
基于改进LeNet-5网络的车牌字符识别
2020-08-25 06:41张秀玲魏其珺周凯旋董逍鹏
沈阳大学学报(自然科学版) 2020年4期
张秀玲, 魏其珺, 周凯旋, 董逍鹏, 马 锴
(燕山大学 河北省工业计算机控制工程重点实验室, 河北 秦皇岛 066004)
随着计算机图像识别技术的发展,智能交通系统中车牌识别越来越重要,其主要包括3方面的内容:车牌定位、字符分割与字符识别,受光照或者图片变形的影响,其中难度最大的是对车牌字符的识别[1-2].中国车辆牌照字符包含英文大写字母、阿拉伯数字及省份汉字简称[3].国内外对字母和数字的识别研究现在已经相对成熟,但是中文字符相对于字母和数字具有复杂性和多样性,因此识别车牌的中文字符难度较大[4].
学者对车牌识别已经有了很广泛的研究,在文献[5]中用模板匹配的方法,对图片的像素要求较高.文献[6]中支持向量机的方法适合于小样本识别,但进行大样本识别时识别率不高.文献[7]用改进的BP神经网络来实现车牌的字符识别,有很强的自适应性和较强的鲁棒性,对车牌字符的识别率有一定的提高.在文献[8]中用交叉视觉皮质模型法识别车牌字符,方法简单模型小,识别率约为96%.文献[9]用神经网络对单个汉字进行识别,网络结构简单,但识别率还有待提高.
传统的车牌字符识别是用模板匹配和BP神经网络等方法进行识别,近年来由于卷积神经网络不用对图像再进行复杂的预处理,可以对复杂的图像自动提取特征和分类,因此卷积神经网络在图像识别方面应用越来越广泛[10-11].卷积神经网络是一种前馈神经网络,网络层数越深,提取到的特征越多越抽象,本质是从输入到输出的映射,它的主要特点包括局部感受野、权值共享以及下采样[12].卷积神经网络相邻两层之间神经元通过权值共享使其具有更少的网络连接数和权值参数,极大降低了模型学习的复杂度,使训练过程变得更容易,收敛速度较传统网络更快[13].提高卷积神经网络的识别精度对于很多实际应用来说有非常重要的意义.
本文在传统的LeNet-5网络原结构上运用深度学习的模块对传统网络结构进行加深加宽,加BN层和Dropout优化网络,用全局池化替换全连接层,大大提升了图像特征提取的有效性,同时也提高了运算速率.经过实验验证,改进后网络的识别精度和识别速度都有明显的提高,达到预期效果.
1 LeNet-5网络及其改进
LeNet-5网络作为一个非常经典的神经网络模型,最早被应用于手写数字的识别,是一种前馈式神经网络.传统的LeNet-5网络一共有7层,有2个卷积层、2个池化层、3个全连接层,每层都含有大量可以训练的权重参数[14].直接用传统LeNet-5网络车牌字符识别,发现网络需要训练较长时间才能收敛,网络损失值较大.原因如下:
1) 与手写数字相比,车牌图片受光照情况和复杂背景等因素影响有噪声,原网络层数较浅,用原网络提取的特征个数少,不足以有效识别车牌字符;
2) 手写数字只有10种,车牌字符含有汉字,结构比较复杂,原网络识别神经元少,提取特征不够;
3) 原网络中有3个全连接层,参数比较多,极大的导致网络训练速度慢,收敛慢.
1.1 对传统LeNet-5网络结构进行改进
针对前文所述情况对传统的LeNet-5网络进行改进.
1) 使用卷积 Inception-SE模块代替原网络中第3层卷积层和第5 层全连接层.Inception结构有优良局部拓扑结构性能,可以对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个比较深的特征图.在提取到目标更多丰富特征的同时,增加网络深度和宽度.卷积核的选取关系到能否提取到有效特征,经过实验论证,5×5的卷积核用2个3×3卷积核代替效果更好,所以调整卷积核大小,在 Inception-SE模块里用2个3×3卷积核代替一个5×5卷积核.改进后网络中包含多个卷积层,网络深度明显增加.
