
弱监督学习语义分割方法综述
2020-08-05 07:01李宾皑郝鸣阳顾书玉
数字通信世界 2020年7期
李宾皑,李 颖,郝鸣阳,顾书玉
(1.国网上海市电力公司建设部,上海 200120;2.南京七宝机器人技术有限公司,南京 211100)
1 语义分割
语义分割是计算机视觉的基础性问题之一,是图像分类、场景解析、物体检测、3D 重建等任务的预处理步骤[1]。2014 年,Long 等人提出了全卷积网络(fully convolutional network,FCN)[2]模型,该方法使用原始图像作为模型的输入,使用模型直接对图片中的每个像素进行分类,模型的输出结构即为原始图像的语义分割图。在PASCAL VOC 2012图像分割竞赛中,全卷积网络取得了62.2%的分割准确度。在此基础上,Chen 等人通过在模型末端添加全连接CRF提出了DeepLab模型[3],在PASCAL VOC 2012图像分割竞赛中取得了71.6%的分割精确度。Liu 等人通过“区域-区域”上下文来建模相邻图像块之间的语义关系,进一步将分割准确度推升至78.0%。
尽管在分割效果上取得了巨大的进步,但这些基于深度学习的方法依赖大量像素级手工标注的数据。对图片中对象逐像素标注所需的时间是仅标注对象边界框所需标注时间的15倍[4],Cityscapes 数据集中单张图片平均标注时间高达1.5小时。表1中可以看到常见语义分割数据集中的样本数量与类别数量,昂贵的标注成本不仅提升了语义分割算法工程落地的难度,也在一定程度上限制了深度神经网络的规模,因为网络的层数越多、参数量越大,对训练样本的需求往往也更高。
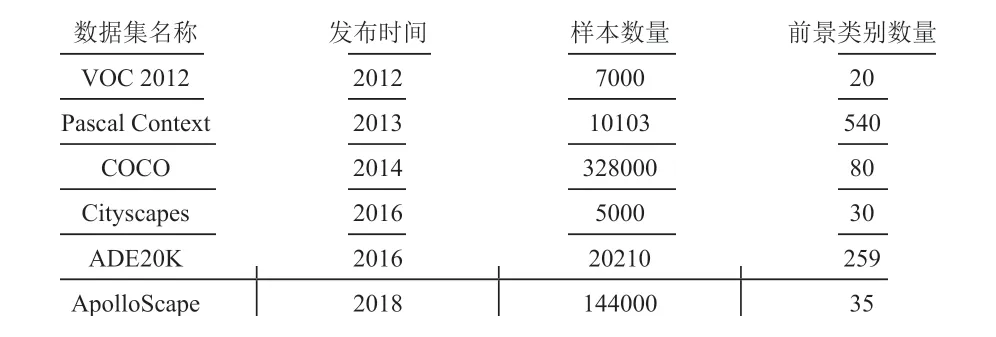
表1 常见语义分割数据集中样本数量
为了降低图像标注的难度,一种方式是仅队数据进行简要标注,或利用监控、互联网爬取得到的数据固有的结构训练模型。这类使用比像素级标注粒度更粗的标注进行学习的语义分割方法一般称为弱监督学习语义分割方法。
2 弱监督学习的语义分割方法
2.1 弱监督学习
弱监督学习指的是在没有全部样本真实值标签这样强监督信号的情况下,训练深度学习模型的手段。一般来说,弱监督监督学习方法可以分为三类:
(1)不完全监督学习是指训练样本中只有小部分图片具有手工标注的真值标签,而大部分图片没有标注的情况下,训练模型的方法。
(2)不确切监督是指训练样本的标注粒度较低,只对训练图片中待分割物体的类别或边界框进行标注的情况下,训练模型的方法。
(3)不准确监督是指训练样本中的标签不总是真值,即存在错误标注的情况下,训练模型的方法。
由于语义分割中训练数据收集的主要难度在于人工像素级标注的工作量极大,因此使用边界框、语义点、粗略标注特别是图像类别标签进行训练的不确切监督方法受到了广泛的关注。
2.2 实例级标注语义分割方法
实例级标注指的是对于一幅图片中的所有待分割的物体,只对其边界框和类别进行标注。与像素级标注相比,实例级标注不仅可以极大的降低标注所需的人工成本,还可以将既有的目标检测数据集如OpenImage 等直接作为语义分割数据集来使用。
2015年,Dai 等人通过观察到CFM、FCN 等方法实际上只使用了多次下采样之后的、粗糙的像素标注进行训练,受此启发提出了BoxSup。BoxSup 将MCG 等无监督的区域生成方法和DeepLab 等监督的语义分割方法结合,首先使用无监督的区域生成方法对边界框中的图像进行分割,并为分割后的每一个区域选择一个类别标签,得到原始标注并以此为监督训练语义分割模型。在语义分割模型训练结束后,BoxSup 将根据训练后的语义分割模型反过来调整标注中每一个区域所对应的的类别标签,其最小化目标函数可以写做:

式中,i为图片的序号,即对于训练集中的全部图片,最优化语义分割模型参数θ和所有分割区域{S}的标签{ls},使(εo+λεr)的值最小。εr为调节两目标函数比例的超参数,εr为语义分割模型在区域标签为{ls}时的损失函数,εo则约束了边界框内的同类别区域应尽量覆盖整个边界框。具体的:

