
融合空间注意力机制的行车障碍预测网络
2020-09-05 12:04雷俊锋肖进胜
光学精密工程 2020年8期
雷俊锋,贺 睿,肖进胜
(武汉大学 电子信息学院,湖北 武汉 430072)
1 引 言
先进辅助驾驶系统(Automatic Data Acquisition System,ADAS)是智能交通领域内的研究热点。ADAS实时收集和处理车内外环境数据并做出反馈,从而让驾驶者迅速察觉可能发生的危险。前碰撞预警系统(Forward Collision Warning System,FCWS)是ADAS系统的一部分,通过车前传感器感知环境并获得障碍信息,在碰撞前发出紧急碰撞警告。早期的机器视觉研究者通常采用目标检测的方法,定位图像中的常见障碍物[1-2]; YOLO(You Only Look Once),RCNN(Regions with Convolutional Neural Notworks)等[3-4]目标检测网络的出现,在车辆和行人目标的检测上有较好的效果[5],但对于树木、墙壁等不常见障碍物的检测效果不好;由于全卷积网络的出现[6-7],也有研究者采用语义分割的方法进行自动驾驶场景的识别[8],但是硬件开销大且预测速度慢,无法达成实时检测的任务。
伴随着从AlexNet[9]到EfficientNet[10]的目标分类网络的发展,部分研究人员提出将障碍预测从检测车辆、行人等具体目标,转变为直接预测前方障碍的概率。基于该思想,Giusti等[11]提出使用神经网络将输入图分为可继续行驶类与不可行驶类;Richter[12]研究了DNN在障碍预测中的场景不确定性问题。这些研究使得障碍预测不再局限于车和人目标的检测,对大部分障碍物都有一定的预测能力,但预测准确性不佳,不能确定障碍物方位,缺乏对行车控制的研究,仍不能满足行车避障需求。针对以上不足,本文提出一种融合空间注意力机制的卷积神经网络Coll-Net(意Collision Network),与现有算法相比,Coll-Net在满足实时运行的前提下较大提升了障碍预测算法的准确性,并对护栏、树丛等障碍均具有预测能力;同时,提出了基于Coll-Net的行车策略,辅助系统进行障碍方位的判定以及车速控制,以满足智能驾驶中的避障需求。
2 基于驾驶员视觉信息的障碍预测
行车时驾驶员判断前方障碍的重点是障碍的视觉特征而非障碍物与行车的绝对距离,比如针对出现在前方路面的电动车,驾驶员首先根据视觉中电动车较远判断不会发生碰撞,然后根据电动车由远及近的视觉信息判断可能与电动车发生碰撞,如图1所示。据此,本文将行车视野图划分为不发生障碍碰撞与可能碰撞两类,并设计Coll-Net网络对前方出现障碍的概率进行预测。

图1 行车视野Fig.1 Driving visual field