Squeeze and Excitation(SE)块是一种非常有效的门机制,对通道关系进行建模,可以有效地增强整个网络中模块的表示能力,增强有效特征的表现能力,并且抑制无效特征.Squeeze的含义是压缩,在Squeeze过程中是将原来的特征维度进行压缩,输出的维度相匹配于输入的特征通道数.2个全连接层建模通道的相关性,构成了Excitation过程.在整个SE模块中是先把输入的特征维度降低,再经过激励函数激活,通过全连接层又回到原来的维度.Inception-SE模块的结构如图1所示.
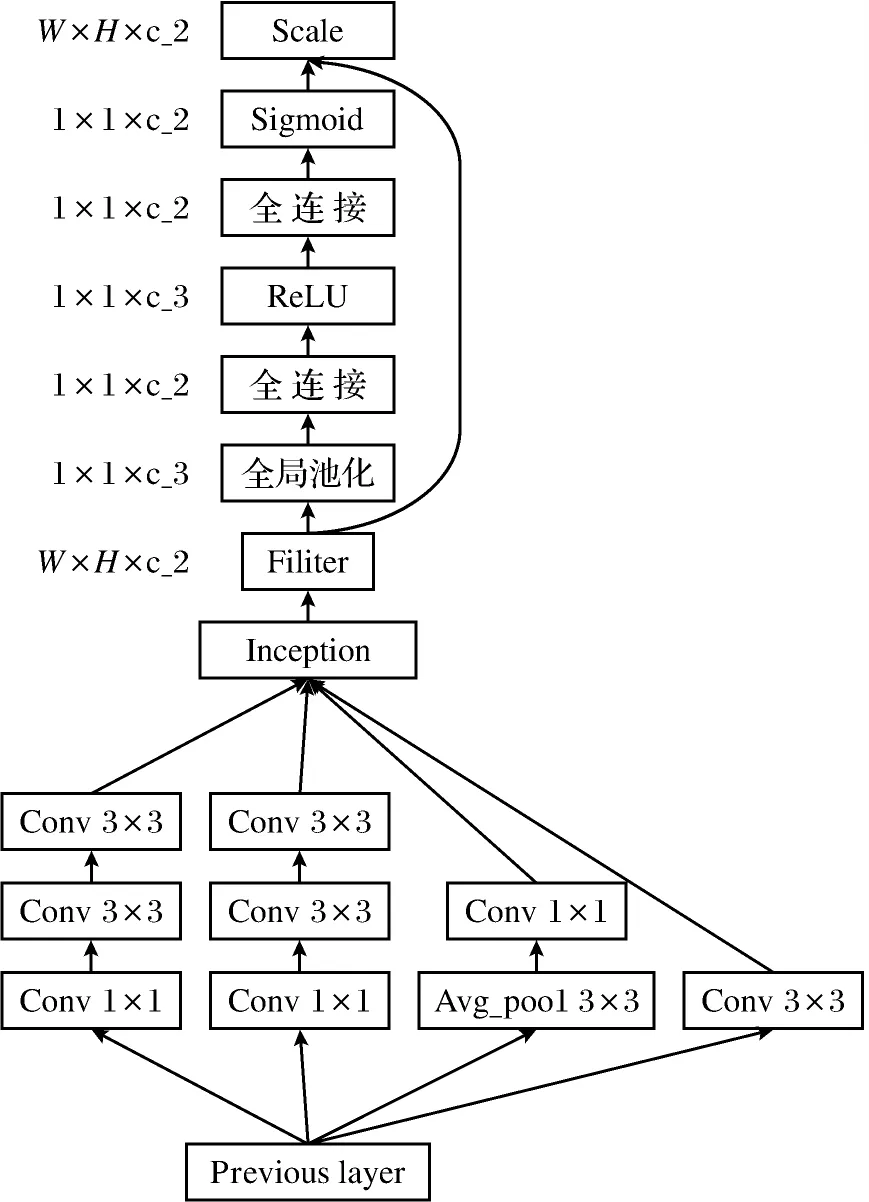
图1 Inception-SE模块结构Fig.1 The module structure of Inception-SE
2) 使用BN层和Dropout. 随着网络层数加深需考虑过拟合情况, 神经网络各层输出经过层不同的内操作差异会逐渐增大影响实验效果. 对每层样本做归一化处理, 可以改善神经网络的输入, 在一定程度上可以提升网络训练速度, 防止过拟合和梯度弥散, 优化网络. 在每一层卷积层后加Dropout可以在训练时忽略一部分特征感测器, 使网络有更好的泛化性, 也可以提升网络速度.
