
基于卷积神经网络和概念格的图像语义完备标注
2020-09-02 06:52:22李雯莉张素兰张继福胡立华
小型微型计算机系统 2020年9期
李雯莉,张素兰,张继福,胡立华
(太原科技大学 计算机科学与技术学院,太原 030024)
E-mail:zhsulan@126.com
1 引 言
网络图像数据的爆炸性增长以及图像标记的主观性和随意性,造成了大量图像的标签缺失和语义噪声,不能很好地描述图像内容.而且这些海量的图像数据通常都包含着丰富的语义内容,但标签的不完备却给基于文本的图像检索带来了巨大挑战,影响了其他相关产业的发展.为丰富图像标签内容,提高图像检索准确率,许多研究者已对缺失标签进行自动补全的图像标签完备方法展开了深入研究[1-4].
近年来,国内外对图像标签的完备标注研究取得了一定的成果.目前的研究工作中,一些学者将给图像标签补足问题转化为标签矩阵补足问题,其中,Wu L等人[5]提出了一种TMC模型,并且通过矩阵的形式将标签和图像之间的关系展示出来,借助搜索与之最为相似的图像部分加以进行标签补足;Guillaumin M等人提出基于K-近邻图像的标签传播算法[6],使用图像底层视觉特征进行一系列特征融合加权寻找视觉近邻完成图像标签传播,根据视觉近邻将相似度更高的相关标签传播给待标注图像.这两种方法提高了图像标注量,但缺少对标签本身相关度的分析,影响标注效果.Wu B等人[3]通过将缺少标签的多标签学习(MLML)问题视为从提供的标签信息传播到缺失标签的节点依赖关系图,通过不同的标签依赖关系以构建两种不同类型的混合图(基于MG-CO的同类共现混合图和基于MG-SL的稀疏-低秩混合图),将图像间相似性作为无向边连接不同图像间的标签节点,利用语义层次结构作为有向边来连接不同的类,或在所有标签上嵌入高阶相关性,分别基于这两种图,将MLML问题转化为凸优化问题,进行标签的完备;Zhang Y等[7]提出利用标签之间的协方差矩阵描述成对标签之间的相关性,但缺少与图像本身底层特征的联系;刘杰等人[8]联合两种不同模态(视觉模态和文本模态)的主题分布概率,构造图像之间的关系模型,通过计算基于不同模态下先验、后验联合概率分布完成标签标注,虽然考虑文本模态对标注结果的影响,但由于很难精确得到图像与标签之间的分布关系,标注效果改善不大,造成了一定的误差.黎健成等人[9]尝试构建多标签排名损失函数输出图像标签结果,但其未处理标签样本忽视了图像-标签间的局部包含关系,影响了标注结果.虽然图像完备标注已经取得一定的成果,但也存在以下不足:1)需要选择组合图像底层特征,不能主动学习图像特征,可能会导致图像部分视觉信息缺失,导致标注不精确;2)缺失了语义标签本身的相关性的研究,将图像不同贡献程度的标签内容同等权重处理,忽视了标签语义分布的不均匀性和相关性.
建立缺失标签图像低层的视觉特征与标签之间的关系,并有效地改善语义标签是提高图像标签完备标注精度的一个关键.深度卷积神经网络因具有深层网络结构并能够主动学习并抽象出图像的底层特征,具有更强大的表达能力,在各种视觉识别任务中显示出巨大潜力[10,11].概念格因能很好地将概念之中包含与层次之间的关系展示出来,成为一种构建高效数据分析与知识提取的工具[12-14].因此,为提高图像完备标注的精度和召回率,本文采用CNN提取图像低层视觉特征与标签的关系,并通过概念相关度计算,利用概念格对待完备图像进行标签补足,提出了一种基于CNN和概念格的图像完备标注方法.
2 相关理论
2.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)通常由输入层、卷积层(convolutional layer)、池化层(pooling layer,也称为取样层)、全连接层及softmax层[15]构成,具有局部连接、权值共享、池化操作及多层结构[16]等四个特点.由于CNN具有深层的网络结构,并且可以通过非线性多层变换主动学习图像特征,具有很强的表现力,因此,本文尝试利用卷积神经网络对图像标签进行图像的完备标注.
2.1.1 卷积层与池化层
卷积层是CNN特征提取最重要的环节,每一层采用3个卷积核串联,步长设置为1,后接一个池化层.通过卷积提取低级特征(例如边缘),并通过权重分布连接上层实体表面的局部区域,并将局部加权和传递给非线性函数Relu函数以获取卷积层的输出值.假设第i层为卷积层,为第i层的卷积核;表示为前一层的输出特征,则输出图像值为式(1):
(1)
其中,×表示卷积运算,ai,j表示第i层第j个卷积核输出的特征值,wb表示第i层特征映射增加的偏置值,f(·)为激活函数,这里取Relu函数,即为式(2):
(2)
池化层紧接着卷积层之后,常用的池化操作有最大池化、均值池化等.由于卷积过程中存在或多或少的冗余信息(即重复卷积的元素),需要每个神经元对局部接受域进行池化操作,起到二次提取特征的作用.本文采用最大池化操作,采用规模大小为2×2的池化核,效果如图1所示.
