
NSTL大数据管理与计算平台的设计与应用实践
2020-08-03 09:33:52董智鹏常志军张建勇钱力
数字图书馆论坛 2020年7期
董智鹏 常志军 张建勇 钱力
(中国科学院文献情报中心,北京 100190)
NSTL发展规划的智能知识服务需要深入的数据挖掘、语义计算、深度学习等技术进行强有力的支持。NSTL经过近20年的发展,已形成了海量的多来源、多类型的文献元数据库,当前采用的存储技术和管理技术相对比较传统,数据管理成本较高,横向扩展与弹性收缩较差,已不能满足业务对数据的应用需求,亟须引进具有良好扩展特性的开源大数据生态圈技术,建设大数据管理与计算平台。形成统一化、规范化、智能化的数据业务管理体系,提高业务运行效率,支持海量文献元数据的集中管理和计算业务,提高数据管理的效率,扩展数据间的关系,强化数据的关联度,以适应NSTL从文献服务向知识服务转变的发展战略。
1 数据管理业务流程再造
传统数据管理流程采用联机事务处理(OLTP)机制进行数据交互,在大规模处理数据时,存储与计算瓶颈凸显。针对NSTL业务流程再造目标分析,数据管理流程需要满足海量多来源异构数据汇聚、融合、计算等大吞吐量操作,所以需对传统数据管理流程进行改造与优化,采用联机分析处理(OLAP)机制,提高数据计算效率、数据计算精度,有利于支撑数据产品研发。
1.1 业务流程再造目标
NSTL业务流程再造目标对数据业务中的数据管理流程提出3个主要任务。首先,需满足多来源、多类型、海量的数据资源的采集、发现、评估、共享与合作等;其次,满足集成数据汇聚、数据融合、数据增值计算、名称规范、语义标注和知识标引等,实现数据全生命周期的管理;最后,以知识发现为目标,促进知识与知识、数据与数据、用户与用户、知识与用户的关联、计算与聚合。
1.2 数据加工管理转型
NSTL数据加工是支撑文献服务的重要环节之一,经过多年的建设与发展,已经形成了自主加工,通过数据库集成商和出版社购买、开放获取、赠予等多种渠道获取数据方式。随着数据来源的增多,数据量的增大,目前的数据加工方式和管理流程已不能适应NSTL发展对数据加工的新需求。所以,基于NSTL发展目标再造数据加工业务流程,从“移动数据”向“移动计算”转型[1],逐步形成从资源采集到数据计算,再到数据产品的数据加工流程具有非常重要的战略意义。基于业务流程再造的数据加工流程管理框架如图1所示。
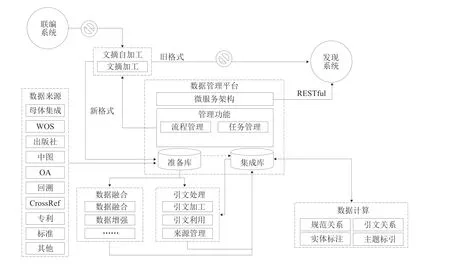
图1 数据加工流程管理框架
