
富媒体聚合过程中人工智能应用研究
2020-07-26 14:23张路吴正威
软件导刊 2020年7期
张路 吴正威


摘 要:为了提高富媒体聚合过程的资源利用效率,特别是针对资料标签化工作量庞大的问题,运用语义分析与图片识别等一系列人工智能技术,对富媒体生产制作流程进行改进,可将资源标签化效率提高80%以上,为产出高质量的富媒体资源提供强大的技术支持。
關键词:富媒体聚合;人工智能;标签
DOI:10. 11907/rjdk. 192231 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)007-0046-04
Research on the Application of AI in the Process of Rich Media Aggregation
ZHANG Lu1,2,WU Zheng-wei3
(1.Central Propaganda Department Organ Service Center, Beijing 100052,China;2. School of Software,Beijing Jiaotong University, Beijing 100044,China;3.Jiangsu Ruitai Digital Media Co., Ltd., Wuxi 214072,China)
Abstract:In order to improve the efficiency of resource utilization in the process of rich media aggregation, especially in view of the huge amount of data tagging, a series of artificial intelligence technologies such as semantic analysis and image recognition are used to improve the production process of rich media, which can increase the efficiency of resource tagging by more than 80%, and provide strong technical support for the production of high-quality rich media resources.
Key Words: rich media aggregation; artificial intelligence; tag
0 引言
在短短20年间,信息技术的发展一日千里。随着计算机存储容量和网络速度的不断提高,每时每刻都会产生海量的多媒体数据。同时,随着交互技术的发展,除传统的鼠标键盘输入方式外,触屏交互方式颠覆了以往PC时代的人机交互界面,媒体交互也呈现出更为丰富的形式。
与此同时,出现了一种新的媒体呈现形态,通常被称为富媒体[1],即融合了文字、图片、音频、视频等,既包含媒体内容,又具备交互功能的一种媒体聚合形态。
聚合后的富媒体内容能更好地凸显与表现内容主题,因此深受人们喜爱。但同时也可以看到,在富媒体的生产制作环节,编辑们在海量的媒体资源面前,往往需要耗费大量精力对媒体资源进行整合。富媒体聚合面临多种问题亟待解决,这也成为当下富媒体应用的主要瓶颈。人工智能技术的蓬勃发展,为解决这些问题提供了很好的技术基础,将对富媒体的进一步发展起着重要的推动作用。
结合人工智能发展趋势[3-4],针对不同媒体资源,可以采取不同智能手段提升工作效率。针对文本,主要结合语义分析技术[8]对文本进行再加工;针对图片,主要采用图像识别的方式[11-12,20]提升工作效率。
本文将对富媒体制作流程进行梳理,同时在文本及图片应用场景下,对采用传统工作方式与人工智能技术后的工作效率进行对比分析,以体现运用人工智能技术的优势,并为富媒体未来的发展提出建议。
1 人工智能
1.1 人工智能定义
人工智能(Artificial Intelligence,AI)是研究、开发用于模拟、延伸与扩展人的智能的理论、方法、技术及应用系统的一门新兴技术科学,研究范围包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
1.2 人工智能发展