2.1.2 全连接层
在CNN结构中,全连接层中的每个单元与其前一层的所有单元加以全连接,以此进一步将卷积层、池化层中具有类别区分性的局部信息加以优化整合.为了提升CNN网络性能,最后一层全连接层的输出值被传递给最后一个输出层,通常采用Softmax逻辑回归.为避免训练过拟合,常采用正则化方法,不参与CNN的前后向传播过程,使部分隐藏层节点失效,有效地降低神经元之间相互适应的复杂性,进而提升借助神经网络学习来获得的图像特征的品质.
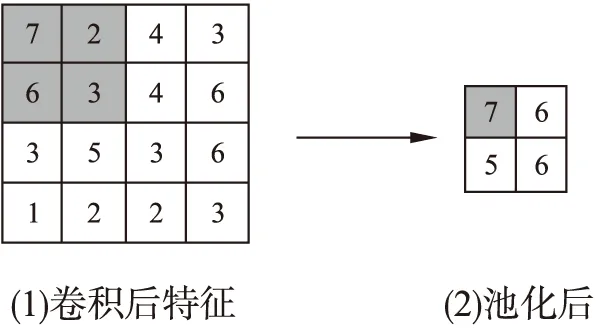
图1 规模2×2的最大池化操作示意图Fig.1 Schematic diagram of the maximum pooling operation of scale 2×2
2.2 概念格
概念格(concept lattice)是20世纪80年代初由德国Wille教授提出的[17],因每个概念及上下层概念之间隐含地表示了属性之间的关联关系,成为一种有效的数据分析方法和知识表示工具.概念格也被称为形式概念分析(Formal concept Analysis,简称FCA),参照文献[18,20],本文给出相关定义:
定义 1.在概念格理论之中,一般会将形式背景作为一个三元组C=(U,A,R),在这之中,对象集即为U,属性集即为A,及一个二元关系.若对于一个对象与任意属性,存在关系R,那么称为“对象u具有属性a”,记为uRa.如表1所示,表中用“x”标记出对象与属性之间的映射关系.
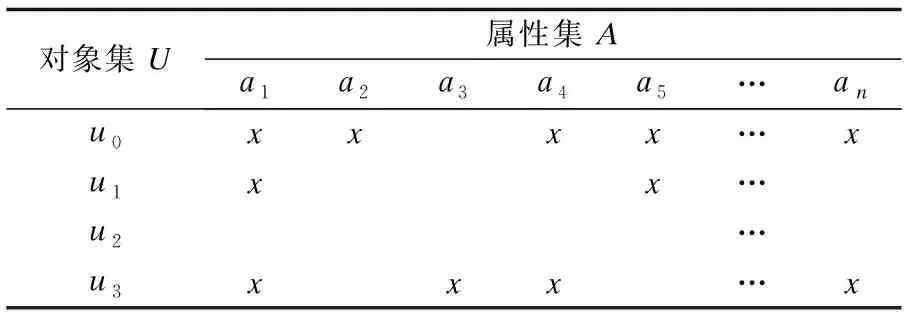
表1 对象U与属性A的形式背景Table 1 Formal background of object U and attribute A
定义 2.对于任意一个二元组z= (I,T),I⊆U,T⊆A,在对象集和属性集上分别满足如下运算:
f(I)={a∈A|∀u∈I,uRa}
g(T)={u∈U|∀a∈T,uRa}
若f(I)=T,g(T)=I,则定义z=(I,T)是基于形式背景C(U,A,R) 这一基础之上的形式概念,所以形式概念z的外延即为I,而形式概念z的内涵即为T.
定义 3.设z1=(I1,T1)、z2=(I2,T2)表示形式背景C(U,A,R)上的两个形式概念,若:
z1≤z2↔I1⊆I2↔(T1⊆T2)
则z1是z2的子类节点,z2是z1父类节点.将用这种偏序关系组成的集合称为C上的概念格,记为
3 本文方法
虽然CNN在图像标注领域取得了很大进展,能够逐层抽象特征图的重要信息,但由于方法本身高度依赖于真实边界框,当将其转移到没有任何边界框信息的多标签数据集时,可能会限制其泛化能力.如某幅图像存在缺失标签“cloud”"和“sky”,经过卷积神经网络标注之后,只标注“cloud”,缺失了标签“sky”.但在一般情况下,“cloud”和“sky”并不完全孤立,存在依存关系,被用来标注同一幅图像的概率极高,如果在语义上不加处理,会影响图像的标注效果.因此,针对上述问题,本文从图像语义相关度的角度,根据概念格的结构特征以及语义相似度计算的基本思想,通过对标签贡献值进行排序来完成标签的预测,对深度卷积神经网络的标注结果进行改善,本文提出了一种基于CNN和概念格语义扩展的图像完备标注模型,如图2所示.