3) 全连接层常在网络结构后面,对前面的特征进行加权然后分类.大部分情况下全连接层参数是网络中最大的,运行耗时很长.经过多次论证,用全局池化层(global average pooling,GAP)代替全连接层可以融合学到的深度特征.本文采用softmax损失函数来指导学习过程,将多个标量映射为一个概率分布.改进减少了参数,提升了网络训练速度,也可防止过拟合.
根据以上内容,传统LeNet-5网络原结构图和改进后网络结构图如图2所示.
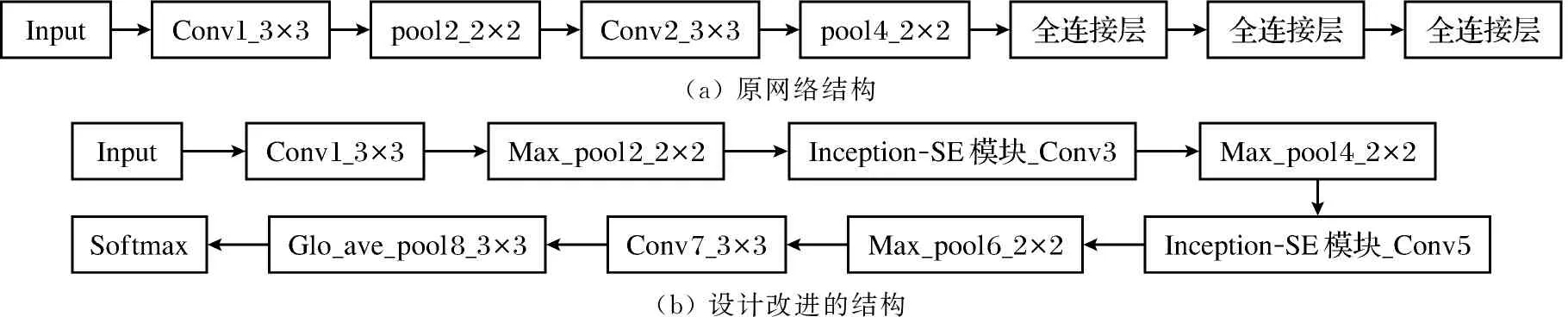
(a) 原网络结构(b) 设计改进的结构
1.2 改进后LeNet-5网络的结构描述
第0层为输入层,输入分割好的车牌字符图片,尺寸为28×28的图像.各网络层卷积池化卷积核尺寸和在该层的特征图尺寸参数如表1所示.在所有的卷积层中,卷积核滑动步长均为1,本实验中用的卷积核激活函数是Relu函数,Relu函数网络的稀疏性比较好,减少了参数的相互依存关系,它相较于原sigmoid激活函数可以非常多的减少训练时间,过拟合问题的发生可以得到缓解.在第1层卷积层Conv1中有96个卷积核,经过第1层得到96个28×28的特征图.第3层和第5层为整体的Inception-SE模块层,每个模块有4个分支.网络第3层模块中分支1有3个卷积层,卷积核个数分别为32、64、64;分支2有3个卷积层,卷积核个数分别为16、24、24;分支3有1个平均池化层和1个卷积层,有16个卷积核,分支4只有1个卷积层包含24个卷积核.网络第5层模块结构和第3层模块结构相同,分支1卷积核个数分别为64、96、96,分支2为48、64、64,分支3有32个,分支4有24个.
