
基于两阶段特征选择的医疗敏感文本分类
2020-08-12 02:35:04陈春玲姜慧敏郭永安
计算机技术与发展 2020年8期
陈春玲,姜慧敏,郭永安
(1.南京邮电大学 计算机学院、软件学院,江苏 南京 210023; 2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
随着医疗信息化,对医疗大数据的深入分析研究,大量的医疗数据不仅是对医疗过程的记录,还被用于深入地进行数据挖掘和分析,从中总结出这些数据的隐藏价值,促进医学技术的发展,提高医疗检测系统的有效性[1]。但是,医疗大数据使用过程中出现的问题也不容小觑。对于医疗信息,一方面通过对医疗信息数据的挖掘,对病症的诊断、治疗、药物开发、临床试验、发现疾病等提供科学决策具有重要意义。但在另一方面,在数据对外发布使用之前,如果病人的数据被完全泄露,可能会侵犯到病人的隐私,甚至由于数据的泄露,个人数据信息被随意交易,给病人带来更加严重的影响。冯登国等人[2]对于大数据的隐私保护提出了六种方法,其中包括匿名、数据溯源、访问控制等方法类别。但是这些方法实际上都是对数据进行处理,对数据的路径追踪以及数据权限的访问,而缺乏对源数据的分类的考虑。国内现有的对医疗领域的隐私保护技术[3-4]主要是基于匿名化的医疗数据隐私保护、基于医疗数据加密的隐私保护、基于访问控制的医疗数据隐私保护以及医疗数据的分级保护。文中从对医疗敏感数据的分类入手,以提高后续敏感数据的处理效率为目标进行医疗数据的隐私保护。
传统的医疗文本分类方法,侧重于进行医疗数据的分类管理[5],对如何快速地从医疗数据中分类敏感数据与非敏感数据的研究较少,考虑选择合适的方法对医疗信息进行敏感性分类,对于医疗信息的隐私保护技术的提高具有重要意义[6]。在传统的文本分类方法中,通常只有一个阶段的特征选择,其中使用较为广泛的是基于TF-IDF的特征选择方法。TF-IDF方法是一种利用文档中的术语频率赋予权重进行特征排名的特征选择方法,对于医疗敏感文本,由于其数据结构涵盖了结构化、半结构化和非结构化数据,仅仅考虑术语频率对于特征选择的效率和分类的效果是不够的。考虑到医疗敏感文本的特殊性,在特征选择的过程中,还要考虑特征的降维,以提高分类的准确率,因此需要对传统的医疗文本分类方法进行改进。文中提出的基于LSI-TF-IDF两阶段特征选择的医疗文本分类方法,在特征选择阶段通过连续的两个阶段的特征选取和特征降维,提高分类的准确率,从而达到对医疗敏感文本分类的高效性。
1 传统医疗文本分类
传统的医疗文本分类主要侧重于自由文本分类。文本分类的过程,一般包括四个步骤:文本预处理、特征选择、分类、评估[7]。
第一步中,在读取输入文本文档之后进行文本预处理。此时,文本文档被划分为特征,数据表示中的文本文档则被表示为向量空间,而其组件是该特征及其特征在该文本文档中每个特征的频率所占据的权重。而后对其进行删除非信息特征操作,包括消除停用词、处理分词、文本标记、词干还原等步骤。
第二步中,特征选择的主要作用是减小数据大小,提高预测精度,提取重要特征,轻松理解属性或变量,最终减少执行时间。特征选择的过程可以概括为:对预处理过的文本进行搜索生成特征子集,通过评估产生最好的子集,通过验证方法验证产生的子集是否是最佳子集,若是最佳子集,则达到停止标准;若不是最佳子集,则当达到最大迭代次数时会停止循环。根据特征选择的评估任务,可以将特征选择方法分为两类:基于过滤的方法和基于包装的方法,分类依据按照是否依赖分类器进行划分。具体的特征选择方法包括文档频率(DF)、Pearson相关标准、相关系数、信息增益(IG)、互信息(MI)、χ2统计、期望交叉熵(CE)、文本证据权重(WET)、遗传算法(GA)等[8-10]。
在第三步中,分类器的功能是根据文本文档的内容将其合并为一个或多个预定义的类别[11]。传统文本分类方法来源于模式分类,可以分为三类[12]:第一类是基于统计方法,如朴素贝叶斯、支持向量机(support vector machine,SVM)、K-近邻(K-nearest neighbor,KNN)、Rocchio等算法;第二类是基于连接的方法,如人工神经网络;第三类是基于规则的方法,如决策树、关联规则、粗糙集等。有很多算法用作分类器,但广泛使用的算法(分类器)[13-14]是决策树分类器、SVM分类器、朴素贝叶斯分类器和K-最近邻分类器。