本文构建Coll-Net行车障碍预测系统如图2,其工作原理是:单目摄像头捕捉前方视野图像,这些图像经预处理[13]后送入Coll-Net,经池化下采样处理以及残差网络骨架提取空间特征后,由重标定网络进行通道特征加权以挑选出重要特征并生成空间特征图,这些图最后由全连接层处理并归一化为障碍概率。Coll-Net的预测值供处理器做出行车决策,系统将根据障碍概率进行车速控制,并结合图像中多窗口的预测值进行障碍方向判定。
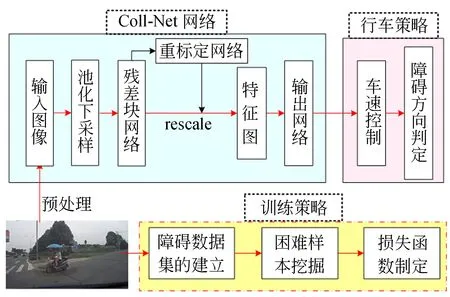
图2 Coll-Net行车障碍预测系统构成Fig.2 Framework of Coll-Net obstacle prediction system
3 障碍预测网络设计
3.1 Coll-Net网络设计
3.1.1 整体网络框架
Coll-Net是由残差网络骨架Residual Network[14]根据空间注意力机制改良而得到的卷积神经网络,如图3所示,系统工作时,采集图像首先预处理成200×200的单通道图像,然后输入到含有32个尺寸为5×5的卷积核且步长为2的卷积层,再采用尺寸为3×3且步长为2的最大池化层对其进行下采样而生成32张尺寸为50×50的特征图,然后在同一批次图像中完成特征图的批标准化(BN)和非线性化(PReLU)操作。采样层输出的特征图尺寸为:
Lout=(Lin-Wkernel)/Sstride+2,
(1)
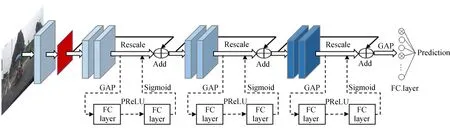
图3 Coll-Net深度神经网络结构Fig.3 Coll-Net deep neural network structure
其中:Lin,Lout表示输入与输出图尺寸,Sstride,Wkernel表示步长与核尺寸;然后,特征图依次经过3个结构相同但通道数和步长不同的改良残差卷积块,得到空间注意力机制挑选后的关键特征;最后,采用全局平均池化方法(Global Average Pooling, GAP)和全连接层进行处理后,使用Sigmoid函数输出归一化的障碍预测概率。表1给出了Coll-Net行车障碍预测网络结构涉及的操作,表中Rescale表示是否使用通道注意力机制进行重标定,Add表示与上个卷积块的输出进行连接,S表示步长,FC表示全连接层处理。
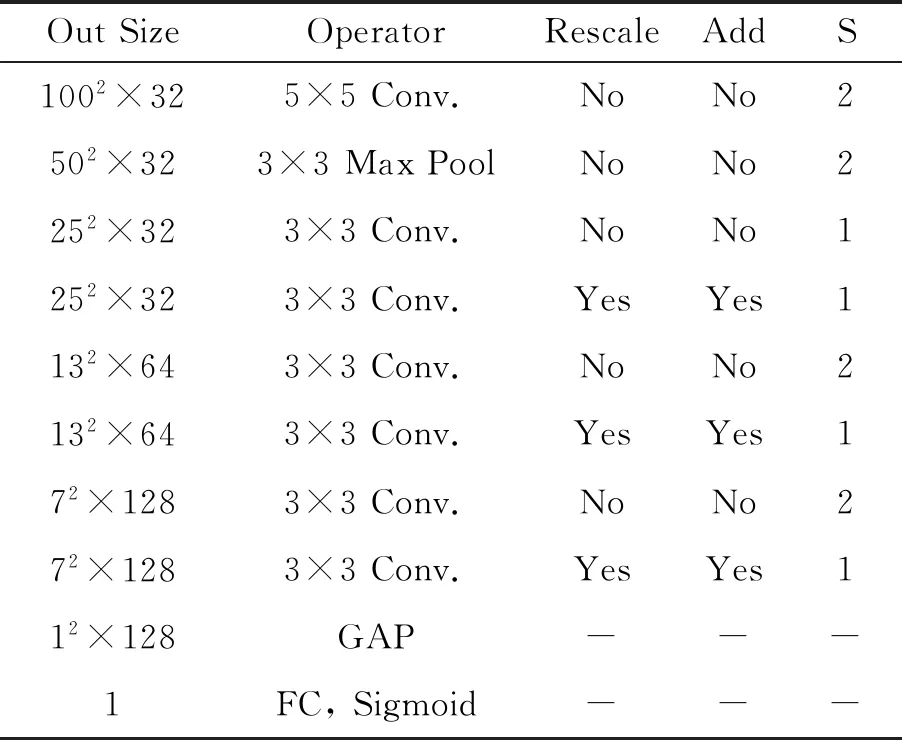
表1 Coll-Net结构与输出
3.1.2 残差网络骨架
残差块是残差网络骨架的基本组成单元而卷积层是残差块的处理单元。图4(a)为残差块的运算过程,即输入量x依次通过两个卷积层变换为F(x)后,再与F(x)做求和计算,得到结果则输入到下一残差块进行处理。残差层卷积块的输入输出关系为:
F(x)=W2⊗[σ(W1⊗x+b1)]+b2
