
跌倒异常行为的双重残差网络识别方法*
2020-09-13 13:53:42王新文谢林柏
计算机与生活 2020年9期
王新文,谢林柏,彭 力
物联网技术应用教育部工程研究中心(江南大学物联网工程学院),江苏无锡 214122
1 引言
异常行为识别是视频行为识别领域中的重要研究方向,对社会安全和发展具有重要意义。跌倒识别作为异常行为识别任务之一,尤其老人跌倒识别,是关爱弱势群体的重要研究课题。根据联合国2015年世界人口老龄化报告,在2015年至2030年间,年龄在60岁及以上的人数预计将增长55%[1]。每年全球估计有64.6万人死于跌倒,有3 730万人跌倒严重到需要医疗照顾[2]。随着计算机视觉技术和传感器技术的发展,国内外对老人跌倒检测进行了研究,并取得了一定的进展[3-8]。根据跌倒检测的方式,跌倒检测主要分为两类,基于可穿戴设备[4,7]和视觉图像[5-6,8]的跌倒检测方法。基于视觉图像技术是对摄像设备采集的视频或图像数据进行跌倒识别处理。Mirmahboub等人[8]使用背景建模的方法提取运动目标轮廓,然后根据运动目标轮廓的特征进行行为分类。Kong等人[5]通过深度相机和Canny滤波器得到二值图像的轮廓,然后根据轮廓图像中的每个白色像素的切线向量角度判断动作行为是否为跌倒。Min等人[6]使用快速区域卷积网络[9]检测人体形状的纵横比、质心和运动速度,通过这些特征随时间的变化关系来判断动作行为是否为跌倒。
随着深度学习的快速发展,卷积神经网络在图像处理[10-11]和视频分析[12-16]领域取得了很大的突破。与传统方法相比,深度学习有较强的特征学习能力。在视频行为识别领域中,行为特征提取主要采用两种思路。第一种是采用二维卷积分别提取RGB和光流图像的空间特征和时间特征[12]。第二种是直接使用三维卷积神经网络提取图像序列的时空特征,如三维卷积网络(3-dimensional convolutional networks,C3D)[13]、三维残差网络(3D residual networks,3DResnet)[15]、伪三维残差(pseudo-3D residual networks,P3D)[14]等。Tran等人[13]把二维卷积拓展到三维提取时空特征,该方法将时间和空间信息在一个卷积网络结构内完成,速度较快。为改善深层结构带来的梯度消失问题,He等人[11]提出二维残差网络(residual network,Resnet)结构,Hara等人[15]把二维Resnet扩展到三维得到3D-Resnet,提高了行为识别效果。Qiu等人[14]在残差结构基础上提出一种伪3D的P3D模型,用1×3×3的空间卷积和3×1×1的时间卷积代替3×3×3的时空卷积,降低了模型计算量。Tran等人[16]也提出了一种用空间卷积和时间卷积代替3×3×3时空卷积的2+1维残差网络((2+1)D residual network,R(2+1)D)。不同于P3D包含三种残差模块,R(2+1)D仅包含一种残差模块,并进行了超参数设计。
