
基于随机森林和深度自编码高斯混合模型的无监督入侵检测方法
2020-09-10 06:50胡宁方兰婷秦中元
网络空间安全 2020年8期
胡宁,方兰婷,3,秦中元
〔1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京211189;3.网络通信与安全紫金山实验室,江苏南京 211111〕
1 引言
近年来,网络安全问题更加突出,网络上新的攻击手段层出不穷,这些攻击手段比先前的攻击手段更加隐蔽、更加智能、更难以发现。入侵检测被视为信息安全的“第一道防线”因机器学习技术迅速发展面临更大的威胁。许多研究人员使用机器学习算法进行入侵检测,获得了较好的结果。
有监督学习方式的网络异常检测,可以很好的识别攻击行为。然而,其具有两个弊端。第一,有监督学习过于依赖标签,需要在大量的有标记数据的基础上进行,即需要大量的人工操作和资金投入。第二,有监督学习只能学习已有的攻击类型,对于新的攻击手段,有监督方式无法检测[1]。入侵检测研究需要大量数据,随着时间推进,数据量增长速度快,无法及时给新增数据打上正确标签。有监督学习依赖标签,而无监督方法可以凭借没有标签的数据学习正常数据特征,并根据数据特性获得划分异常的方法。因此,无监督方法具有很好的应用前景。
针对上述问题,Bo Zong[2]提出深度自编码高斯混合模型DAGMM进行无监督网络异常检测。然而,该方法训练集为异常数据,真实网络环境理应通过训练正常数据学习数据特征,异常数据计算后将偏离正常数据。一方面获取用于异常检测的阈值;另一方面,模型训练过程只需要正常数据,无需学习已有攻击,对新的攻击手段具有一定检测能力。此外,真实网络环境中数据维度高、数据量大,本文提出了一种基于随机森林和深度自编码高斯混合模型的无监督入侵检测方法RF-DAGMM。首先,通过随机森林算法进行特征选择,选择最优特征组合。然后将随机森林特征选择方法与深度自编码高斯混合模型结合,进行网络异常检测。
本文具体贡献有三点:
(1)将异常检测方法应用于网络入侵检测,训练集只需要正常数据,解决了人工标记困难、无法检测新型攻击的问题;
(2)针对数据维数过高、无关特征对检测结果产生干扰的问题,提出了一种基于随机森林的特征重要度特征选择方法;
(3)将随机森林特征选择方法与深度自编码高斯混合模型结合RF-DAGMM,将对结果重要的特征输入DAGMM模型,用于网络异常检测。提出的RF-DAGMM模型可以缩短训练时长,并且在精确率、召回率、F1值多个指标获得优于DAGMM的结果。
2 相关工作
网络攻击可以引发网络流量特征的显著变化,由此,Moustafa[3]等和Khammassi[4]等提出了基于统计或行为特征的流量异常检测方法,但存在两个问题:一是需要人工设计准确反映流量特性的特征集;二是攻击者利用对抗机器学习思想针对性改变攻击流量特征来消除数据分组的时空分布特性,就可以逃避防火墙和安全软件的检测。
有监督学习只能针对常见、危害性较大的攻击方法学习,无法学到网络中所有攻击手段。而无监督学习可以从无标签数据中总结规律。现有的无监督异常检测方法可以分为三种:基于重构的方法、One-Class分类、聚类分析。基于重构的方法主要基于正常数据经压缩重建后的重构误差不同,但是大量异常样本可能以正常水平潜伏;One-Class方法在数据维数增加时会受到次优性能的困扰;聚类分析很难直接用于多维数据。
