
网络资源归档标准WARC及其应用研究
2020-08-06 08:29郭晓云
兰台世界 2020年7期
郭晓云


摘 要 详细阐述网络资源归档格式标准(WARC)的制定背景、发展历程、特点和优势,分析了WARC标准的应用情况和生态圈建设,探讨了WARC在档案领域的应用。
关键词 WARC网络资源归档ISO标准 标准应用
Abstract The paper elaborates the background, progress, characteristics and advantages of web resources archiving standard WARC, analyzes the application situation and ecosystem construction of WARC, and explores the application of WARC in archival field.
Keyword WARC; web resources archiving; ISO standard; standard application
WARC(Web ARChive)文件格式标准是由ISO国际标准化组织2009年发布的网络信息资源存档格式标准,是面向网络信息资源长期保存领域唯一的文件格式标准。网络信息资源是指依托互联网等大型网络,以网站、社交媒体等形式发布的信息资源。网络信息资源存在寿命短、易丢失、不可再生的特点,这意味着如果没有归档保存,这些宝贵的资源将不复存在。网络资源存档(Web Archive)的目的就是抢在这些资源消失之前将它们归档保存起来,WARC标准则是网络资源存档保存封装格式,用于解决网络资源格式多样、联系复杂等保存问题,目前已广泛应用在世界各国的数字图书馆、数字档案馆、数字资源仓储机构中。
一、WARC标准解析
GB/T 33994-2017对WARC格式的描述是:“WARC(Web ARChive)文件格式提供了一个由多个资源记录(数据对象)连接成一个长文件的协议,其中每个资源记录由一组简单文本标头和任意数据内容块构成。WARC格式将作为组织、管理和储存采集来自网络和其他数以亿计的数字资源的一种标准,可用于构建收割、管理、访问和交换内容等各种应用。”[1]
WARC不仅存储资源记录内容本身,还可以存储附加的元数据,支持重复资源的检测、资源格式转换、大资源的分隔存储等功能。WARC本身只定义了存储格式标准,WARC文件具体如何存储、如何解析都取决于软件的具体实现。
WARC文件主要构成要素是WARC资源记录,一个文件由若干个WARC资源记录(warc record)构成,WARC记录间以两个空行(CLR)分隔。WARC记录有多种类型,包括warcinfo、response、resource、request、metadata、revisit、conversion、continuation八种,用于记录软件收割网页时的所有信息,包括访问请求、元数据等,尽可能完整地保存网络资源,而不仅仅是网页内容。
WARC记录(warc record)由记录头(head)和内容块(block)构成,中间以空行分隔。记录头由版本行和若干个warc命名字段(warc-field)及字段值构成(形式如:WARC-Type:request)。版本行说明遵循的WARC标准版本号,如WARC/1.0代表2009版标准,WARC/1.1代表2017版标准。Warc命名字段值列表记录WARC记录各种元数据,如WARC-Type:response标识WARC记录的类型是response,代表Http请求的返回。WARC1.1版提供了21种WARC命名字段,用于描述记录块内容、获取过程、块间联系等。每条WARC记录都会包含记录编号WARC-Record-ID、记录类型WARC-Type、记录日期WARC-Date、內容类型Content-Type、内容长度Content-Length这5个必备字段及其他相关命名字段。内容块记录实际的内容,比如response记录会记录服务器返回的内容,内容块格式为UTF-8,如果返回的是二进制内容,会转换为UTF-8格式。
