
一种基于改进条件生成式对抗网络的人脸表情生成方法
2020-09-02 06:52:22王先先李菲菲
小型微型计算机系统 2020年9期
王先先,李菲菲,陈 虬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
E-mail:xxwang2017@163.com
1 引 言
人脸表情生成的目标在于生成表情丰富而纹理清晰的不同人脸,其可广泛应用于表情分类、辅助驾驶、人机交互等多个领域.因此,表情生成一直以来都是计算机视觉和图像处理领域的研究热点.传统方法通常使用计算机图形学方法进行建模来实现人脸表情的生成.Lin等[2]提出将人脸划分成若干几何区域,然后将参考人脸表情的纹理映射到目标表情的几何区域中.Zhang等[3]提出根据不同表情之间特征点的变换对人脸进行表情变形.这些方法虽然在一定程度上实现了人脸表情的生成,然而生成的目标表情一方面数量有限(取决于几何区域的划分),另一方面并不自然,缺乏真实性,很难得到进一步利用.
近年来,生成式对抗网络[4]在图像生成方面展现出了强大的拟合能力.研究人员利用生成对抗网络可以生成高质量纹理细节图像的特点来实现人脸表情的生成.本文利用条件生成对抗网络模型,以目标人脸表情形状为条件,任意人脸表情为参考图像,实现人脸表情的生成.主要贡献可以归纳如下:
1)以人脸特征点位置为不同的表情形状进行建模,作为目标表情生成的引导条件,并对Pix2Pix模型[13]的网络结构进行改进,以提高其在人脸表情生成方面的性能.解决当前人脸表情生成模型网络结构复杂,参考表情和目标表情之间不能直接相互转换的问题.
2)利用训练好的变分自动编码器[14]作为人脸表情形状控制器.通过该控制器可以生成一系列具有视觉语义变化的、可解耦的表情形状.将形状控制器和表情生成模型相结合,可以生成连续的、具有视觉语义变化的人脸表情.
2 相关工作
2.1 图像生成模型
近年来,深度神经网络在图像生成领域取得了很大的进展.一般来说,通常有两类常用的生成模型用于图像生成.一类基于VAE[1](variational auto-encoder)的生成模型是一种概率统计模型.它主要由用于推断输入图像统计信息的编码网络和用于重构输入图像的解码网络组成.这类生成模型具有训练稳定、收敛速度快等一系列优点.然而,由于VAE模型优化的目标函数是对数似然函数的下界,生成的图像整体上看起来较为模糊.另一类基于GANs[4](generative adversarial networks)的图像生成模型则是通过生成器和判别器之间的对抗学习,隐式地捕获真实图像的概率分布.通过对抗性的训练,GANs类模型可以生成更加清晰、逼真的图像.然而原始的GANs模型仍然存在许多显著的缺陷[27],如模式崩溃和训练不稳定等.研究人员[22,23]提出了一些有效的方法来稳定训练过程、提高生成图像的质量.此外,为了使得生成的图像具有某些期望的属性,研究人员[15,25]提出使用条件GANs对生成的图像进行约束.比如引入类标签之类的辅助信息来指导手写数字图像的生成.目前为止,基于CGANs的模型已经广泛应用于超分辨率图像生成[10,11,26]、图像风格转换[12,18]、图像修复[20]等领域.由于对抗网络在生成图像方面的优异表现,我们同样采用对抗网络来完成目标人脸表情的生成.
2.2 人脸生成模型
利用深度神经网络生成人脸表情的研究工作大致可分为两类:一类是研究人员使用离散的面部属性来进行人脸生成.Yan等[9]提出将性别、表情类别、头发颜色等信息编码到条件VAE模型的瓶颈层中,从而生成具有多样化外观的人脸.Choi等[17]将不同的表情状态(如生气、开心)划为不同的域,并提出StarGAN实现几种典型表情之间的相互转化.StarGAN的判别器不仅需要判断生成图像的真伪,还需要判断它来自哪个域.虽然这些方法可以生成高质量的人脸表情图像,然而编码后的离散人脸属性并不足以描述丰富的面部表情.例如,开心的表情可能对应于嘴巴大小不同的各种笑脸.为了解决这个问题,研究人员探索如何将连续的辅助信息整合到生成模型中.Zhou等[8]提出可以将人脸身份和表情信息相分离的CDAAE模型.在CDAAE中,给定参考人脸表情,通过改变表示不同表情强度的FAU(facial action unit)标签可以生成同一个人的多种表情.GAGAN[5]将人脸表情形状和GANs相结合,使得生成的人脸表情真实、自然并且具有指定的表情形状.然而,由于GAGAN本身的半监督性,其并不能对生成人脸的身份信息进行任何控制.有关连续人脸表情的生成,Qiao等[7]提出利用人脸特征点直接对两个不同的表情形状进行线性插值,然后使用全连接网络将这些形状压缩成一维的编码向量,最后将编码向量输入到对抗网络中进而完成连续表情的生成.Song等[6]同样以人脸特征点为可控条件并提出G2-GAN模型用于面部表情合成.G2-GAN通过两个生成网络分别实现表情的移除和生成,进而实现任意表情的转换.在本文中,我们从现有的方法出发,提出了一种简单而有效的模型来实现目标人脸表情的生成.为了对不同的表情形状进行建模,我们使用像素宽度为1的折线段来连接人脸不同部位的特征点.该模型将参考表情与人脸形状控制器相结合,既可以直接生成目标表情而不用中性人脸表情作为中间的转换媒介,也可以实现连续人脸表情的生成,同时保持人脸身份信息的一致性.
