
网络信息资源的冗余数据检测算法设计
2020-07-29 08:55谢娜
微型电脑应用 2020年7期
关键词:网络信息资源


摘 要: 针对网络信息资源中冗余数据提取精度差、非线性冗余数据难以提取,导致冗余数据的检测查全率及准确率较低的问题,设计了网络信息资源的冗余数据检测算法。针对网络信息资源中的线性冗余数据,采用经验模态分解方法提取冗余数据特征,通过特征时间序列得出其状态特征分布函数,据此构建线性冗余数据检测模型;针对非线性冗余数据难以检测的问题,重构非线性冗余数据特征,采用高阶累积特征后置聚焦搜索方法构建特征时间序列的指向性波束模型,实现非线性冗余数据的准确检测。实验结果表明,该算法能够准确检测网络信息资源冗余信息,对冗余数据的查全率为98%,检测准确率为95%,证明该算法性能优异。
关键词: 网络信息资源; 冗余数据; 检测算法; 经验模态分解
中图分类号: TP 311文献标志码: A
Detection of Natural Gas Information Abuse in Public
Resource Network by redundant Model method
XIE Na
(College of Electronic Information, Xianyang Vocational and Technical College, Xianyang, Shanxi 712000, China)
Abstract: Aiming at the problems of poor accuracy of redundant data extraction in network information resources and difficulty in extracting non-linear redundant data, which lead to low detection recall rate and accuracy of redundant data, a redundant data detection algorithm for network information resources is designed. For linear redundant data in network information resources, empirical mode decomposition method is used to extract redundant data features, and its state feature distribution function is obtained through feature time series, and a linear redundant data detection model is constructed accordingly. The problem of data is difficult to detect, reconstruct the characteristics of nonlinear redundant data, and we use the high-order cumulative feature post-focus search method to construct a directional beam model of feature time series to achieve accurate detection of nonlinear redundant data. Experimental results show that the algorithm can accurately detect redundant information of network information resources. The recall rate of redundant data is 98%, and the detection accuracy rate is 95%, which proves that the algorithm has excellent performance.
Key words: network information resources; redundant data; detection algorithm; empirical mode decomposition
0 引言
網络信息资源以文本、图像、音频、视频、软件、数据库等多种形式存在,网络信息资源的开放性,导致数据存在重复的现象。冗余数据会占据网络资源,对冗余数据检测能够使得网络信息资源有更好的可扩展性,可以有效帮助资源网络节省存储空间,提高网络带宽利用率。网络信息资源中冗余数据具有时变性和随机性的特征,且非线性冗余数据更是难以检测[1]。针对这一问题,相关学者对网络信息资源的冗余数据检测算法做出了研究。