当监控视角、动作姿态和场景等复杂时,为了使深度学习方法提取更有效的视觉特征,需要通过增加卷积网络的层数来增强模型表征能力。以上3D卷积网络方法中,C3D网络的参数较多,不适合进行深层的拓展;3D-Resnet是一种残差结构,更适用于模型的深层拓展,但是模型训练时仍然存在梯度消失问题,导致训练损失下降慢、模型过拟合和测试识别率低。
针对以上问题,本文提出了一种双重残差网络模型(double 3D residual network,D3D)用于跌倒识别。双重残差网络模型是通过在残差网络中嵌套残差网络,使得卷积网络层数加深时,误差反向传播的梯度能够传入浅层卷积,缓解训练时梯度消失问题,并充分融合了浅层和深层视觉特征。本文将双重残差网络在UCF101行为识别数据集和多相机跌倒数据集(multiple cameras fall dataset,MCFD)上进行了测试,验证了提出的双重残差网络对削弱梯度消失影响的有效性。最后,在MCFD和热舒夫大学跌倒数据集(UR fall dataset,URFD)上进行了跌倒识别实验,分别达到了较好的效果,有效地解决了在监控视角、人体姿态和场景等复杂的情况下跌倒识别率较低的问题。
2 基于双重残差卷积网络的跌倒识别方法
2.1 基于3D卷积网络的跌倒识别方法
卷积神经网络是一种通过卷积和池化等操作从图片中提取更为高级和抽象特征的深度学习模型。二维卷积只能够有效地提取二维图像的空间特征,而三维卷积可以提取到视频图像序列的时间和空间特征。是第i层的第j特征图上(x,y,z)位置处的特征值,如式(1)所示:
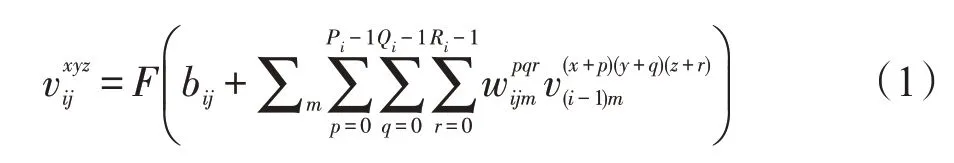
其中,F为非线性函数,如Relu、Softmax。P、Q、R分别是3D卷积核的高、宽和时间维度大小,是卷积核点(p,q,r)与上一层第m个特征图相连接的权重,b为卷积核的偏置。
跌倒和蹲下以及坐下等其他日常行为复杂多样,并且在不同的摄像角度下呈现不同的姿态,如图1[17]。传统跌倒识别算法[5-6,8]需要对视频进行大量的预处理,如背景减除和提取轮廓等,而基于3D卷积网络的方法可以通过训练学习模型来自动提取视频中动作的时空特征,从而对跌倒、行走和蹲下等其他日常行为以及背景(没有动作发生)进行分类识别。基于3D卷积网络的行为识别框架如图2所示。

Fig.1 Types of fall and daily action图1 跌倒及日常动作类型
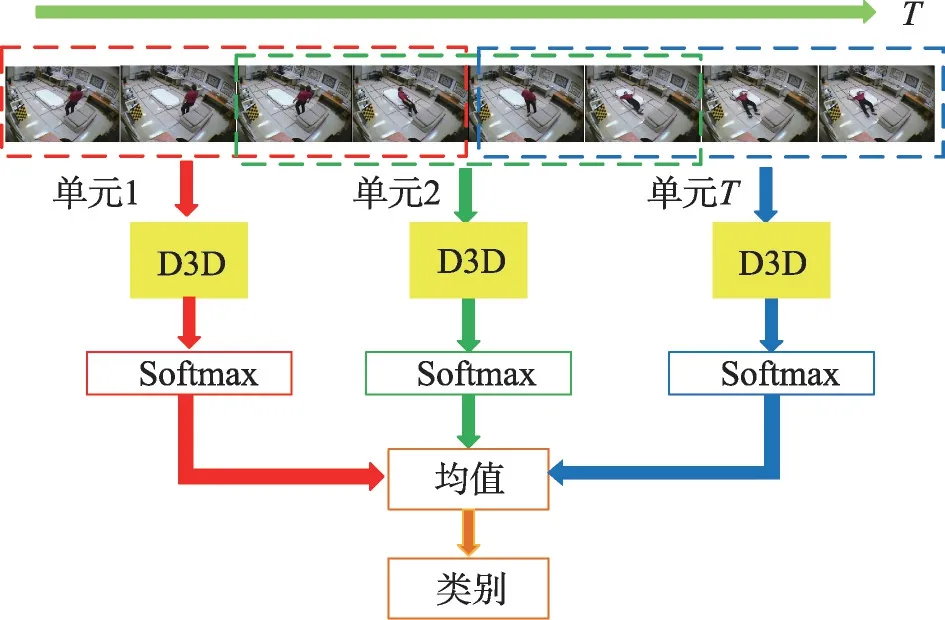
Fig.2 Fall recognition method based on 3D convolution neural network图2 基于3D卷积神经网络的跌倒识别方法
将帧长为L的视频序列V输入到3D卷积模型进行动作识别。由于3D卷积模型输入维度固定,因此将视频序列V划分为帧长为l的视频单元,步长为δ,则,T为视频单元总数。把视频单元ut输入到3D卷积网络模型输出yt,经Softmax层得出n类行为的概率值