WARC文件首个WARC记录的记录类型是warcinfo,用于记录整个WARC文件的信息。warcinfo记录的内容块主要记录收割软件的信息,包括软件名、收割软件IP地址、收割软件机器名、是否遵守机器人协议等。Warcinfo类型记录块如图1所示。
WARC标准通过WARC-Concurrent-To、WARC-Refers-To、WARC-Segment-Origin-ID等特殊的命名字段实现不同记录块之间的关联关系。
以WARC-Concurrent-To为例,如果WARC记录的WARC-Concurrent-To值相同,则表示这几条记录都属于同一个获取过程。比如,获取网页中的某个资源,则整个过程会产生request请求记录、response返回记录、metadata元数据记录等WARC记录。其中,request和meatadata记录的WARC-Concurrent-To字段的值会与response记录的WARC-Record-ID相等,表示这两条记录是response记录的附加记录,描述了网络资源的请求过程和相关元数据,通过这种方式,可以完整地记录网络资源的抓取全过程,尽量多地存档相关数据。
有时候一个抓取过程抓取到的网络资源可能会分散到多个文件中,为了保持文件之间的联系,WARC标准建议抓取软件在除了warcinfo记录外的所有记录中添加WARC-Warcinfo-ID,值为抓取过程产生的第一个WARC文件的warcinfo记录的WARC-Record-ID。
分段功能(segment):分段是指如果抓取的资源过大,超过了WARC文件的大小限制,WARC支持对响应资源进行分段存储,将内容切分存储在多个WARC文件中,WARC推荐的上限为1GB。以存档一个超过1GB的大视频文件为例,存档的第一个WARC文件会包含一个response记录,该记录的WARC-Target-URI为抓取的视频资源URL,WARC-Segment-Number字段为1,标识这是分段的第一段。WARC-Payload-Digest为整个视频文件的校验摘要,WARC-Block-Digest为该段的校验摘要。第二个WARC文件会包含后续的分段记录,记录的WARC-Type为continuation,表示分段的后续记录,WARC-Target-URI仍为原视频URL,WARC-Payload-Digest为整个视频文件的校验摘要,WARC-Block-Digest为本段的校验摘要,WARC-Segment-Origin-ID为第一个分段记录的WARC-Record-ID,WARC-Segment-Number为2,标识是第二个分段,如果这个分段是最后一个段,则会添加WARC-Segment-Total-Length记录,标识整个视频文件的大小。分段记录示例如图2所示,左边为第一个分段记录,右边为第二个分段记录,连线标出了两个记录之间的联系。
去冗余功能(revisit):存档网络资源时会经常出现重复资源现象,比如两个网页都使用了同一张图片,如果这些重复资源都存档,会浪费存储空间。WARC标准提供了revisit记录,当软件进行网络资源抓取时,通过计算校验码发现要存档的资源是已经存档过的记录,则不再重复存储这个资源,而是新建一条revisit记录。记录的WARC-Target-URI为抓取的URL,WARC-Refers-To为已存档的资源的WARC-Record-ID,WARC-Refers-To-Target-URI为已存档记录的WARC-Target-URI,WARC-Refers-To-Date为已存档记录的WARC-Date,revisit记录不记录内容块,此时Content-Length为0,也可将内容设置为HTTP/1.x 304 Not Modified消息,Content-Length设为返回内容长度。