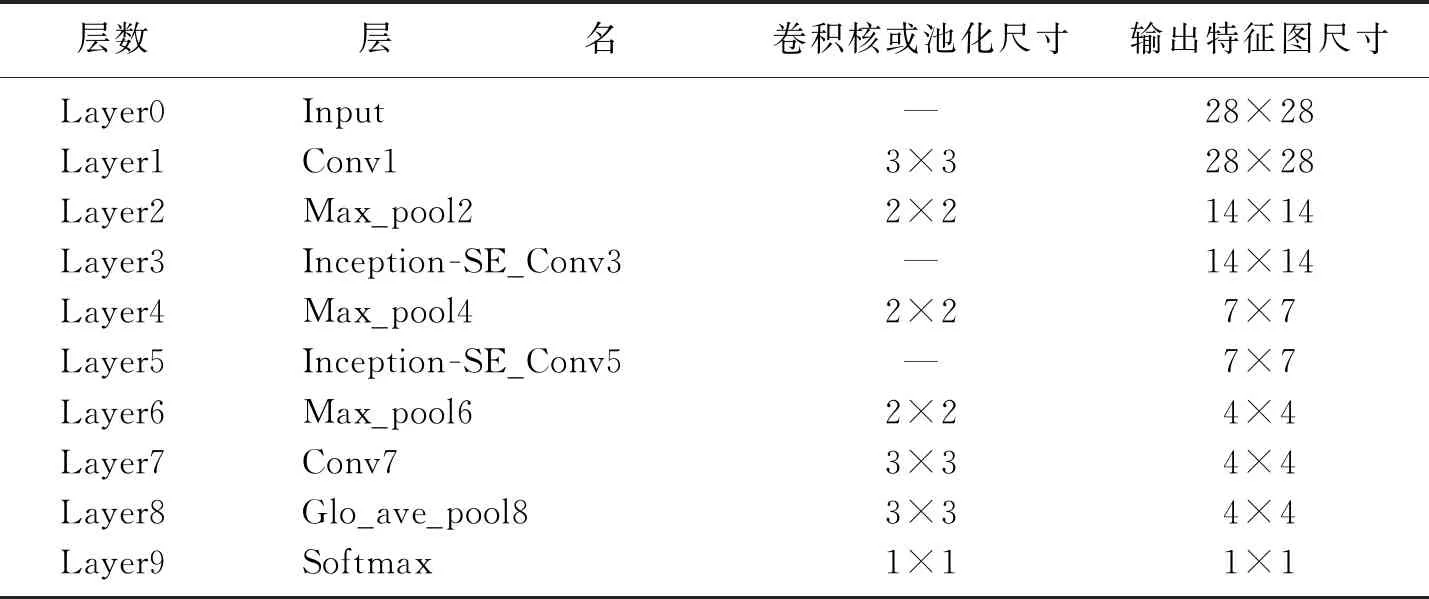
表1 改进后的网络结构Table 1 The improved network structure
1.3 改进后LeNet-5网络的算法
整个网络的训练过程分为正向传播和反向传播.正向传播过程是卷积层和池化层提取特征的过程,反向传播用来传递误差,使用随机梯度下降,更新权值参数来调整整个网络.
正向传播主要运算如下.
卷积层的运算为
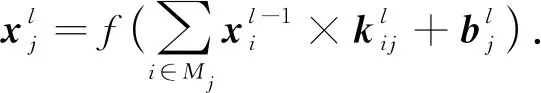
(1)
式中:k表示卷积核;l是层数;Mj代表第j个特征图;b代表偏置项.
池化层的计算为
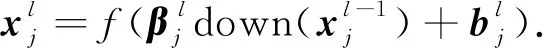
(2)
式中:down(·)表示下采样函数;β分别对应每个输出的特征图;b代表偏置.
提取的特征在Inception-SE模块中,除了前面的卷积和池化过程外,Squeeze and Excitation过程计算公式为
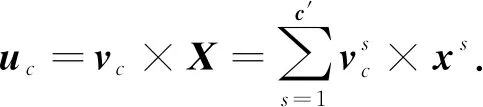
(3)
式中:uc表示c通道的二维矩阵;c是通道;vc表示第c个卷积核;xs表示第s个输入.
式(4)中zc是squeeze得到的结果,W,H表示压缩后特征图的尺寸,经过sigmoid函数,得到式(5)权重sc.
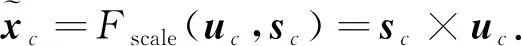
(6)
反向传播算法根据定义好的损失函数取值,从而达到优化训练网络,减小损失函数的目的.主要是使式(7)结果达到最优.
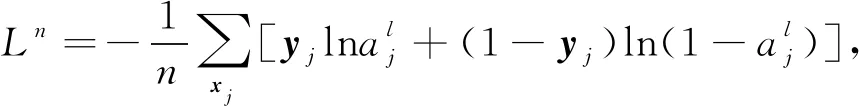
(7)
式(7)为常规的交叉熵的表达式,L表示最后的损失函数值,yj表示经过正向传播最后的实际输出,aj表示经过rule函数的输出,表征了当前样本标签为1的概率.
