 模型训练
图2中的第二阶段为模型训练部分,分为离线训练和在线检测两部分,离线训练把构造好的特征输入到初始化的LSTM 网络中进行模型训练,训练好的预测模型输入以相同方式构造的特征样本进行异常流量检测,如果模型检测到网络中的流量异常则发出警报.
3 LSTM 网络结构和参数更新
3.1 网络整体结构
LSTM 网络结构由RNN 加入门控机制改进得到,RNN[15]能够很好地处理不固定长度并且有序的输入序列.RNN 前向传播过程如图3所示,网络参数权重的更新不仅仅依赖每一时刻t样 本输入xt对参数w的调整,而且依赖t时刻之前计算并保存的隐含状态ht-1对参数的调整.与传统的RNN 相比,LSTM[16]本质上还是基于t时刻的输入xt和t-1时刻的隐状态ht-1来计算t时刻的输出yt和t时刻的隐状态ht.但是由于门控机制的加入,LSTM 网络更适合处理长依赖问题,更加容易学习到工控网络周期性的规律,并且容易识别由多个数据包共同作用引起的攻击类型.
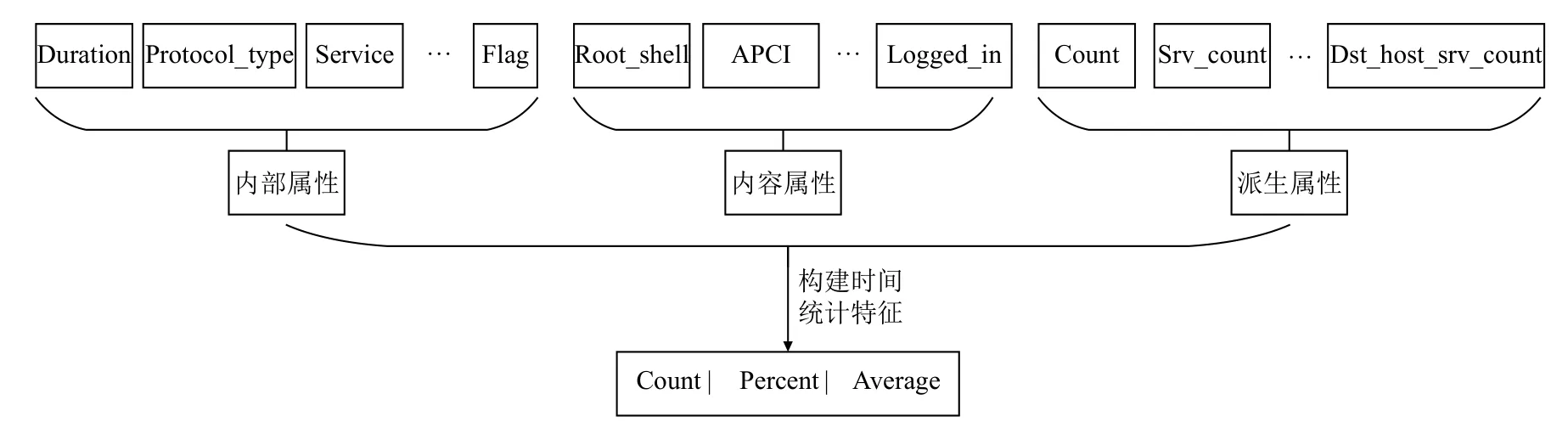
图2 特征构造流程

图3 RNN 前向传播过程
本文提取数据包字段并构造了12 个有效的时间统计特征,网络模型在t时刻的结构为一个简单的前馈神经网络,整体的网络结构如图4所示,有N个前馈神经网络组成,不同时刻的前馈神经网络通过隐藏层神经元传递依赖关系.每层的前馈神经网络分为3 层,分别是包含12 个神经元节点的输入层(Input Layer),含有64 个神经元节点的隐藏层(Hidden Layer),含有12 个神经元的输出层(Output Layer),在训练过程中,前N个时刻的流量数据包用于预测N+1 时刻的流量统计值,即前N个时刻为样本特征,第N+1 个时刻为样本标签.
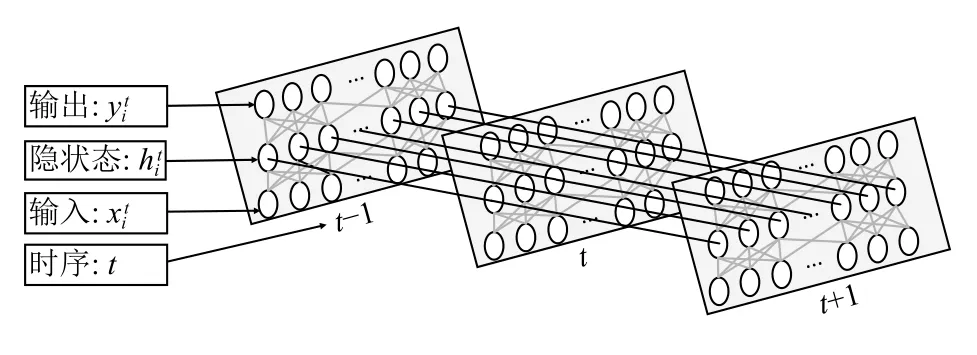
图4 LSTM 神经网络时间展开图
3.2 参数更新过程
LSTM 网络相比RNN 增加了存储单元用来存储长期记忆,增加了输入门用来记忆t时刻的输入信息,新来一个样本,并不会完全学习记忆其中的特征,而是自动学习除其中有多少有用信息可以用于N+1 时刻的预测.遗忘门用来选择性的忘记过去的某些信息,起控制内部信息的作用.输出门起控制输出信息的作用,3 个门控单元的加入让LSTM 网络在用梯度下降算法更新参数时不易于陷入梯度消失的问题,3 个门的逻辑结构如图5所示.
