
基于自然语言的国网投诉工单智能分类模型构建
2020-07-29 08:55张兆芝陈翔高敏卢燕燊张钟杰
微型电脑应用 2020年7期
张兆芝 陈翔 高敏 卢燕燊 张钟杰


摘 要: 为了更好的深入挖掘投诉工单背后所蕴含的信息,从自然语言处理技术出发,对客户投诉工单进行深入文本挖掘。在对电力投诉工单进行数据清洗的基础上,运用jieba进行分词,构造专业词典提升分词准确度,并对特征进行降维,然后运用利用词袋模型对中文文本进行分词,利用Bagging集成模型,构造包括朴素贝叶斯模型、决策树模型等在内的多个分类器模型,实现对词频在不同业务中的分布情况的研究,并根据结果开展相应改进措施,把控住当下电力客户投诉的主要问题,为不同类型的电力客户提供差异化的服务策略,以落在实处的为客户解决难题。
关键词: 自然语言; 投诉工单; 分类器模型
中圖分类号: TG 409文献标志码: A
Construction of Intelligent Classification Model of Complaint
SheetstoState Grid Based on Natural Language
ZHANG Zhaozhi, CHEN Xiang, GAO Min, LU Yanyan, ZHANG Zhongjie
(Fujian Power Supply Serice Co., Ltd., Fuzhou, Fujian 350000, China)
Abstract: In order to better dig out the information behind the complaint sheet, based on natural language processing technology, customer complaint sheet is deeply mined. On the basis of data cleaning for power complaint worksheet, the key dictionary is constructed, and the dimension of the feature is reduced. Then the Chinese text is segmented by using the word bag model, and several classifier models including Naive Bayesian model and decision tree model are constructed by using Bagging integrated model. The distribution of word frequencies in different services is studied. Result corresponding improvement measures are carried out to control the main problems of current power customers'complaints, and to provide different service strategies for different types of power customers, so as to solve the problems for actual customers.
Key words: natural language; complaint worksheet; classifier model
0 引言
随着我国电力行业供给侧改革的深入,进一步提高客服人员管理的质量,提高用户的体验和客户满意度,成为当前电力企业的共识。而要提高客户的满意度,就需要从热点工单业务入手,对热点的工单业务进行挖掘,以此快速找到在电力服务中存在的短板。而在业务工单中,投诉工单和回访不满意工单,可直接的反应出客户对电力企业产品和服务的问题,也是客户满意度的一个最为直观的反映。因此,要转变和提升客户服务满意度,就需要从这类工单入手。但是从目前的方式来看,针对工单的分类处理,大部分是工作人员通过95598客户诉求数据进行分析,然后对其中的内容进行筛选,最后完成对不同工单类型的分类。这种方式虽然有效,当缺乏必要的辅助分析手段,从而导致分析效率不高,分析结果不够客观,进而影响了分析和解决的效率。对此,需要结合当前的自然语言处理技术和文本挖掘技术等,对95598来电工单进行智能分类,以实现对业务工单的智能化挖掘。而从具体的智能化处理方法来看,人们提出了各种方法,如王震(2016)结合95598的特点,提出采用LDA算法对工单进行分类;任华(2018)在采用大数据对电信投诉工单进行挖掘,以此大大提高了挖掘的效率。本文则在以上研究的基础上,提出一种基于自然语言处理技术的投诉工单分类模型。