2 改进LeNet-5网络的车牌仿真实验
2.1 实验环境及所用数据集
本实验在Linux系统下的Keras2.0.9深度学习平台上进行.处理器为Intel Core i7-6850k,主频3.2 GHz,内存32 GB,显卡为GeForce GTX1080TI.
所用数据集为从网络上搜集车牌图片,对图片进行切割得到5 300张28×28车牌字符数据,使用过程中,为了避免出现过拟合情况,对数据进行旋转、平移等泛化数据处理,数据集扩增至10 400张,分类后有7 800张训练集,1 300张测试集,1 300张验证集,都包括字母、数字和汉字.由于车牌图片受光照不均匀、倾斜程度不同等影响,对原始样本字符切割之后,对切割好的字符图片进行归一化处理,减少外部光照等因素对识别效果的影响.车牌图片如图3(a)所示,切割归一化后车牌字符图片如图3(b)所示.
2.2 结果分析
2.2.1 网络识别率比较
神经网络模型训练时需要设置学习率来控制参数更新的幅度,如果幅度过大,会致使参数在极优值的两侧来回浮动,参数过小时,虽然能保证收敛性,但会影响优化速率,本实验设定0.1的学习率能保证收敛性和优化速率.在训练前期网络不稳定,需要调节迭代次数确定网络收敛的迭代次数.每一次的采样数据也需要通过实验调整来达到更好的识别效果.通过实验证明改进后的网络进行600次迭代训练收敛,未改进的网络需要900次迭代训练收敛.原网络和改进后网络对车牌数据经过900次迭代后识别精度和loss值对比图见图4,图5为改进后LeNet-5网络的测试结果图.
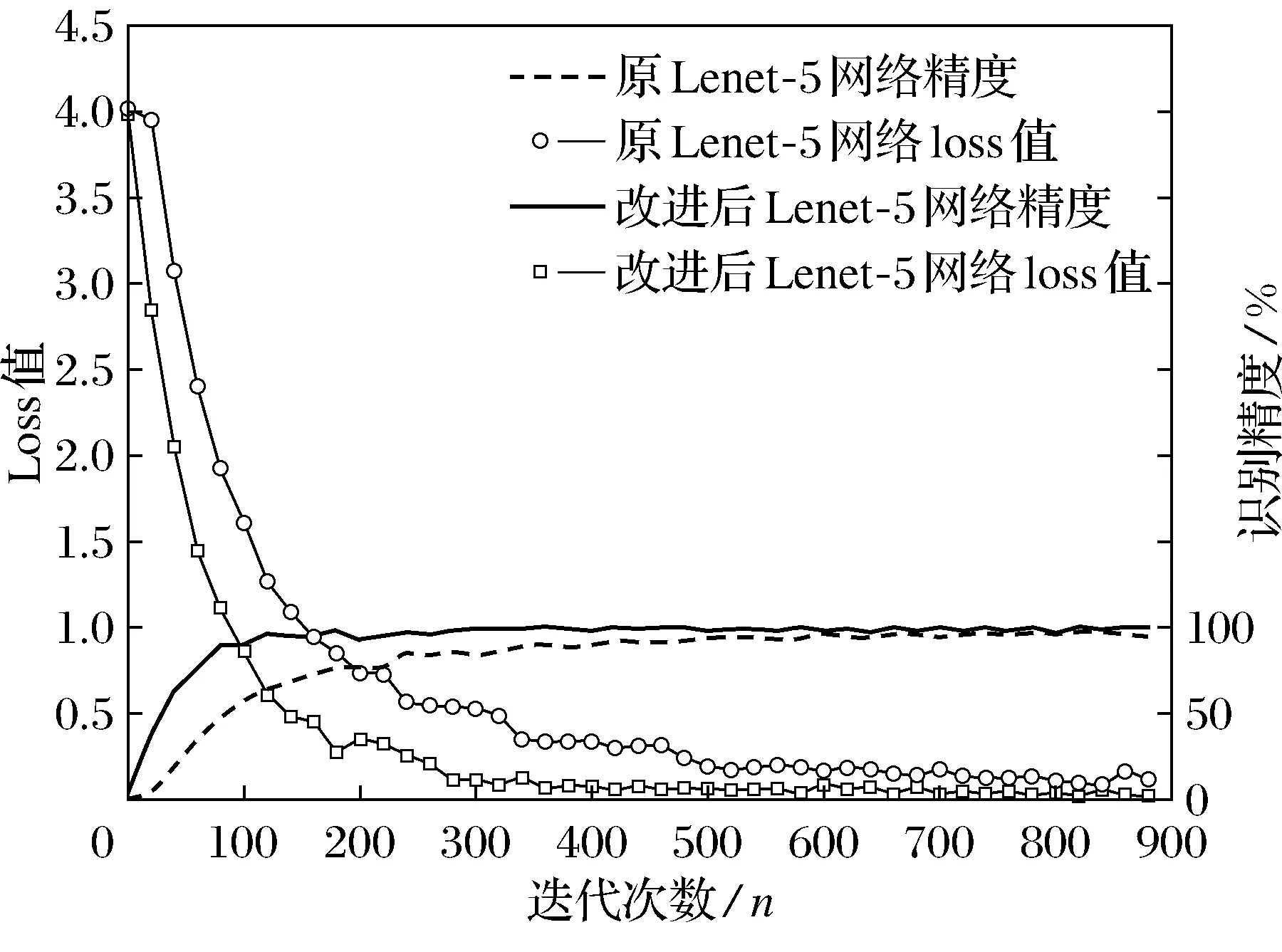