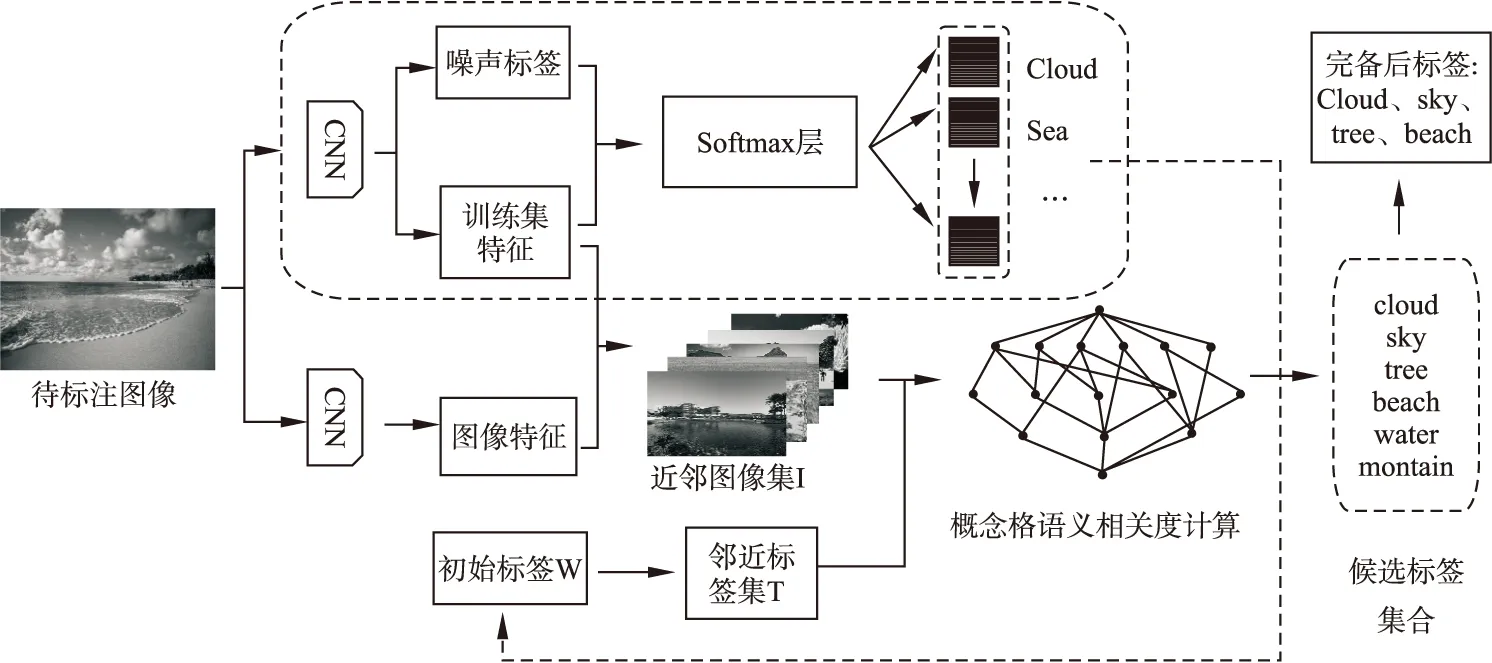
图2 基于CNN和概念格语义扩展的图像完备标注模型图Fig.2 Image completion annotation model based on CNN and concept lattice semantic extension
3.1 基于CNN的图像初始标注
与传统的神经网络相比,卷积神经网络有了显著的提高,通过构建具有多个隐含层的非线性网络结构,实现复杂函数逼近,使用特征映射来学习图像的内容潜在地寻找图像中的各种目标.本文采用类似于2014年大规模视觉识别挑战赛提出的卷积神经网络方法[19]对图像特征进行提取,为了更好地初始化卷积神经网络模型,需要对基于ImageNet预先训练的模型参数进行微调,通过调整竞赛中VGG-Net模型,以此来完成模型的训练,与其不同的是本文为增加数据量,进行了对数据旋转、尺度缩放处理和均值化过程.本文采用VGG-Net中性能更好的VGG19模型,包含19个隐藏层(12个卷积层,4个池化层和2个全连接层)、1个输入层和1个输出层.整个网络均使用相同大小的卷积核(3×3)和最大池化大小(2×2),输入图像大小均为224×244.具体过程如下:
1)采用VGG19模型进行预训练,使用ImageNet数据集训练,并调试网络参数至最佳通用状态.
2)使用Multi-Scale做数据增强,将图像缩放到不同尺寸S,满足输入要求.令处理后的待标注图像为I0,则I=[f0,f1,…,fm]T,其中fm为原始像素,m为像素数.
3)初始化图像标签数量,为不陷入局部最优,减少过拟合,将其作为深度网络有效的监督信息,对其Normalized cut聚类分割,结果如图3所示.
4)输入CNN网络,将高维的输入图像转化为低维的抽象的信号特征,将边缘特征抽象组合成更为简单的特征输出.
5)为减少卷积操作后存在的冗余信息及降低特征维数,采用最大池化操作.设第i层为池化层,输入的图像值.为fi,分割成的图像块区域为Rk(k=1,2,…,k),如式(3)下:
(3)

图3 Normalized cut图像分割可视化图Fig.3 Normalized cut image segmentation visualization
6)进行全连接层计算.对倒数第二个全连接层输出的4096*1的向量做softmax回归,得到特征向量,在得到的20个由深度网络提取到的特征做softmax回归得到标签的概率中选择最大的一个作为图像块的标签,计算如式(4)所示,重复该步骤直至所有图像块被标记,得到初始标注集合W0.