第四步中,由于文本数据被分为测试集和数据集,通过测试集对训练集训练得出的分类器模型进行评估。对训练集和测试集的划分可以通过保持法和K折交叉验证法实现。目前对于文本的分类处理来说,评价的方法和指标包括召回率(recall ratio)、精确率(precision ratio)和F1度量[15]。
传统医疗文本分类是基于TF-IDF特征选择方式仅考虑用文本中的词频进行特征选择,而未考虑到医疗敏感本文数据结构的复杂性,单一阶段的特征选择之后,分类效果并不够理想。不同于传统医疗文本分类的单一阶段特征选择方式,下一节提出的基于LSI-TF-IDF两阶段特征方法,通过连续利用现有特征降维和特征选择方法对文本进行特征选择,对医疗文本进行敏感性分类。
2 LSI-TF-IDF两阶段特征选择的文本分类
基于LSI-TF-IDF两阶段特征选择方法包括两个阶段:第一阶段采用LSI方法,对原始文档进行特征降维;第二阶段采用TF-IDF方法从原始文档中获得权重数字表示,进行特征提取。
潜在语义索引(latent semantic indexing,LSI)[16]是一种流行的线性代数索引方法,通过词同现产生低维表示。LSI的目的是在最小化全局重建误差的基础上,找到原始文档空间的最近似子空间。它基于奇异值分解(singular value decomposition,SVD)并将文档向量投影到近似子空间中,用余弦相似性准确地表示语义相似性[17]。给定一个术语文档矩阵X=[x1,x2,…,xI]∈Rm,假设X的等级为R,对X进行奇异值分解,如式(1)所示:
X=U∑VT
(1)
其中,∑=diag(δ1,δ2,…,δr),且∂1≥∂2≥…≥∂r是X的奇异值。U=[u1,u2,…,ur],ui是左奇异向量,V=[v1,v2,…,vr],其中vi是右奇异向量。
词频-逆文本术语频率(term frequency-inverse document frequency,TF-IDF)是由Sparck Jones[18]提出的IDF演化而来的,TF-IDF认为比起在少数文档中出现的术语,在许多文档中出现的术语,应该赋予更少的权重[19]。TF-IDF术语加权的公式如下:
(2)
其中,wi,j表示文档j中术语i的权重,N是集合中文档的数量,tfi,j是文档j中术语i的术语频率,由式(3)定义,dfi是集合中术语i的文档频率,由式(4)定义。
(3)
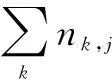
(4)
其中,|D|表示文件总数,|{j:ti∈di}|表示包含词语ti的文件数目(即ni,j≠0的文件数目)。
LSI-TF-IDF两阶段特征选择算法如下所示:
Algorithm:LSI-TF-IDF算法。
1.输入:经过文本预处理后的dataset,存放于文档列表doc_list中
2.输出:返回特征选择词典dict_feature_select
3.根据式(1)计算文档向量矩阵X和查询矩阵Q
4.对矩阵X进行奇异值分解,得到左奇异值U和右奇异值V
5.计算query-document的余弦相似度
6.返回相似度最高的语句sims
7.sims切片存放于词列表list_words中
8.进行词频统计
9.根据式(3)计算每个词的TF值
10.根据式(4)计算每个词的IDF值
11.根据式(2)计算每个词的TF*IDF术语加权
12.对字典值由大到小排序
在两阶段的特征选择中,首先采用LSI方法形成文档矩阵,采用余弦相似性评估文档矩阵,进行数据降维。而后利用TF-IDF方法,对降维后的文档数据中术语频率进行排序,从而完成特征提取。完成特征选择之后,紧接着就是对特征样本进行分类,最后在分类出的敏感样本和普通样本结果上,对其进行评估。因此,LSI-TF-IDF两阶段特征选择算法用于医疗敏感文本分类的流程包括以下五个步骤:文本预处理、LSI特征降维、TF-IDF特征选择、分类、评估。
3 仿真与实验
3.1 数据集和实验方法
实验数据集使用736份糖尿病文本病历样本,对其进行处理,将它分为敏感样本和普通样本。在Pycharm平台上使用,并使用python语言进行设计,中文分词工具是Jieba。在分类器训练部分,分别选择了朴素贝叶斯、KNN和SVM作为文中的分类算法。在特征选择阶段,对基于TF-IDF方法和基于LSI-TF-IDF两阶段特征选择方法进行比较。对于分类结果评估,采用10倍交叉验证法对数据集进行评估。