人工智能技术涉及学科较多,发展历程相对缓慢。由图1可以看出,在上世纪初期,人工智能的研究开始兴起,并从初级的手工知识阶段逐步过渡到统计学习阶段。到本世纪初,随着计算与存储技术的发展,大数据技术也日趋成熟,统计分析效率得到成倍提升,从而使人工智能技术也得到了飞速发展。伴随着深度学习的运用,目前已逐步迈入第三阶段的语境顺应阶段。
1.3 媒体技术中的人工智能
在媒体技术领域主要涉及机器视觉、语言与图像理解、自动规划、智能搜索、语音识别、语音合成等方面的人工智能应用。
富媒体制作是在获得各类媒体资源后进行聚合加工创作,之后再进行发布的过程。针对媒体聚合过程效率较低的问题,如何更高效地进行富媒体内容聚合,成为媒体人关注的首要问题。因此,可考虑通过引入人工智能技术以解决目前遇到的一些问题。
2 需求分析
如何对海量媒体资源进行有效的管理与应用,已成为影响日常富媒体制作效率的关键问题。针对不同媒体类型,有着不同的使用需求,以下将依次进行分析。
2.1 文本应用
文本内容属于最常见的内容载体,基于其自身特点,通常需要进行存储与检索。在检索过程中,用户会希望检索到更符合需要的文字,这种需求又可分为精确需求与关联需求,即推荐。常规或传统文件工具是以关系型数据库为基础的平台,由于缺乏分词能力,往往会检索出很多无效数据,从而导致制作效率低下。
同时,作为出版内容,敏感词审核也非常重要,但目前大量内容仍需要依靠编辑进行人工审核,工作量巨大,且效率不高。
另外,文本与音视频之间有着间接的耦合关系,特别对于儿童群体,由于认知的限制,无法有效进行阅读。如果能将文本转换为语音形式,則能让该群体接触到更多内容。但受限于人工配音的高昂成本,以及音色及场景的复杂性,传统方式无法实现规模化。
2.2 图片应用
在图片领域,涉及到对图片的鉴别,即确认图片来源的合法性与可用性。在版权意识逐渐强化的大背景下,判断素材资源是否涉及侵权,是否存在如色情/涉政等非法内容,也需要在使用图片前进行鉴别。同时,对图片中文字合法性的审查也是十分必要的。
图像识别结果主要体现为标签化,即通过编辑的查看对图片进行标签化管理的过程,标签化主要为了便于在后期应用过程中快速找到相应内容。人工方式同样存在效率低下的问题,比如在出现新的标签需求后,编辑需要重新对图片进行查阅,从而确认是否需要重新进行标签化,这一过程费时又费力。
2.3 音频应用
音频由于不可见,在应用过程中通常难以进行标签化处理。针对音频的标签化,一方面可对音频中包含的歌词内容进行分析与处理,形成标签;另一方面可针对音乐场景或情感制作分类标签,这类标签则更为复杂,同时依赖于个人的欣赏水平与音乐素养。对歌词内容的解析,需要事先将音频中的语音识别为文字,因此可运用语音识别技术,提取其中的语音信息转换为所需的文本内容。
2.4 视频应用
视频可认为是图像与音频的集合,同样需要对视频内容进行审查与标签化,而这一过程同样是耗时又耗力的,往往很难快速形成大量标注后的视频,因此也无法有效应用于实际需求中。
综上所述,在目前的富媒体制作过程中,需要对收集的媒体资源进行大量复杂的标签化工作。若缺乏有效标注,在选择素材时,检索或推荐素材的匹配度则会较低,需要更多人工介入。因此,本文考虑运用人工智能技术提高相关工作效率,从而进一步提升富媒体制作效率。
3 人工智能富媒体聚合平台设计
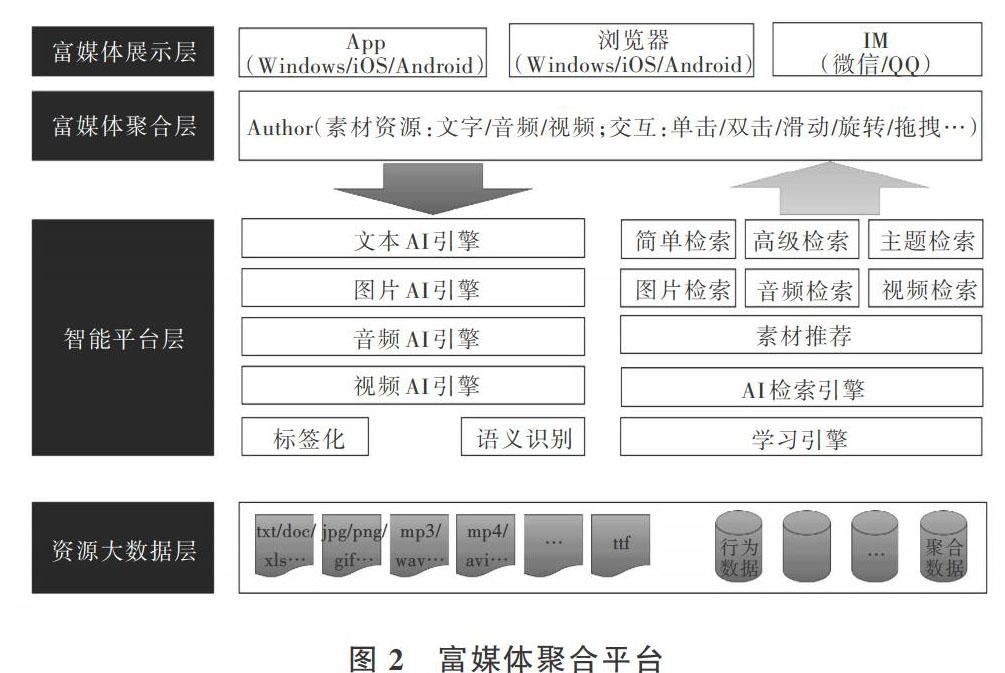
富媒体工具本身是基于对媒体资源的整合,而这些媒体资源往往是由后端平台承载的。本文构建一个智能化平台与富媒体工具进行无缝对接,在整个富媒体加工过程中充分运用AI技术。富媒体聚合平台如图2所示。
从媒体资源输入到媒体聚合后输出,通过集成人工智能技术,可提升整体工作效率。对于各类可文本化的资源进行语义化识别,之后进行相应标签化;对于不同场景,通过深度学习不断提高输入端处理能力。在制作富媒体资源时,系统可结合用户行为特征与主题内容特征进行精确查找与关联推荐,为用户提供高效的素材资源服务,从而加快富媒体资源聚合进程,高效、便捷地进行富媒体资源生产与输出。
4 人工智能技术应用
面对编辑不断提高的制作标准,本文考虑在不同领域应用不同的AI技术以解决目前所遇到的问题。
4.1 文本领域应用
文字存储与检索应用是数据库技术时代的基本应用,而在人工智能时代,单纯的文字检索已远远不能满足人们的应用需求。因此,通过智能的语义分析技术(NLP),可按照更符合人类日常的语言交流习惯,对被检索的文本对象进行标识,从而避免检索时出现词同义不达的情况。基于语义的分析,一方面可形成更精确的标签,另一方面可大大提高对敏感词的识别准确率,以避免过度过滤。结合行业、场景、业务等不同维度,可使各类文本标签形成相互关联、相互影响的标签网络体系,从而更好地理解用户检索需求。