(4)
3.2 基于概念格的语义扩展改善
本文把节3.1去掉softmax层的CNN模型,作为一个图像通用特征提取器,因输出特征包含了卷积层和池化层使其具有全局和局部的特征表现,具有更强的抽象表现能力,为每个图像提取全连接层第二层输出的4096维特征向量并保存再使用PCA进行维数缩减以保持80%的特征差异,最终输出对应的图像特征.对得到的图像归一化之后为256×256然后转换为向量,若选择性搜索后得到的图像个数为N,则图像转换成大小为65535*N的向量矩阵.后对该矩阵SVD分解,得到降序排列的特征值,利用特征值计算权值,得到相似图像的权重,如式(5)所示:
(5)
其中,λi表示图像的特征值.其次,将由深度网络得到的权重值wi大于0.5的图像块对应图像构成近邻图像集合I,由图像特征搜索到的近邻图像与对应标签生成形式背景,利用图像标签之间的语义相关度来描述图像之间的相似程度,据此计算近邻图像的语义相关度.
假设待标注图像I0,得到k张(假设k=5)与其最相似的近邻图像I1-I5,获取图像I0及其近邻图像所有的标签并入集合T中,则Ik={I0,I1,I2,I3,I4,I5},T={“sky”、“grass”、“river”、“tree”、“ground”、“people”、“bird”、“animal”、“dog”、“car”}.根据定义1构造近邻图像与标签映射关系并进行归一化处理,即存在映射关系“x”的将其置换为1,反之,记为0,构造出形式背景G,如表2所示.为方便表示,分别用“t1-t10”
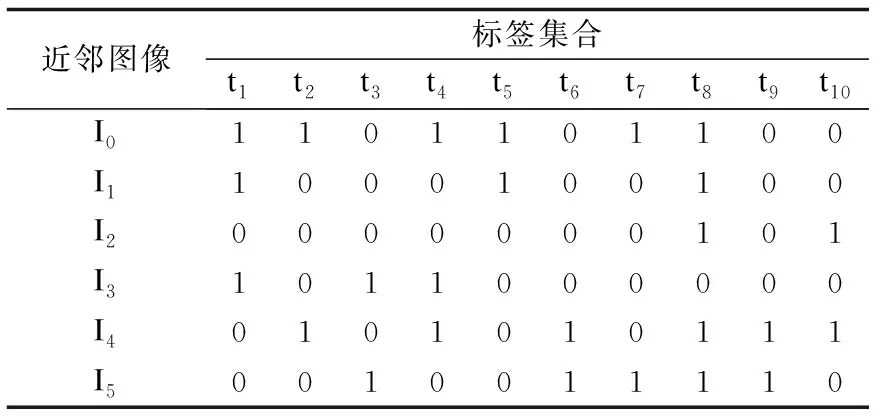
表2 形式背景G表Table 2 Formal background G
按序表示标签集合中的词,并依形式背景G构造Hasse图,如图4所示.
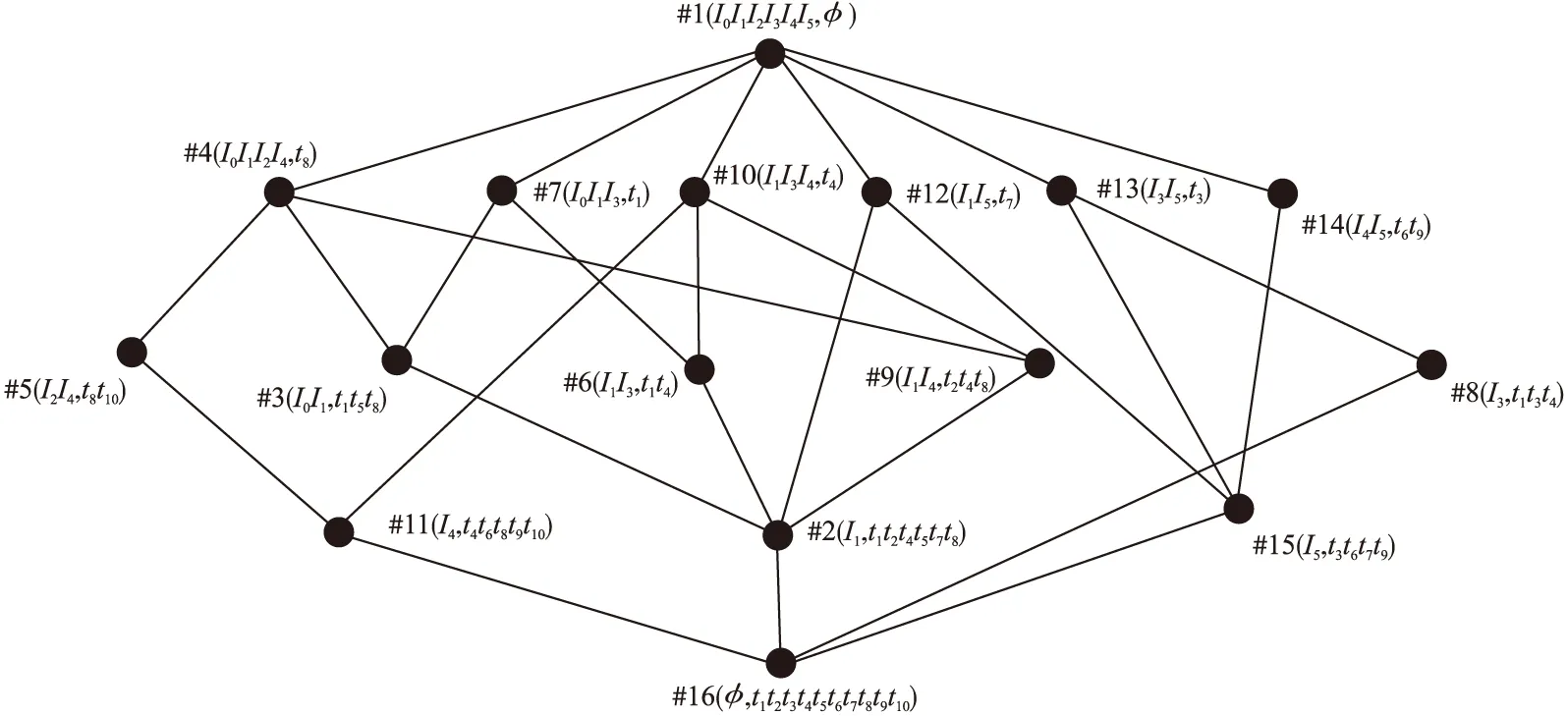
图4 形式背景G的Hasse图Fig.4 Hasse image of formal background G
概念格是一种有效的语义层次分析工具,为利用概念格进行图像标签语义相关性分析,本文定义了如下一些语义相关度概念.