改造后的数据加工管理流程从多来源异构数据采集获取出发,遵循NSTL统一文献元数据标准规范,基于新构建的大数据管理与计算平台进行数据的解析与存储,平台的数据加工任务管理模块将需要加工的数据分配到相应的数据处理平台,如数据融合系统和引文处理系统,进行数据融合,集成处理。通过平台任务管理模块对数据进行关联计算,如引文关系、规范关系、主题标引等,最终形成可服务数据。再通过基于微服务架构的RESTful接口向外部提供数据输出服务,以支撑更多的数据产品研发和知识服务。
2 大数据管理与计算平台设计
根据NSTL数据管理业务流程再造的目标,选择大数据相关技术搭建NSTL大数据管理和计算平台,全面支撑NSTL各类数据的加工管理,支撑对大规模数据进行关联计算的需求。本设计将大数据管理和计算平台构建划分为4个主要任务:①集成大数据生态圈开源软件,部署基础环境;②设计从抽取、清洗、转换、装载等全生命周期管理的数据治理流程体系与技术规范;③集成多来源异构数据,抽取实体,进行相关数据计算;④基于微服务技术建设数据输出服务接口。
2.1 业务架构
NSTL大数据管理与计算平台的核心目标是建立可支撑数据获取、清洗、集成、增值的海量数据治理流程,形成可提供数据分布式存储和计算的基础环境。业务架构如图2所示。
作为支持NSTL数据业务的大数据基础环境,平台将遵循NSTL统一文献元数据标准,支撑数据获取、数据治理(数据清洗、数据集成、数据增值)以及数据服务等各业务环节,最终释放数据价值。
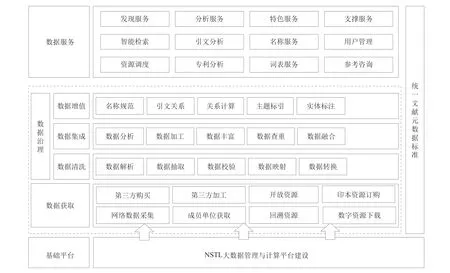
图2 平台业务架构
2.2 技术架构
NSTL大数据管理与计算平台以大数据生态环境松耦合[2]的研发理念,在数据管理的重要阶段(如源文件管理、元数据管理、索引管理等)对数据进行处理和完善。提供以HDFS[3]和Hive[4]技术为基础的数据存储环境,以Yarn、MapReduce、Spark[5]计算框架为基础的数据计算环境,以ElasticSearch[6]、Redis[7]技术为基础的数据查询服务环境,以Kafka、Spark-streaming技术为基础的流式处理环境,以Hue、Oozie技术为基础的可视化环境,5个环境协同调度与工作,实现无缝衔接。涉及的工业级大数据技术有HDFS、MapReduce、Spark、Hive、ElasticSearch、Hue、Oozie、Kafka、Zookeeper、Redis、MicroService、Flume-ng等。从技术层面可分为数据接入层、分布式存储层、分布式计算层、数据模型层、数据服务层以及应用层。平台技术架构如图3所示。
从数据源到服务层,根据数据规模、计算规模、服务模式等对平台进行功能层次划分。存储层提供海量数据的存储功能,采用Hadoop-HDFS。计算层提供海量数据的计算引擎,该层采用MapReduce、Spark多引擎模式,全新设计了MapReduce主要用于科技数据非迭代处理,而Spark主要用于模型计算、关系计算等处理的计算分工。同时,平台提供计算任务管理平台,支撑多用户远程提交计算任务,共享计算资源。索引分为计算索引和服务索引,分别支撑底层计算和用户服务。服务层为用户提供高效、稳定的数据查询服务。