式中,N为S中区域的总数;B为每个区域对应的边界框;"IOU"(B,S)为分割区域与边界框之间的交并比;δ(lS,lB)为分割区域与边框类别一致性谓词。BoxSup采用了一种迭代的贪心策略来优化式,在多次迭代后,模型的性能可以达到略低于强监督训练的可观水平。
在BoxSup 的基础上,Bbox-Seg 将EM 算法应用到了语义分割模型的训练当中,使模型在小部分样本像素级标注、大部分样本实例级标注的半监督训练集上取得了更好的效果。SID 利用边界框标注和先验信息对分割区域进行处理,直接得到高质量的区域标签对语义分割模型进行训练,避免了BoxSup 中训练集的迭代。
2.3 图片级标注语义分割方法
尽管实例级的标注方法极大地简化了标注任务,但当数据集较大时,对每个对象边界框的标注依然是一项繁重的工作。一种粒度更粗的标注方法是使用图片级的类别标签,即对于每张图片中感兴趣对象是否存在进行标注。图片级的类别标签的标注难度极低,有时标签甚至可以直接从互联网、物联网中得到,因此这类弱监督语义分割方法受到了产学界的格外关注。
由于图像类别标签中不包含任何位置信息,因此在分割时必须采用额外的方法对对象进行定位。类激活图(Class Activation Mapping,CAM)[5]是最常用的定位方法之一。通过将VGGNet、GoogLeNet 等网络最后一层卷积层提取的特征经过全局平均池化(Global average pool)后再输入全连接层分类,CAM 可以将全连接层输出的类别分数投射回卷积神经网络最后一层特征图中,以此完成对待分割物体的粗略定位。

图1 通过CAM对类别相关的对象进行定位
主流的图片级标注弱监督语义分割方法均运用了CAM 对待分割目标进行了定位,SEC 是其中较有代表性的一种。SEC 提出了seed、expand、constrain 三 原则,利用CAMs 计算局部图像区域对最终图片分类中各类别的分数的贡献,SEC 粗略地估算每个类别的对象在图片中出现的区域。然而,由于类激活图的分辨率较低且往往只会在对象的局部区域才会有较高的响应,因此无法直接使用类激活图进行训练。为了解决这一问题,SEC 在普通的语义分割损失之上又增加了扩张损失和边界约束损失。扩张损失通过全局加权排序池化(global weighted rank pooling,GWRP)构成,该池化方法结合了全局最大值池化和全局平均值池化的特性,要求模型输出大小适中的预测区域。边界约束损失则要求模型预测结果与全连接CRF 的预测结果尽可能的相似,要求模型的预测区域符合图片的结构和纹理等信息。
在SEC 的基础上,AffinityNet 对像素之间的一致性,从而获得了更好的泛化能力。rpm 观察到CAMs 对实例对象类别的响应的最大值应该再该实例区域内这一特点,通过CAMs 响应的局部最大值反向推导来扩大与每个局部最大值响应的区域,从而完成对同类实例对象的分割。IRNet[6]使用一般性的(class-agnostic)模型对图中的对象及其边界进行检测,并以此为依据扩散CAMs得到的信息。
3 试验验证
为了验证弱监督语义分割模型在电网场景中运用的可行性,本文使用在POSCAL 2012测试集中取得了最高mean IoU 的图像级标注弱监督方法IRNet[6]进行了实验。在数据准备阶段,我们共收集了训练集15,000张变电站、建筑工地中设备、人员的图片,对呼吸器、压力表、压板开关、人员等类别进行了图片级标注并按照4 ∶1的比例划分为训练集和测试集。为了进一步增强数据的多样性,试验过程中对训练集中的图片采用了随机水平翻转、正负15°以内的随机旋转、HSV 色彩空间中的随机扰动等方式进行增强,最终得到增强后的训练数据约60,000张,所有图片的尺度被调整为最长边不超过512像素。
模型分为CAM、IRNet 和语义分割网络三部分进行训练。在训练CAM 时使用交叉熵作为损失函数,设置学习率为0.01,批大小为32,训练轮次为5轮。在IRNet训练阶段,设置学习率为0.025,批大小为4,训练迭代次数为20轮。最终结果如图2所示,由于缺少人工的逐像素标注,在现有试验条件下无法计算mean IoU 等客观评价指标。尽管边缘的分割效果与使用像素级标注强监督的方法相比仍有较大差距,但对区域的正确分割使得该模型能够在数据增强、相机位姿估计等场景中作为前处理使用。实验证明了弱监督语义分割方法在实际工程应用中的价值。
值的注意的是,试验中发现训练集中类别出现的相关性可能导致图片级标注的语义分割方法性能大幅下降。如说将呼吸器硅胶桶和呼吸器油封作为两个类别进行标注训练,由于绝大多数照片中的呼吸器都包含了硅胶桶和油封两个部分,因此硅胶桶和油封都会作为特征被CAM 学习,从而导致模型无法对两个类别进行区分。为了解决这一问题,一个可能的思路是采用实例级标注的弱监督学习或半监督学习。

图2 IRNet对变电站建筑工地数据集的分割结果
4 结束语
本文针对电力系统中图像语义分割技术样本标注成本过高的问题进行了分析,对基于深度学习的语义分割方法特别是弱监督方法进行了介绍和分析,并通过实验证明了在电网场景中使用弱监督标签实现语义分割的可行性。实验表明,弱监督语义分割方法可以极大地简化模型训练数据的标注过程,从而起到降低标注成本、增加样本数量和多样性的作用。在对图像分割边缘准确性不敏感的应用场景下,弱监督语义分割方法是一种可行的方案。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
长江学术(2016年4期)2016-03-11
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
