
基于极端梯度提升特征重要性的K-匿名特征选择
2020-09-10 06:50王旭万长胜
网络空间安全 2020年8期
王旭,万长胜
〔1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京211189〕
1 引言
随着互联网行业的迅速崛起,全球数据量呈指数级增长,数据的采集与发布越发频繁,信息数据共享更加方便。然而在大数据带来极高商业价值的同时,以共享信息和数据挖掘为目的的数据发布过程中出现的隐私泄露事件频发,例如FaceBook与数据分析公司Cam-bridge Analytica的不当共享造成8,700万用户个人信息泄露[1]等。
为了避免数据发布时的隐私泄露问题,K-匿名模型在隐私保护领域得到了广泛的应用。然而将部分数据匿名化,势必会导致数据挖掘算法性能的下降,因此本文提出了一种基于极端梯度提升特征重要性的K-匿名特征选择算法,并通过在真实数据集上的实验,验证了本文的算法无论在平衡隐私保护和数据挖掘性能方面还是在运行效率方面都优于文献[2]中基于Greedy_Ha- -mdist的特征选择算法。
2 基本概念和技术
2.1 隐私保护中的数据属性定义
数据发布或共享时最常用的数据类型为关系型数据表,数据属性一般可分为标识符、准标识符、敏感属性和非敏感属性4类。例如,表1所示某医院的就诊记录表部分数据,当将此部分数据进行共享发布时,由于涉及到病人的隐私,一般需要将信息脱敏,最简单的方法便是将姓名属性去除。但是当攻击者拥有某些患者的背景知识,通过一些属性的组合也可以推断出患者隐私,例如已知张三是一名邮编为102211的42岁女性患者,即使数据表中没有姓名这一属性,也可推测出张三患有感冒。其中,姓名即为标识符,疾病为敏感属性,而性别、年龄以及邮编属于准标识符,非敏感属性即不属于上述三类的特征。
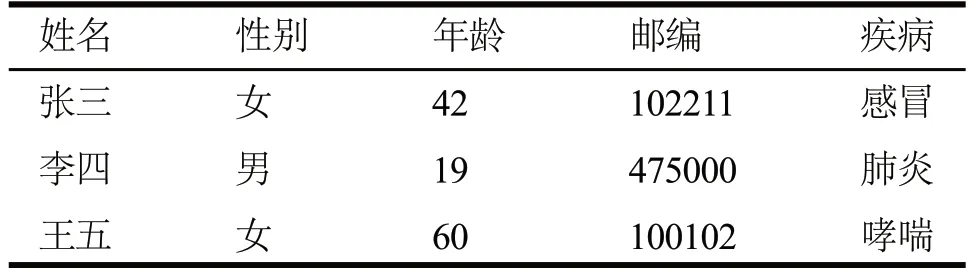
表1 就诊记录表
2.2 K-匿名特征选择
(1)K-匿名概念
K匿名模型常用于抵抗链接攻击,为了便于讨论,设待发布数据如表2所示,该数据表包含X1,...Xn共n条记录,其中Ai(i=1,2,...m)为准标识属性,AS为敏感属性。
隐私模型要求每条记录在公布的数据中与其他至少K-1条记录无法被区分开来[3]。可见,K-匿名模型要求对匿名处理后的数据表中的每条记录Xi,都应至少有K-1条记录在准标识符上的取值与Xi相同。K值越大,说明无法区分的记录越多,攻击者由准标识符推断出敏感信息的概率越低,即隐私泄露的风险越小。

表2 待发布数据表
(2)K-匿名特征选择
对于给定的K值,待发布数据表不一定可以满足K-匿名模型的要求,此时就需要对数据表中的准标识属性进行选择,使得选择出来的特征子集构成的数据表满足K-匿名模型的要求。如表3所示,Ai(i=1,2...5)为待匿名特征,假设K-匿名模型选取K为2,如果特征集为(A1,A4,A5),即表中灰色部分的数据,则该子集满足2-匿名的条件。

表3 K-匿名特征选择示例
2.3 极端梯度提升特征重要性
XGBoost (Extreme Gradient Boosting)也称作极端梯度提升,算法的基本思想是选择部分的特征和样本生成一个简单的模型(本文为决策树)作为基本分类器,通过学习前一个模型的残差并最小化目标函数来生成新模型,重复执行此过程直到满足终止条件,最终生成大量简单模型并组合为准确率较高的综合模型。其核心在于新的模型在相应损失函数梯度方向建立,修正“残差”的同时控制复杂度[4]。
(1)目标函数
XGBoost的目标函数由损失函数和正则项两部分组成,损失函数:

其中,N为样本个数,yi为第i个样本的标签,fm(xi)为第i个样本在第m次迭代中的预测值。L(θ)以LogLoss为损失函数,设其关于fm(xi)一阶导数和二阶导数可分别表示为gi和hi,则通过泰勒展开式可以将L(θ)近似表示为:
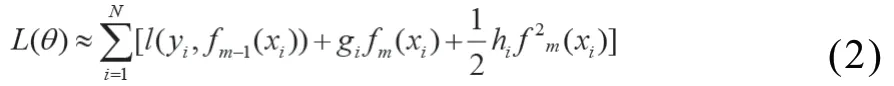
本文所用的基本模型为回归树,正则项表达式为:

其中,T为叶子节点个数,w为每个叶子节点的权值,γ与λ分别为T和w的惩罚系数,二者控制树的复杂度从而防止过拟合。经决策树被归至叶子节点Ij的样本的损失函数的一阶导数和二阶导数之和可分别表示为Gi和Hi,去除常数项部分,对其关于w求导得到使目标函数最小的最优w,将其带入目标函数,函数变为:

(2)特征重要性度量指标
重要性度量是衡量每个特征对样本进行分类时贡献程度的方法,XGBoost一般可以根据特征分裂的平均次数、特征平均覆盖率和特征的平均增益对特征重要性进行度量。由于前两者只是反映了特征在模型分裂过程中作为决定性特征出现的相对频率和次数,而平均增益直接反映了以此特征分裂后带来的准确率的提升程度,是解释特征重要性的最相关属性,因此本文主要通过特征平均增益来确定每个特征的重要性指标。
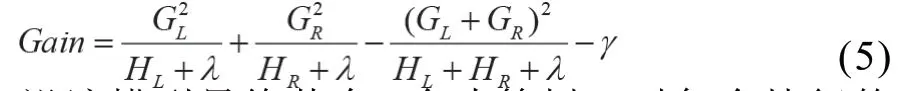
设该模型最终共有X个决策树,对每个特征的重要性度量指标计算,需要将其在每棵树(即每个基分类器)中的增益相加并取平均,即:

3 实验算法与思路
3.1 问题引入
通过特征选择的方法可以实现数据集的K-匿名从而保护数据隐私,但是从全部特征中得到最佳匿名特征子集是NP完全问题,如表3所示,其中除了(A1,A4,A5)满足2-匿名要求,(A2,A4,A5)也满足2-匿名的条件。在对不同的特征对应的子集进行数据挖掘时,其分类性能是不同的,为了使得在隐私得到保护的前提下数据挖掘分类性能较高,本文提出了利用极端梯度提升算法度量特征重要性,按照特征重要性对原始数据集特征进行排序,并采用序列前向搜索的贪心策略,进行K-匿名特征选择[5]。
3.2 实验算法
根据实验思路,通过极端梯度提升算法衡量每个特征重要性,并根据其重要性将特征降序排序,特征子集初始化为空集,并依次把分类性能最高(特征重要性指标最大)的特征加入特征子集,并判断数据在特征子集上是否符合K-匿名条件,若具有K-匿名性,则将该特征留下,否则剔除,具体算法如算法1所示。

算法1:XGB-KA(D,K)
算法第8行K-anonymity_test(D′)用来判断数据集D′是否满足K-匿名条件,即任一条记录都至少有K-1条记录在准标识特征上与其具有相同的取值(即有相同的准标识符),具体实现过程如算法2所示,其中2~9行实现了等价类的划分(每个q为一个等价类,字典中q对应的取值表示该等价类中包含多少条记录)。
4 实验流程与结果分析
4.1 数据集介绍
为了验证本文提出的XGB-KA算法可以有效地平衡数据分类挖掘性能和隐私保护程度,本次实验选取了两个UCI常用的真实数据集—Adult以及Breast-Cancer-Wisconsin数据集进行特征选择和数据挖掘,由于文献[2]中Greedy-Hamdist算法整体思路与本文类似,只是衡量特征重要性所用算法不同,因此将本文算法与Greedy-Hamdist算法在挖掘分类性能和运行效率两个方面进行对比。