1 构建目标
本文的研究思路是:以自然语言处理技术为车几乎,结合95598客户诉求问题,利用机器学习算法对工单进行智能分类,从而以机器替代人工,提升工单分析的效率,减少工作人员的工作力度,并提升分析的广度和深度。因此,本文构建的目标,是通过自然语言处理技术,完成诉求工单数据的处理,并通过机器学习算法,实现对工单的分类,以提高工单智能分类的效率与准确性,更好的实现用户诉求的精准定位。
2 整体解决方案设计
在上述构建目标下,以自然语言处理技术为基础,以数据标注为手段,对工单投诉业务进行重新梳理,然后建立分类规则、关键词典,以提取工单的特征,然后结合机器学习算法建立投诉工单分类模型,进而实现对95598工单的智能分类。整体解决方案如图1所示。
2.1 数据标注
文本分类 (tagging) 是一个有监督学习问题,需要事先准备好已经分类好的样本供模型进行学习。在本研究中,主要根据工单中的“受理内容”“处理情况”“受理录音文本”及“处理佐证录音”等作为智能归因分类的主要对象,通过分析其中的文本内容,完成对工单的智能化分类。同时在本文中,主要是以‘营销和‘运检两个方向作为业务的主要标注对象。具体标注过程如图2所示。
2.2 文本清洗
文本清洗是自然语言处理中的重要步骤。通过文本清洗,可减少词汇的噪音,继而得到更多更为有效的文本特征,并提高分类模型分类的精度。在文本清洗中,主要包括小写转化、去除标点符号和停用词去除等清洗工作。
2.2.1 小写转化
为更好的方便计算机对词义的辨识,需要将大小写进行转换。将文本中设计到的所有的英文文本全部变为小写,这样可避免出现相同副本的问题。比如,在文本词汇计算时,“Analytics”和“analytics”中因为大小写的不同,会被认为是两个不同的单词。
2.2.2 去除标点符号
删除标点符号,目的是减少训练数据的大小,从而提高训练的效率。
2.2.3 停用词去除
在文本数据的处理中,去除停用词的目的是为了减少信息对模型分类的干扰,所以一般在去除中,会创建一个列表stopwords,以此将其作为停用词库。
2.2.4 常见词和稀缺词去除
常见词、稀缺词和停用词一样,都是为了避免噪声干扰。在具体的常见词去除中,可以把常出现的10个字的文本数据抽出,然后删除;稀缺词则采用一般的形式去替代,以提高稀缺词的计数。
2.2.5 消歧转换
对文本描述中出现的同音错别字,需要进行转换,如“陪产”要根据具体的语音意思, 转换为“赔偿”。
2.3 特征提取
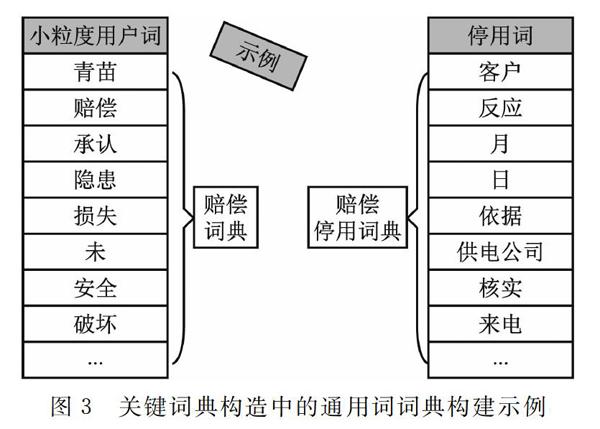
2.3.1 关键词典构造
在完成文本数据的处理后,则需要采用关键词典对文本数据特征进行提取。具体关键词典构造方法主要包含两种:一是建立投诉工单数据的小粒度用户词典和停用词典。其中,小粒度用户词典建立的目的是提高模型的泛化能力,而建立用户词典,是为了保证专有词的准确切分;二是过滤掉停用词词点钟的没有实际意义的词。具体示例如图3表示。
2.3.2 文本分词
文本分词的目的,是为了保证词语的准确切分。在具体分词方法上,吴刚勇(2018)在其发表的论文中,则采用了隐马尔可夫模型和Jieba包对投诉工单文本进行分词。在本文中,则采用词袋模型(Bag-of-words model)进行分词。所谓的词袋模型,是在自然语言处理和信息检索下被简化的一种表达模型。具体分词示例如图4所示。
2.3.3 赋权与选择
在完成词典提取后,结合词出现的相关指标,如词频数、词频率等,进行组合赋权,然后对比模型效果,提取最适合拟合模型的文本特征。在上述基础上,再对文本特征进行特征降维,以进一步提取与业务相关的特征。具体思路如图5所示。
3 分类器模型构建
特征分类是实现投诉工单智能化的关键。要实现工单的自动分類,就需要选定训练集的数据,然后借助分类器模型对工单数据进行分类,进而了解工单中的热点事件或词语,以此为下一步的电力营销服务改进提供借鉴与参考,实现电力营销被动转主动的方式,提高用户满意度和忠诚度。在本文中,在构建分类算法的基础上,使用AdaBoost进行集成学习,提高分类器精度。而在AdaBoost样本中,通常采用朴素贝叶斯和决策树分类器。
3.1 朴素贝叶斯分类器
朴素贝叶斯的原理是在给定分类变量的情况下,所有朴素贝叶斯分类器中给定目标值与属性之间相互条件独立。在给出的待分类项中,求解此项出现条件的条件下,各个类别出现的概率。那个概率最大,则认为此待分类项属于其中的某个类别。具体原理如图6所示。
3.2 决策树分类器
决策树表示的是对象特征与对象目标分类之间的一种映射关系。其中每个分叉的路径代表的是某个可能的特征水平,而每个叶节点则表示为对应的从根节点到该叶节点的路径表示的对象的目标分类对于给出的该分类项。具体步骤如图7所示。