3 改进的条件人脸表情生成模型
3.1 条件人脸表情生成模型
3.1.1 模型网络结构
除了表情上的差异,目标图像和参考图像应该共享同一张人脸的大部分纹理信息.为了在保持人脸身份信息不变的条件下,模型能够根据表情形状g生成目标表情,我们采用改进的Pix2Pix[13]模型作为生成器,如图1所示.该模块主要由两个子网络组成:编码网络GEnc和解码网络GDec.目标表情形状g与参考图像Iref进行连接后共同作为U-Net结构的生成器的输入.生成器的编码网络Genc从输入的图像中提取身份、纹理等高级特征到瓶颈层.生成器的解码网络Gdec则负责融合来自U-Net路径的高级特征和来自skip-connection路径的低级特性以生成目标人脸表情.为了提高了生成图像的质量,我们在Pix2Pix模型的基础上做了以下几个方面的修改:
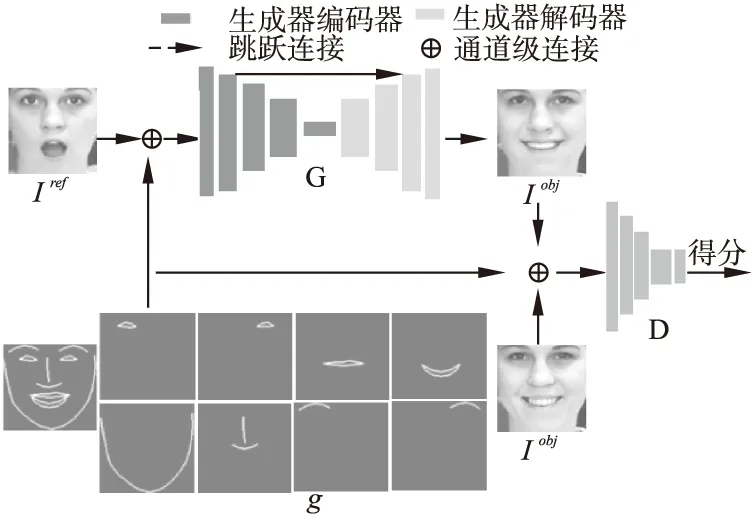
图1 人脸表情生成模型的整体结构Fig.1 Overall structure of facial expression generation model
1)我们使用WGAN-GP[24]代替原始的GANs.原始GANs判别器对输入的判别图像只作真假的二值判断,而WGAN-GP采用wasserstein距离度量目标图像与生成图像分布之间距离.与原始GAN相比,它可以为生成器提供更好的优化方向.
2)对于Pix2Pix模型而言,生成器的编码网络GEnc和解码网络GDec镜像层之间存在很多跳跃连接.而在实验中,我们发现镜像层之间过多的跳跃连接会导致生成器的过拟合,即在训练集上生成目标表情的性能要优于测试集.为此,我们减少冗余的连接,只保留一条跳跃连接.
3)为了简化模型的组成结构,除了判别器的最后一层外,生成器和判别器的所有卷积层均采用3×3大小的卷积核.
3.1.2 对抗损失
对抗网络最重要的特点是通过生成器和判别器之间的对抗性学习来训练网络模型,使得生成器能够生成真实且自然的图像.在本文中,多通道的表情形状图像g和参考人脸表情Iref成对的作为生成器的输入.根据Pix2Pix模型和WGAN-GP模型,我们的对抗网络的损失函数如下:
LGen=-EIref,g~P(Iref,g)D(G(Iref,g),g)
(1)
LDis=-EIobj,g~P(Iobj,g)D(Iobj,g)+EIref,g~P(Iref,g)
D(G(Iref,g),g)+λEI′,g~P(I′,g)(‖I′D(I′,g)‖2-1)2
(2)
其中LGen和LDis分别表示生成器和判别器的对抗损失函数,Iobj表示目标人脸表情,EI′,g~P(I′,g)(‖I′D(I′,g)‖2-1)2表示WGAN-GP网络的梯度惩罚项.