图4 改进网络和原网络训练结果对比
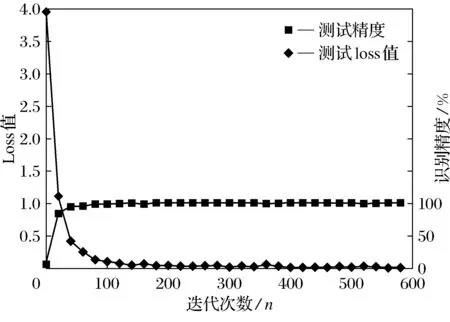
图5 改进后的网络测试精度Fig.5 The test accuracy of improved network
从图4中可看出100次迭代之前,识别精度和损失函数值都有大幅度变化,从100次迭代之后开始缓慢变化,从精度曲线和loss曲线对比明显看出改进后的网络精度上升更快,loss值下降的更快,说明改进后的网络具有更好的识别效果.
从图5可以看出,测试结果和训练结果相差不大,说明网络不存在过拟合情况,网络有良好的鲁棒性.测试数据集样本少,识别速度更快.
改进后网络和原网络的识别精度和网络收敛时间对比如表2所示,可以明显看出改进后网络识别精度提升,很大程度上降低了网络的损失值,识别时间比原时间缩短了一倍.实验结果表明,改进后的网络在识别精度上较原网络提高了1.71%.
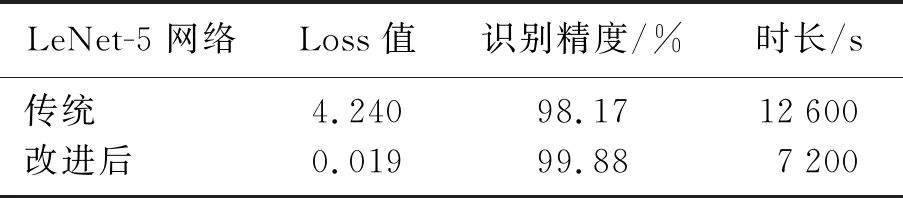
表2 改进前后的网络精度和时长对比
2.2.2 对于汉字和字母数字的识别精度比较
在当前车牌字符识别研究中,由于汉字的结构复杂,所以识别起来难度较大.为了进一步验证本文网络对于汉字的识别效果,用本文网络和最常用的车牌字符识别方法对汉字和数字字母分别做了对比识别.模板匹配法和BP网络是最常用的车牌字符识别方法.其中本文网络每次采样200张图像,共进行600次迭代训练.各方法得到的字符识别精度如表3所示.由表3可以看出,本文网络对于汉字的识别精度高于其他方法的识别精度,各种方法对字母和数字的识别精度均高于对汉字的识别精度.