取所有测试单元的Softmax层输出的均值作为最终的结果p。

则p中最大的概率值pmax所对应的类别标签i即为最终的识别结果。
2.2 双重残差卷积网络
当人体行为姿态和场景复杂时,为了提取更深层次和更抽象的时空特征,需要增加卷积网络的深度,但是三维卷积网络深度过大时,会产生梯度消失的问题。梯度消失是在误差反向传播训练模型时,越靠前的卷积层权重参数的梯度值越小,使得浅层卷积的权重参数无法进行调整,这会导致模型训练收敛速度缓慢和模型表征能力变差。为了解决梯度消失问题,He等人[11]提出了二维残差卷积网络,有效地提高了图片分类的精度。由于人体行为不仅包含图像空间信息还包含时间信息,因此把二维残差网络扩展到三维残差网络得到3D-Resnet[15]。本文在进行行为识别实验时发现,3D-Resnet网络模型仍出现梯度消失、损失收敛速度缓慢和测试精度差的问题。因此为了进一步削弱网络加深带来的梯度消失影响,提高模型质量和跌倒识别精度,本文对3D-Resnet改进如下:
定义一个3D-Resnet单元为:

其中,x、y为残差单元的输入与输出,F(x,W)是x经过两个三维卷积输出的特征图。W1、W2为残差单元卷积核的权重,σ为Relu激活函数。为了方便显示,把卷积中的偏置舍弃。
图3给出了两个相连接的3D-Resnet单元结构,输出为:

其中,F1(x,W)、F2(x,W)是分别经过卷积输出的特征图。W1、W2、W3、W4为残差单元中卷积核的参数矩阵。3D-Resnet单元内部卷积层通道梯度为卷积层输出对输入的导数:
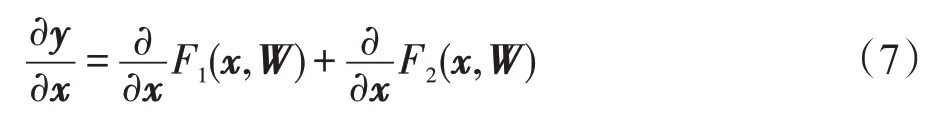

Fig.3 3D-Resnet unit and D3D unit图3 3D-Resnet和D3D单元
把图3中两个3D-Resnet作为一个整体模块。假设一个残差网络中共有M残差模块相连接,则训练误差反向传播时,残差网络的第m(0 ≤m≤M)模块层的梯度为:

其中,J为误差函数,Y(m) 为第m模块层的输出和m+1层的输入为第i模块内部卷积层通道梯度。根据式(8)可知,3D-Resnet第m模块层的梯度为其后面所有内部卷积层通道梯度之积。随着网络的加深会导致第m层的梯度较小或接近于0,造成梯度消失情形。
为了进一步削弱梯度消失的影响,令第m模块层的梯度为:
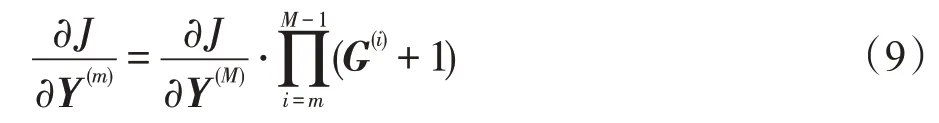
式(9)中加入“1”的目的是为了在进行误差反向传播时,使得模型浅层卷积的梯度不接近于0,从而避免梯度消失,使得浅层卷积参数得到充分训练。因此对于每一个残差模块,内部卷积层通道梯度为:
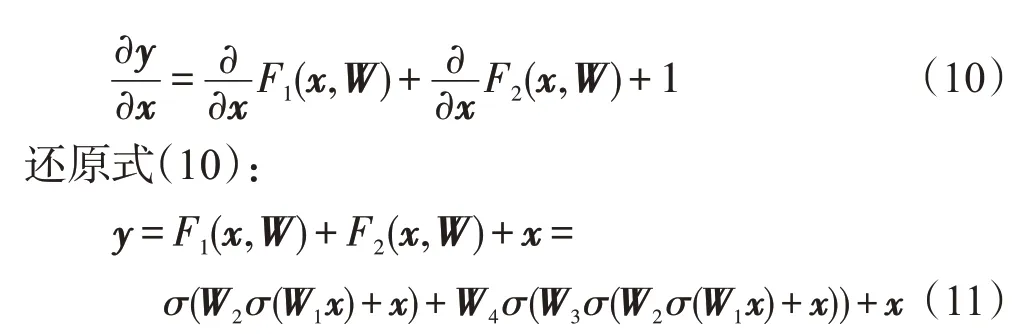
则y的网络结构形式是在残差结构中再嵌套两个残差模块。同时针对跌倒视频数据集小的特点并为了防止模型出现过拟合情形,本文通过减少残差模块内部的非线性函数数量,提高模型线性表征能力,形成了一种双重残差网络(D3D)[15],如图3所示。