3.1.3 像素级损失
优化对抗损失函数使得生成的图像看起来更真实,但这还不够.对于人脸表情变换的任务,我们还希望生成表情Igen和目标表情Iobj尽可能地一致.Isola等[13]工作表明优化生成图像和目标图像之间的L1范数可以有效地缓解由L2范数所引起的模糊结果.因此,我们使用L1范数来计算生成图像Igen和目标图像Iobj之间的像素级的差异:
LPix=‖Iobj-Igen‖1=‖Iobj-G(Iref,g)‖1
(3)
3.1.4 感知损失
优化像素损失一方面有助于保持生成图像和目标图像面部轮廓特征一致.然而,另一方面也会导致生成的图像在纹理丰富的区域存在一定程度的模糊.Johnson[12]等提出的感知损失在超分辨率图像生成、风格转换等任务中得到广泛的应用,表明了它在提取纹理特征方面的有效性.因而我们采用预先训练好的VGG-FACE[28]分别提取生成表情和目标表情的纹理特征.通过优化感知损失函数,使得二者在特征空间保持一致性:
LPerp=‖F(Iobj)-F(Igen)‖1
(4)
其中F表示训练好的VGG-FACE模型.
综合上述,模型总的损失函数如下所示:
LTotal=LDis+LGen+λ1LPix+λ2LPerp
(5)
3.2 表情形状控制模型
大多数情况下,我们只有有限数量的人脸表情用于转换.事实上,我们几乎也不太可能通过检测或标注的方法得到目标人脸表情的形状.因此,设计一种控制器来生成各种表情形状,进而引导目标表情的生成是一项非常必要的工作.已有的工作[5]采用PCA(principle component analysis)的方法来实现.这些方法先将人脸形状的一维向量压缩到低维空间进行编码,然后通过改变编码向量的值并解码至高维空间来生成新的形状.然而,基于PCA的方法本质上是一种线性编码,无法捕捉输入表情形状特征之间的非线性关系.此外,编码向量的某一维度与表情形状可分解的视觉属性之间只存在弱关联性.为解决这一问题,我们使用β-VAE[14]作为表情形状控制器,如图2所示.与标准VAE的结构相同,它也是由编码器网络和解码器网络组成,其目标函数如下:
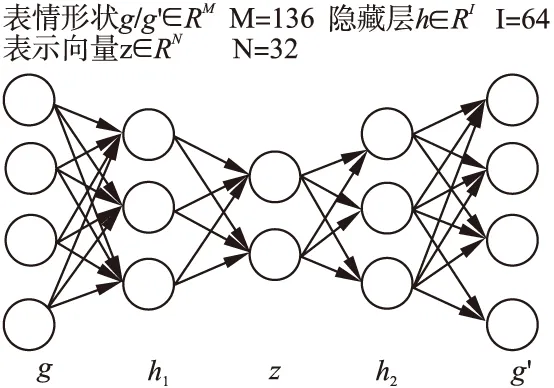
图2 表情形状控制器的网络结构Fig.2 Networks structure of expression shape controller
LCtrl=Eqø(z|g)logpθ(g′|z)-βKL(qø(z|g)‖pθ(z))
(6)
其中第一项logpθ(g′|z)表示重建形状g′的最大对数似然函数,θ为解码网络.通过优化这一项,形状控制器的解码网络可以从条件编码向量z|g中重构出人脸形状g.第二项KL(qø(z|g)‖pθ(z))为正则项,pθ(z)是均值为0,协方差为0,方差为1的先验多元高斯分布.编码网络ø将输入的表情形状g进行压缩编码.通过优化这两个分布Kull-back Leibler距离,条件编码向量z|g的每一维度都具有视觉特征可分解的解释性.与标准VAE不同的是,可调权重系数β负责平衡表情形状g的重建精度和相应的表示向量z|g中每个维度的可解释性.在这项工作中我们将超参数β的值设置为10的表示向量中每个维度的可解释性.在这项工作中我们将超参数的值设置为10.