y=σ[F(x)+x],
(2)

图4 残差块和卷积层的逻辑构成Fig.4 Structure of residual block and conv. layer
其中:W1,b1,W2,b2分别表示Conv. layer 1层和Conv. layer 2层的权重和偏移量;σ(.)表示批标准化与非线性激活操作;⊗表示卷积操作;y表示输出。图4(b)为卷积层涉及的运算,即它先对输入x做卷积操作以提取局部特征图;然后针对同批次中各输入图对应的特征图进行批标准化处理BN[15],并把各神经元输入的分布拉回均值为0方差为1的标准正态分布,使后续激活函数的输入值落到函数敏感区域;最后利用激活函数对卷积层输出进行非线性化以提高网络的非线性处理能力。Coll-Net的卷积层使用PReLU函数进行非线性激活,这样便能在不增加网络计算开销和过拟合风险情况下,较好地解决ReLU函数带来的神经元死亡问题,并有利于提升小网络的表达能力。BN和PReLU的输入输出关系如式(3),式(4):
(3)
(4)

3.1.3 空间特征重标定网络
针对行车安全系统障碍预测精度要求高的特点,Coll-Net引入空间注意力机制对残差块进行改造,如图5所示。改进之处在于:采用注意力机制对第二个卷积层的结果进行通道加权,并且权重由空间特征重标定模块(Rescale Module)获得。加权后的空间特征按下式计算:
y′=Padding(Scale)⊙y,
(5)
其中:yJ,y′为加权前、后的特征图,Padding(Scale)表示填充后的加权值;算子⊙表示Hadamard乘积。

图5 改良残差块结构Fig.5 Structure of improved residual block
考虑到各特征图对预测结果的贡献度不同,改良残差块采用特征重标定模块获取每个特征通道的权值Scale,以衡量对应通道特征的重要程度,如图6。可通过训练的方式来学习Scale,即先令经卷积层处理后得到的通道数为C的特征图y,经过全局平均池化处理而使输出Y具有全局感受野;然后将其送入有C/n个神经元的全连接层(FC1);再令其经过PReLU以提升重标定网络的非线性表达能力,进而与具有C个神经元的全连接层(FC2)相连;最后通过Sigmoid函数获得归一化的加权值Scale。

图6 重标定模块结构Fig.6 Structure of rescale module
重标定模块的计算公式为:
Scale=Sig{ω2·PRe[(ω1Y+ε1)]+ε2},
(6)
其中y,Y,Scale分别表示输入的空间特征图、全局池化输出和重标定获得的加权值;W,H表示空间特征图的宽和高;Ci表示第i个通道;ω1,ω2,ε1,ε2分别表示FC1和FC2层的权重及偏移量;Pre(.),Sig(.)表示PReLU和Sigmoid函数,并且Sigmoid函数的数学表达式为:
Sig(α)=1/[1+exp(-α)].
(7)
重标定模块采用两个全连接层,旨在更好地拟合各通道间相互关系。为了降低计算复杂度,将FC1层的通道数从原空间特征图的C降至C/n, FC2层的通道数继续保持为C。改良残差块的输出为:
Add=x+y′.
(8)
3.1.4 输出网络
先将第3个改良残差块提取的128张特征图进行全局平均池化处理,然后将其送入全连接层以拟合特征图与预测值的线性关系,最后采用Sigmoid生成归一化的障碍预测值。输出网络采用全局池化与全连接层组合构式,这样既可减少特征图直接连接全连接层时产生的大量模型参数,又可降低全连接层过拟合的危险。
3.2 训练策略
3.2.1 障碍数据集
本文结合行车实际,依据驾驶员视觉内障碍物由远及近的变化以及应用场景中可能出现汽车、自行车、行人、电线杆、护栏、墙壁等障碍物,构建适用于Coll-Net网络的数据集。该数据集基于UZH开放数据集Driving Event Camera Datasets(DECA)[16-17]。本文从中挑选由远及近的障碍物图片(尺寸640×480),并将其中可能发生车辆碰撞的图片标记为1,无碰撞可能的图片标记0,在此基础上按比例对训练集、测试集和验证集进行划分。Coll-Net要求输入200×200的单通道图,故须对数据集做预处理。为此将数据图片二值化并从中心向四周截取尺寸为480×480的图块,再将其缩小为200×200标准图片,作为最终实验用数据。
3.2.2 损失函数
Coll-Net的输出经Sigmoid函数处理后取值处于[0,1]之内,该输出视作输入图被判定为正类(有障碍)的概率,因此训练中以二分类交叉熵函数作为基本损失函数。该函数数学形式如式(9):
BCEk=-log[p(Pk|Παk)]=
(9)
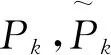
(10)
其中μ表示正样本的权重。
3.2.3 困难样本挖掘
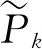
(11)
式中γ为困难样本权重调节因子,当加大γ时样本损失权重将降低。网络训练损失函数最终为:
(12)
式中N表示样本总数。
4 基于障碍预测的行车策略
4.1 车速控制策略
基于Coll-Net输出的行车障碍概率,本文提出一种车速控制方法,即当Coll-Net对输入的车前图像做出概率预测后,处理器便开始基于预测概率p进行驾驶分析:当p=0时,因无发生碰撞的可能故可保持正常行车速度;但当p=1时,因会发生碰撞故应将车速降至0。循此思路,本文构建出基于碰撞概率的实时控制车速模型如式(13)所示:
Vk+1=(1-pk)[(1-ρ)Vk+ρVnorm],
(13)
