
基于Django 的汉维地址翻译网络服务的设计与实现
2020-08-19 06:18:34斯拉吉艾合麦提如则麦麦提艾山吾买尔张济民汪烈军刘胜全
现代计算机 2020年19期
斯拉吉艾合麦提·如则麦麦提,艾山·吾买尔,张济民,汪烈军,刘胜全
(1.新疆大学信息科学与工程学院,乌鲁木齐 830046;2.新疆大学新疆多语种信息技术实验室,乌鲁木齐 830046)
0 引言
命名实体(Named Entity,NE)是指具有特定意义的实体,主要包括人名、地名、组织机构名、时间日期、地址、量词表达式等,表达文本的关键部分,承载着文本的重要信息。因此,机器翻译中命名实体的准确翻译对译文整体质量具有十分重要的影响[1]。命名实体翻译对跨语言信息检索具有十分重要的作用[1-2],命名实体的识别[3]与翻译等相关技术是目前自然语言处理领域的一个研究热点。
命名实体具有一定的组成规范,部分实体变化较大,而且不断出现新的词汇的部分,有些实体在语料中很少见,这使得机器翻译中出现严重的未登录词(Out-Of-Vocabulary,OOV)问题,给翻译任务带来了极大的难度。命名实体翻译对准确性和规范性有较高的要求。由于命名实体翻译有其自身的特点,实体翻译与句子翻译之间存在着很大的差异,因此,很有必要将命名实体翻译作为一个独立于句子翻译的问题进行研究。
地址翻译在学术上可以归结为命名实体翻译任务[4]。文本地址信息一般由几个基本地址单元组成,结构相对比较规整,通常情况下地址单元可以是一个地名、机构名或者地名追加地址辅助信息。作为命名实体的一部分,学者们对地址翻译已经开始开展相关的研究。苗等人[5]提出了一种面向机器翻译的机构地址切分方法,在地址翻译领域中得到了很好的效果。对于地址与机构名翻译,李等人[6]提出了一种先切分,再翻译,最后调序的方法,在地址翻译中取得了不错的效果。哓等人[7]定义与归纳了邮政信函上的地址信息,提出了一种非精确字符串匹配技术的自动地址翻译方法。于等人[8]提出了一种规则与统计相结合的中文地址翻译方法,并取得了较好的效果。
随着深度学习的快速的发展,基于神经网络的机器翻译方法有了长足的进步[9],国内外学者们开始使用神经网络对命名实体进行翻译[10-11]。本文使用完全注意力机制的神经机器翻译模型Transformer 来搭建汉语-维吾尔语地址翻译模型,设计与实现了基于Django的网络服务接口,并使用UWSGI+Nginx 来负载均衡提高并发量。本文分别提供了维吾尔语-汉语通用文本翻译服务与汉语-维吾尔语文本地址翻译服务。为了方便演示,设计与实现了基于Django 的汉语-维吾尔语地址翻译在线系统及页面。
1 相关模型及工具
1.1 机器翻译模型
神经网络翻译模型[12]自提出以来,在多个语言对上的表现显著地超过了统计机器翻译模型,成为当前主流的翻译模型[9,13-14]。本文使用哈佛大学自然语言处理研究组开源的OpenNMT[15]工具进行完全注意力网络的神经机器翻译模型Transformer[16]来训练汉语-维吾尔语地址翻译系统。