本文将DAGMM模型应用于网络入侵检测,使用正常数据作为训练集,并在该方法基础上针对数据维数过高、无关特征对结果产生干扰问题进行改进,提出了一种基于随机森林和深度自编码高斯混合模型的无监督入侵检测方法RFDAGMM,该方法注重对结果重要的特征,消除无关特征对检测结果的影响。基于多个数据集的实验结果表明,该方法检测结果优于DAGMM,同时减少训练时长和计算成本。
3 RF-DAGMM方法
RF-DAGMM模型由三部分组成:特征选择网络、深度自编码网络和高斯混合模型。该模型原理如图1,特征选择网络选择对结果重要的最优特征组合,进行冗余特征的删除;深度自编码网络将数据的重构误差及压缩编码作为数据的低维表示;高斯混合模型通过训练输出样本能量用于异常判别。
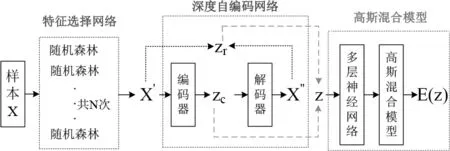
图1 RF-DAGMM模型图
3.1 特征选择网络
分类高维数据时特征空间大,数据容易过拟合,特征选择可以减少数据维度,降低分类器复杂度,使之更关注提供重要信息的特征。特征选择网络通过随机森林(Random Forest,RF)算法选择对结果重要的最优特征组合。一方面消除无关特征对结果的干扰,另一方面节省模型训练时长和计算成本。
因此,本文提出一种特征选择网络,以特征重要度为标准,选择对结果重要的最优特征组合。由于随机森林算法具有随机性,进行S次特征选择,每次选择M个特征,并取S次特征选择的交集作为最终集合。
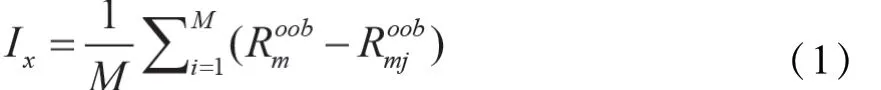

3.2 深度自编码网络
深度自编码网络完成数据的降维操作,得到高维数据的低维表示,其输出包含两部分:通过编码器学习到的数据的压缩表示、深度自编码器的重构误差。
3.3 高斯混合模型

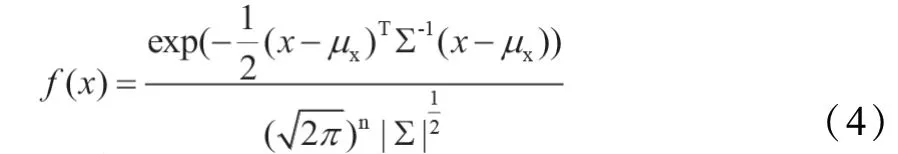
训练过程:给定N个样本,该模型损失函数为:
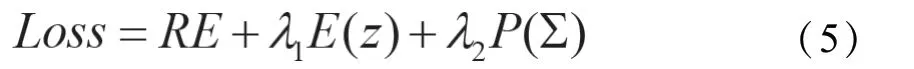
判别方法:异常检测的判别阈值T根据数据的样本能量及异常数据比例c决定。具体而言,对N条数据通过RF-DAGMM模型求取样本能量,并对所有数据的样本能量值升序排列,阈值T的取值为所有样本能量中第(1-c)N处的样本能量值。在异常检测中,将样本能量大于阈值T的样本判断为异常,反之为正常。
4 实验分析
本节基于KDD99数据集、UNSW-NB15数据集、CICIDS2017数据集进行实验,并介绍预处理过程及实验结果的对比与分析。
4.1 数据预处理
(1)删除无关信息
由于原始数据集包含网络中源主机和目标主机的IP地址、端口号、时间戳,删除这些信息以提供无偏检测非常重要,使用这些信息可能会导致对信息的过度训练[6]。
(2)数据集重组
在网络安全中,旨在通过训练正常数据,实现异常数据的检测,即希望异常数据占比较小,KDD99数据集中攻击数据占比较高,不符合无监督入侵检测的要求,因此对其进行数据重组,数据信息如表1所示。
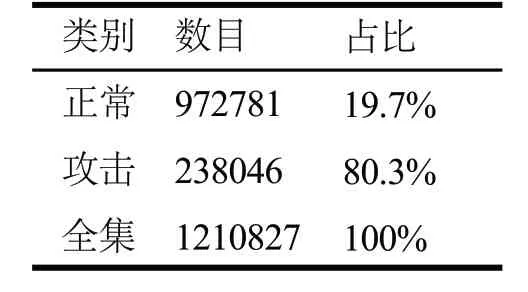
表1 KDD99重组数据
(3)符号特征one-hot编码
由于深度自动编码器的输入应为数字,而数据集中个别特征为符号特征,因此需要对符号特征进行编码处理。同时,因特征取值之间为并列关系,并无前后关联关系,因此对符号特征进行one-hot编码。由于数据进行重组后,攻击数据减少,one-hot编码过程中可能出现所有数据在某个特征下的取值均相同,因此删除冗余特征。