其中:Vk,Vk+1为k,k+1时刻行车速度;Vnorm为正常行车速度;ρ∈(0,1)表示增速控制系数,当ρ较大时车速增长较快,反之则车速增加较慢;pk为k时刻预测碰撞概率,当碰撞概率较小时,系统以(1-pk)(Vnorm-Vk)速度提速直至正常行车速度;当碰撞概率较大时则令系统逐渐减速至0。此法不仅为行车避障提供参考速度,而且为推进Coll-Net在无人车和自动驾驶上的应用提供一定的支撑。
4.2 障碍方向判定
为提升行车系统的避障能力,提出基于多窗口Coll-Net预测的障碍方向判定策略,以控制行车方向。该策略的思路是:先将摄像头捕获的图像尺寸缩小为640×480,并在图像上方截取尺寸为640×400的感兴趣区域;然后在该区域的左、中、右三个区域分别截取尺寸400×400的窗口;再将三个窗口图像转变为尺寸200×200的灰度图,并将其输入到Coll-Net中进行障碍预测。值得一提的是,每个窗口的预测值pred均表征对应车前方向出现障碍的概率,并且当pred≥0.5时可判定该方向出现障碍物。图7给出了多窗口Coll-Net预测障碍方向的流程。

图7 障碍物方向定位流程Fig.7 Process of obstacle direction localization
5 实验结果分析
5.1 实验准备
5.1.1 实验数据与平台
本文基于DECD构造网络训练集(含28 806张训练图和1 590张验证图)而对Coll-Net进行训练;使用基于DECD构建的测试集(含1 576张测试图)对Coll-Net的障碍预测能力进行评估;而且将实验结果与同等训练条件下采用VGG-16[18],ResNet,EfficientNet-B0,InceptionV3[19]等大型深度学习网络及谷歌专门针对嵌入式设备设计的目标检测网络MobileNetV3[20-21]得到的结果做对比。特别是为了验证Coll-Net的障碍预测及其行车策略的有效性,文中还在Udacity开放的Self-Driving无人驾驶数据集中选取具有代表性的行车场景进行模拟实验。全部输入图片均采用与训练数据预处理相同的前处理方式。训练及测试代码均运行于Linux系统并使用Intel(R) Xeon (R) W-2133 @ 3.60 GHz六核CPU,至于Coll-Net网络的搭建则使用以Tensorflow作为后端的Keras框架且使用opencv进行图像预处理,且使用python作为编程语言。训练时使用Nvidia RTX2080Ti进行计算加速,考虑到嵌入式设备的计算能力,故测试中只使用CPU单核进行模型评估。
5.1.2 训练过程