Transformer也是由编码器和解码器两个部分组成。编码器由一个多头注意力网络和一个简单的全连接前馈神经网络组成,中间添加了残差连接,共有6层,每一层之间进行层标准化操作。解码器是由两个多头注意力网络和一个全连接前馈网络组成,同样是6层,也有残差链接和层标准化操作。
Transformer 模型里面的多头注意力由多个缩放点积的注意力组成,缩放点积注意力计算公式如式(1)。
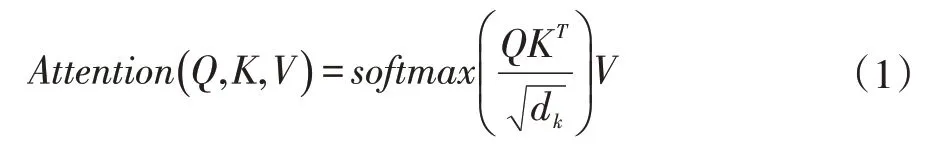
首先使用Query-key 向量通过相似度计算得到权重,除于缩放因子然后用Softmax 函数对权重归一化,最后乘以V,作为注意力向量。
多头注意力机制计算公式如式(2)和(3),给定(Q,K,V),首先使用不同的线性映射分别将 Q、K 和 V 映射到不同的空间,然后使用不同的注意力网络计算得到不同的空间的上下文向量,并将这些上下文向量拼接得到最后的输出。
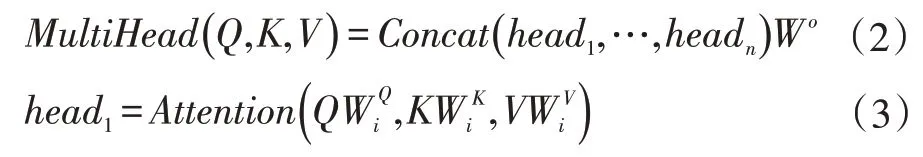
对一个序列到序列的问题来说,序列的顺序是一个很重要的信息。Transformer 使用了位置编码的方法,将编码后的向量与词嵌入进行求和,加入了相对位置信息。计算位置编码的公式如式(4)和(5):

其中,pos 指词语在序列中的位置,dm odel是词向量维度。
Transformer 模型在摒弃了传统的CNN 和RNN 网络,表现更好的性能,可并行化,速度更快,同时能提升翻译质量。
1.2 Django Web框架
Django 是基于Python 语言的开源Web 应用框架,发布于2003 年。Django 框架内部各个模块联结紧密,遵循 MVC(Model,View,Controller)设计规范,可以避免重复代码。Django 简单易学,具有很强的扩展性,具有模板系统以及强大的自带后台系统,是目前最受欢迎的Web 框架之一。
Django 采用MTV 的框架模式,其中M 表示模型(Model),与 MVC 中的 M 功能相同,映射业务对象,负责和数据库交互,进行数据处理;T 表示模板(Tem⁃plate),与MVC 中的V 功能相同,负责封装构造要返回的HTML,将页面展示在浏览器上;V 表示视图(View),与MVC 中的C 功能相同,负责接收请求,进行业务处理,返回应答,模型和业务之间协调业务逻辑关系。Django MTV 结构图如图1 所示。
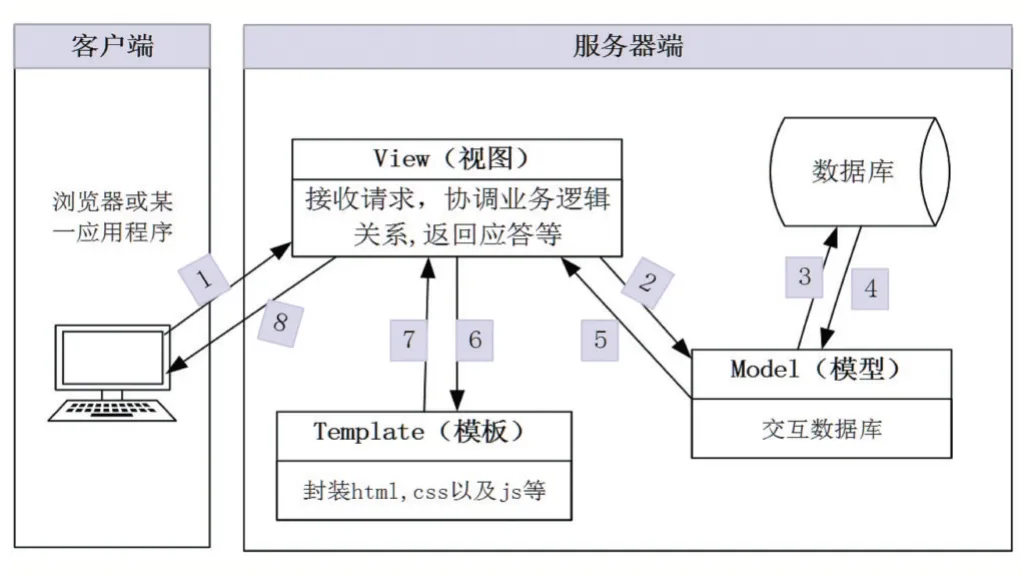
图1 Django MVT结构图
1.3 UWSGI 与Nginx服务器
UWSGI 是一个全功能的 HTTP(HyperText Trans⁃fer Protocol)服务器,实现了 WSGI(Web Server Gateway Interface)的所有接口,是一个快速、自我修复、开发人员和系统管理员友好的Web 服务器。主要作用是把HTTP 协议转化成语言支持的网络协议。
