
基于改进Deeplab V3+网络的语义分割①
2020-09-22 07:45席一帆孙乐乐何立明
计算机系统应用 2020年9期
席一帆,孙乐乐,何立明,吕 悦
(长安大学 信息工程学院,西安 710064)
1 引言
图像分割是计算机视觉领域的重要分支,在无人驾驶,医学图像,3D 重建等场景用广泛的应用.传统的图像分割算法利用图像的颜色、纹理、形状等低级语义信息进行分割,缺失像素的对比度,方向度等中级语义[1-4];聚类是利用像素中级语义进行分割,但缺少像素之间的实体类别之间的高级语义;深度学习算法学习图像中的高级语义.深度学习的语义分割是对图像像素进行逐个分类,解析图像的深层次语义信息.Shelhamer 等[5]提出FCN (全卷积网络)可以对任意大小的图片进行处理,同时还引入跳级连接使低级语义信息和高级语义信息的融合,反卷积上采样恢复图像分辨率,但在细节上分割效果不好;Ronneberger 等[6]提出一种基于编码解码器架构的U-net,编码器对图像进行深层次的特征提取,生成高级语义信息,解码器利用跳级连接的思想,对不同分辨率特征图进行通道融合产生较好的分割效果.Vigay Badrinaryanan 等[7,8]提出SegNet,该网络架构与U-net 类似,不同的是SegNet 上采样利用编码器池化操作的下标去恢复图像分辨率,加速网络的推理,且占用更少的内存.Zhao 等[9]提出PSPnet 利用空间金子塔模块以不同的感受野提取全局特征,融合上下文信息进行上采样得到预测结果.Lin 等[10]提出Refinet,充分利用下采样的特征图,利用长范围残差链接的思想,将粗糙的高层语义特征和细粒度的底层特征进行融合,通过Renfinet block 将特征图进行逐层融合生成分割图像.谷歌提出一系列Deeplab 模型[11-14],其中Deeplab V3+的分割效果最优,但该模型在处理速度和模型容量上并不占优势,本文依据Deeplab V3+模型提出一种优化算法,对骨干网残差单元重新设计,对ASPP 模块进行优化,且在公开数据集进行对比实验,改进后的模型在准确度和精度提高的情况下,进一步提高网络的处理速度,优化该模型的内存消耗.
2 方法与网络
2.1 Deeplab V3+网络概述
Deeplab V3+网络模型主要基于编码解码器结构,如图1所示.该模型的编码器架构由骨干网ResNet101和ASPP 模块组成,骨干网提取图像特征生成高级语义特征图,ASPP 模块利用骨干网得到的高级语义特征图进行多尺度采样,生成多尺度的特征图,在编码器尾部将多尺度的高级语义特征图在通道维度上进行组合,通过1×1 的卷积进行通道降维.解码器部分将骨干网的低级语义特征通过1×1 卷积进行通道降维,保持与高级语义特征图串联在一起时的比重,增强网络学习能力.再用3×3 的卷积提取特征,编码器尾部进行上采样,产生最终的语义分割图.
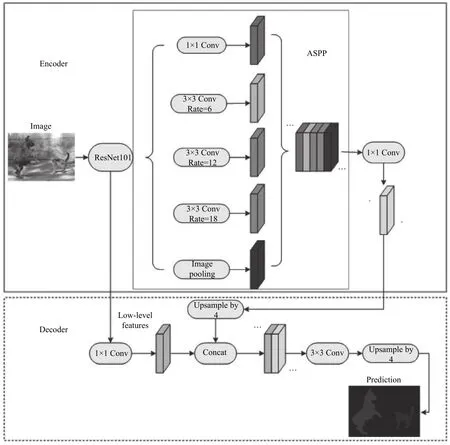
图1 Deeplab V3+模型图
2.2 骨干网的改进
骨干网ResNet101 利用基于瓶颈设计的残差块作为基本单元,组成101 层的残差网络.如图2(b)骨干网由通道数为w0的残差块组成,w0的组合为(64,128,256,512),这4 类瓶颈残差单元的数目分别为(3,4,23,3),加上网络前端的7×7 的卷积和最后1×1 卷积层共101 层.瓶颈单元拥有更少的参数,可以训练更深层次的网络,而非瓶颈单元(如图2(a))随着深度增加,可以获得更高的准确率,结合瓶颈单元和非瓶颈单元的优点,重新设计残差单元.文献[15,16]已证明二维卷积能被分解成一系列一维卷积的组合.依据文献[17]在卷积层松弛秩为1 约束的条件下,卷积层f i可以重新写成:

图2 骨干网


式中,L为卷积层的数目,φ(·)为ReLU.将骨干网的瓶颈单元替换为1D 非瓶颈单元(如图2(c)).在3×3 卷积输入特征图通道数相同的条件下,1D 非瓶颈单元能减少33% 非瓶颈单元的参数和29% 的瓶颈单元参数.(假如c为3×3 卷积输出通道数,则3×3 常规卷积参数量为w0×3×3×c,2D 分解后的参数量为w0×3×1×c+w0×1×3×c,分解后能减少约33%权重参数;1D 非瓶颈单元总参数量12w02,瓶颈单元的总参数量17w02,非瓶颈单元的总参数为18w02)分解2D 卷积后,增加ReLU 非线性操作,能增强1D 非瓶颈单元的学习能力.因此1D 非瓶颈单元拥有非瓶颈单元的准确率高的和瓶颈单元参数少,易训练深层网络的优点.
2.3 ASPP 模块的改进
ASPP 模块主要是对骨干网的特征图进行多尺度语义信息提取.由于ASPP 模块中3×3 卷积会学到一些冗余信息,参数数量多,因此会在训练中耗费很长时间.常规卷积已被证明会计算许多重叠的冗余信息.依据骨干网改进的方法,将ASPP 中3×3 的空洞卷积进行2D 分解(如图3所示),将其分解成3×1 和1×3 的卷积,保持其空洞率.该改进的ASPP 模块卷积参数量比常规卷积的参数量要少33%,在速度上比3×3 卷积快,能够提取到重要的语义信息,有效的减少该模块计算量.

图3 改进的ASPP 模块
3 实验与分析
3.1 实验环境
实验运行环境Win10 操作系统,工作站 GPU 型号为:NVIDIA GeForce GTX 1070 (8 GB 显存),基于Tensorflow深度学习框架,本文利用Deeplab V3+原文的tensorflow官方源码,并对其进行改进,进行对比实验.
3.2 实验训练与结果分析
实验用的是PASCAL-VOC2012 增强版数据集,训练集10582 张,验证集1449 张,该数据集包括20 个类别.本实验将图片分辨率缩放至513×513 像素,由于真实标签和预测结果是灰度图,为了显示分割效果采用RGB 彩色图显示.训练网络前,将图像转化为Tfrecord文件,便于高效读取数据.
本实验将基于的1D 非瓶颈单元的骨干网在Imagenet数据集上进行预训练,再将其预训练权重加载到改进的模型中.利用上述数据集进行训练,超参数设置如表1所示.
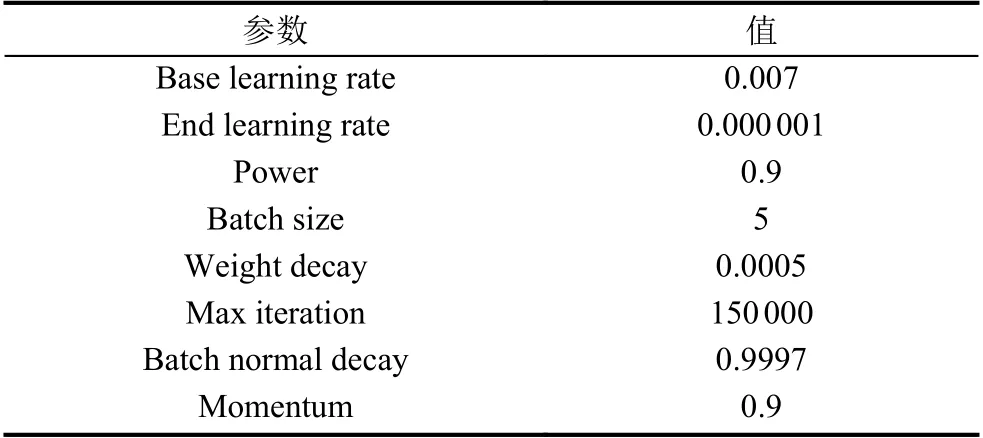
表1 训练参数
学习率采用多项式衰减,当迭代次数超过 Max iteration 次,学习率为End learning rate.采用动量梯度下降法去优化损失函数,总共迭代71 epochs,如图4所示,总共迭代150307 次,每迭代一次大约耗时7 s.总损失(总损失包括交叉熵损失、权重正则化损失)在大约12 万次左右开始收敛,选取总损失最低的模型作为测试模型.改进模型在训练集上的MIoU为89.9%,像素的平均准确率97.3%.

图4 总损失函数图
图5所示,改进后的模型在拥有多个类别对象的图像上,有良好的分割结果,尤其是在第一幅图将车与人两个类别的边界处分割效果较好.