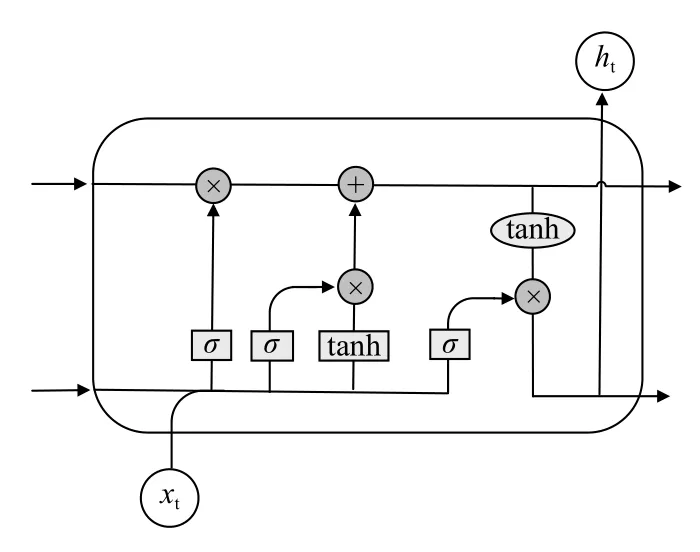
图5 LSTM 网络门控机制
输入门输入15 分钟以内180 个样本的时间统计值,15 分钟为滞后历史特征数值,在训练过程中是一个超参数,经过多组训练实验得到最优滞后历史特征,对滞后历史特征数值的选择如表1所示,可以发现,当滞后历史特征为15 分钟时,模型在验证集上的损失最低,表面用前15 分钟的流量去预测下一时刻流量的时间统计特征最准确,本文以5 s 为最小单位,在预测流量时,预测下一时刻(5 s 内)的流量统计特性.网络内部输入门的计算过程为
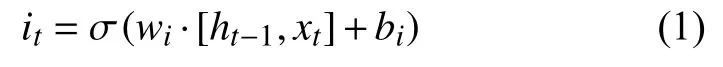
其中,σ为Sigmoid 激活函数.遗忘门、输出门和输入门计算方式一样,细胞状态Ct用于长期记忆,更新过程为:
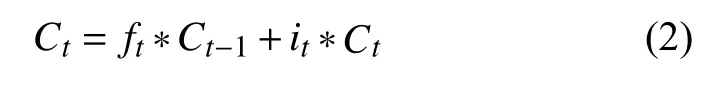
隐状态ht用于短期记忆,更新过程为:

其中,ot为输出门的输出,tanh 为双曲正切激活函数.
本文的隐藏层神经节点有960 个,网络输入的是一个三维向量[640,180,12],第一维batch_size 的含义是一次性将640 个样本序列,输入到网络中进行训练,使用梯度下降的方法完成一次误差反向传播和参数更新,第二维time_step 的含义是用前180 个样本去预测下一时刻的流量值,第三维input_size 是单个样本的维度.网络的输出是一个二维向量[640×180,12],第一维代表输出(预测)的时刻流量值,第二维代表单个样本的维度.网络的输出为数值型数据,所以损失函数采用均方误差损失函数[17],定义为
其中,y为样本标签,y′为模型预测值,输出值为1×12 的向量,图6为网络输出层的数据流图,隐藏输出为输出层的输入,经过reshape 后和输出层权重进行点积运算,加上偏置后得到115200 个样本的预测值.