Nginx 是一款高性能的HTTP 服务器,反向代理Web 服务器,服务器功能和UWSGI 功能很类似,但是Nginx 还可以用作更多用途,例如,通过反向代理,可以拦截一些Web 攻击,保护后端的Web 服务器;可以负载均衡,分配请求到多节点Web 服务器;也可以缓存静态资源,加快访问速度,释放Web 服务器的内存占用。Django、UWSGI 与Nginx 之间的关系及工作流程如图2 所示。
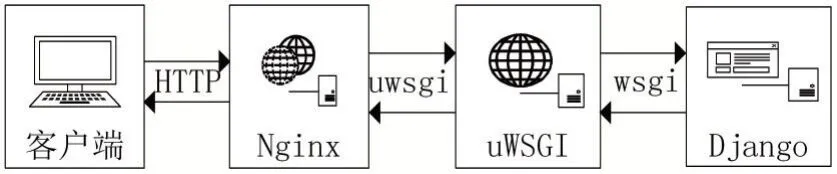
图2 Django+UWSGI+Nginx工作流程
2 设计与实现
2.1 系统整体架构
本文研究工作以Python 编程语言编写,翻译模型以PyTorch 深度学习框架搭建,由于神经网络机器翻译系统模型与结构复杂,参数庞大,使得翻译速度变慢并且系统难以并行化。针对此问题,本文以Django +UWSGI+Nginx 架构设计实现了地址翻译网络服务,使得让系统同时处理多个请求,从而翻译速度与并发量两个方面达到较好的工程要求。本文所设计的整体系统框架如图3 所示。

图3 系统整体框架图
具体的,首先Nginx 服务器接收到客户端(一般是浏览器或某种应用)发送过来的HTTP 请求,将参数包进行解析,如果是静态文件请求就直接返回用户请求的静态文件。如果是一个动态的请求,那么Nginx 就将请求发个UWSGI,UWSGI 接收到请求后将参数包处理成WSGI 可以接受的格式,并发给WSGI,WSGI 根据请求调用应用程序的某个文件(一般是Django 里面的view.py 文件)里面的某个函数,最后处理完将返回值再次交给WSGI,WSGI 将返回值打包,打包成UWSGI 能够接收的格式,UWSGI 接收WSGI 发送的请求,并转发给Nginx 代理,Nginx 最终将返回值返回给客户端。
2.2 汉-维地址翻译接口说明
本文研发的系统是基于web 的网络服务接口,接口说明以及调用参数对使用者很重要,下面详细介绍汉维地址翻译服务接口的调用参数、调用示例以及服务接口的返回结果。具体的,接口调用参数信息如表1所示,接口调用示例如表2 所示,接口返回示例如表3所示。
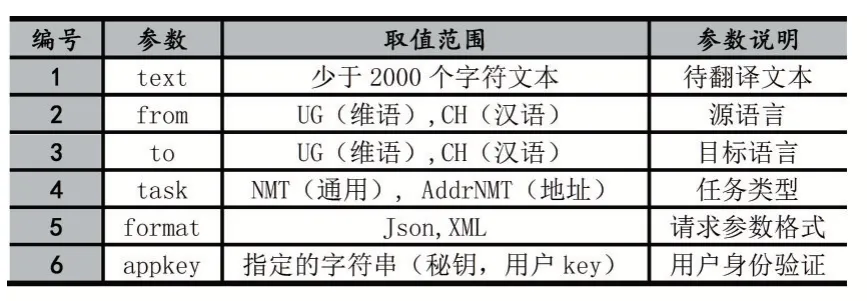
表1 接口调用参数表
其中text 表示带翻译文本,from 与to 分别是源语言和目标语言语种,appkey 是用户秘钥,format 是输入参数格式,task 参数表示为任务类型,用户根据需求可以选择使用通用的机器翻译模型(NMT)或者是地址翻译模型(AddrNMT)。

表2 接口调用示例表

表3 接口服务返回示例表
服务接口返回结果中,text 表示模型翻译结果,code 参数是本次请求的状态,通过code 代码可便于发现错误原因,不同的code 代码有不同的含义,如果code 是200 表示当前请求成功,如果是0 说明接口服务内部出现异常,如果是500 表示服务器内部错误等。
2.3 系统演示
另外,为了方便演示本文设计了在线地址翻译页面,系统效果如下图4 所示。
系统页面功能解析:
上侧框:输入待翻译文本;