图5 改进后模型在验证集分割结果
3.3 实验对比
语义分割有4 种评价指标,分别为像素精度(PA),均像素精度(MPA),均交并比(MIoU),频权交并比(FWIoU).假设有K+1 个类,pij表示被属于第i类但预测为第j类的像素数目,即pii为真正的像素数量(TP),pij为假负的像素数量(FN),pji为假正像素数量(FP).
PA:为被分类正确的像素占总像素数目的比例:

MPA:计算每个类被正确分类的像素比例,再取平均:
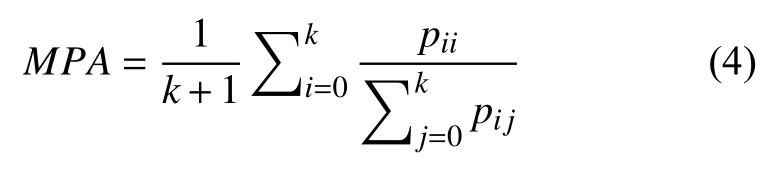
MIoU:真实标签与预测标签的交集比上它们的并集,计算每个类的IoU,再取平均:
FWIoU:在IoU 的基础上将每个类出现的频率作为权重:
为了便于对比,实验将MPA,MIoU作为原模型与改进后的模型衡量标准.
表2说明,改进后的模型在均像素精度上比原模型高0.78%,且在MIoU上比原模型高0.63%,因此改进模型拥有更准确和可靠的分割结果.表3可以得出,改进后的模型在设备上所占内存大小和单张图片处理速度上,明显优于原模型,其中在单张图片的运行时间上,改进后的模型速度提高约9.44%,且模型容量减少了19.6%.主要由于对骨干网和ASPP 模块的卷积层进行改进,去掉冗余的权值,参数量变少.

表2 Deeplab V3+与Modified Deeplab V3+的均像素精度和均交并比比较(%)

表3 Deeplab V3+与Modified Deeplab V3+在单张图片处理时间与模型大小的比较
图6所示总损失函数,Deeplab V3+和Modified Deeplab V3+模型的损失函数收敛速度几乎一样,原模型Total loss 最终收敛到1.91,而改进后模型Total loss收敛到1.73,且改进模型的损失函数摆动幅度小更稳定,训练时间比原模型短3.5 小时.

图6 总损失函数
图7中圆圈标记出的图像区域,Modified Deeplab V3+的分割结果更精细.例如:第一幅图Modified Deeplab V3+将椅子的空当分割出来,而原模型未分割出,且原模型将窗户误分类为显示屏;第二幅图改进模型将飞机机翼准确分割出,原模型未分割出机翼;第三幅图改进模型能将车顶的人的跳跃姿态和车下的人准确分割,原模型对车顶的人分割结果模糊,且车下的人未被分割出;第四幅图改进模型准确将椅子分割;最后一幅图改进模型在马的腿部分割效果比原模型要完整.明显可以看出改进模型分割效果更好,且误分类少.主要归因于Modified Deeplab V3+的1D 非瓶颈单元提高了图像分类的准确度,且ASPP 模块卷积分解后,引入非线性操作,增强网络学习能力,有助于减少误分类,同时在分解的卷积上再引入空洞卷积,进一步扩大感受野,提高网络在图像边缘分割的精细度.

图7 Deeplab V3+与Modified DeeplabV3+测试集分割结果对比
4 结论
本文提出了一种基于卷积分解优化Deeplab V3+网络的算法,该算法主要利用2D 卷积分解减少参数冗余,提高处理速度,同时引入非线性操作,增强模型学习能力.本文利用该算法重新设计Deeplab V3+模型骨干网的残差单元,使其既拥有非瓶颈单元的准确度,又有瓶颈单元参数少,易训练深层网络的优点;同时又对ASPP 模块也进行优化,加速网络的推理速度,减少其训练和处理时间.实验结果证明Modified Deeplab V3+与原模型相比在提高均像素精度的同时,明显提升均交并比,且网络处理速度提高9.44%,优化网络模型的内存消耗.测试集的结果表明,Modified Deeplab V3+在图像细节处分割结果更精确.进一步的工作是探究如何控制感受野的大小,提高模型对小目标分割的精确度.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
英语文摘(2021年10期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
通信产业报(2020年12期)2020-04-26
作文周刊·高二版(2019年43期)2019-01-06
环球时报(2018-09-13)2018-09-13
通信产业报(2018年21期)2018-08-20
通信产业报(2017年46期)2018-01-22