冯慧芳等针对冗余数据的时变性现象,提出时序特征分析方法,解决了线性冗余数据难以检测的难题。但是存在无法检测非线性冗余数据的缺陷[2]。常志朋等提出高阶Markov链方法,解决了非线性冗余数据难以检测的难题,但是存在检测查准率较差的缺陷[3]。潘越伟提出基于高阶谱分析的资源滥用行为预测和异常检测模型,解决了冗余数据检测准确度较低的问题,但是未考虑非线性冗余数据检测的问题[4]。
以上3种方法存在未考虑非线性冗余数据的问题,冗余数据检测的查准率及查全率还有待提高,因此本文针对以上问题,提出一种网络信息资源的冗余数据检测算法。对网络信息资源中的冗余数据进行时间序列拟合和特征采样,构建冗余信息模型检测线性冗余数据;根据相空间重组方法重构非线性冗余数据特征,在重构后的相空间中提取高阶累积特征,采用高阶累积特征的后置聚焦搜索方法实现非线性冗余数据的准确检测[5]。最后通过仿真实验验证了所设计算法的有效性。
1 基于瞬态时序规则的冗余数据检测算法设计
利用经验模态分解法提取冗余数据特征,分析冗余数据特征的时间序列,得到冗余数据的瞬态时序规则,据此构建特征信息分布模型,根据冗余数据节点输出信号模型及数据接收模型得到冗余数据的检测模型,完成对冗余数据的检测[6]。
1.1 网络信息资源数据的瞬态时序规则
为准确检测网络信息资源的冗余数据,首先需要分析冗余数据的时间序列。冗余数据是一组非线性时间序列,将冗余特征序列分解重组,并分析、检测冗余数据的特征。
在网络信息资源的第i个通信节点,重组资源数据特征,得到冗余数据两个时序节点之间的坐标为(xs,ys),采用经验模态分解法,得到网络信息资源的冗余数据特征模型为式(1)。
式中,T为数据重组次数。分析网络信息资源冗余数据状态,得到冗余数据的状态特征尺度为式(2)。
其中,P为资源数据的幅值调制,I为网络资源的冗余数据振荡衰减,t为冗余数据重组次数。
对网络信息资源冗余数据输出信号进行经验模态分解,将复杂的网络冗余数据分解为一个多径的IMF分量,得到冗余数据的状态信息融合动态方程为式(3)。
上式中,rj(x)为网络信息资源冗余数据的信息融合误差,xi为IMF分量,s为网络资源数据。
在网络信息资源客户端接收到的冗余数据状态行为特征模型为g(t),结合冗余数据的状态信息融合动态方程,得到网络信息资源的冗余数据特征时间序列为式(4)。
设网络信息资源冗余数据的状态行为特征分布函数为式(5)。
其中,Wx(t,v)、Wy(t,v)分别表示横、纵向行为特征分布函数,t0为冗余数据起始重组点。此时,网络信息资源冗余数据在时序范围内的瞬态时序规则为式(6)。
由式(6)实现冗余数据的时间序列分析,在此基础上构建网络信息资源冗余数据检测模型[7]。
1.2 网络信息资源冗余数据检测模型构建
分析时间序列,得到冗余数据的瞬态时序规则后,构建冗余数据的冗余信息检测模型。冗余数据特征的信息分布模型为
式(7)。
式中,ue,k为信息分布序列,k为分布序列数量。采用冗余数据特征混叠谱分解方法,将uv,k按照uv和uk的组成原则时序特征分解,得到网络信息资源的冗余数据群延迟特征分布为式(8)。
通常情况下,网络信息资源中冗余数据特征信息的时间序列是时变非平稳的,在非平稳时变冲突过程中,采用相空间重构方法,分解冗余数据的时变信息,根据经验模态特征得到资源分布信息的带宽瞬态时序规则估计为式(9)。
式中,(t)为网络信息资源冗余数据的均匀采样的频谱均值,ck为比特反馈系数,τ为时间采样步长,bk是多尺度分解的平均发生频率,当权系数满足b0=0时,构建网络信息资源冗余数据节点输出信号模型为式(10)。
式中,a(t)和θ(t)分别是网络信息资源信道冗余的原始數据包络和不稳定节点输出相位信息,a(t)和θ(t)与网络信息资源传递数据信息通道的幅度和瞬时序规则有关,通过扩展信道均衡设计,得到通信节点由N=2P个阵元组成,则信息资源的冗余数据接收模型为式(11)。
其中,si(t)为资源链路结构模型中的第i个节点的接收到的网络冗余信息[8]。冗余数据发生节点输出的整个行为特征具有非平稳性,采用非平稳信号检测方法,得到网络信息资源的冗余数据的检测模型表示为式(12)。
可见,网络信息资源的冗余数据可以通过公式(12)模型检测[9]。
综上所述,得出基于瞬态时序规则的冗余数据检测算法整体流程,如图1所示。
分析图1可知,构建网络信息资源的冗余数据特征模型,根据冗余数据的瞬态时序规则构建信息特征分布模型,检测冗余数据节点输出信号,采用非平稳信号检测方法得到网络信息资源冗余数据的检测模型。
2 网络信息资源冗余数据的检测算法改进
在对冗余数据检测的基础上,针对非线性冗余数据难以检测的问题,根据高阶累积特征后置聚焦搜索方法,提取非线性冗余数据特征,构建非线性冗余数据检测模型,完成对非线性冗余数据的检测。