定义 4.概念-概念相关度Rel(dist(zi,zj)).由图4可知,两个概念之间形成的通路越短,则概念间的相似度越大,若Dist(zi,zj)表示一个格结构中两个概念之间形成通路的最短路径长度,则基于概念-概念之间的相关度计算公式如(6)定义如下:
Rel(dist(zi,zj))=τ/(τ+Dist(zi,zj))
(6)
其中,Rel(dist(zi,zj))表示概念zi和概念zj间的语义相关度;τ为大于0的实数,这里取τ=1.
定义 5.外延-概念相关度Rel(I,z).随着深度的增加,由定义2可知,概念节点中外延数逐渐减少,共同拥有的内涵数就会越具体,概念之间的相似度也会随之减小.因此,本文通过考虑概念节点间的关系和概念节点所处的深度对图像语义相关度的影响,给出基于外延-概念的相关度计算公式如式(7)定义如下:
Rel(I,z)=(|Ii|∩|Ii|)/max
((|Ii|,|Ii|))×(1+σ)(dep1+dep2)
(7)
其中,Rel(I,z)表示的是基于外延-概念的相关度, |Ii|∩|Ij|表示的是概念zi=(Ii,Ti)和概念zj=(Ij,Tj)间相同的外延个数;dep1和dep2分别代表的是概念节点zi和概念节点zj所处的深度,设概念格顶层概念的层次为1,其节点深度为上邻节点概念层数加1;σ是为体现概念节点深度对其影响的修正参数,这里取σ=0.1.
定义 6.内涵-概念相关度Rel(T,z).概念格结构中,概念与概念之间距离越远,则外延所共同拥有的内涵数越少.由此可以得出,随着概念格Hasse图概念节点的深度增大,概念外延的语义相关度与外延共同拥有的内涵数成正相关性.因此,本文通过考虑概念节点间的关系和概念节点所处的深度对相关度的影响,提出基于内涵-概念的相关度计算公式如式(8)定义如下:
Rel(T,z)=(|Ti|∩|Ti|)/max
((|Ti|,|Ti|))×(1+σ)(dep1+dep2)
(8)
其中,Rel(T,z)表示的是概念-内涵的相关度,|Ti|∩|Tj|表示的是概念节点zi和概念节点zj所拥有共同内涵数的个数;σ是修正参数,作用同定义5.
根据定义4、定义5及定义6,依据式(6)、式(7)、式(8)计算出每个概念节点之间的相关度Rel(zi,zj),降序排列得到近邻图像对其图像语义的支持度并将其归一化,利用相似图像之间的语义相关度,进一步衡量图像之间相似程度,可以大大减少噪声图像标签的加入.因此,综合考虑概念-概念、外延-概念、内涵-概念以上三者对图像语义相关度的影响,本文给出基于概念格的图像语义相关度公式(8)定义如下:
Rel(zi,zj)=Rel(I,z)×α+Rel(T,z)+
Rel(dist(zi,zj))×γ
(9)
其中,α、β、γ是各部分所占的权重比,且α+β+γ=1.由于内涵和外延在概念对中具有同等大小的权重比,根据概念格的对偶原则,本文取α=β=0.25,则γ=0.5.