3.3 集成学习模型构建
在分类器模型设计的基础上,考虑到不同数据的挖掘不平衡问题,采用Bagging进行集成学习。具体实现的思路为:在给定训练集的基础上,Bagging算法从中均匀、有放回地选出的多个子集作为新的训练集;而在新的训练集上,则采用多个模型进行训练,最后在通过投票表决等方法,得到最终的结果。具体来讲,在采用Bagging集成模型中,将贝叶斯分类模型、决策树分类模型都加入到该集成模型中,以用于对不同文本数据对分类。最后通过降低结果方差的凡是,提升对未出现文本的泛化能力。
4 分类结果验证
为验证上述方案的正确性,以分类的准确率、遗漏率、查准率、查全率等作为评价依据,并以“停电”作为分类示例,分析不同分类模型的对投诉工单的分类效果。具体是将训练集中的待分类工单输入至拟合分类器中进行分类,然后进行效果评估,评估结果如表1所示。
同时在全部输入投诉的工单后,分类器模型共识别出118张疑似停电工单。具体分类结果如图8所示。
根据图8的结果看出,在识别出的118张工单中,深藏着不同不同类型的意思停电工单,其中停送电投诉类工单为74张,占整体的62.7%;营业投诉类工单上为14张,占整体的11.86%;服务投诉类工单为2张,占1.69%。由此可以看出,在通过分类后,可以明确投诉类工单出自哪个部门,而电力企业则可以根据工单指向,对不同的部门进行考核和追责,并转变当前的服务方式,提高自身的服务满意度。
5 总结
通过上述的分析看出,在通过自然语言处理后,并结合机器学习算法,打破了传统的电力营销分析方式。而通过挖掘,也填补了在电力营销挖掘中存在的用电诉求盲区,为更好的实现用电需求侧的管理,提高自身的服务质量,提供了更为精准的信息化算法。
参考文献
[1] 厉建宾,朱雅魁,付立衡. 基于大数据技术的客户诉求分析与应用[J]. 电力大数据,2017,20(10):14-17.
[2] 李颢,张吉皓. 基于文本挖掘技术的客服投诉工单自动分类探讨[J]. 移动通信,2017,41(23):66-72.
[3] 周慧珺,龙涛,陈景航. 一种基于K均值的移动客户投诉数据处理算法研究[J]. 电信工程技术与标准化,2018,31(7):77-80.
[4] 刘海滨. 历史工单分析与智能派单的探索[J]. 信息通信技术与政策,2018(6):68-74.
[5] 吴刚勇,张千斌,吴恒超,等. 基于自然语言处理技术的电力客户投诉工单文本挖掘分析[J]. 中国设备工程,2018(17):154-156.
[6] 吴刚勇,张千斌,吴恒超,等. 基于自然语言处理技术的电力客户投诉工单文本挖掘分析[J]. 电力大数据,2018,21(10):68-73.
[7] 门萍,郭瑞英,王一灵,等. 基于规约的电力客服投诉处理中心与地市公司现场处理投诉共享机制研究[J]. 机电信息,2018(30):148-149.
[8] 黄峰,王定军. 基于文本相似度的智能工单分析系统解决方案研究[J]. 电子技术与软件工程,2018(19):206-207.
[9] 朱龙珠,徐宏,刘莉莉. 基于深度学习的95598重大服务事件识别研究[J]. 电力信息与通信技术,2018,16(11):19-23.
[10] 任华,王铮,杨迪. 基于大数据技术的客服投诉智能分类与預警系统[J]. 电信科学,2018,34(S2):100-107.
[11] 徐俊利,赵江江,赵宁,等. 营销活动问题标签分类语料库的构建与分类研究[J]. 计算机应用与软件,2019,36(3):42-48.
[12] 刘兴平,章晓明,沈然,等. 电力企业投诉工单文本挖掘模型[J]. 电力需求侧管理,2016,18(2):57-60.
[13] 王震,代岩岩,陈亮,等. 基于LDA模型的95598热点业务工单挖掘分析[J]. 电子技术与软件工程,2016(22):190-192.
[14] 陈亮,王刚,王震. 并行LDA主题模型在电力客服工单文本挖掘中的应用[J]. 科技创新导报,2017,14(12):245-248.
[15] 杨兆明,于磊,袁纯良. 人工智能在银行工单处理系统中的应用与探索[J]. 中国金融电脑,2017(9):52-56.
[16] 罗欣,张爽. 深度学习在电力潜在投诉识别分类中的应用[J]. 浙江电力,2017,36(10):83-86.
(收稿日期: 2019.05.25)
作者简介:张兆芝(1976-),女,本科,高级工程师,研究方向:电力营销服务。
陈翔(1975-),女,本科,工程师,研究方向:客户服务。
高敏(1979-),女,本科,中级经济师,研究方向:营销服务。
卢燕燊(1983-),女,本科,中级经济师,研究方向:营销服务。
张钟杰(1988-),男,本科,工程师,研究方向:电力系统设计。