对比反向传播梯度公式(8)和(9),改进的残差单元D3D内嵌套两个3D-Resnet残差单元可以削弱梯度消失影响,从而保证模型参数充分得到学习和训练。同理为了拓展模型的深度,在D3D单元内嵌套多个3D-Resnet残差单元,如图4所示。
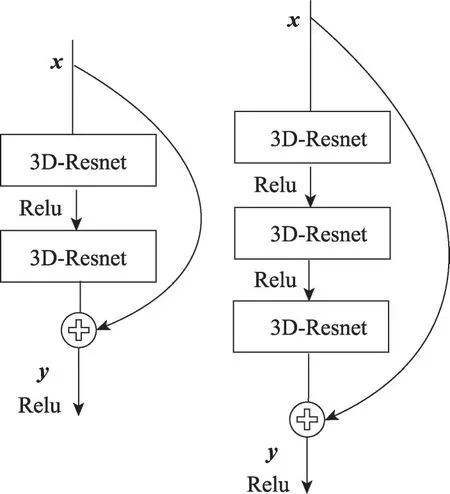
Fig.4 Improved structure of D3D unit图4 改进结构的D3D单元模块
2.3 D3D网络模型及损失函数构造
考虑到跌倒数据集视频数量较小,为了便于和3D-Resnet[15]对比,以3D-Resnet为基准模型,分别构建网络层数为18层和34层的D3D模型。D3D的网络层数、卷积核数量和大小与文献[15]里的3D-Resnet相同,但两者的内部结构连接方式不同。
构建的D3D网络模型结构如下:
(1)输入层(Input)第一个卷积层(conv1)和第一个下采样层(Max Pool)与3D-Resnet相同。
(2)4个D3D残差模块,每个D3D残差模块包含不同数量的3D-Resnet单元模块(Block)。其中每个3D-Resnet单元包含2个卷积层,大小为3×3×3,并去除了内部的非线性函数提高线性表征能力。每个3D卷积核的数量在4个模块中分别为64、128、256、512,与3D-Resnet相同。D3D残差模块在模型中用于解决梯度消失问题。
(3)第二个下采样层(Average Pool)采用3×3×3的均值池化操作进行特征融合。
(4)全连接层(FC)和Softmax,其输出维度大小为动作种类的数量。Softmax分类器接在全连接层后面,输出每个视频所属行为类别的概率。
图5给出了D3D网络模型结构,而对于18层的D3D网络结构,每个D3D模块包含2个3D-Resnet单元,即图5中n1~n4都为2。同时对模型进行深层拓展,构建34层的D3D模型,网络层数与3D-Resnet相同。对于34层的D3D模型结构,同样包含1个卷积层、4个D3D模块和1个全连接层,4个D3D模块内部分别含有3、4、6、3个3D-Resnet单元。表1给出了18层和34层D3D模型的具体参数以及输入输出大小。为了充分地提取时序特征,所有的卷积采用的时间步长为1。为了降低维度并充分提取空间特征,conv1、conv5_1、conv5_3采用降采样方法,空间步长为2,其余卷积的空间步长为1。由于网络模型各层卷积核的数量和步长参数设置不同,导致基于跨连接方式的残差结构输入与输出特征图的维度不一致而不能直接相加,采用1×1×1卷积来调整维度。

3 实验结果与分析
3.1 数据集
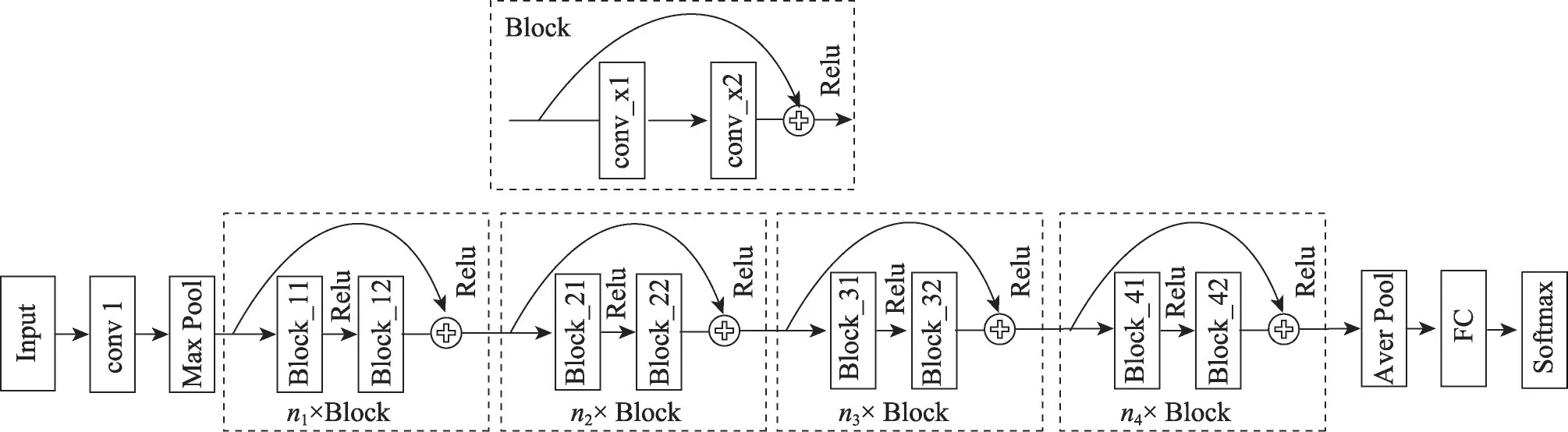
Fig.5 Double residual network structure图5 双重残差网络结构

Table 1 Parameters of D3D structure表1 D3D结构参数