4 实验结果和分析
在本节中,我们评估了该方法在生成目标人脸表情方面的性能.首先,我们介绍了两种常用的表情数据集及其预处理方法和训练设置细节.然后,我们在任意人脸表情转换、人脸表情生成、人脸表情移除、连续人脸表情生成等任务上展示了生成图像的可视化结果.此外,对于表情生成和表情移除任务,我们选取PSNR(peak signal to noise ratio)和SSIM(structural similarity index)指标来评估生成图像与目标图像之间的差距,以此证明该方法的有效性.
4.1 数据集及预处理
4.1.1 CK+数据集
CK+数据集[16]是由来自123个人共计593个面部表情序列组成.每个人都包含几种典型的表情序列图像,这些表情序列以中性的表情开始,以某种最强烈的表情结束.除了少数彩色的表情序列外,CK+数据集中的图像大多为灰度图像.我们将这些彩色图像转换成灰度图像,并按照8∶2的比例随机地选择99个人的表情序列作为训练集,其余24个人的表情序列作为测试集.此外,我们直接使用该数据集提供的68个人脸表情特征点作为表情形状.
4.1.2 Oulu-CASIA数据集
Oulu-CASIA数据集[21]是由80个人的6种不同的表情序列组成.这些表情序列由近红外和可见光两种摄像机分别在三种不同的光照条件下(暗光、弱光、强光)获得.我们只选取可见光摄像机在强光照下拍摄的序列作为实验数据.实验总计使用了480个表情序列,其中前50个和后30个人的表情序列分别在在芬兰和中国获得.为了保证样本的平衡性,我们按照8∶2的比例随机选取一个由40个芬兰人和24个中国人组成的训练集,以及一个由10个芬兰人和6个中国人组成的测试集.此外,该数据集并没有提供标注好的特征点,我们使用FAN模型[19]来进行提取.
4.1.3 数据集预处理
同一表情序列中相邻图像往往只存在细微差异.然而我们的方法需要任意抽取一对不同的表情作为模型输入.为了减少不必要的训练时间,我们每3帧对原序列进行采样,进而构建一个相对小的训练集.原训练集中所有图像可以在3个epoch内训练完毕.实验中,根据人眼位置进行人脸对齐,然后裁剪出具有5像素边距的图像,最后将裁剪后的尺寸缩放成144×144.同时,对特征点坐标进行仿射、缩放等操作,使其与处理后的人脸图像保持一致.训练时,我们使用像素宽度为1的折线来连接不同部位的特征点,以构建一个多通道的表情形状图像.此外,表情图像的值归一化为[-1,1],多通道的表情形状的值设置为1.在训练形状控制器时,将特征点的坐标值进行均值为0,方差为1的归一化.
4.1.4 训练细节
训练时使用ADAM优化器进行优化;批处理大小设为4;判别器和生成器的学习率分别设置为0.0002和0.0001;损失函数的权重参数λ1和λ2分别设置为10和1;训练时采用随机水平翻转和随机裁剪的方法进行数据增强;测试阶段只使用中心裁剪,裁剪尺寸为128×128大小.
4.2 实验结果及分析
4.2.1 任意人脸表情转换
人脸表情转换是指实现任意参考表情和目标表情之间的转换.G2-GAN采取的方法是首先使用表情移除模型将参考表情转换成中性表情,然后使用表情生成模型将中性表情转换成目标表情.而在我们的模型中,中性表情并不作为完成转换的必要中间媒介.实验结果显示在图3和图4中.对于每个人的三行表情而言,第一列为参考表情Iref,第二列和第三列分别为目标表情Iobj和相应的生成表情Igen.可以看到,转换后的人脸表情和目标表情既具有相同的身份信息也具有相同表情形状,所述模型可以很好地完成目标人脸表情的转换工作.然而,由于生成的表情图像同时受到参考表情Iref和目标表情形状g共同的作用结果.因此,生成表情和目标表情之间存在细微的差别.此外,在Oulu-CASIA数据集上的实验结果表明,生成的图像不受表情形状以外因素的影响(如眼镜和背景等).与Oulu-CASIA人脸数据集相比,CK+人脸数据集中的图像具有更高的分辨率,这也合理地解释了图4中所生成的人脸表情在纹理更丰富的嘴巴和眼睛等区域具有更加清晰的细节特征.