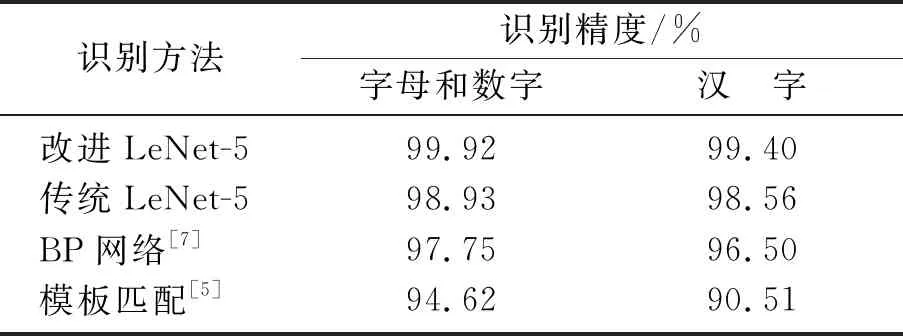
表3 字母、数字和汉字的识别精度
2.2.3 改进后的网络中SE模块的识别效果
SE模块属于soft attention机制的一种,是从特征重标定的角度提高模型的识别效果.它通过学习的方式自动获取每个特征通道的重要程度,依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征,根据loss去学习特征权重,让有效特征的权重大,无效或效果小的特征权重小.为确认SE模块对网络的改进效果,对改进网络进行加上和去掉SE模块进行实验,实验结果如表4所示.从表4看出有SE模块识别精度提升了0.66%.可见SE模块对于网络改进发挥了很大的作用,有效提升了网络的识别精度.
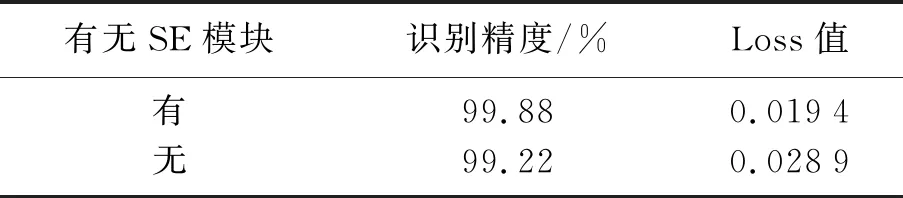
表4 改进后网络中关于SE模块的识别效果
2.2.4 改进网络中最优精度的Dropout值
Dropout是网络在训练过程中关闭一部分神经元,可以增加泛化能力,提高精度.不同的Dropout值在网络中达到的效果不同,过高或者过低都会造成网络训练精度和验证精度差别很大,导致网络效果欠佳.对Dropout设置不同的值运用到改进网络中,不同值的识别精度如表5所示,由表5看出,在Dropout值为0.3时,本文改进网络达到精度最优.
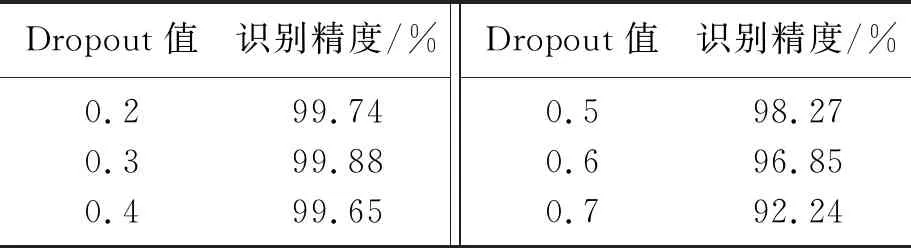
表5 不同Dropout值的识别精度Table 5 Recognition rate of different Dropout value
3 结 论
本文对卷积神经网络LeNet-5用于车牌字符识别进行了研究,并对传统的卷积神经网络LeNet-5进行了改进.研究结果表明,Inception-SE卷积模块加深加宽了LeNet-5网络的卷积层,丰富了提取的特征,识别精度比原网络有了很大提高.使用BN层和Dropout很好地优化了网络,避免了出现过拟合的情况.采用的全局池化层代替全连接层极大的提升了识别时间.实验结果说明对原网络改进有效.通过实验发现对于汉字的识别难度确实比字母数字大,汉字识别精度有待进一步提高.通过对改进网络有无SE模块进行实验,发现SE模块从特征提取方面可以很大程度提升网络精度.另外Dropout值的大小对于网络精度也有很大影响,在本文网络中0.3最佳.本文实验是对网络结构进行了改进,图像的识别精度还可以进一步提高,下一步的研究方向是对网络的损失函数的改进,有待进行进一步的研究.
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
集美大学学报(自然科学版)(2021年2期)2021-04-29
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