转换功能(conversion):转换是指格式转换,WARC存档的目的是永久保存,在存档网络资源时,如果发现要存档的资源不符合永久保存格式要求,则除了原始资源记录外,还可以进行格式转换,并建立conversion记录。conversion记录的WARC-Refers-To为原始资源记录的WARC-Record-ID,WARC-Block-Digest为记录的校验码。除了conversion记录,还应添加metadata记录,记录转换过程的元数据,包括转换软件、转换时间、原格式、转换格式等。
压缩功能(Compression):WARC存档产生的数据量是很惊人的,以存档一个百度搜索首页为例,这是一个包含元素很少的网页,产生的Warc文件大约有700K左右,复杂的网页存档文件会更大。为了节省空间,WARC标准虽然没有提供内置的压缩支持,但给出了外部压缩方案。WARC推荐使用GZIP压缩算法[RFC 1952],这是一个开源无损压缩算法,GZIP文件可以由多个独立压缩的部分构成,WARC标准建议在压缩时对WARC文件的每个记录分别压缩,这样在外部索引和访问时不需要解压整个WARC文件,不影响检索效率。WARC收割软件在生成WARC文档时可以将WARC记录逐条使用GZIP算法压缩,并在索引中记录WARC的偏移量和大小,最后形成GZIP压缩形式的WARC文档,要读取某条记录时,通过偏移量和大小直接获取压缩后的记录内容,解压即可,不影响使用效率。WARC标准建议压缩后的文件扩展名为“.warc.gz”。
二、WARC标准的应用情况
优秀的标准离不开好的应用环境支持,WARC标准是一套成熟、优秀的存储格式标准,可用于网络信息资源的存储、交换和利用。互联网保存联盟IIPC一直在不遗余力地推广此项标准,构建了成熟的WARC应用生态圈。WARC格式也在IIPC联盟單位得到广泛的应用,涌现了许多优秀的Web Archive项目,比较知名的有美国互联网档案馆IA的Archive-it项目、澳大利亚国家图书馆的澳大利亚网络文献资源保管与利用系统PANDORA、日本国立图书馆NDL的长期保存系统WARP、荷兰国家图书馆主持的网络化欧洲存储图书馆项目NEDLIB、英国的网络信息保存联盟计划UKWAC等。
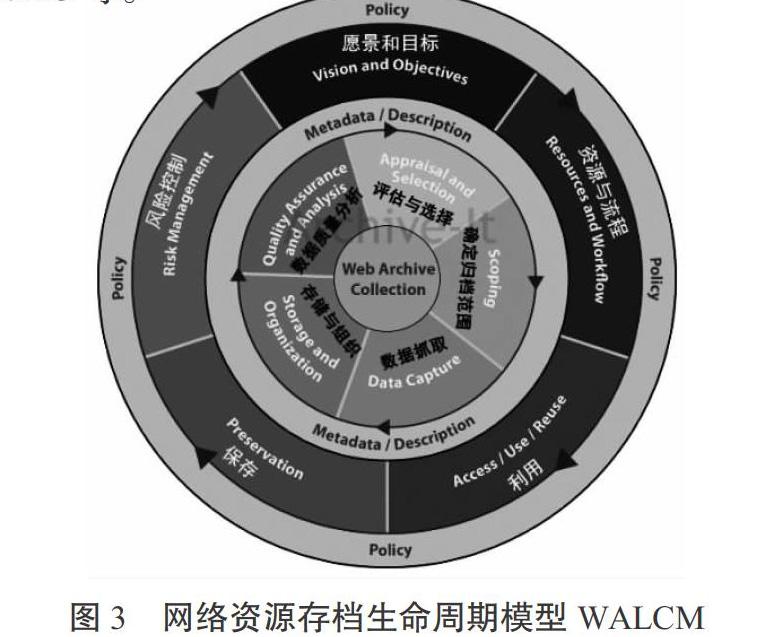
2013年3月,互联网档案馆IA的Archive-It项目团队发布了Web Archiving生命周期模型白皮书[2],分享了Archive-It项目及其合作伙伴在Web归档领域的实践经验和理论总结。Archive-It项目团队深入剖析总结了哥伦比亚大学图书馆、阿尔伯塔大学图书馆、蒙大拿州立图书馆、北卡州立图书馆、北卡州档案馆、克莱顿大学图书馆六家合作伙伴Web存档项目建设中的经验教训,将技术和管理相结合,提出了网络资源存档生命周期模型Web Archiving Life Cycle Model(WALCM),目的是为需要进行网络资源归档的机构提供通用的建设流程和建设模型,WALCM模型如图3所示。
模型的核心是Web存档集合,也就是WARC文件集,是Web存档形成的结果。最外层代表政策(Policy),是指Web存档活动相关的政策面,如存档过程涉及的法律法规、存缴制度等,这些都会影响Web存档的范围和权限。政策层的下一层是从机构角度理解的Web存档过程,包括五个方面。一是愿景及目标(Vision and Objectives),即机构进行Web归档的目的。二是资源与流程(Resources and Workflow),即机构建设Web归档项目可利用的资金、人力、智力、合作方等资源及利用这些资源的方法,其中人力资源尤其重要。三是利用(Access/Use/Reuse),即机构是否需要将存档资源提供给公众,如何提供利用,如何管理公众的利用行为;四是保存(Preservation),即机构如何保存在Web归档活动中形成的数据及元数据。五是风险控制(Risk Management),即机构如何处理Web归档中存在的风险,包括版权问题、授权问题、利用问题,如在采集过程中是否遵循robots.txt机器人协议等。第三层是元数据与描述层(Metadata/Description),Archive-It团队将元数据与描述处理从具体环节上升到整个生命周期,目的是强调元数据处理活动是贯穿于Web存档全过程的,Web文档资源收集、存储、分析、利用的全过程都会产生大量元数据,这些元数据都应作为Web记忆的一部分保存下来。第四层是实践层,即Web存档需要完成的具体工作,包括五个步骤,分别是选择与评估、确定归档范围、数据获取、数据存储与组织、数据质量管理与分析利用,五个步骤形成一个流程闭环,虽然有些内容是基于Archive-It平台的使用经验,但仍然有借鉴意义。