MCFD[17]是由在同一房间位于不同位置和角度的8个摄像头拍摄而成,包含24个场景视频,帧率120 frame/s。每个场景包含不同的动作,如跌倒、行走、做家务和下蹲等。根据实验需求,将数据集中每个视频剪切成单一动作的视频片段,时间长度为1~3 s,其中跌倒视频持续时间为1 s左右。表2给出了剪切好的视频数量,包含8个类别,分别是背景、行走、跌倒、躺下、坐下或坐起来、下蹲或匍匐、做家务、假摔。实验时将数据集随机分成5个子集,进行5折交叉验证。
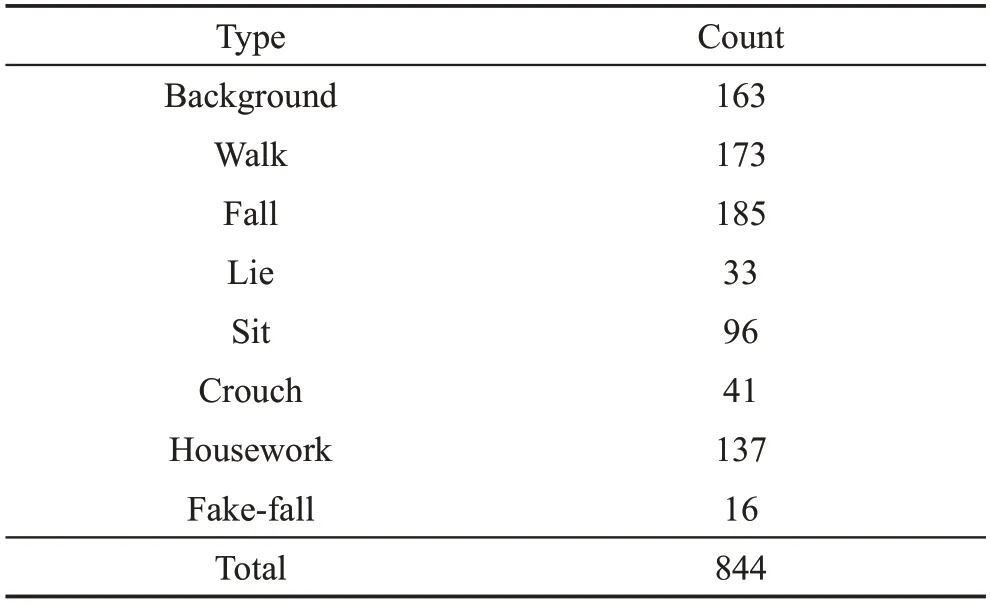
Table 2 MCFD quantity distribution表2 MCFD数量分布
URFD[18]包含70个活动(30个跌倒和40个日常动作),视频总数量为100个,帧率30 frame/s,其中跌倒视频是由两个位于不同位置和角度的摄像头拍摄得来。将视频剪切成单一行为的视频片段,持续时间1~4 s。URFD数据集的行为分为4个类别,分别是跌倒、走、坐下或躺下以及其他日常活动(弯腰、下蹲和趴着等),对应的视频数量如表3所示。

Table 3 URFD quantity distribution表3 URFD数量分布
UCF101[19]是从YouTube收集的具有101个类别的动作视频数据集,一共包含13 320个视频,每个时长2~15 s,帧率25 frame/s。该数据集大致可以分为5种动作:人与物互动、人与人的互动、肢体动作、演奏乐曲和体育运动。把UCF101数据集划分为两部分,训练集和测试集,划分比例为4∶1。此数据集在本文仅用于评估D3D模型缓解梯度消失问题的泛化能力。
3.2 实验参数设置及训练测试细节
为了便于模型训练测试,并减少连续图片帧之间的冗余信息,首先以一定的采样频率将每个视频转为图片序列。根据经验,UCF101视频每秒间隔采样5张图片,URFD视频每秒间隔采样6张图片。由于MCFD数据集的原始视频帧率为120 frame/s,因此每个视频转为图片序列时,每秒间隔采样25张图片。训练测试时,采用数据增强技术[20],把视频采样的图片按照中心剪切,将其裁剪成112×112作为网络模型的输入。模型训练时,从训练集的每个图片序列中随机选取连续的16帧图片序列作为网络模型的输入,则卷积网络模型的输入大小是16×112×112。
采用随机梯度下降算法对模型进行优化,动量参数为0.9。为了防止模型过拟合,全连接层在训练时加入dropout,并设置dropout为0.5。学习速率设为0.000 1,批量大小为8,迭代次数(epoch)为50。采用呈正态分布的随机数作为参数初始化,标准差为0.01。本文实验的软件和硬件环境为Tensorflow1.8、Ubuntu16.04和GeForce GPU1070Ti。
测试阶段如图2所示,从每个测试视频中的图片序列中重叠采样连续16帧的图片作为一个测试单元,以14帧为步长(即相邻采样重叠帧数为2,经验值)。将每个视频的所有测试单元输入到网络模型中,计算所有Softmax输出的平均值作为该视频最终的测试结果。每个视频对应一个动作类别标签,如果测试得到的视频分类结果和标签相同,则该视频被判断为正确识别。