平台采用Spring Cloud[8]技术,结合科技数据服务的特点,甄选、二次开发相关组件进而整合了一套集服务注册器、负载均衡器、权限控制、服务生产者、服务消费者等核心组件的科技数据服务架构,并扩展了消费管理及防爬功能,构建了分布式微服务系统。应用层指基于大数据平台的应用系统,可支持业务链条的数据应用,包括平台级别和服务级别的应用,并能根据业务量,进行弹性扩展保证服务性能。
2.3 平台构建
平台构建主要从平台数据流程技术规范制定、总体硬件服务器组件部署和网络拓扑划分、大数据技术生态圈开源软件选型与集成部署三方面展开。平台旨在解决多源异构数据的存储和计算的瓶颈,依托NSTL统一文献元数据标准规范建立统一化的分层管理数据流程和技术规范体系,构建统一数据集成子系统和分布式计算任务管理,建设具有消费管理及防爬虫功能的分布式微服务子系统。
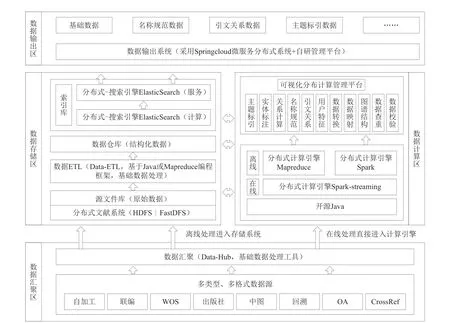
图3 平台技术架构
2.3.1 技术规范制定
技术规范规定了基于NSTL大数据管理与计算平台覆盖文献元数据处理的生命全周期,即技术类型、文件存储的读写操作、计算处理的编程引擎、元数据规范、数据微服务接口使用等。制订的技术标准规范包括五大类,即数据采集引进存储规范、计算引擎技术标准规范、搜索引擎技术标准规范、高速缓存技术标准规范和服务接口技术标准规范。此外,技术标准体系各环节数据描述遵循NSTL统一文献元数据标准3.0(正式版)。
针对数据来源复杂、异构多样、存储分散的特点,对数据采集存储进行规范。从采集频率、数据文件格式、结构化规范、存储目录规范、增量更新模式5个角度制定规则,以保证数据规格化、流程规范化和业务标准化。针对MapReduce和Spark计算引擎的特点,计算引擎技术标准规范从数据输入、计算逻辑实现、结果输出三个阶段制定规则,以保证各业务计算模型、处理程序在平台中正确执行。针对ElasticSearch搜索引擎软件集群的特点,搜索引擎技术标准规范从建索引、各类型检索、索引更新、索引删除等多种操作制定规则,以保证各业务在使用搜索引擎时,程序能够正确执行。针对Redis服务的特点,高速缓存技术标准规范从计算处理各个层面可能依赖高速缓存技术进行性能提升的环节制定规则,以保证各业务在使用Redis时,程序能够正确执行。针对平台的接口管理和监控,制定服务接口技术标准规范,用户可以通过访问平台地址进入系统,使用用户注册、接口申请以及API实例监控等功能来满足各种需求。
2.3.2 硬件设施部署