选择与评估(appraisal and selection)主要是确定采集的网站列表,目前Web存档主要有两种策略,一种是全采集策略,即采集所有的网站,如互联网档案馆采用的就是这种策略;一种是选择采集策略,即只采集特定的网站或是特定主题和事件相关的网页,如美国国会图书馆Minerva项目就只收集了2002冬奥会的专题网站。对大部分机构来说,Web归档应该采取的都是选择采集策略,选择与评估阶段主要就是确定要采集的网站URL的列表。确定归档范围(Scoping)用于确定每个网站采集的网页范围,是采取全部网页还是部分网页。比如,可以只采集网站某个栏目,或是仅仅采集某种类型的文件,如PDF文档。数据获取(Data Capture)是指使用爬虫软件采集需要的网络资源,此阶段需要考虑爬虫软件的具体设置,数据采集的频率和时间等细节。Archive-It提供的开源爬虫软件Heritrix就提供了丰富的定制功能。从统计数据来看,针对不同的采集源机构一般都会设置不同的采集策略,而且数据采集有时候会产生意想不到的结果,如采集的数据容量大大超出原来估计的容量等等,这些都需要在采集过程中不断调整和干预。存储与组织(Storage and Organization)是指制订采集后数据的存储和管理计划,包括短期存储和长期存储计划,存储副本问题,如何建立数据索引等等。数据质量分析(Quality Assurance and Analysis)是指检查获取的数据质量和完整性,可以通过查看爬虫程序生成的抓取报告或是使用Archive-It提供的Wayback回放软件检查数据质量,也可以使用相关的软件工具来进行数据质量鉴定,如北卡州立图书馆就使用了一个开源系统Constraint-Analysis来检查数据采集结果,该系统可以可视化地展现WARC文档中的资源,用户可据此判断抓取的资源是否在收集范围内。
目前,WARC应用的研究重点主要集中在以下几个方面。
一是社交媒体信息的存档问题。自诞生起,Web存档的对象主要是各类网站,包括政府网站和商业网站。但随着社交媒体的出现和广泛应用,社交媒体逐渐成为网络信息资源的主要来源,如何存档这些数字记忆也成为Web存档领域的研究重点。社交媒体存档的研究包括存档的法律法规依据、存档的意义、存档的选择范围、采集频率、存档的技术等。比如Twitter、微博等形式的社交媒体如何存档问题。微博是指140字内的短网文,支持图片、视频,其结构和传统网页完全不同,如何处理这种形式变化?最终生成的WARC文件结构如何设计?微博采集的对象如何选择,是按账号采集还是按话题采集?采集时只采集微博还是包括微博后面的评论?这些都是需要研究探讨和解决的问题。
二是网络资源采集技术的发展。随着网络技术的发展,特别是HTML5标准的推广,网页的形式也在发生变化,Javascript脚本、Flash组件、CSS样式表、HTML5等新的网页编码方式和交互设计,流媒体的大量使用等,这些变化导致很多传统的网络爬虫程序失效。新的网络采集解决方案也在出现,如使用无头模式的Chrome headless配合Selenium来归档Javascript脚本较多的网站,通过虚拟浏览器浏览行为抓取数据。使用youtube-dl脚本下载流媒体视频等。
三是与大数据、云计算等新技术的结合。云计算与大数据已成为当前的主流技术,特别是在大规模数据的处理方面。Web归档会产生大量的WARC存档文件,这些文件的存储、分析、利用等都可以借助云计算和大数据的力量,提高WARC文件处理的效率、WARC数据分析的质量、WARC数据可视化展示效果等。互联网档案馆提供的WARC开源分析工具ArchiveSpark[3]就使用了大数据软件框架Spark,可以实现大量WARC数据的处理、提取和分析。