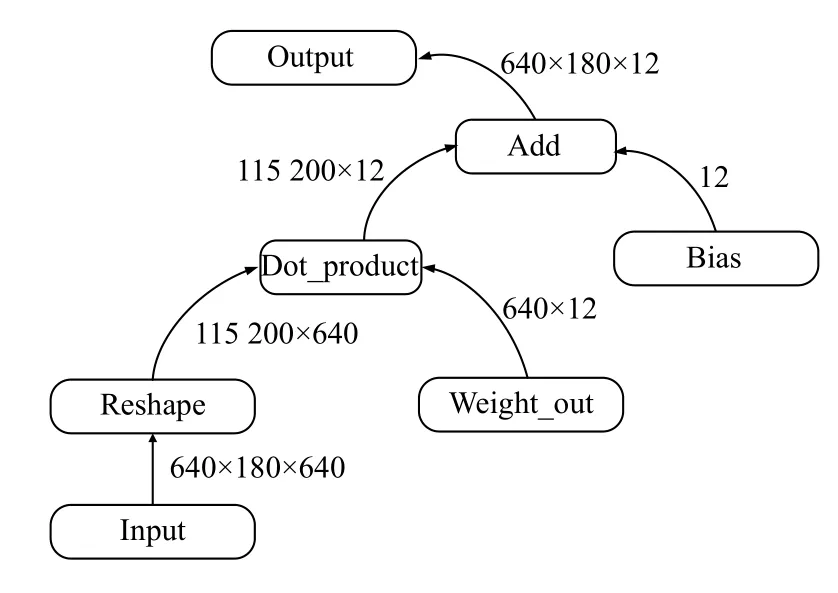
图6 网络输出层数据流图
4 实验设计与结果分析
本文训练模型所用的数据采集自东北电力公司某子网,利用C++库函数libpcap 对数据包进行捕获和深度解析,对捕获到的数据包在时间维度上进行整合,对时间间隔为5 s (慢速攻击标准)内的流量报文构造统计特征生成一个样本,数据集的大小为4.26 GB,将数据集按照采集时间分为训练集和验证集,训练集和数据集的比例为70%:30%,由于时间序列的原因,划分数据集不能随机打乱,而是按照采集流量的时间线,把前70%的数据包划分为训练集,后30%的数据包划分为验证集,供模型训练和验证其有效性[18].
4.1 模型训练过程
模型训练过程中,网络参数可以由训练得到,滞后历史特征和隐藏层神经节点个数两个超参数通过网格调参的方式选取最优组合,通过多轮训练的结果,如表1所示,可以发现,最优组合为滞后历史特征的值为15 分钟,隐藏层的神经元节点数的值为960 个.模型每更新500 次参数后计算一次训练误差和验证误差,在迭代到第19 轮时,validation_loss (验证误差)达到最小,在最优组合的超参数下,模型在验证集上的准确率可以达到97%,图7为模型的validation_loss 下降过程,从图7中可以看出,从第19 次迭代后,模型的validation_loss 不再下降.
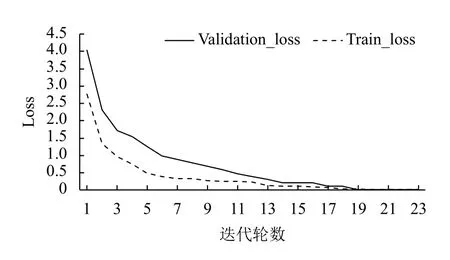
图7 训练和验证损失
4.2 实验结果对比
表2列举出了多种主流算法对工控网络异常流量的识别率、误报率和识别效率,可以发现,本文算法在识别率和识别效率均优于半监督的K-means 算法、单类支持向量机(One Class Support Vector Machine,OCSVM)和BP 神经网络,相比卷积神经网络方法,本文算法误报率稍高,但是识别效率却快了几倍.总体而言,本文算法结合工控网络周期性强和流量报文具有时序的特点,使用LSTM 模型取得了较好的效果.
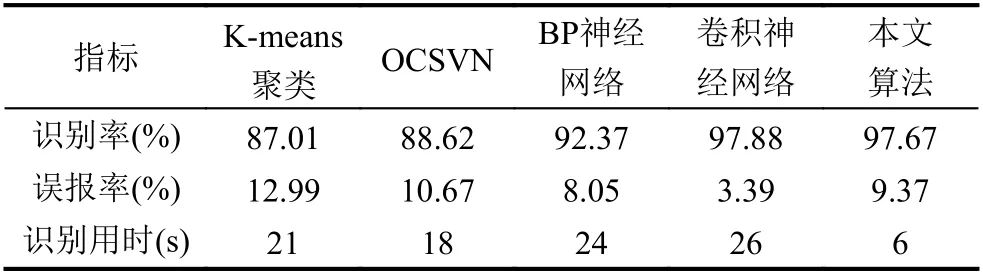
表2 各类算法测试结果对比
5 总结
本文以工控网络中的电力系统网络为研究对象,使用LSTM 算法识别工控网络流量异常,结合工控网络场景相较单一和周期性的特点,采集流量后对解析的数据包字段解析重构时间统计特征,采用时序预测的方式识别流量异常,通过实验可以发现,能有效识别出异于正常情况的网络波动,由于提前预测出正常流量的特征值,算法在异常流量的识别效率上优于传统识别方法,有利于技术人员尽早发现异常做出相应的安全防护措施,提高工控网络在入侵检测方面的安全性.本文提出的时序预测模型虽然在识别准确率和识别效率相较其它算法有所提升,但是时序预测模型要求流量数据具有周期性这一特点,并且模型的最终效果非常依赖训练前期的特征构造,目前特征构造中使用计数、百分比和均值统计指标,后续为了进一步提高模型的识别率,降低模型的误报率,会在特征构造中加入其它的统计指标.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
中国电子报(2019年75期)2019-01-16
物联网技术(2018年8期)2018-12-06
中国新通信(2016年2期)2016-03-11
中国经济周刊(2016年9期)2016-03-09
中国信息化周报(2015年17期)2015-06-01
小学阅读指南·高年级版(2014年2期)2014-05-27