2.1 非线性冗余数据特征提取
对网络信息资源中的非线性冗余数据的非线性拟合和特征采样,假设网络信息资源非线性冗余数据输出信号的标量时间序列为
x(t),t=0,1,…,n-1,非线性冗余数据分布的频谱特征为式(13)。
式中,j表示采样发生频率[10]。采用相空间重组方法,在重构的相空间中提取得到非线性冗余数据高阶累积分量为g=[g(0),g(1),…,g(N-1)]T,此时网络信息资源非线性冗余数据的IMF分量之和为式(14)。
式中,ci代表各经验模态分解IMF分量,rn代表高阶累积量。采用双曲调频母小波后置聚焦搜索,得到非线性冗余数据的冗余时间点τ为时间t的函数,为式(15)。
式中,c为动态特征的时间窗口,构建网络信息资源的信道模型[11],描述为式(16)。
式中,an(t)为信道带宽。在重构的相空间中得到非线性冗余数据特征向量模型为式(17)。
式中,e为相空间重构特征量。根据公式(17)提取非线性冗余数据特征向量,以此作为搜索目标向量,进行非线性冗余数据的检测。
2.2 非线性冗余数据的检测
根据非线性冗余数据特征向量构建一个微分方程[12],表达非线性冗余数据的信息流模型为式(18)。
式中,h[z(t0+nΔt)]为非线性用于数据时间序列函数,ωn为非线性冗余数据时间序列测量误差值。
采用后置聚焦搜索方法完成非线性冗余数据正交分布向量分解[13],为式(19)。
式中,n-(m-1)τ,表示非线性冗余数据时间序列的分布时滞,m为在相空间中的嵌入维数。
由此构建网络信息资源的非线性冗余数据时间序列的指向性波束模型[14-15],完成对网络信息资源的非线性冗余数据的检测,为式(20)。
式中,λ为数据采样次数。根据上述算法,完成对冗余数据的检测。
由此可得用于络信息资源非线性冗余数据检测的算法,如图2所示。
分析图2可知,针对非线性冗余数据,首先提取其分布频谱特征,据此构建特征向量模型,利用后置聚焦搜索分解非线性冗余数据正交分布向量,构建非线性冗余数据时间序列的指向性波束模型,完成非线性冗余数据检测。
3 检测实验
3.1 实验环境及实验数据
为验证所提方法对冗余数据特征检测的有效性,设计了仿真实验。采用MATLAB仿真软件作为实验平台,利用C++编程实现网络信息资源中冗余数据检测算法的运行,以资源分布数据库中的数据及资源网络的中心交换机数据作为实验原始数据,选用1 024 MB网络信息资源,其中包含20个冗余数据,设置网络信息资源的资源搜索和相关行为特征的采集时间间隔5 min,离散采样发生频率为fs=10*f0 Hz=10 KHz,采样的样本长度为1 024 MB,冗余数据的训练集为频带2~30 kHz、时宽5.6 ms的线性调频时间序列。
采用文献[2]、文献[3]方法作为实验对照组,测试三种方法检测网络信息资源冗余数据的查全率及准确率。
3.2 冗余数据的检测查全率评价
在冗余数据检测的基础上,测试三种方法对融数据检测的及查全率,计算如式(21)。
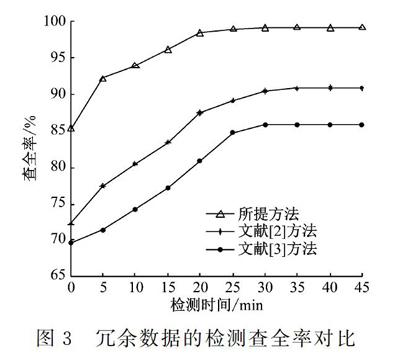
式中,A为检测到的冗余数据,B为网络信息资源。根据上述计算公式,对1 024 MB网络信息资源共进行10次检测并取每次检测结果的均值,得到冗余数据的检测查全率对比结果,如图3所示。
从图3结果得知,采用文献[2]方法检测冗余数据的查全率为89%,采用文献[3]方法的查全率为86%,而采用所提方法对冗余数据检测的查准率查全率为98%。根据上述结果得出,所提方法对冗余数据检测的查全率较高,说明所提方法的检测性能较好。
3.3 冗余數据的检测准确率评价
测试采用3种方法检测网络信息资源冗余信息的准确率,得到检测准确率的对比情况,如图4所示。
由图4可知,文献[2]方法对网络信息资源中冗余数据的检测准确率为60%,文献[3]方法对冗余数据的检测准确率为75%,而所提方法对冗余数据的检测准确率为95%。由此可以得出,采用所提方法检测冗余数据的准确率较高。
4 总结
本文提出一种基于经验模态分解及高阶累积特征后置聚焦搜索的网络信息资源冗余数据检测方法。采用经验模态分解方法,构建冗余数据检测模型,以此完成对网络信息资源中线性冗余数据的检测;采用相空间重组方法重构非线性冗余数据特征,提取高阶累积特征,根据高阶累积特征的后置聚焦搜索方法构建检测模型,完成对非线性冗余数据的准确检测。实验结果表明,所提算法能够有效检测到网络信息资源中的冗余数据,对冗余数据检测的查准率和查全率较高,能够保障网络信息资源的有效利用。
在保障公共网络资源利用效率的基础上,需要进一步保障网络信息资源的安全性和稳定性,未来将重点对这一方面做出进一步研究。
参考文献
[1] 陈虹君, 罗福强, 赵力衡,等. 大数据下网络信息资源丢失优化识别仿真[J]. 计算机仿真, 2017, 34(9):358-361.