三、WARC标准在我国档案领域的应用建议
WARC标准虽然在国外应用得非常广泛,但在国内应用案例并不多。目前,国内WARC标准最大的应用项目是中国国家图书馆的网络信息资源采集与保存试验项目(Web Information Collection and Preservation WICP)[4]。该项目2003年开始启动,目的是对中国境内的互联网资源进行采集与保存,采用的工具是IIPC提供的Web归档工具包,存档格式为WARC,从项目试验效果看,虽然IIPC的工具包在中文处理、兼容性等方面存在一些问题,但总体效果比较满意。2007年,国家图书馆成为IIPC联盟成员机构。2019年4月,国家图书馆启动了国家互联网信息战略保存项目,旨在建设覆盖全国的分级分布式中文互联网信息资源采集与保存体系,仍然沿用WARC格式标准。在档案领域,目前公开的应用实践只有2015年河南省郑州市档案局(馆)进行的政府网站归档工作试点[5],试点工作归档对象是以gov.cn域名结尾的郑州市所有政府部门、各级党委的网站,使用的是互联网博物馆提供的工具包,存档格式为WARC,并进行了压缩处理。这次试点重点包括WARC软件工具使用、网站采集策略制定、WARC存储管理,试点结果特别指出网站归档的速度和存储容量问题,虽然已经进行了压缩处理,但对七个政府网站的一次采集,采集数据就达1.5G,因此得出采用云存储方案的必要性。
WARC标准不仅是优秀的网络资源长期保存和交换格式,也适用于其他传统数字对象的长期保存,如丹麦皇家图书馆就曾使用NetArchiveSuite系统将图像资源保存为WARC格式,取得了很好的效果[6]。WARC被采用为国家标准,目的就是为了有效推动WARC在我国网站资源归档和数字对象长期保存领域的应用。
要推动WARC标准及网络资源归档在我国档案领域的应用,笔者认为可从两个方面着手。
一是强化政策指引和制度支持。我国档案领域对于网络资源归档的研究起步较早,2006年,就有档案学者开始研究网站的归档问题。政策层面的起步也较早,2014年底,时任国家档案局局长杨冬权就提出要尽快启动各级国家政府网站网页存档工作。2016年4月印发的《全国档案事业发展“十三五”规划纲要》中明确提出“研究制定重要网页资源的采集和社交媒体文件的归档管理办法;加强电子档案长期保存技术研究与应用。”2016年11月,中办、国办印发的《国家电子文件管理“十三五”规划》明确提出“推进政府网页及电子邮件、音視频等电子文件归档”。2017年5月,国务院下发的国办发〔2017〕47号《国务院办公厅关于印发政府网站发展指引的通知》[7]中明确提出了网页归档的要求,“要求政府网站遇整合迁移、改版等情况,要对有价值的原网页进行归档处理。归档后的页面要能正常访问。”47号文件还规定了网页标签规范,“要求政府网站以meta标签的形式,对网站名称、政府网站标识码、栏目类别等关键要素进行标记,标签值不能为空。”这些元数据都是网页存档及后续分析利用的基础。2017年7月,国家标准局将WARC引入国家标准目的就是解决存档格式问题。对社交媒体的归档,2017年实施的《电子文件归档与电子档案管理规范》和2018年印发的《机关档案管理规定》也都明确提出社交媒体文件应该归档。
从政策层面来看,网络资源归档的要求是明确的,目前亟需解决的是配套的实施细则和制度安排问题。实施细则需要重点明确政府网站和政府社交媒体的归档范围,归档频率,归档中的元数据采集要求,WARC存档文件的采集、封装、元素命名、打包等使用规范,归档文件的保管期限、存储要求,WARC存档文件的索引、分析、检索、展现、利用规范等等,为网络资源归档人员提供明确、清晰的操作指导。制度安排方面包括探索建立政府网络信息存缴制度,明确政府部门与档案机构在政府网络信息归档活动中的任务分工,变档案机构被动采集为政府部门主动存缴。制定网络资源归档相关的保障制度,从组织机构、人力、物力等方面给予制度保障。结合国内政府网站及社交媒体的特点,制定相关的政府网站网页设计规范、元数据标注规范、社交媒体采集规范等归档标准规范。