据此计算所有概念之间的语义相关度,如在形式背景G中,从节点#2和#3、#3和#4存在上下位关系,节点#2和#15为同层次概念,由式(9)可以得出如下关系:
Rel(z2,z3)=(1/2+3/6)×0.25×(1+0.1)3+4+
1/2×0.5≈0.737
Rel(z2,z15)=(0+1/6)×0.25×(1+0.1)4+4+
1/(1+2)×0.5≈0.257
Rel(z3,z4)=(2/4+1/3)×0.25×(1+0.1)2+3+
1/2×0.5≈0.585
可以得到:
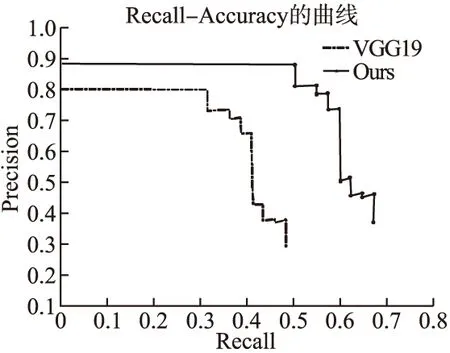
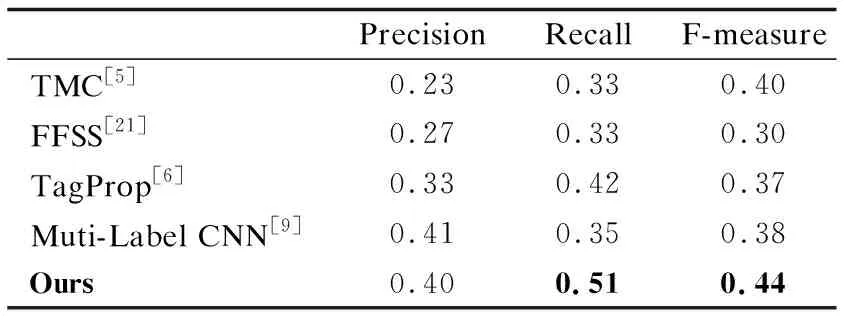
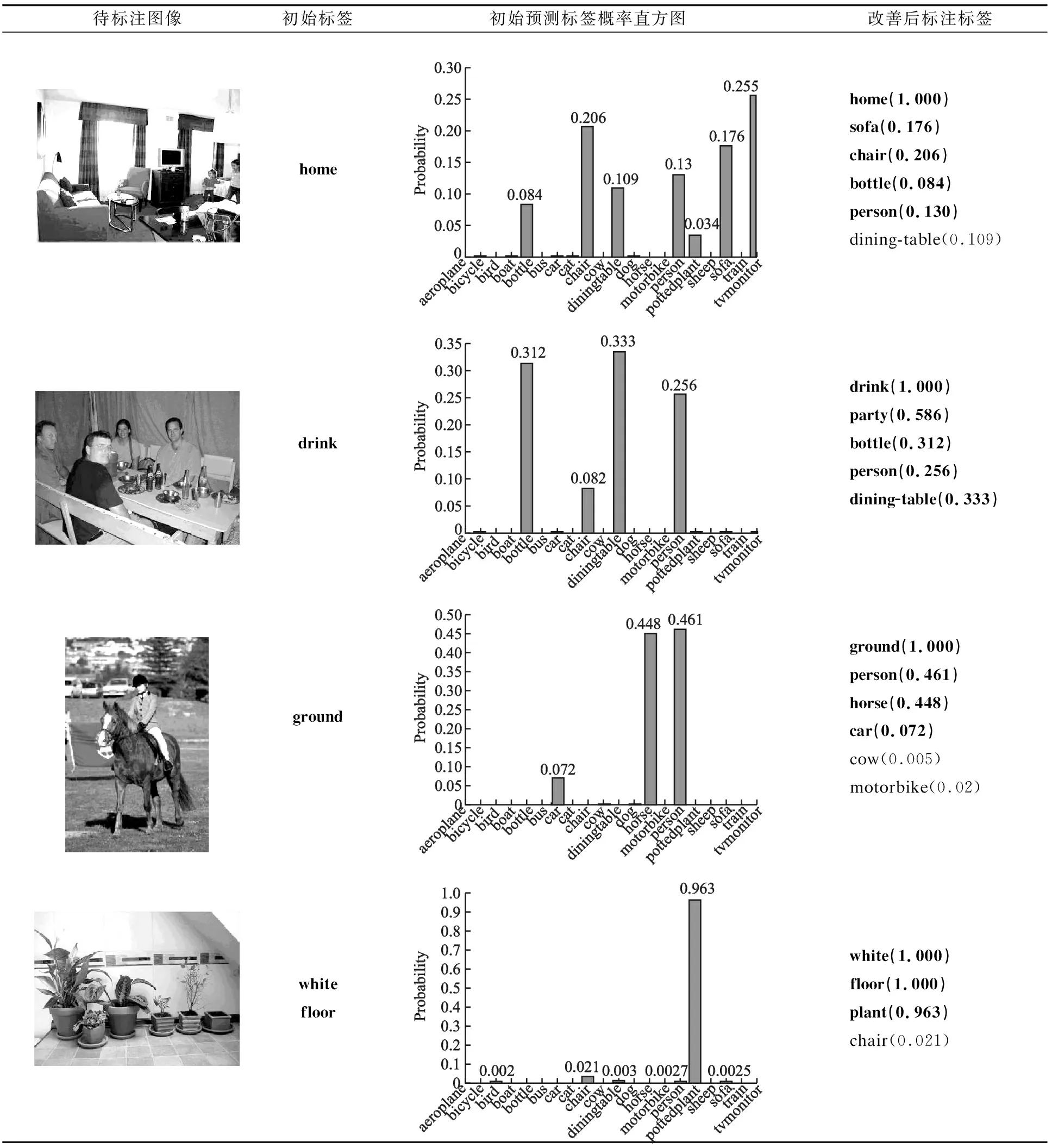
Rel(z2,z15) 由此可知,父节点的语义相似度要比同层次概念节点的高,同时,随着概念格层次的逐渐加深,父子节点之间的语义相似度也会随之增大.我们将包含同一对象的不同概念节点相关度叠加得到图像之间的语义相关度,例如由节点#2、#3、#4可知待标注图像I0与图像I1的语义相关度为1.322,与图像I5的语义相关度为0.257.由此可得,待标注图像Ii与训练集Ij视觉相似度.当待标注图像Ii越高时,图像Ij与Ii的语义相关度越高时,其标签贡献值越大,越有可能被标记. 通过节3.2计算图像标签之间的语义相关度,获取一系列同待标注图像关联密切的近邻图像标签作为候选标签,对初始预测标签进行语义扩展.由于近邻图像与待标注图像的相似度程度不同,且一般与待标注图像语义相关度更相近的图像对标注结果影响更大.由于图像集I是根据图像底层特征搜索降序而得,并且同时考虑了底层特征与高层语义的相似性,兼顾近邻图像语义对标注结果的影响,从而避免某些标签过少或过多,改善标注结果,丰富图像的语义内容.因此,本文融合CNN标注结果并结合近邻图像与待标注图像的语义相关度,从视觉和语义两个角度,筛选候选标签集中关联程度强的候选标签,从而保留支持度更高的标签标记图像. 根据式(5)获取的图像块权重大小wi,从视觉角度,将其作为近邻图像Ik对待标注图像的支持度指标之一;根据概念格获得近邻图像与待标注图像的语义相关度,计算候选标签集中每个关键词对待标注图像的支持度sup(tgj,Ii): (10) 其中,φ(Ik,tj)近邻图像Ik与标签tgj的所属关系,若近邻图像Ik被赋予标签tgj,则φ(Ik,tj)=1,反之为0.得到每个标签词的分数之后,将sup(tgj,Ii)进行归一化处理,为减少不相关的标签语义词,本文将支持度大于0.01的候选标签词保留,去除标签噪声后,作为待标注图像最终的的标签词. 结合上述通用CNN模型以及概念格语义相关度计算规则,给出本文方法主要步骤,具体如下: 输入:待完备图像I0,初始标签集合W0,已训练好卷积神经网络CNN. Step 1.预处理.利用Ncut算法对图像进行分块,每块图像为不同聚类区域; Step 2.图像特征提取.对每块图像进行选择性搜索,得到每一块子图像感兴趣区域,利用CNN得到抽象特征图; Step 3.初始候选标签获取.将特征图做softmax线性回归,通过式(4),得到标记图像的标签概率,以及输出初始标签集合W0; 本文在数据集Corel5k上做了对比试验.实验过程中随机抽取一定数量的图像进行模型性能测试,分为训练集、验证集、测试集.软件环境为MATLAB 2018b.另外,进行深度学习的相关服务器配置:4块1080TI11G显卡,2个CPU 64G内存(Intel i7-6900K 26核、56线程).表3是实验相关数据集的介绍. 表3 实验数据集表Table 3 Introduction to experimental data sets 本文采用准确率Precision、召回率Recall以及F-measure作为本文方法的性能评价指标.其中,准确率Precision指的是正确预测为正占全部预测为正的比例;召回率Recall指的是正确预测为正占全部正样本的比例,F-measure指的是查准率和召回率调和均值的2倍.