[2] 冯慧芳, 张俊鹏, 杨茂. 基于时序网络的VANET拓扑特征分析[J]. 计算机应用研究, 2017, 34(10):251-254.
[3] 常志朋, 刘小弟, 张世涛. 基于高阶Markov链的重大决策社会风险变权集对预测模型[J]. 控制与决策, 2018, 33(12):134-141.
[4] 潘越伟. 网络中资源数据传输效率优化数学模型仿真[J]. 计算机仿真, 2018, 35(2):144-147.
[5] 曾明, 王二红, 赵明愿,等. 基于时间序列符号化模式表征的有向加权复杂网络[J]. 物理学报, 2017, 66(21):265-275.
[6] 张超. 基于双谱能量算子的碰摩转子故障特征提取[J]. 中国工程机械学报, 2018(3):269-273.
[7] 周雪燕, 孔梦荣. 多尺度纹理图像数据抗干扰信息映射方法研究[J]. 微电子学与计算机, 2017, 34(7):128-131.
[8] 朱飞燕. 大数据资源调度中多种类复杂信息智能定向检索[J]. 自动化与仪器仪表, 2019, 232(02):124-127.
[9] 陈宏涛, 刘帆, 张静. 结合多元经验模态分解和加权最小二乘滤波器的遥感图像融合[J]. 光子学报, 2019, 48(5):123-125.
[10] 王猛, 谭跃生. 云计算平台网络公共资源应急调度仿真研究[J]. 计算机仿真, 2018, 35(2):371-374.
[11] 汤建明, 寇小强. 海量网络文本去重系统的设计与实现[J]. 计算机应用与软件, 2018, 35(12):39-43.
[12] 任智, 李秀峰, 王坤龙,等. 考虑节点多社区属性的机会网络高吞吐量路由算法[J]. 小型微型计算机系统, 2018(8):1719-1724.
[13] 毛正雄, 赵志宇, 孙北宁. 基于Nginx的Web响应加速优化研究[J]. 自动化与仪器仪表, 2018(4): 31-34.
[14] 夏远远, 王宇. 基于HNC理论的社区问答系统问句检索模型构建[J]. 计算机应用与软件, 2018(8):98-101.
[15] 张仕学. 大型文本数据库中分布式数据去重备份方法[J]. 科学技术与工程, 2018, 018(004):310-315.
(收稿日期: 2020.03.28)
基金项目:咸阳市科学技术研究局攻关专项(2019k02-08)
作者简介:谢娜(1982-),女,硕士,副教授,研究领域:计算机网络技术等。
猜你喜欢
魅力中国(2017年14期)2017-07-28
卷宗(2017年13期)2017-07-19
中文信息(2017年5期)2017-06-08
现代情报(2017年4期)2017-05-18
中国管理信息化(2017年8期)2017-05-16
现代经济信息(2017年3期)2017-04-05
电子技术与软件工程(2017年3期)2017-03-22
电子技术与软件工程(2016年24期)2017-02-23
中国教育技术装备(2016年20期)2016-12-12
软件导刊(2016年9期)2016-11-07