二是加强合作交流与技术引进。网络资源归档工作是一项技术性很强的工作,WARC标准也是一个专业性很强的技术标准。档案领域要推动网络资源归档工作和WARC标准的应用,应加强国际国内合作交流与技术引进。互联网保存联盟IIPC是Web Archiving领域影响最大的国际交流合作平台,其成员除了部分国家的国家图书馆外,也包含一些档案机构,如英国国家档案馆(The National Archives,U.K.)。我国国家图书馆已于2007年加入IIPC,档案界可效仿加入国际档案理事会的做法,以中国档案学会的名义申请加入IIPC联盟,通过IIPC这个国际平台加强与联盟机构的合作交流。网络信息存档是一项巨大工程,人力、物力、财力耗费巨大。中国国家图书馆作为国内最早使用WARC标准,开展大规模网络资源归档工作的单位,在网络资源归档方面积累了丰富的实践经验和研究成果。数字资源长期保存相关的理论与技术也一直是我国图书馆界研究的一个重点,国内部分商业机构也在研发推广相关的技术产品。档案界应加强与图书馆界、商业机构的合作和技术交流,做好协作分工。如与国家图书馆互联网信息战略保存项目合作,由档案机构负责政府网站及社交媒体的归档工作,国家图书馆及相关机构负责其他网站和社交媒体的归档工作,通过WARC标准实行数据对接,共同完成保存中国互联网数字记忆的任务。在技术上,与国家图书馆和商业机构合作,研发适合我国档案机构特点的网络归档软件;指导政府网站发布系统升级改造,实现网页发布与网页存档同步进行,定期由网页发布系统生成WARC文件并存缴到档案机构;探索WARC标准与档案机构大量采用的OAIS参考模型相结合的解决方案等。
参考文献
[1]中国国家标准化管理委员会.网络资源存档格式标准GB/T 33994-2017信息和文献 WARC文件格式最新发布 [EB/OL].[2017-07-22].https://www.sohu.com/a/159096915_734807.
[2]Archive-It.WAAnnouncing the Web Archiving Life Cycle Model[EB/OL].[2013-03-11].https://archive-it.org/blog/post/announcing-the-web-archiving-life-cycle-model/.
[3] helgeho.ArchiveSpark[EB/OL].[2020-03-11].https://github.com/helgeho/ArchiveSpark.
[4]張炜,张文静.中国网络信息采集工作研究现状分析——以国家图书馆为例[J].图书馆建设,2008(7).
[5]石华.档案馆保存政府网站策略研究——以郑州市档案局馆为例[J].档案管理,2016(1).
[6]Mikis Seth Sorensen.NetArchiveSuite[EB/OL].[2020-01-07].https://sbforge.org/display/NAS/NetarchiveSuite.
[7]国务院办公厅.国务院办公厅关于印发政府网站发展指引的通知[EB/OL].[2017-05-15].http://www.gov.cn/zhengce/content/2017-06/08/content_5200760.htm.
猜你喜欢
中国质量与标准导报(2022年2期)2022-06-09
中国计算机报(2021年10期)2021-04-27
现代职业教育·高职高专(2020年1期)2020-08-16
魅力中国(2018年5期)2018-07-30
读者(2018年8期)2018-04-03
中学科技(2016年7期)2017-05-16
共产党员·下(2017年1期)2017-02-09
软件导刊(2016年9期)2016-11-07
智能计算机与应用(2007年4期)2007-08-25
青年文摘·上半月(1991年3期)1991-01-01