3.2 评价标准
对于分类结果的评价标准可以通过精确率、召回率和F1值进行评估。
召回率也称为查全率。在文本分类中,正确识别出属于C类的文本数与测试集中实际存在的属于C类的文本总数的比值为分类召回率,公式如下:
(5)
其中,TP表示由分类器正确计算将属于C类的文本判定属于C类;FN表示由分类器错误地将属于C类的文本判定为属于其他类。
精确率也称为查准率。正确识别出的属于C类的文本数与识别出的属于C类的文本数二的比值,为分类精确率,公式如下:
(6)
其中,TP表示由分类器正确计算将属于C类的文本判定属于C类;FP表示由分类器错误地将应属于其他类的文本判定为属于C类。
F1度量是基于精确率和召回率的调和平均,定义如下:
(7)
其中,P为精确率,R为召回率。
3.3 实验结果
实验通过对糖尿病文本数据进行敏感样本分类,基于TF-IDF的传统文本分类方法的实验结果以及评价标准比较分别如表1和图1所示,基于LSI-TF-IDF的两阶段文本分类方法的实验结果以及评价标准比较分别如表2和图2所示。
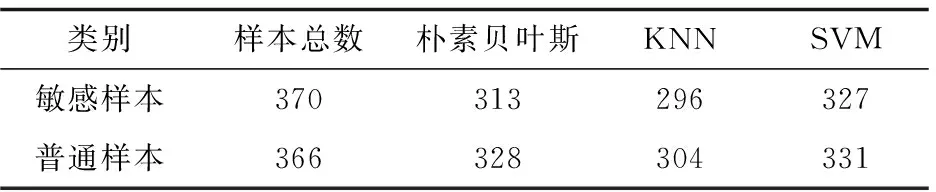
表1 基于TF-IDF的分类结果

表2 基于LSI-TF-IDF的分类结果

图1 基于TF-IDF的医疗敏感文本分类
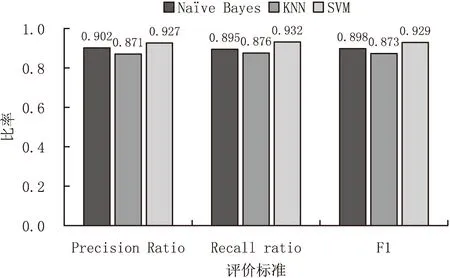
图2 基于LSI-TF-IDF的医疗敏感文本分类
3.4 实验分析
由表1和表2对比显示,在经过连续两阶段的特征降维和特征选择后,正确分类出的敏感样本数目有所增加,对于朴素贝叶斯分类器,正确分类的敏感样本数由313份增加到331份;对于KNN分类器,正确分类的敏感样本数由296份增加到324份;对于SVM分类器,正确分类的敏感样本数由327份增加到345份。
由图1和图2对比显示,对于朴素贝叶斯分类,基于LSI-TF-IDF两阶段特征选择算法的分类精确率相比于单一的基于TF-IDF特征选择的分类精确率由89.2%上升到90.2%,召回率也由84.6%上升到89.5%;对于KNN分类,基于LSI-TF-IDF两阶段特征选择算法的分类精确率相比于单一的基于TF-IDF特征选择的分类精确率由82.7%上升到87.1%,召回率也由80%上升到87.6%;对于SVM分类,基于LSI-TF-IDF两阶段特征选择算法的分类精确率相比于单一的基于TF-IDF特征选择的分类精确率由91.9%上升至92.7%,召回率由88.4%上升至93.2%。可以看出无论是精确率、召回率还是F1值,基于两阶段特征选择的医疗敏感文本分类都比传统医疗敏感文本分类有所提高。
因此,根据对实验结果的对比分析,对于医疗文本的敏感性分类而言,基于LSI-TF-IDF两阶段特征选择的文本分类方法比传统的基于TF-IDF文本分类方法取得了更好的分类效果。
4 结束语
从对敏感数据的分类角度切入隐私保护,针对传统的文本分类方法用于医疗敏感数据的分类准确性不足的问题,提出了基于LSI-TF-IDF两阶段特征选择的医疗敏感文本分类方法,通过连续两阶段的特征降维和特征提取,提高分类的准确性,解决了传统分类方法的不足。以TF-IDF特征选择为例,通过实验对传统的基于TF-IDF医疗文本分类方法和基于两阶段文本分类的医疗敏感文本分类方法进行比较。实验证明,基于LSI-TF-IDF两阶段特征选择的文本分类方法对于医疗敏感文本分类具有更好的效果。但是,由于医疗数据量大,文本数据包括半结构化数据和非结构化数据,分类器的选择不同会导致分类速度和分类结果的准确性有差别,如何针对医疗数据的特点选择性能最好的分类器,需要具体的进一步研究。
猜你喜欢
电子测试(2018年1期)2018-04-18 11:52:35
电子制作(2017年23期)2017-02-02 07:17:06
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2014年15期)2014-04-04 12:05:20
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
