
基于K-S 检验与距离相关分析的网络借贷信用评价指标体系构建
2020-07-25 09:17
技术经济 2020年5期
(内蒙古财经大学经济学院,呼和浩特 010070)
一、研究背景
P2P 网络借贷(peer to peer lending,个人对个人借贷)系指资金出借方与借入方不是通过银行而是依托互联网平台建立借贷关系的无抵押贷款[1]。
网络借贷作为一种极具活力的新型互联网金融模式,具有无需中介、交易便利与覆盖面广等优点,备受借贷双方青睐,近年来获得了蓬勃发展。根据网贷之家发布的《2018 年中国网络借贷行业年报》显示,截至2018 年中国网络借贷行业累计平台达6430 家,全年累计交易规模为17948 亿元,行业参与人数突破千万。
网络借贷突破了时间与地点的局限,提升了金融资源的使用效率,缓解了小企业融资难的困局。然而,由于贷款门槛较低、缺乏专业信贷人员与借贷双方缺乏现实接触等因素,使得相比于传统信贷,网络借贷的信息不对称情况更严重,导致平台违约事件频发、信用风险日益加剧。信用风险过大已成为网络借贷发展的瓶颈。
科学评估网络借贷的信用风险,从而对网络借贷这一新经济业态的潜在风险隐患及时甄别与预防,对于互联网金融健康持续发展意义重大。网络借贷信用风险评估已成为备受关注的前沿领域[2]。
评价指标体系建立是网络借贷信用评价的基础环节,若是构建的评价指标体系包含大量重复或是不重要的指标,则运用何种评价模型均无法得到科学的评价结果。
目前网络借贷的信用评价主要侧重两类。
(一)信用评价指标体系研究现状
Francesco 等[3]通过相关分析筛选指标,建立了包括盈利能力、偿付能力、流动性状况和信贷质量共4 个准则的网络借贷信用评级指标体系。谭中明等[4]通过网络问卷调查方式与隶属度分析结合,利用因子分析方法,从流动性、透明度、品牌等方面构建网贷风险评价指标体系。蒋翠清等[5]运用信息增益、信息增益率及卡方检验对软、硬信息指标的重要性进行排序,通过封装筛选确定最优的网络信贷指标体系。张成虎与武博华[6]在网络调研与因子分析筛选基础上,构建了包含软信息的P2P 网络借贷信用风险评价指标体系。刘传哲等[7]以对称不确定性为基础测算指标间的相关系数,删除冗余指标,并利用异质集成模型对网贷信用评分问题进行研究。
现有信用评价指标体系的共同不足:一是现有信用评价指标筛选方法基本采用相关分析、因子分析剔除反映信息冗余的指标,上述方法仅仅揭示了变量间的线性关联程度,但P2P 网络借贷作为一种互联网金融创新模式,其海量、复杂的借贷数据往往具备非线性特征。因此,采用现有相关分析、因子分析无法揭示网贷信用评价指标间的非线性联系,从而导致信用评价指标筛选的结果不可靠;二是现有信用评价指标不能保证对客户违约与否进行有效甄别,这与信用风险评价这一根本目的相悖。信用评价目的是甄别违约企业与非违约企业。
(二)网络借贷影响因素的研究现状