算法2:K-anonymity_test(D′)
Breast-Cancer-Wisconsin数据集共699条记录,11个特征;Adult数据集共32,561条记录,14个特征,本次实验按照原数据集正负样本比例随机抽取了1,500条记录。
4.2 实验流程
本次实验首先对数据集进行预处理,然后利用极端梯度提升特征重要性进行K-匿名特征选择,最后通过SVM模型对匿名后的子数据集进行分类。算法性能采用Precision和Recall两个指标进行测评,算法效率则通过运行时间进行对比分析。
本次实验环境为:Intel(R) Core(TM)i5-5200U CPU @2.20GHZ 2.20GHZ;4.00GB(RAM)内存;Windows 10 64位操作系统。算法均通过Python3.7.5实现。
4.3 数据分类挖掘性能分析
在不同的K值下,对本文提出的XGB-KA算法和文献[2]提出的Greedy-Hamdist算法在两个数据集上分别进行分类实验,得到的结果如图1-图4所示。当K=0时,数据集隐私完全没有受到隐私保护,随着K值的增大,隐私保护程度越来越高,但由于只保留较重要的特征,分类性能在可接受的范围内有所下降。除此之外,无论K值为多少,本文提出的XGB-KA算法性能都优于Greedy-Hamdist算法,可见在同等隐私保护程度的前提下,XGB-KA的分类性能优于Greedy-Hamdist算法。
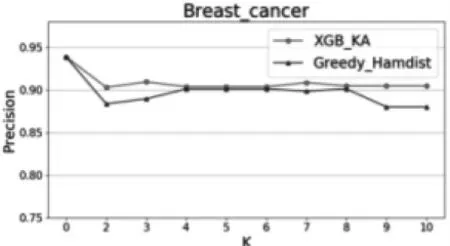
图1 两种算法在不同K值下的Precision1
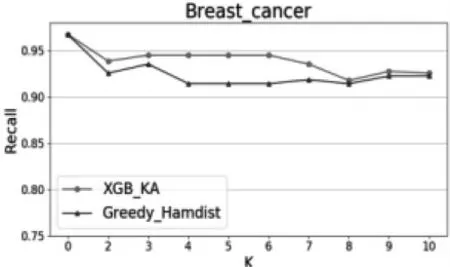
图2 两种算法在不同K值下的Recall1
4.4 算法效率分析
通过统计不同K之下两个算法运行的时间来比较其效率,实验结果如图5和图6所示,由于不同的K值下需要剔除的特征数量不同,两种算法在不同K值的运行时间均有一定的波动,但本文提出的XGB-KA算法运行时间均短于Greedy-Hamdist算法,这表明XGB-KA算法运行效率更优。
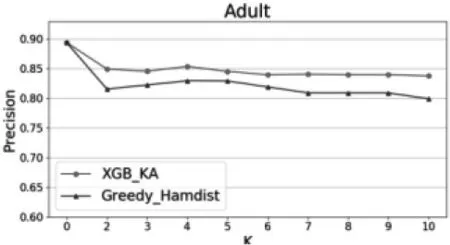
图3 两种算法在不同K值下的Precision2

图4 两种算法在不同K值下的Recall2
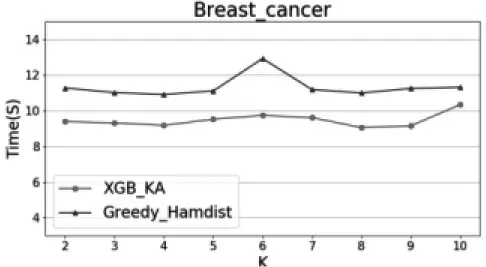
图5 两种算法在不同K值下的运行效率1

图6 两种算法在不同K值下的运行效率2
5 结束语
本文利用极端梯度提升特征重要性衡量特征对分类结果的贡献度,并结合K-匿名条件对数据集进行特征选择,使得经过选择后的特征子集在原始数据集上投影得到的子数据集在得到隐私保护的同时保持了较好的分类性能。实验结果证明,无论在分类性能还是在实现效率上,本文提出的XGB-KA算法都优于文献[2]中的Greedy-Hamdist算法。
未来可以考虑将特征选择方法与其他隐私保护模型相结合或者利用其它更加高效的特征重要性度量方法,更好地实现隐私保护程度和数据挖掘性能之间的平衡。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
电子技术与软件工程(2016年24期)2017-02-23
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
哈尔滨理工大学学报(2016年2期)2016-09-12
电脑知识与技术(2016年15期)2016-07-04