3.3 评估指标
通常跌倒识别算法使用以下指标来进行评估:
(1)准确率(accuracy,Ac):跌倒与其他日常行为被正确分类的比例。
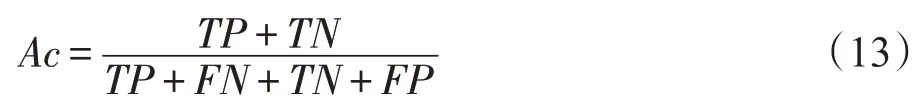
(2)灵敏度(sensitivity,Se):跌倒被正确识别出的比例。

(3)特异性(specificity,Sp):日常行为没有被识别为跌倒的比例。

其中,TP(true positive)代表被正确识别为跌倒的数量;FP(false positive)代表其他日常行为被错误地识别为跌倒的数量;TN(true negative)代表其他日常行为没有被识别为跌倒的数量;FN(false negative)代表跌倒被错误地识别为其他行为的数量。
3.4 D3D模型梯度消失问题评估
为了验证本文提出的D3D残差模型对缓解梯度消失问题的效果,本文采用D3D和3D-Resnet的18层和34层网络在数据集UCF101和MCFD进行训练。不同节点梯度值变化和模型损失函数值变化,如图6、图7所示。
由于篇幅原因,仅给出了D3D和3D-Resnet模型在卷积浅层conv2_1和深层conv5_1的梯度均值,如图6所示。从图6中可以发现,3D-Resnet的conv2_1处的梯度较小接近于0,而D3D模型增加了conv2_1的梯度,并且conv2_1和conv5_1的梯度值差距相比3D-Resnet较小,验证了公式(8)和(9)的理论分析,表明D3D缓解了梯度消失问题。从图7中可以看出,与相同层数的3D-Resnet相比,D3D结构模型的损失函数收敛速度较快,表明D3D网络模型削弱了误差反向传播时梯度消失问题,使得模型参数得到充分训练而且加快了模型损失收敛速度。
3.5 跌倒识别实验
3.5.1 跌倒识别实验结果及分析
将MCFD数据集随机分成5个子集,视频数量分别是169、169、169、169、168。把其中4个子集用于训练,剩余1个作为测试集,进行5折交叉验证(Fold1、Fold2、Fold3、Fold4、Fold5)。

Fig.6 Node gradient value curve图6 节点梯度值变化曲线

Fig.7 Iterative training curve of loss function图7 损失函数迭代训练曲线
为了充分显示D3D和3D-Resnet网络模型对跌倒识别的效果,表4、表5列出了18层的D3D和3DResnet进行5折交叉验证的结果。从表4、表5特异性、灵敏度和准确率的平均数据可以看出,D3D模型对跌倒识别的效果均超过了3D-Resnet,分别提升了0.101、0.167、0.117。说明改进后的残差网络增强了模型质量,降低了跌倒的误检率和漏检率,提高了跌倒的识别率。MCFD数据集的动作种类较多且较为复杂,本文改进的残差网络方法在MCFD数据集上得到了较大的提升,说明D3D模型解决了由于监控视角、人体姿态和场景等复杂情况下导致模型识别性能较低的问题。