中间部分:用户根据自己的需求可以选择模型以及翻译语言方向等;
下侧框:显示翻译结果。

图4 汉维地址翻译页面
系统工作流程:
(1)点击翻译按钮以后客户端将待翻译的文本以及用户所选择的内容打包JSON 格式请求发送给Web服务接口;
(2)服务端解析用户请求之后把待翻译内容传给翻译模型;
(3)翻译模型经过大量的计算将文本内容进行翻译并把结果返回给客户端。
3 实验
3.1 实验环境
本文实验在Ubuntu 18.04 操作系统上进行,硬件环境为Intel Core i5-9400F CPU @ 2.90GHz 处理器,2块 NVIDIA GeForce RTX 2080 Ti(11GB),32G 内存以及500G 硬盘。使用的软件环境有Ubuntu 18.04 版本的 64 位操作系统,Python3.6、PyTorch1.0、Django3.0、uwsgi2.0.15 以及Nginx1.12.1 版本。地址翻译模型使用OpenNMT 工具,通过Transformer_base 参数在单个GPU 卡上训练。
3.2 实验结果与分析
为了更正确的测试本文汉维地址翻译服务接口并发量以及相应速度两个方面的性能,本文利用2000 条文本地址对接口进行多线程测试。为了更全面验证,分别测试三次,最后将三次的相应时间与成功次数求平均。主要的测试结果如表4 所示。其中,成功次数是指请求成功的个数,相应时间是接口所花费处理所有请求的时间,每秒翻译个数是指平均每秒处理的地址文本个数。

表4 汉维地址翻译服务接口测试结果
表4 的实验结果可以看出系统具有比较稳定的速度和并发量,当线程数量分别 1,16,64,128 的时候没有数据包丢失的情况,而随着并发量的继续增加系统出现丢失数据包的情况,线程数量为200 每批1 个句子的时候平均丢失了20 个请求包。从平均每秒翻译的句子个数来看:单线程每批翻译一个句子的时候平均每秒翻译的句子个数为3.78 个;当线程数量128,每批50 个句子的时候平均每秒翻译个数为46.03;当线程数量200,每批50 个句子的时候平均每秒翻译个数为44.40。这说明系统不丢失数据的情况下并发量128左右,每批50 个句子的时候达到比较好的结果。由于实验环境的局限性,本文实验使用一台服务器和两张GPU 卡进行的,分析系统的翻译速度和并发量,该项工作具有一定的实践意义。
4 结语
本文使用PyTorch 深度学习框架与OpenNMT 工具构建了完全注意力机制的汉维地址翻译模型,并使用简单易学的Django Web 框架编写网络接口,然后通过一款优秀的Web 服务器UWSGI 和轻量级反向代理服务器Nginx 来实现负载均衡,最终实现了Django +UWSGI+Nginx 架构的稳定并具有并发量的汉维地址翻译服务接口。由于实验环境的局限性,本文只用一台服务器进行实验,但是实际应用中模型翻译质量、速度以及并发量要求更高,未来将进一步对地址翻译任务模型与工程方面进行更深入的探索。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