(1)服务器组件部署。NSTL大数据管理与计算平台基础设施硬件部署,将配备30台服务器支撑数据深加工过程,强调存储能力、计算能力、服务能力。其中,10台服务器构建分布式存储集群,10台服务器构建分布式搜索引擎集群,6台服务器构建分布式计算集群,4台服务器部署集中管理工具、日志服务应用。
(2)网络拓扑结构。网络拓扑主要由6部分组成:可扩展的数据汇聚服务器集群,可扩展和可负载均衡的Map-Reduce计算引擎,HDFS文件系统以及Hive数据仓库共用服务器集群,可扩展的ElasticSearch计算引擎集群,可扩展和可负载均衡的Spark计算引擎集群,可扩展的SpringCloud微服务集群。
2.3.3 软件设施部署
(1)关键技术选型。NSTL数据具有多类型、多来源、数据量级增长快等特性,传统处理技术很难进行较高效的数据处理。在分布式存储方面,G级别大文件可采用HDFS分布式文件系统;小文件的存储1M左右,甚至更小,则采用FastDFS文件系统。索引存储采用ElasticSearch。高性能缓冲存储采用Redis。通过以上软件整合,可使存储所需资源按需使用,可根据业务需要弹性伸缩存储能力,有效节省成本用于海量数据的管理和分析,提供Hadoop/Spark框架对接能力。
在分布式计算方面,海量数据ETL等处理适合采用MapReduce、模型计算等适合采用Spark、实时要求高的计算适合采用Spark-streaming或Storm、简单的类SQL处理适合用HiveSQL。通过以上软件整合,可支持对海量数据的清洗、抽取等技术数据处理的并行执行,覆盖多种主流计算引擎。可定制主流的模型,提供实时分析与推荐,专注于垂直数据的深度[9]。
通过以上大数据生态圈成熟技术的整合,可使平台具有多源聚合、多类型存储、高吞吐、可弹性扩展、计算模型准确度高、计算资源分配较合理等特性。
(2)关键技术部署。平台主要从技术架构中的3层功能区进行部署,即数据汇聚区、数据存储区和数据输出区。平台上集成部署了分布式文件系统(HDFS)、分布式计算系统(MR)、搜索引擎集群(ES)、内存计算集群(Spark)、高性能KV服务(Redis)、数据仓库管理工具(Hive)、分布式协调系统(ZK)大数据处理与管理工具等。
针对通用分布式技术环境部署进行系统级优化,以开源软件官方网站提供的说明为基础,结合集群的实际情况进行调优。解决包括SSHD登录慢,永久性关闭防火墙,最大打开文件数、进程数、文件数、单一进程可申请的内存数以及关闭SWAP等问题。对分布式组件的部分重要参数,通过关闭置换区,增加文件描述符的最大数量,提供足够的内存和线程最大数量以及对JAVA虚拟机和DNS缓存的设置,进行了进一步优化。