公式如下: 其中,TP指的是预测标签中与图像相关且预测正确的图像总数;FP指的是预测标签中与图像无关却被标记的图像总数;FN指的是将预测标签中将正类预测为负类数的图像总数. 为了衡量深度卷积神经网络模型的性能,本文首先从分类器的角度来衡量模型的标注准确率,分别给出了不同深度训练模型VGG16和VGG19在数据集MS Coco和VOC 2012上的ROC-AUC曲线图,如图5(a)和图5(b)所示. 图5 不同深度网络ROC-AUC比较图Fig.5 Comparison of different depth networks ROC-AUC 由图5可知,虽然两个卷积网络模型均表现出良好的学习能力,但VGG19的曲线更靠近左上方,模型的泛化能力要更强,预测精度可达91%,证明VGG19模型在训练数据上的损失函数值更小,拥有更好的抽象特征的能力,这可以为下一步提取训练集通用特征提供可靠的保障.因此,本文选用VGG19网络结构作为模型初始标注的预训练模型. 为验证概念格语义扩展的有效性,针对候选标签集中最终标记的不同标签个数,展示一组不同预测个数对Precision以及Recall影响的P-R曲线.本文设置两组实验进行对比,一组基于VGG19模型对待标注图像进行多标签排序标注,另一组在获得初始标注之后,利用概念格对CNN标注结果进行语义扩展改善.首先将测试集图像调整为256×256,然后从每幅图像中随机提取224×224(及其水平映射),通过减去每个提取的图像块的平均值进行预处理,输入CNN的第一卷积层,直至最后输出softmax层产生1000类的概率分布,选取候选标签集中Top-5作为图像的最终标签.训练网络时,本文使用动量为0.9且重量衰减为0.0005的随机梯度下降来训练网络.为了克服过度拟合,对全连接层中前两层都进行丢失率为50%的删除操作.将所有层的学习率均初始化为0.01,每20步下降到当前速率的十分之一(总共90步),训练完成后保存网络模型.实验结果如图6所示. 图6 P-R曲线图Fig.6 P-R curve 由图6可以得出,曲线刚开始无明显变化,随着图像召回率Recall的增加,基于VGG-net网络多标签排序算法标注精度率先开始下降,而本文方法在保证准确率的基础上,召回率更高,说明本文方法更优.该实验表明,采用概念格对图像进行语义相关度分析对提高图像标注标签的召回率具有重要意义.当召回率达到54.74%,准确率开始下降,这是因为在概念格对标签进行语义扩展时,当候选标签集预测个数不断增大,会有一部分噪声标签被标记图像,造成过度标注.由于很多标签词存在关联性,利用图像-标签之间的上下位关系,在视觉近邻的基础上,可以得出图像之间的语义关联程度.在预测标准个数一定的情况下,若仅根据图像的边界特征进行分类识别和标注,不足以丰富图像的标签语义内容,且准确率和召回率显然不如本文中的方法,这证明了本文方法对标签改善的有效性,在某种程度上提高标签标记的可能性. 本文选用数据集Corel5k作为对比实验的验证数据集,它拥有50个类别,每张图片大小为192×128,每张图片均有1~5个标签,选取Corel5k中的500张测试集(263个标签)进行测试,并与之前的一些经典的图像标注算法进行对比,对比方法包括:TMC标注模型[5]、特征融合和语义相似(Feature Fusion and Semantic Similarity,FFSS)[21]和标签传播算法(Tag Propagation,TagProp)[6]、Muti-Label CNN[9]方法. 表4 实验结果比较表Table 4 Comparison of experimental results 表4中部分算法数据来源于其对应的文献.通过表4可以看出,与传统的标签传播算法相比,准确率和召回率有显著提升,本文方法在准确率和召回率上分别达到40%、51%,与文献[21]相比,本文方法利用深度学习网络摒弃复杂的特征融合,利用大数据集辅助特征学习迁移微调网络,有更强的区分效果,准确率提高了13%.