对于KDD99数据集,符号特征为service、flag、protocol_type,one-hot编码后总特征维数为119(包含标签)。对于UNSW-NB15数据集,符号特征为proto、service、state,进行onehot编码后总特征数为197(包含标签)。对于CICIDS2017数据集,去除无关信息后只有数字特征,因此不需要one-hot编码。
(4)数字特征归一化处理
为了消除指标之间的量纲影响,解决数据指标之间的可比性,在数据预处理阶段对数据进行标准化处理,处理后各个特征指标将处于同一数量级。因此,标准化处理后的数据比较适合综合对比评价。其中,最典型的标准化处理方式就是数据的归一化处理。对数据中剩余特征向量进行归一化处理,采用最大最小归一化方法,其公式为:
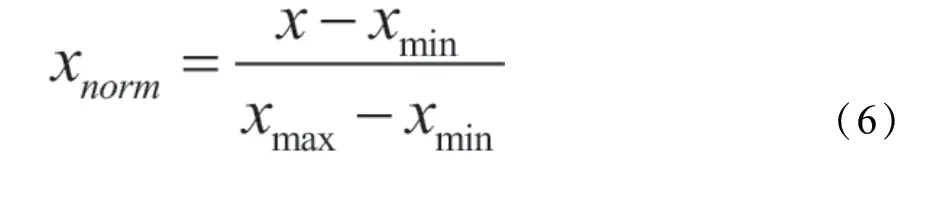
4.2 RF-DAGMM实验对比
本节分别基于KDD99、UNSW-NB15、CICIDS2017数据集进行实验,三个数据集的实验中深度自编码网络中的编码器结构为每层节点数分别为90-45-20-10-1、102-50-25-10-1、46-23-10-1的全连接层,解码器结构与编码器对称,网络中的激活函数为tanh。
基于上述实验分别进行20次测试,并取平均值作为结果,同时选择DAE、DSEBM-r、DSEBM-e[7]方法作为对比实验。DAE为深度自动编码器,使用重构误差作为异常检测标准;DSEBM-e是基于深度结构化能量模型,利用样本能量作为检测异常的标准;DSEBM-r与DSEBM-e共享同样的技术,以重构误差作为异常检测,具体实验结果如表2所示(最佳结果已加粗)。
表2中结果表明,在基于KDD99、UNSWNB15、CICIDS2017三个数据集的实验中,RFDAGMM在准确率、精确率、召回率、F1值多个指标上,均取得优于DAGMM的结果,并且RFDAGMM训练时长更短。
在与其他模型的实验结果对比中,基于KDD99数据集的实验中,RF-DAGMM模型在召回率、F1值上取得最优结果,准确率为次优结果。基于UNSW-NB15数据集的实验,RFDAGMM在准确率、召回率、F1值上均取得最优结果,精确率为次优结果。基于CICIDS2017数据集的实验中,RF-DAGMM在多个指标上均取得最优结果。综上,考虑多个指标,RF-DAGMM为上述模型中的最优方案。
5 结束语
本文提出一种基于随机森林和深度自编码高斯混合模型的无监督入侵检测方法RF-DAGMM。该模型主要有三部分组成:特征选择网络、深度自编码网络、高斯混合模型。特征选择网络利用随机森林方法实现维数约简,更加注重对实验结果较为重要的特征,消除无关特征对检测结果的干扰,对实验结果的提升、训练时长的减少起到了关键性作用。基于KDD99、UNSWNB15、CICIDS2017数据集的实验结果表明,RFDAGMM模型多个指标上的结果均优于DAGMM模型,同时节省了训练时长。与其他方法相比,RF-DAGMM亦为其中最优方案,为多维数据无监督网络入侵检测提供了新的研究方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中国典型病例大全(2022年7期)2022-04-22
小学生学习指导(中年级)(2021年12期)2021-12-30
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
电影新作(2014年2期)2014-02-27