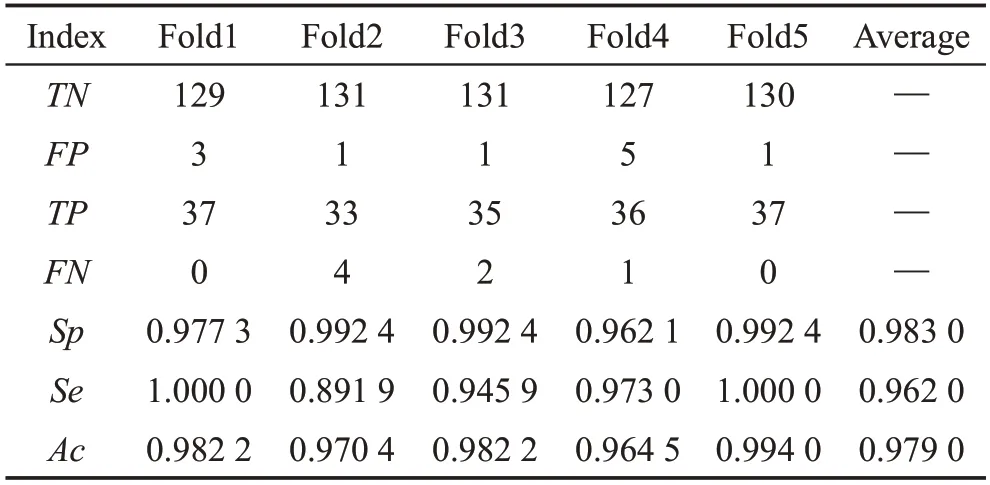
Table 4 Cross-validation results of D3D-18 on MCFD dataset表4 D3D-18在MCFD数据集上的交叉验证结果
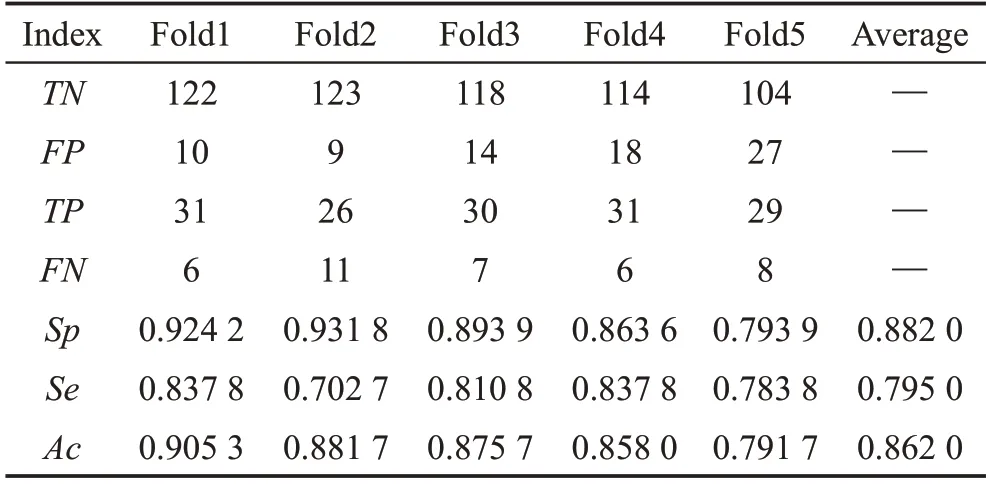
Table 5 Cross-validation results of 3D-Resnet-18 on MCFD dataset表5 3D-Resnet-18在MCFD数据集上的交叉验证结果
为了验证D3D模型对跌倒识别的泛化能力,本文在URFD跌倒数据集上进行5折交叉验证。将数据集随机分成5个子集,视频数量分别是30、30、32、29、32。把其中4个子集用于训练,剩余1个作为测试集。
从表6和表7的数据对比分析看出,相对于3DResnet模型,D3D模型在跌倒数据集上的特异性、灵敏度和准确率的均值都有较大的提升,由此说明本文提出的D3D模型在跌倒识别中具有良好的泛化性能。
3.5.2 与其他3D卷积算法对比
为了更为客观地显示本文改进的3D残差卷积网络模型的性能和在跌倒识别上的有效性,表8列出了几种3D卷积网络算法在数据集MCFD和URFD上的测试结果以及Tensorflow模型存储大小。
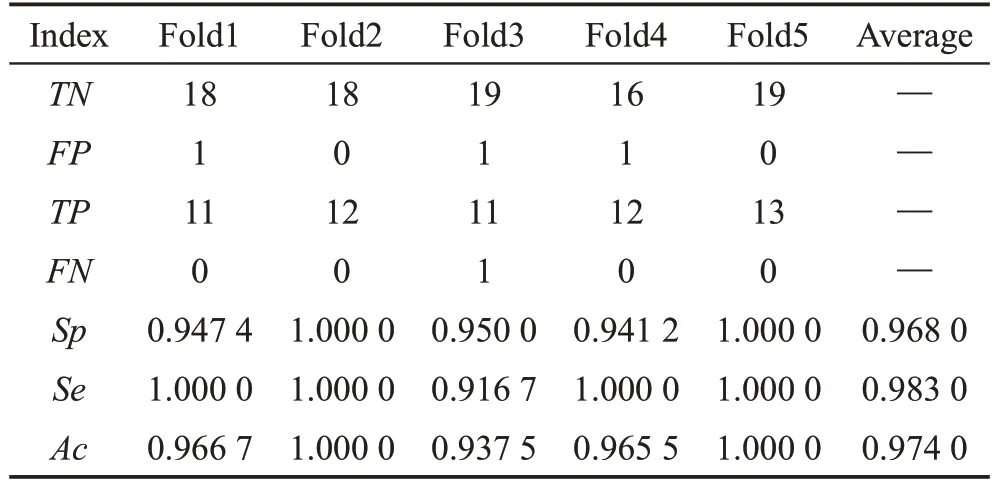
Table 6 Cross-validation results of D3D-18 on URFD dataset表6 D3D-18在URFD数据集上的交叉验证结果
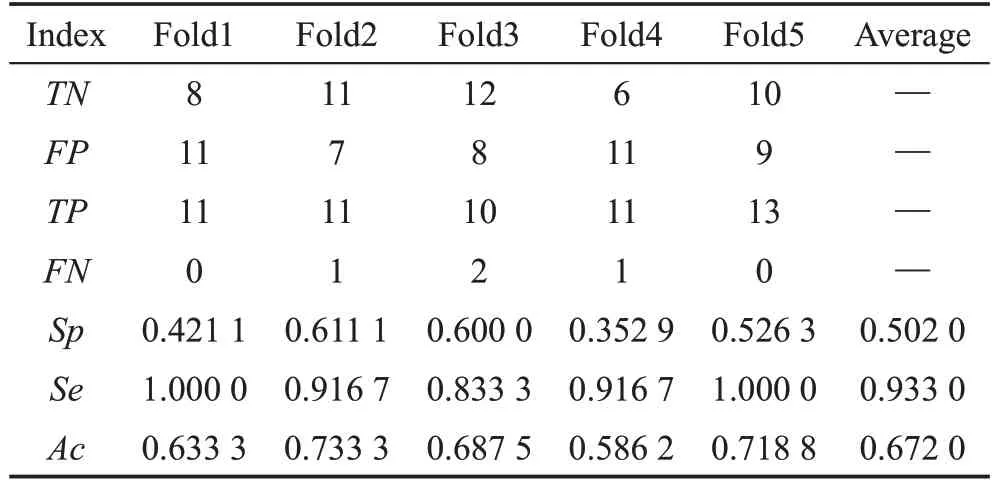
Table 7 Cross-validation results of 3D-Resnet-18 on URFD dataset表7 3D-Resnet-18在URFD数据集上的交叉验证结果
对比两个数据集的识别结果发现,18层和34层D3D模型的评估指标特异性、灵敏度和准确率结果均比3D-Resnet优越,说明改进的残差网络的性能得到了提升。同时发现如下问题:D3D和3D-Resnet的18层与34层在两个数据集上的识别效果不一致,34层结构在数据集MCFD上的指标Se、Ac效果较18层网络结构差。这是因为数据集MCFD的行为种类较多且复杂,而且模型卷积层数较深,导致深层模型的卷积参数不能较好地学习,造成过拟合,但是从3DResnet和D3D的34层相对于18层跌倒评估指标Se、Ac的增量(分别为-0.168、-0.014和-0.065、-0.007)可以看出,D3D-34的增量较大。由此可以说明D3D相对于3D-Resnet性能得到了提升,进一步降低了模型过拟合的影响,提高了跌倒识别效果。