图3 Oulu数据集上的人脸表情转换Fig.3 Facial expression transform on Oulu dataset
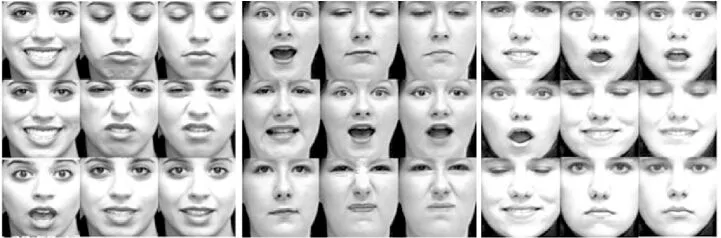
图4 CK+数据集上的人脸表情转换Fig.4 Facial expression transform on ck+ dataset
4.2.2 人脸表情移除和生成
人脸表情移除是指将具有某种表情的人脸转换成不含任何表情的中性人脸,反之则称为表情生成.对于表情移除,我们使用各表情序列中的第一帧作为目标表情Iobj(中性表情),而其余各帧依次作为参考表情Iref.对于表情生成,我们使用各表情序列的第一帧作为参考表情Iref(中性表情),其余各帧依次作为目标表情Iobj.我们分别在CK+和Oulu数据集上进行表情移除和表情生成实验.在测试集中,我们随机地从生成的表情序列中为每个人选取4张生成的人脸表情,并将它们与真实图像相比较,结果如图5和图6所示.对于图中每个人的三行表情序列而言,第一行表情为真实图像,第二行为表情生成图像,第三行为表情移除图像.可以看到,表情生成的图像几乎和真实图像具有相同形状,而所有表情移除的图像几乎一致.此外,我们使用PSNR和SSIM指标分别定量地评测了表情生成和表情移除任务中生成的图像与真实图像之间的差异.同时,为了表明改进方法的有效性,我们对不同的模型结构做了对比试验,具体结果如表1所示.其中配置A为所改进的模型;B为Pix2Pix模型;C和A一致,但使用原始GANs;D和A一致,但没有跳跃连接.评测结果表明我们的改进方法在两个数据集上均可以显著的提高生成图像的质量.

图5 Oulu数据集上人脸表情生成和移除Fig.5 Facial expression synthesis and remove on Oulu dataset

图6 CK+数据集上人脸表情的生成和移除Fig.6 Facial expression synthesis and remove on ck+ dataset

表1 表情移除和表情生成实验在不同模型配置下定量评测结果Table 1 Quantitative results of different model configurations for expression remove and synthesis experiments
4.2.3 连续人脸表情生成
大多数情况下我们只有少数人脸表情.然而,我们的目标不仅是生成从未见过的人脸表情,我们还想从语义的角度控制这些表情的生成.比如,通过控制表情形状控制器生成只有嘴巴大小改变的表情形状,进而生成相对应的人脸表情.具体方法如下:首先使用训练好的形状控制器,将一个中性的表情形状从形状空间压缩到低维的表示空间.然后通过对指定的维度值进行线性变换,再将其映射回形状空间,得到一组具有共同语义变化的表情形状.最后,将这组形状输入到条件人脸表情生成模型的生成器中,生成一系列语义上可连续变化的人脸表情.在图7中,我们展示了该方法在CK+数据集上的实验结果.每对序列的第一行是由形状控制器生成的一系列连续的人脸形状,第二行是由中性人脸作为参考表情生成的对应表情.三行形状序列分别是通过线性改变低维表示向量的第1维、第2维、第21维值而产生的.我们可以看到,人脸形状低维表示向量的维度与解耦的视觉特征有着密切的语义关系.例如,表示向量的第2维控制眼睛的大小,第21维控制嘴巴的长度,而所生成的表情与人脸形状的变化基本上是一致的.此外,我们还可以完成人脸表情插值任务.通过对表示向量空间中任意两个人脸形状之间的线性插值,可以得到一系列的引导形状.这些形状可以帮助我们在参考表情和目标表情之间生成另一种类型的连续人脸表情.需要特别指出的是,所有这些连续生成的人脸表情均没有对应的真实图像.

图7 CK+数据集上的连续人脸表情生成Fig.7 Continuous expression synthesis on ck+ dataset
5 总 结
在这项工作中,我们提出了一种基于条件生成对抗网络的模型来实现目标人脸表情生成的方法.相比于FAU编码或离散表情类别标签,人脸特征点是对丰富的人脸表情进行建模的一个理想选择.利用特征点表示表情形状,我们的模型能够生成大量的、纹理细节清晰的,同时保持身份信息不变的表情.本文中,我们使用所提出的方法实现了表情转换、表情移除、表情合成等多个任务.此外,将基于CGAN的表情生成模型与所设计的形状控制器相结合,可以方便地在语义层次上实现连续人脸表情的生成.然而,对于头部姿态发生变换的人脸表情生成任务,依然是本文后续工作的研究重点.
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
动漫星空(2018年9期)2018-10-26 01:17:14
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
发明与创新(2015年33期)2015-02-27 10:40:09