当对Coll-Net模型进行训练时,使用了Adam优化器并将学习率设为0.000 1,将批样本数设定为64,正样本权重μ设为0.75,训练迭代轮数epoch设定为50次。为增强预测模型的泛化能力,训练时在输出网络的全连接层设置Dropout为0.4。图8给出了训练集损失值train_loss、准确率train_acc以及验证集的损失值val_loss、准确率val_acc的变化。图中可见,当γ=0时损失函数退化为交叉熵函数;针对训练集,当增大γ时训练集的模型损失值在较低轮次上得到收敛,并当γ=2时预测模型不仅有较快的收敛速度而且还能保证很高的准确性;针对验证集,当γ=2时模型损失值和准确性具有理想的稳定性。故本文将困难样本权重调节因子γ设定为2。
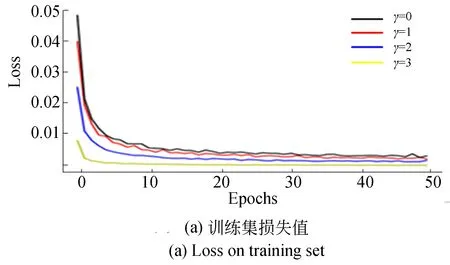

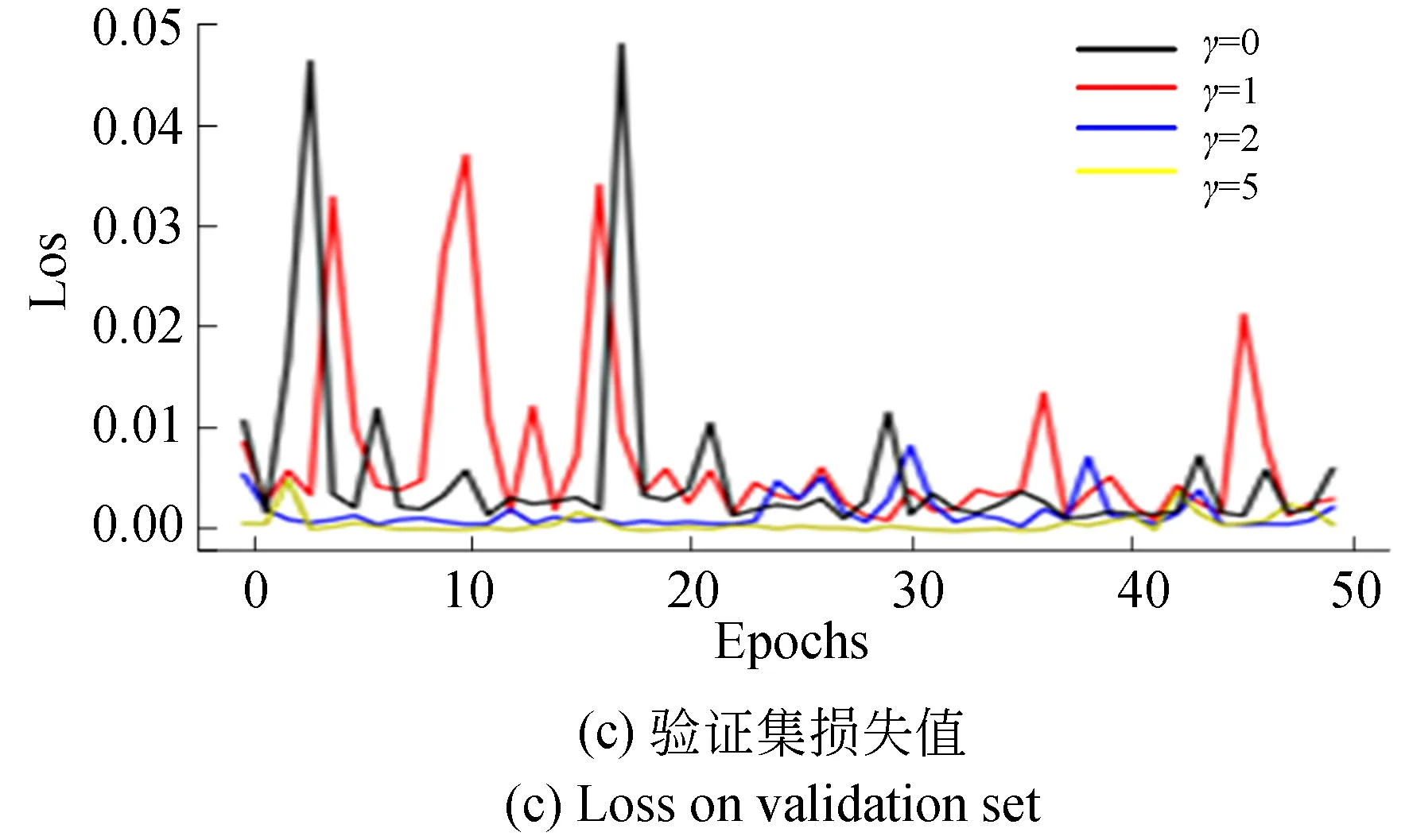

图8 训练过程中的损失率与准确率Fig.8 Loss and accuracy on training process
5.2 Coll-Net模型测试与分析
为了全面客观地评估根据本文方法训练的Coll-Net模型的障碍预测性能,本文测试了不同网络模型在测试集上的准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-score、模型参数量(Parameters)、浮点运算次数(FLOPs)和计算耗时(Latency)的性能指标,计算式分别为:
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
(14)
其中:TP,TN分别表示预测正确的正样本和负样本数,FP,FN表示预测为正而实际为负的样本及预测为负而实际为正的样本。测试中将Coll-Net输出概率prediction≥0.5的样本记为预测正样本,其他的记为预测负样本。表2列出了所得到的Coll-Net性能指标。

表2 模型测试指标和运算性能
Coll-Net在障碍预测准确率和F1-score两个指标上的表现稍逊于VGG-16(-0.63%,-0.07)和MobileNetV3-Large(-0.38%,-0.02),但它对处理器运算能力的要求(参数量和浮点运算数)远低于VGG-16和MobileNetV3-Large,特别是Coll-Net的24 ms预测耗时完全达到了实时处理要求,足以适配车载嵌入式处理器计算性能。图9是Coll-Net在测试集上的预测结果混淆矩阵,图中的Predicion和True分别表示预测值与真实值,Pos,Neg表示正、负并分别代表有碰撞可能和无碰撞可能。
图9可见,系统对测试集中341个正样本和1 172个负样本进行了正确预测,但将12张正样本误判为负(占正样本数的3.4%)并将51张负样本误判为正样本(占负样本数的4.2%)。该结果表明Coll-Net在障碍预测中倾向于危险判定。