与其他3D卷积算法C3D、P3D和R(2+1)D进行对比,本文提出的D3D网络模型在两个数据集上的识别效果较好。P3D和R(2+1)D是简化后的63和35层残差结构模型,两者都采用1×3×3的空间卷积和3×1×1的时间卷积代替3×3×3卷积,其优点是模型参数少和存储较小。与同是残差结构的P3D和R(2+1)D相比,改进后的双重残差模型D3D在两个跌倒数据集上的识别效果较好。这是因为本文在残差网络中嵌套残差网络,一方面缓解了梯度消失问题,另一方面进一步融合了浅层和深层的特征。C3D模型和本文提出的D3D模型跌倒识别效果接近,这是因为C3D卷积网络由8个卷积层和2个全连接层以及池化层构成,网络层数较低,因此受梯度消失的影响较小,使得模型参数得到较好训练。与残差网络模型相比,C3D模型参数较多,模型存储量较大。
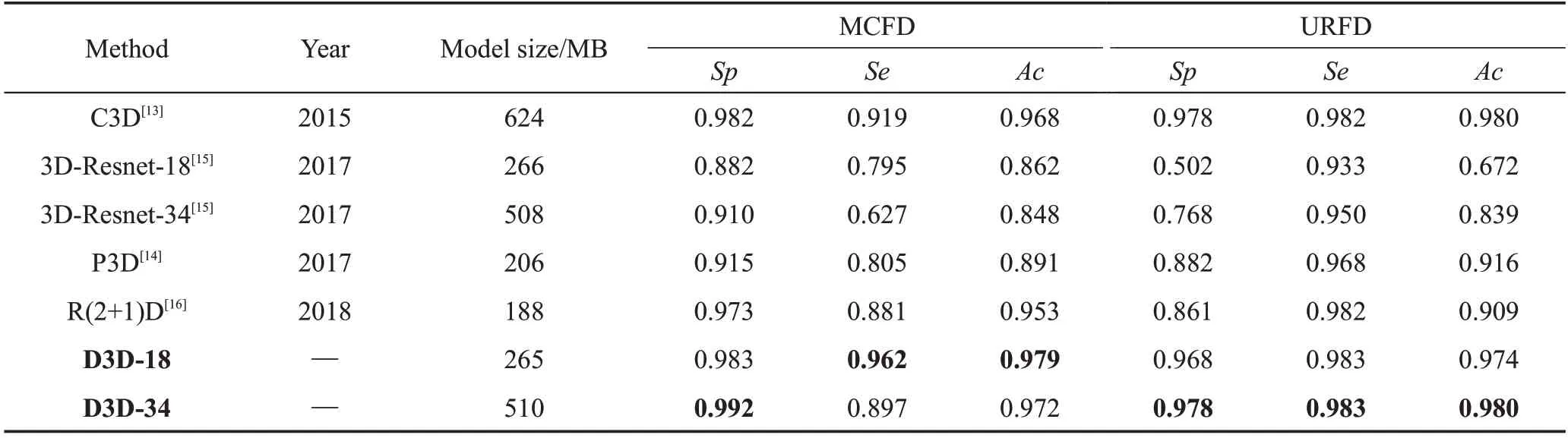
Table 8 Performance comparison of several convolution models on MCFD and URFD表8 几种卷积模型在MCFD、URFD上的性能比较
综合以上分析,本文提出的双重残差网络D3D改善了相同层数的3D-Resnet模型出现的过拟合导致跌倒识别率低的问题,同时在监控视角、人体姿态和场景等复杂的情况下D3D残差网络取得了较好的识别效果,提高了3D卷积网络在跌倒识别中的精度。
4 结束语
针对直接通过增加卷积网络层数来提取有效的视觉特征容易出现梯度消失和过拟合,从而导致行为识别率较低的问题,本文提出了一种基于双重残差网络的跌倒异常行为识别方法。通过在残差网络中嵌套残差网络,充分融合了浅层和深层视觉特征,从而能够进一步降低卷积模型训练时梯度消失和模型过拟合的影响。在UCF101和MCFD行为数据集上进行了验证,D3D模型有效地缓解了相同卷积层数的残差卷积网络模型的梯度消失问题。最后,将D3D网络模型在MCFD和URFD两个跌倒数据集上进行验证,性能优于3D-Resnet、C3D、P3D和R(2+1)D卷积算法,表明了D3D算法对跌倒识别的有效性和可行性。
本文通过分析和改进跨连接方式的残差网络来缓解模型梯度消失问题,从而提高了异常行为识别的准确率,但是仍然存在不足。因此下一步研究方向,将结合残差网络并通过加宽卷积网络融合不同多尺度的视频特征进行行为识别分析。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
数学物理学报(2021年6期)2021-12-21 06:24:38
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
应用数学(2020年2期)2020-06-24 06:02:50
自动化学报(2019年6期)2019-07-23 01:18:32
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
河南科技(2015年8期)2015-03-11 16:23:52
小说月刊(2014年5期)2014-04-19 02:36:48
吐鲁番(2014年2期)2014-02-28 16:54:44
河南科技(2014年3期)2014-02-27 14:05:45