Puro 等[8]通过美国网络借贷平台prosper 数据实证发现,网络借贷成功率与借贷利率及借贷额正相关。Lin 等[9]发现借款者的朋友关系可以降低借款者承担的利率并降低违约风险。廖理等[10]发现虽然借贷利率越高,借款者才容易获得贷款,但此类贷款的违约风险也更高。Emekter 等[11]认为信用评分、借款期限、负债收入比等对于借款违约概率有重要影响。Malekipirbazari 和Aksakalli[12]认为借款者的债务收人比也是影响借贷行为的一个关键因素。Lin 和Viswanathan[13]发现文化与地理位置是影响借贷重要因素,贷款者更倾向于借贷给地域接近、文化相近的借款者。何光辉等[14]运用Logistic 与Probit 模型对中国网络借贷风险决定因素进行分析。李杰和刘露[15]根据Logistic 模型发现借款者总收入、总支出是网贷违约与否关键因素。李延喜等[16]运用Logistic 与Cox 模型发现,借贷成功并不完全取决于贷款利率,借款者的年龄、学历及婚姻状况均有重要影响。
现有研究方法的不足之处:现有网络借贷影响因素中不仅涉及诸多不能显著甄别客户违约状态的指标,还涵盖不少信息重复的指标。
上述问题,本文在网络借贷信用评价海选指标体系,采用K-S检验选取可以显著甄别借款人违约状态的指标,进而通过距离相关分析剔除掉反映信息重复的指标,最终构建网络借贷的信用评价指标体系。并通过全球最大的P2P 网络借贷平台LendingClub 的实际交易数据进行实证研究。
二、网络借贷信用评价指标体系构建原理
(一)P2P 网络借贷的特点
(1)借款者和投资者之间不存在真实的接触,信息更加不透明,导致投资者对借款者的信用风险进行评价更加困难。
(2)现有关于银行各类贷款表现的研究[17-18]表明,消费者信用贷款在很大程度上会受到国内生产总值、失业率和利率等宏观因素的影响,因此如何控制这些宏观因素对于P2P 网络借贷信用风险的影响,将是一个重要的问题。
(3)P2P 网络借贷作为依托云计算、社交网络等新兴技术平台涌现出来的互联网金融创新模式,海量、复杂的网络借贷数据往往具备非线性、高维的大数据特征。
(二)网络借贷信用评价的问题
问题1:怎样从众多繁杂指标中遴选得到可以对网络借贷者违约状态显著分辨的重要指标。
问题2:如何克服现有指标筛选方法仅仅反映指标间线性关联程度的弊端。现有信用评价指标筛选方法基本采用相关分析、因子分析剔除反映信息冗余的指标,上述方法仅揭示了变量间线性关联程度,但P2P网络借贷依托于云计算、社交网络等新兴技术平台,其数据量极大,往往具备非线性特征。
(三)解决问题的思路
问题1 的解决思路:将企业数据分为违约和非违约两类样本,通过K-S检验比较违约样本与非违约样本的分布函数是否有显著差异,按照K-S检验统计值越大、违约样本分布函数和非违约样本的分布函数的偏离愈大,指标越能显著甄别客户的违约状态,选取可以显著区分违约状态与否的指标。
问题2 的解决思路:距离相关分析是近年来高维数据非线性相关分析的流行度量方法,其从特征函数的距离角度定义了两个随机变量间的非线性相关系数。本文采用距离相关系数反映指标间的线性与非线性的综合关联程度,在关联程度强的一对指标中,剔除K-S检验较小、对违约状态影响较小的指标,删除了反映信息冗余指标。
(四)评价指标筛选原理
通过K-S检验统计值的大小反映指标对违约状态分辨能力上的差异,按照K-S检验统计值越大、违约样本与非违约样本的分布函数的偏离越大,指标分辨客户违约与否的能力就越强。进而根据距离相关分析在两个关联程度高的指标中筛选出鉴别分辨违约状态能力强的指标。克服现有相关分析、因子分析等指标筛选方法仅揭示了指标间的线性关联程度和无法反映指标间的非线性关联程度的弊端,弥补现有研究不以能否区分违约状态为标准遴选评价指标的不足。
网络借贷信用评价指标体系构建原理如图1 所示。

图1 网络借贷信用评价指标体系构建原理