另外,文字通过结合语音合成技术,可实现音频的快速输出,从而降低特殊人群获取文本内容时的门槛。更进一步,在获取用户属性信息的情况下,可结合不同语音角色进行针对性选择后再输出,如儿童可以使用卡通类配音,小学生可以使用青少年配音等,从而大大提升富媒体的表现力,使媒体内容更为丰富多彩,能更好地吸引用户注意力。
针对文本领域的应用,以下通过实验进行对比研究。通过人工方式对文本内容进行标签化,首先需要阅读全文,从中找到合适的标记内容。针对篇幅为一万字的文章,按照一个编辑500字/min的常规阅读速度,阅读时长大约为20min;然后结合阅读内容进行标签化处理,之后进行系统录入。录入时间因系统不同而存在差异,本文取平均约2min/个标签作为标签录入时间。一万字的文章在提取10个标签的情况下,整个工作时长预计为:20 min +2 min /个*10个=40 min。由此可知,完成10个标签的标记工作,从阅读、标记到录入共需要40 min的作业时长。同时这一工作是基于线性的方式,也即编辑在进行上述工作时无法同时进行其它工作。
采用基于人工智能的方式,首先运用语义识别引擎,阅读约16万字内容花费时间约为0.2s,解析准确率约为90%,即每万字平均阅读时间约为0.0125s;然后通过系统自动进行录入,10条标签信息记录在0.1s的时间内即可完成录入;结合业务需要,对入库的标签再次进行人工审核,10个标签,每个标签50个文字左右,预计总阅读量为500字,需要花费1min左右的时间。因此,运用人工智能方式结合人工审核模式,每万字的时间开销为:0.0125s+0.1s+1 min≈1 min。由此可见,每万字的标签化时间由原来的40 min减少到1 min左右,花费时间减少了97.5%。
以上是基于单个处理过程独立运行的场景,在充分利用计算机的并行处理能力之后,处理速度还有很大的提升空间。
4.2 图像领域应用
图像识别技术已日趋成熟,运用图像识别技术可以对大批量图像进行审核,从而过滤或标识出有问题的图像,比如暴力、色情及政治敏感的图像等。
运用事先训练好的标签库,可快速进行智能化标引工作,对不同物体、场景等高效地进行自动识别。在完成标签化工作后,需进一步提高用户使用过程中的匹配准确度。例如对太阳进行识别时,还可同时对太阳拍摄时间,如朝阳、烈日或夕阳等进行更精准的识别,从而使用户后期使用时能大大提高检索准确率。
识别工作并非一次性完成,在出现新标签或新场景时,需要对既有素材再一次进行识别与标签化工作。此时运用机器学习方法对新标签进行学习后,新标签的标注工作都可以交由人工智能技术完成,从而大大减少了编辑工作量。
图片检索技术的应用可有效解决在文字检索过程中,描述上存在一定局限性或不完整等情况。在形状、色彩、场景等无法进行精确描述时,图片检索方式将更为高效和便捷。如在图片版权审查方面,人工审查是比较困难的,通过图片检索技术,结合第三方图片版权库,可以有效提高版权审查效率。
针对图像领域的应用,以下也通过实验进行对比研究。在人工鉴图的场景下,平均效率约为1 200张/小时,即每秒0.33张(1张/3秒)。通过采用人工智能技术,如图3所示,在采用不同算法的情况下,单张图片的识别时间大约为不到1ms,而且随着时间推移,识别时间还会不断减少。
目前对单张图片的识别时间最快为0.637 3ms,换算成每秒,即1 569张/秒,相比人工方式提高了约4 707倍,在识别效率上提高了99.978 8%,而且准确率可达到92.980 2%,从而大幅提高了识别效率,对于无法确定的部分再由人工进行标注。
4.3 音频领域应用
通过语音识别技术将音频转换为文字内容后,可以再轻松地运用文本领域的智能化技术,在完成语义分析后进行标签化工作,从而极大地提高了语音内容的可标识性。
在制作不同主题内容时,针对场景需求,可以快速从媒体库中找到所需的音频素材,而不需要编辑花费太多时间聆听后再选曲。
4.4 视频领域应用
视频领域的人工智能应用可以综合运用以上语音、图片和文字的智能技术,提高视频内容标签化过程工作效率。其中对音频除常规应用外,通过集成翻译技术,可以将其转换成所需的字幕内容,使视频获得更多受众。
4.5 标签更新
随着时间推移,媒体资源库通常需要不断地添加与调整资源的标签内容,在做这类重复性工作时,同样可以采用人工智能技术进行初期筛选,之后再进行人工审核。长此以往,可以显著提升工作效率。
5 结语
本文对人工智能技术在富媒体制作过程中的运用场景进行分析,通过采用人工智能技术提高资源标签化效率,为产出高质量的富媒体资源提供了强大的技术支持。可以预见的是,未来随着人工智能技术的发展越来越成熟,很多低效率的重复性工作都可交由人工智能技术协助完成,从而使编辑和制作人员有更多时间投入到内容创作中,将对富媒体的进一步发展产生重要促进作用。