(3)微服务系统建设。平台对外数据接口采用微服务架构,服务接口之间互相独立部署,动态扩展,稳定性高,易于拆分。微服务子系统建设将采用的技术架构为Spring Cloud、EUREKA、ElasticSearch、MySQL。接口通过HTTP请求访问指定的请求方法,接口在访问ElasticSearch前进行安全策略检查,同时响应固定格式的返回结果。接口建立初衷是为了减少服务对于ElasticSearch集群压力,还可以通过定制开发,更好地为用户提供优质的服务。
微服务子系统通过服务注册模块为各数据输出提供接口应用注册,通过数据总线(Data-Bus)支撑获取数据,各应用可共享数据通路也可独立使用,可针对每个服务组件进行拆分和开发;同时支持接口应用热插拔功能。
3 应用实践
基于上述硬件环境、软件环境和技术规范的设计,搭建了满足NSTL数据管理和计算需要的平台环境。目前该平台环境在数据治理流程、分布式计算、微服务等三方面开展了应用。
3.1 多来源异构数据治理流程应用
数据治理需要建立统一化的流程体系,体系构建从数据生态建立、治理统一规范标准、数据双向流动、多种计算框架、数据释放价值五方面支撑。其中数据双向流动通过HDFS文件系统为中介[10],使业务存储覆盖多个文件系统,互相备份数据,保障安全。通过各种合适的计算框架,诸如Java程序、MapReduce程序、Spark程序等保证计算效率,节省计算资源。通过微服务技术使数据服务与数据应用完全解耦,具有弹性扩展能力。平台数据治理流程如图4所示。
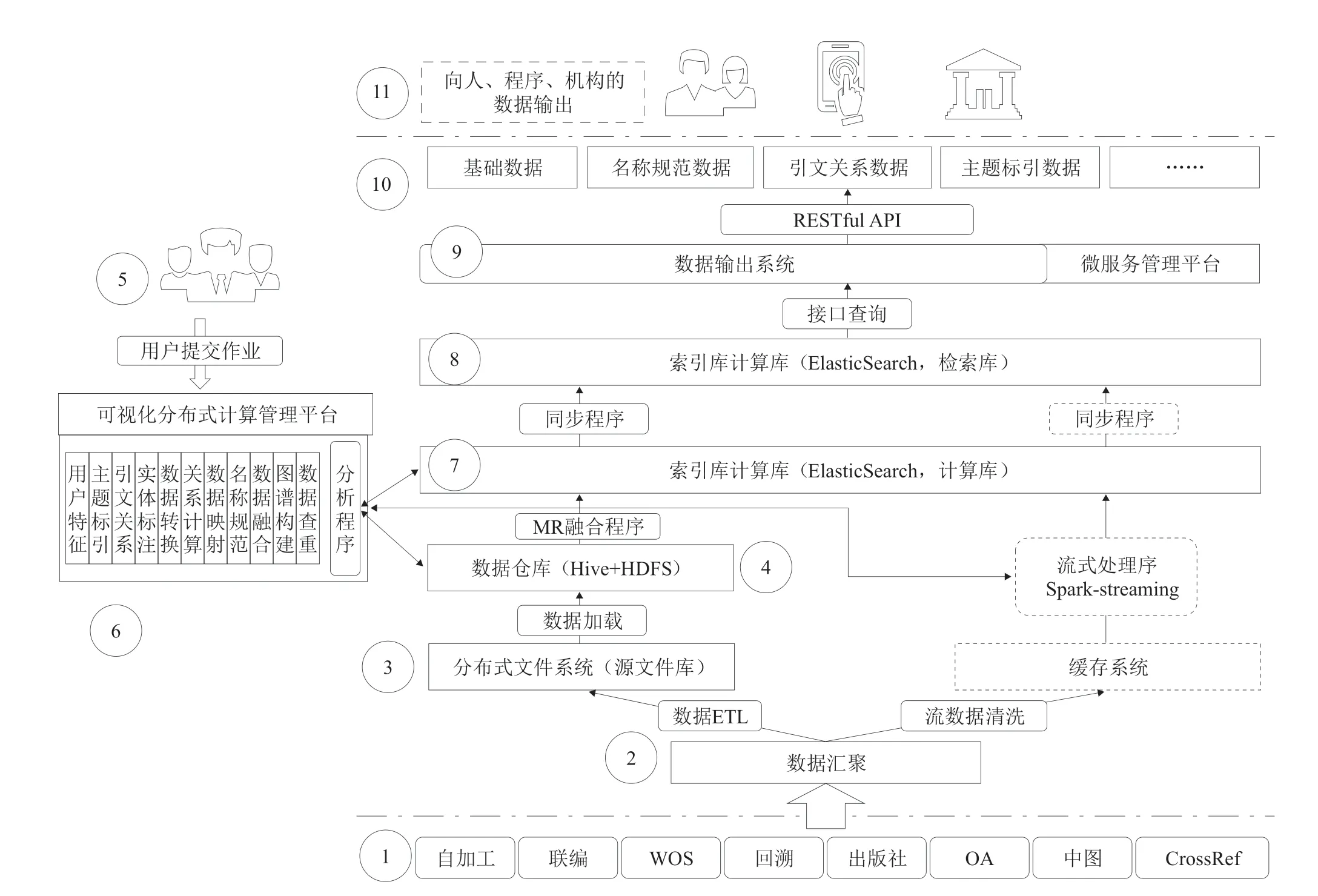
图4 平台数据治理流程
数据流管理分为批处理和流处理。在批处理阶段:①②从数据源开始,对全量数据进行统一汇聚;③来源数据在进行ETL处理后进入分布式文件系统HFDS;④通过Hive元数据管理方式构建数据仓库;⑦采用MapReduce或者Spark计算框架,对数据进行处理后在计算索引中创建索引;⑧计算索引数据定时同步到服务索引中。在流处理阶段:主要的区别在于通过Spark-streaming对数据进行实时处理,并在计算索引中创建索引,后续处理与批处理一致;⑤⑥为更方便、高效地支持多用户使用,平台基于计算框架底层接口开发分布式计算任务管理模块,支撑用户远程提交作业,共享集群的计算资源;⑨⑩在服务层,通过微服务技术将前后端分离;⑪分别向人、程序、机构提供数据输出服务。
3.2 分布式计算技术应用
基于大数据基础设施的新加工模式下的引文数据进行关系计算,形成归一关系、被引关系和耦合关系。基于归一关系还原引文数据,充分发挥引文数据在信息发现、信息利用中的作用。应用主要包括引文关系元数据设计,基于Spark引文计算流程设计,基于Spark引文计算算法封装。