此外,本文采用受试者操作特性曲线(Receiver Operating Characteristic Curve, ROC)及其对应面积(Area under the curve, AUC)作为衡量指标来对比Coll-Net与前文所述Giusti,Richter等研究者提出的障碍预测方法,如图10所示,Coll-Net相比类似算法在ROC和AUC指标上取得了更好的效果。
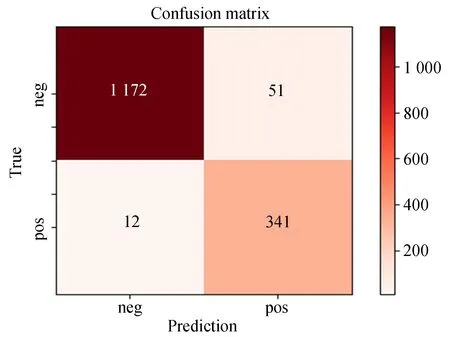
图9 测试集上Coll-Net预测结果Fig.9 Coll-Net prediction result on test set

图10 不同障碍预测方法的ROC曲线Fig.10 ROC curves of different obstacle method
为了反映Coll-Net的空间敏感性,本文采用可视化方法获取了在Udacity数据集上进行Coll-Net障碍预测的激活图(Classification Activation Map, CAM)[22]如图11、图12(彩图见期刊电子版)。图中红色加深部分代表Coll-Net重点关注区域。图11为图像采集车在十字路口前逐渐靠近前车的CAM,当采集车逐渐靠近前车时,网络注意力集中在前车与道路明暗差异明显的区域,这表明Coll-Net网络对明暗变化具有较强的敏感性。
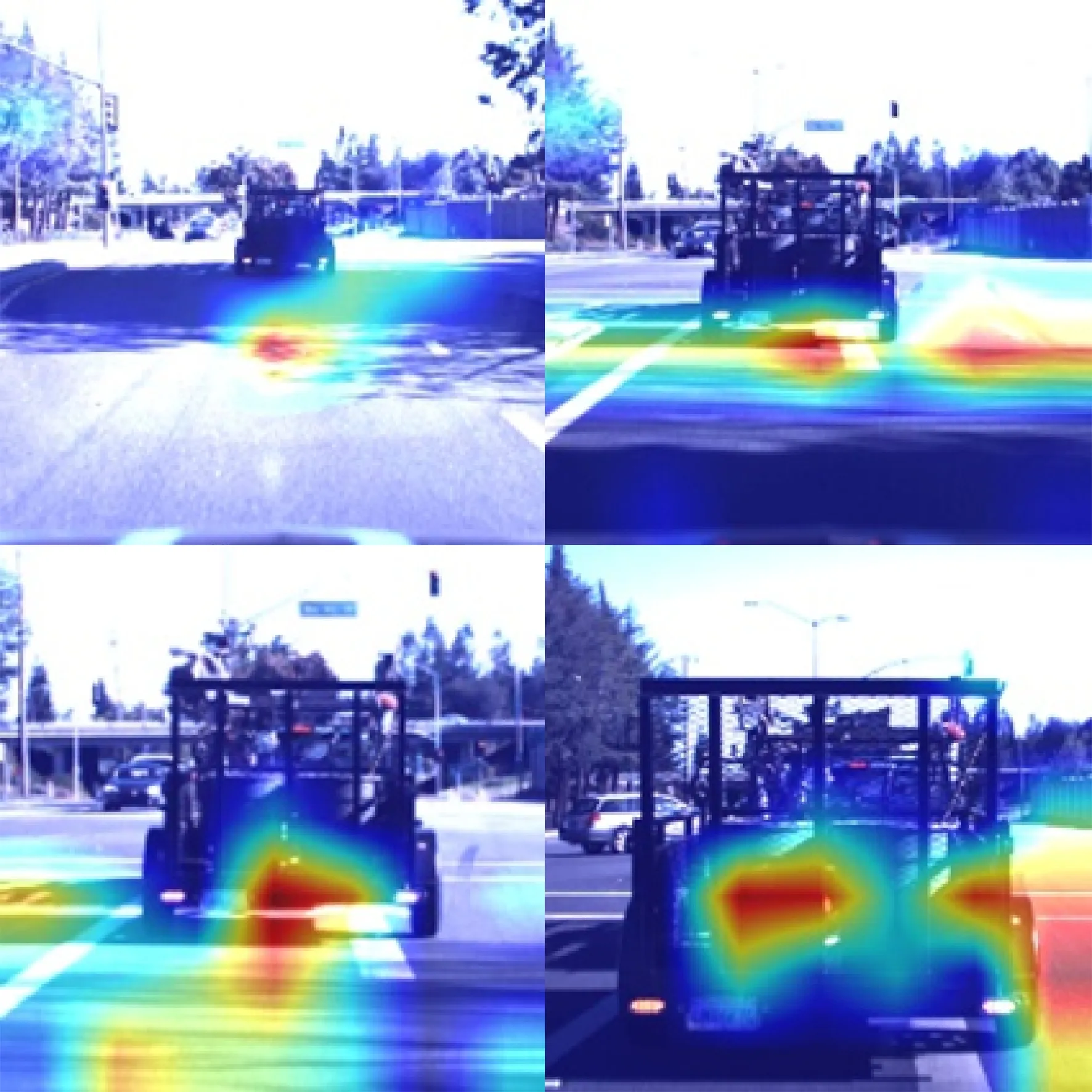
图11 Coll-Net十字路口场景测试Fig.11 Coll-Net test on crossroad
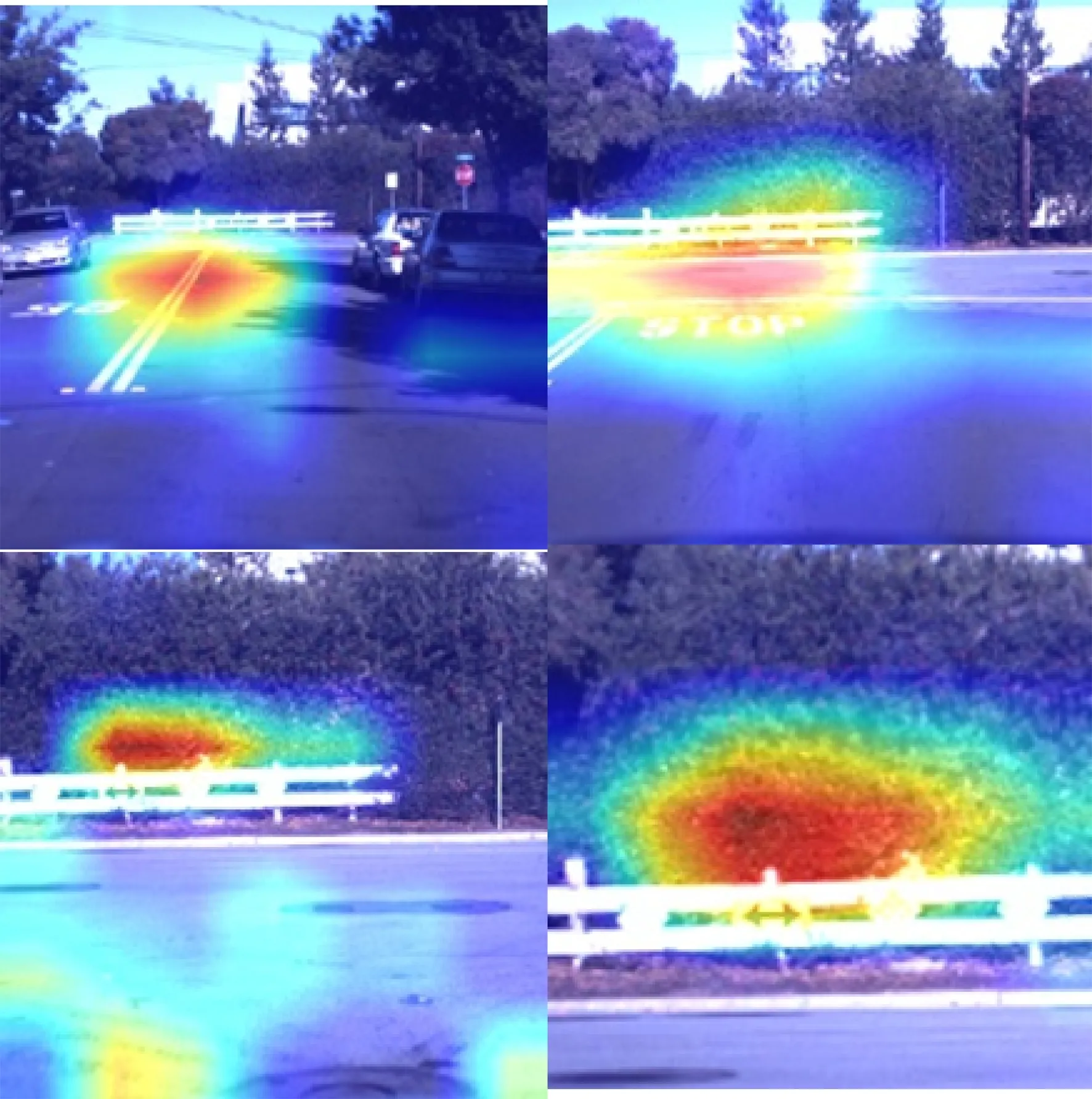
图12 Coll-Net丁字路场景测试Fig.12 Coll-Net test on T-shaped road
图12为图像采集车在丁字路前逐渐向树墙行进时的CAM图。当采集车逐渐靠近障碍时,网络的关注区域从道路转移到障碍物本身。综合两图结果可知,Coll-Net网络能通过道路与障碍的明暗差异以及障碍自身的特征进行障碍预测,具有广泛的行车场景适应性。
5.3 障碍预测和行车策略测试
为检验Coll-Net对其它障碍物及在不同光照条件下的预测能力,分别选取道路护栏、行人和低对比度场景进行测试。图13和图14分别为车辆逐渐靠近护栏和行人的预测结果,图中横坐标表示图片出现顺序,纵坐标为预测值。当障碍物较远时,预测值处于0~0.2的较低水平;当障碍物距离逐渐减少时预测值不断增长,最终达到1,这表明Coll-Net对行人和护栏有较好的预测能力。图15为低对比度条件下在某十字路口前行驶图像,在采集车与前车相距较远、逐渐靠近和前车启动远离的过程中预测值则先保持不变,然后逐渐增长为1并保持,最后下降至0附近。这表明Coll-Net在低对比度条件下仍有良好预测能力。