参考文献:
[1] 傅乃芹. 富媒体与文学出版物的富媒体开发[J]. 出版发行研究,2016(1):50-52.
[2] 刘琼昕,宋祥,王鹏. 面向出版社富媒体知识的文本分类研究[J]. 情报工程,2019,5(2):40-48.
[3] 汪涛. 人工智能发展将驶入快车道[J]. 中国科技产业,2019(9):10-11.
[4] 娄宇爽,李四达. 人工智能设计的发展趋势研究[J]. 艺术与设计:理论,2019,2(7):87-89.
[5] 吴戈. 机器翻译:语义还是数据——人工智能视域下的语义问题与哲学反思[J]. 河南社会科学,2019,27(4):75-80.
[6] 刘宓庆. 翻译与语言哲学[J]. 外语与外语教学,1998(10):42-45.
[7] 刘乔辉. 计算机人工智能识别技术的应用探讨[J]. 科技风,2016(4):121-122.
[8] 李振,周东岱,王勇. “人工智能+”视域下的教育知识图谱:内涵、技术框架与应用研究[J]. 远程教育杂志,2019,37(4):42-53.
[9] 高源. 自然语言处理发展与应用概述[J]. 中国新通信,2019,21(2):117-118.
[10] 赵园丁. 浅谈人工智能时代背景下自然语言处理技术的发展应用[J]. 办公自动化,2019,24(10):63-64.
[11] 郦涛. 基于人工智能的图像识别技术的研究[J]. 通讯世界,2019,26(8):69-70.
[12] 任萌. 图像视觉识别算法概述[J]. 智能计算机与应用,2019,9(3):294-297.
[13] 纪汉霖,黄嘉冬. 我国人工智能产业发展及应用研究[J]. 软件导刊, 2019, 18(3): 34-38.
[14] 过馨露. 人工智能技术及其应用探究[J]. 软件导刊,2018,17(2):35-37.
[15] 王晓阳. 人工智能能否超越人类智能[J]. 自然辩证法研究,2015,31(7):104-110.
[16] WU B,LYU S,HU B G,et al. Multi-label learning with missing labels for image annotation and facial action unit recognition[J]. Pattern Recognition, 2015, 48(7):2279-2289.
[17] ZHOU Z H,ZHANG M L,HUANG S J,et al. Multi-instance multi-label learning[J]. Artificial Intelligence,2008,176(1):2291-2320.
[18] THOMAS L,CAROL P,OANH D,et al. Evaluation of natural language processing (NLP) systems to annotate drug product labeling with MedDRA terminology[J]. Journal of Biomedical Informatics, 2018, 83:73-86.
[19] SOUILI A,CAVALLUCCI D,ROUSSELOT F. Natural Language Processing (NLP) -a solution for knowledge extraction from patent unstructured data[J]. Procedia Engineering, 2015,131:635-643.
[20] WENZHU Y,QING L,SILE W,et al. Down image recognition based on deep convolutional neural network school of cyber security and computer[J]. Information Processing in Agriculture,2018(2):246-252.
(責任编辑:黄 健)
猜你喜欢
科教新报(2022年43期)2022-11-27
西安航空学院学报(2022年2期)2022-07-04
IT经理世界(2018年20期)2018-10-24
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