同时通过与Muti-Label CNN算法比较的实验结果可以看出,虽然准确率相差不大,但进行语义扩展改善后的算法比多标签排序策略的深度卷积神经网络的召回率提高了16%,改进效果明显.这是由于当待标注图像Ii与训练集Ij视觉相似度越高时,图像Ij与Ii拥有的共同标签数越多,标签贡献值越大,支持度更高;由于图像集Ik是根据图像底层特征搜索降序而得,并且同时考虑了底层特征与高层语义的相似性,兼顾近邻语义对标注结果的影响,从而避免某些标签过少或过多,改善标注结果,丰富图像的语义内容. 为进一步说明语义改善的有效性,表5给出了部分图像的标注实例.表5中第二列为图像的初始标签,即图像的不完备标注词,第三列为初始预测标签概率直方图,表中第四列为本文方法改善后的标注标签结果.其中,标粗的为正确预测且标注的标签词,未标粗标注词为图像中不涉及但被本文方法标注的标签词. 表5 标注实例展示Table 5 Annotation instances 从表5中可以看出,在初始标签预测阶段,本文方法可以利用卷积神经网络准确识别图像中某些具体的内容,并且在最终预测标签列中产生出的Top-5标签,都能够很好的反映像内容,对图像语义进行完备,但若仅利用深度模型按照单目标个体标注图像,显然是是不合理的,不能更好的反映图像内容.实际生活中,每幅图像含有多个目标,具有多个语义标签,会由一些标签产生相关的派生标签词汇,而深度学习网络并不能很好的学习这一语义的底层特征,造成标签标注不完备.比如,在第二幅图中,能反映图像的场景抽象标签“party”不存在于图像内容之中,但利用概念格提取标签相关性,改善图像标签标注后,能够扩展图像标签语义内容.总的来说,利用深度网络获取初始标签,可以有效地提高初始标签的准确率,改善人工标注耗时长的问题,避免复杂的特征融合过程,再结合概念格处理标签相关性,能有效地改善标注结果.但从第三幅图像的标注结果来看,不仅存在“horse”,与此同时被标记上“cow”,两者虽相关性较高,但图中未出现“cow”这一具象物体,由此,我们可以看出,利用概念格提取标签相关性,虽能扩展图像标签语义内容,但可能会存在标注过度的现象.因此,若能进一步利用概念格细化粒度分析图像与标签正负相关性,去除标注结果中的噪声标签,将对图像检索、图像标注有很大的改善效果. 本文提出一种基于CNN和概念格语义扩展的图像完备方法.通过构建CNN通用模型获得待标注图像的初始预测标签并获取图像底层特征,在此基础上构造概念格对图像语义标签扩展,有效地丰富图像标签语义信息,改善标签召回率.通过将改善后的模型结果与传统的CNN标注结果对比,证明概念格能有效扩展图像标签语义内容;通过对比传统标签传播算法通用的评价指标,验证本文方法对提升标签召回率的有效性.本文下一步的工作是利用概念格细化粒度并结合图像与标签正负相关性分析图像的标签语义,减小不同模态(图像视觉-语义标签)的距离,进一步提高图像完备标注精度.3.3 标签预测
3.4 算法描述
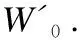
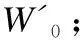
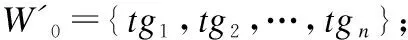
4 实验结果与分析

4.1 性能评价指标
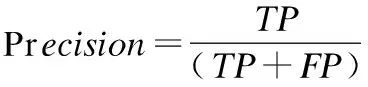
4.2 基于不同深度模型在不同数据集的标注准确率比较

4.3 概念格语义扩展改善的实验结果与分析
4.4 基于数据集Corel5k的实验结果与分析
4.5 标注实例
5 结 论
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
现代语文(2016年21期)2016-05-25 13:13:44
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
大连民族大学学报(2015年2期)2015-02-27 08:28:11