基于Spark引文计算设计流程思想,将关系计算的需求转化为对数据集的筛选、统计的结构化检索语言。类似业务管理系统通过SQL实现主要数据操作的思想。被引关系计算主要抽取文献被引关键字段,通过相关字段检索识别可进行溯源的文献,然后利用Spark进行被引次数累计计算,并提供实时接口输出计算结果。耦合关系计算分别抽取两篇文献的关键字段,利用两篇文献的所有参考文献进行耦合检索(两两共同出现),然后利用Spark进行耦合数累计计算,并提供实时接口输出计算结果。引文关系计算架构如图5所示。
其中Spark计算引擎原理为:通过Spark-submit提交Application,Spark管理节点(Master)将分派集群计算资源,各集群工作节点(Worker)接收任务并实时监控运行状态并反馈管理节点(Master)。目前已对国际西文引文(DISC)数据进行引文计算测试,约3000万条文摘、3亿条引文数据计算时间约6小时,对比原来的计算方式在时间效率上提高3倍。因为目前利用搜索引擎方式计算数据,所以数据可进行增量引文关系计算,增量处理约1万条/分钟级别。
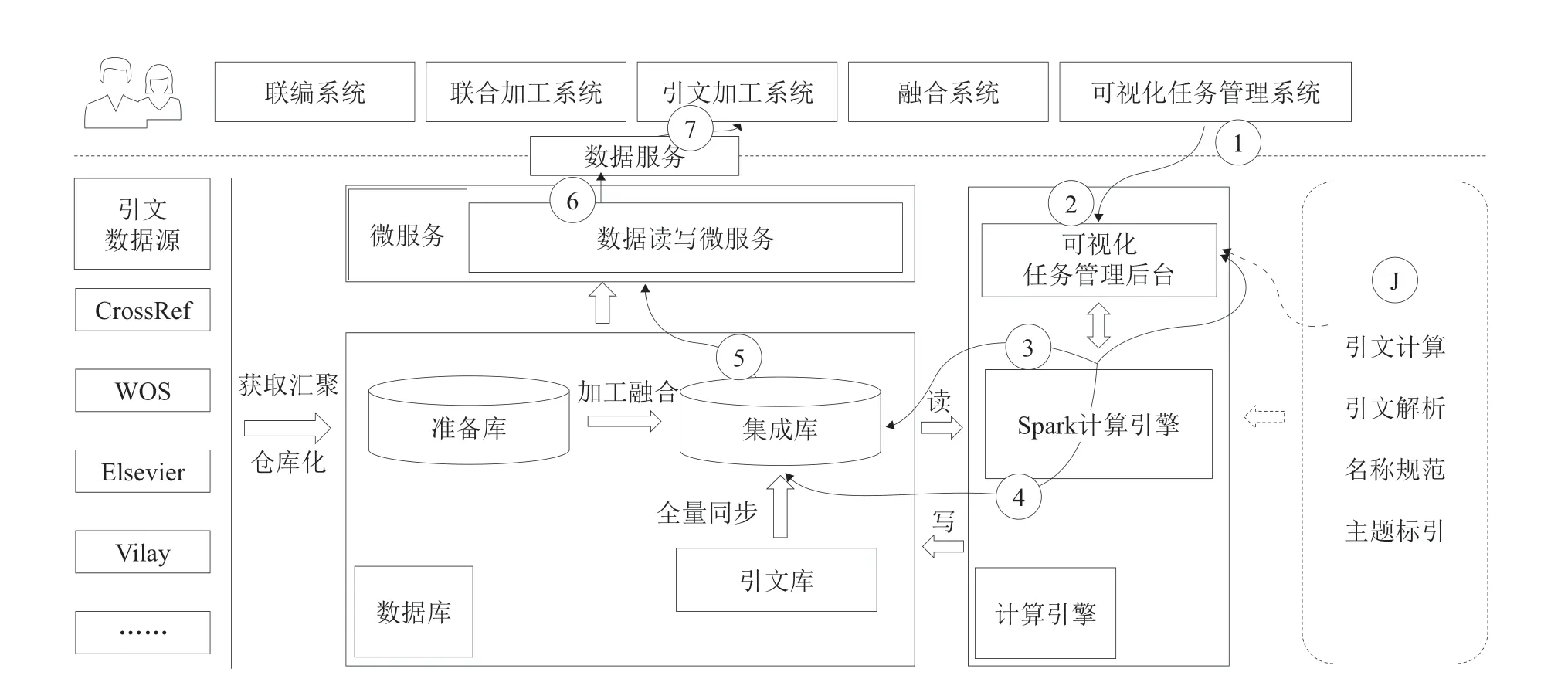
图5 引文关系计算架构
通过大数据基础环境,首先解决了海量数据存储的瓶颈问题,其次利用ElasticSearch搜索引擎解决了数据增量计算问题,最后利用Spark计算引擎提升了计算效率。
3.3 微服务技术应用
基于大数据基础环境中微服务系统,可轻松建立各种类型的数据输出服务接口,各服务接口独立部署,动态扩展,稳定性较高。如通用文献获取接口(XML与JSON格式)、引文关系计算的被引频次与耦合度接口、实体规范关系接口等。部署的接口通过松耦合且独立灵活方式无缝对接NSTL其他业务系统,实现特色数据服务。
4 结语
本文通过基于大数据开源生态圈技术,自主研发满足NSTL大数据管理与计算需求的平台,实现了NSTL业务流程再造目标,解决了数据存储与计算瓶颈,提升了数据治理能力与数据服务能力。同时也探索了基于大数据技术的数据治理框架,并结合NSTL数据服务特点介绍了相关应用示范。未来将基于前期基础,不断实践与探索,进一步优化流程和完善平台,提升文献数据的服务质量,以适应从文献服务向知识服务转变的发展战略。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
铁道通信信号(2020年4期)2020-09-21 09:15:24
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
中国特种设备安全(2019年1期)2019-03-13 01:06:30
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
中国质量与标准导报(2015年2期)2015-02-28 22:27:23