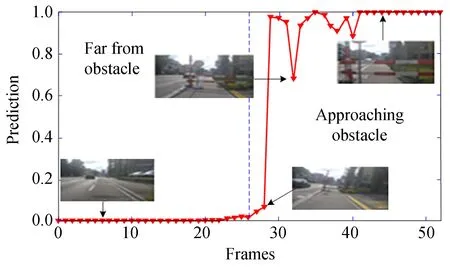
图13 护栏障碍测试Fig.13 Guardrail obstacle test
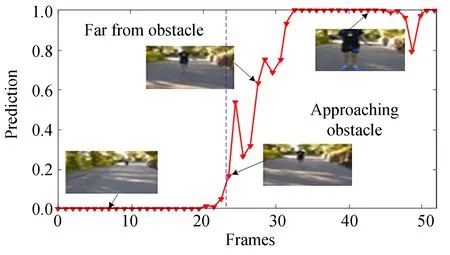
图14 行人障碍测试Fig.14 Pedestrian obstacle test

图15 低对比度场景测试Fig.15 Low-contrast condition test
为了验证本文车速控制策略的有效性,在实验过程中,依据式(12)速度模式并设置增速系数ρ=0.5且使用Udacity连续图像做车速计算,得到图16所示结果。图中,Pred为Coll-Net预测值,Speed表示控制车速与正常车速Vnorm的比值。可见,当车距减少时则车速随预测值增大而迅速减小,这表明了本文基于Coll-Net的车速控制策略的有效性。

图16 车速控制策略测试结果Fig.16 Speed control policy test
图17是利用多窗口Coll-Net预测障碍方向的结果(彩 图见期刊电子版)。当将左、中、右三个窗口的图像输入Coll-Net后得到对应的窗口预测值,将预测值p≥0.5的窗口用红色定位框在原图中进行标记,以表明该方向出现障碍。当行人分别在车辆的右方、中央和左方出现时,Coll-Net都能准确判断了行人所在的区域,这也表明了本文障碍方向预测策略具有可行性。



图17 障碍方向定位测试结果Fig.17 Result of obstacle direction localization
6 结 论
本文提出了融合空间注意力机制的障碍预测网络Coll-Net用于各类行车障碍的预测。Coll-Net网络以单目图作为输入,利用空间注意力机制改良的残差块网络提取图像的重要特征,通过全连接层输出预测的障碍概率,解决了基于目标检测的障碍预测算法中的目标单一性问题,对各类典型障碍物均具有预测能力;与现有算法相比较大提升了预测的准确性,并且能根据多窗口方式大体定位障碍物方向。Coll-Net在DECD数据集上准确率达到96.01%,F1-score达到0.915,模型推理时间仅需24 ms,达到处理的准确性和实时性需求,为Coll-Net在智能驾驶的应用上奠定了一定的技术基础。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
创新作文(1-2年级)(2019年4期)2019-10-15
自动化学报(2019年6期)2019-07-23
汽车与安全(2016年5期)2016-12-01
中国惯性技术学报(2015年1期)2015-12-19
汽车维修与保养(2015年12期)2015-04-18
现代企业(2015年4期)2015-02-28