三、网络借贷信用评价指标体系的构建
(一)海选指标体系的建立
1.网络借贷信用风险的内涵
网络借贷信用风险指网络借贷中贷款者未能按照合同约定及时足额还本付息而给资金出借方带来的风险损失[13-15]。
资金出借方通过考量贷款人的还款能力及还款意愿这两方面来评估其发生违约的可能性。贷款人的还款能力可以通过贷款者年收入等财务特征与贷款者职业等个人特征来反映;而贷款人的还款意愿可由贷款者违约次数等个人信用特征来体现。
同时,现有研究[8-16]表明:贷款金额、贷款利率等借款特征也对网络贷款的信用风险影响显著。此外,现有关于银行各类贷款表现的研究[17-18]表明,消费信用贷款在很大程度上会受到国内生产总值、失业率和利率等宏观因素的影响,因此将外部宏观经济特征纳入网络借贷信用评价指标体系中。
2.准则层设置
3.海选指标体系的构建
以网络借贷信用风险内涵为基础,根据国内外网络借贷信用评价文献的流行高频指标[3-16],建立了包括借款金额、年龄等指标构成的涉及借款标的特征、借款者个人特征、借款者财务特征、借款者信用特征及宏观经济特征5 个准则层的网络借贷信用评价的海选指标体系,见表1。
(二)信用评价指标体系的建立
1.指标数据的归一化
指标数据归一化是把指标原始数据转化为[0,1]间的数,剔除单位及量纲对评价结果的影响。
信用评价指标可分成定量指标与定性指标。定量指标分为成本类型指标、效益类型指标及区间型指标。
成本型指标系指网络借款者的信用状况与指标的数值负相关,即指标数值愈大,则说明借款者的信用状况愈差。效益型系指标系指网络借款者的信用状况与指标的数值正相关,即指标数值愈大,则说明借款者的信用状况愈好。
临床生化检验属于医院重要工作内容,生化检测结果的准确性对诊断和治疗疾病产生直接影响[1]。血液样本溶血是指血液样本在临床检验过程中由各种因素影响导致红细胞被破坏,而细胞内物质进入血清,使得血清呈现出红色,进而影响生化检验结果准确性的医学现象。在当下临床检验实践过程中,若因血液标本溶血导致结果不准确而引发的医疗纠纷,医院往往处于被动地位,并可能需要承担全部责任,所以临床上如何避免或预防血液溶血对生化检测结果带来的影响依然是临床检验科室面对的焦点问题[1]。此外临床对纠正溶血所产生影响的措施缺少关注。本研究对溶血对生化检验准确性影响进行分析并总结相关应对措施,现将相关内容总结如下:

表1 网络借贷信用评价海选指标体系
成本类、效益类指标归一化公式[12]如下所示。

其中:xij为第i个指标第j个借款的归一化值;pij为第i个指标第j笔借款原始数据;n为借款个数。
区间型指标是指当指标的数据值落在某一个特定区间内都是合理的指标。例如:居民消费价格指数、年龄等两指标。指标“居民消费价格指数”理想区间是[100.6,104.7][17-18]。“居民消费价格指数”数值处于该区间中既不通货膨胀又不通货紧缩。根据对网络借贷平台发放调查问卷,发现将指标“年龄”合理区间范围设置为[30,48],即年龄处于该区间的借款者还款意愿、清偿能力都是最强的。
设q1为指标最佳区间左端点,q2为指标最佳区间右端点,根据区间指标的归一化打分公式[12]如下:
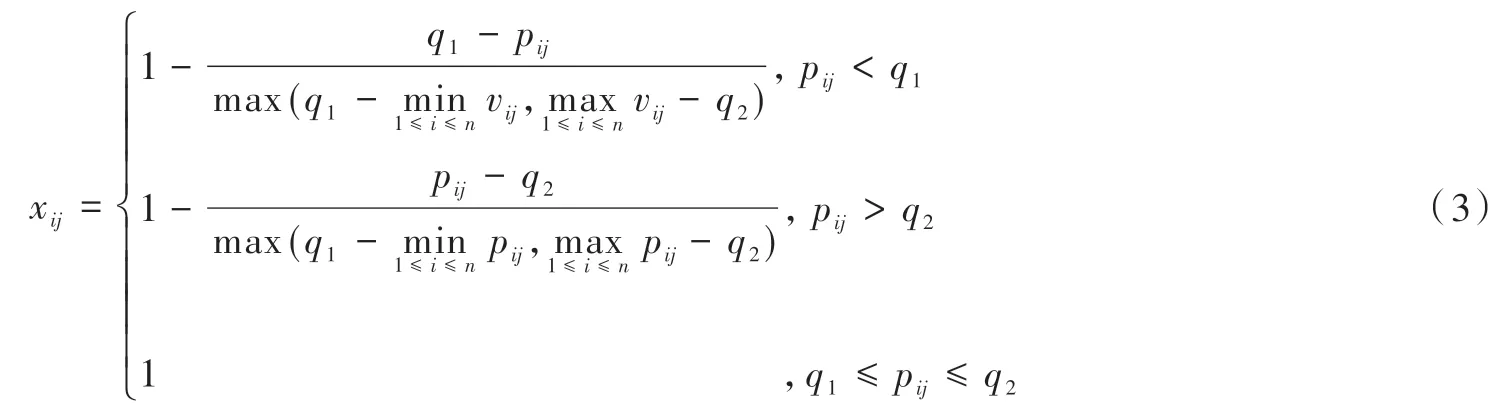
定性指标的标准化得分是在对网贷信用评价专家进行实地访谈调研基础上,按照定性指标的不同程度确定量化打分标准。见表2。
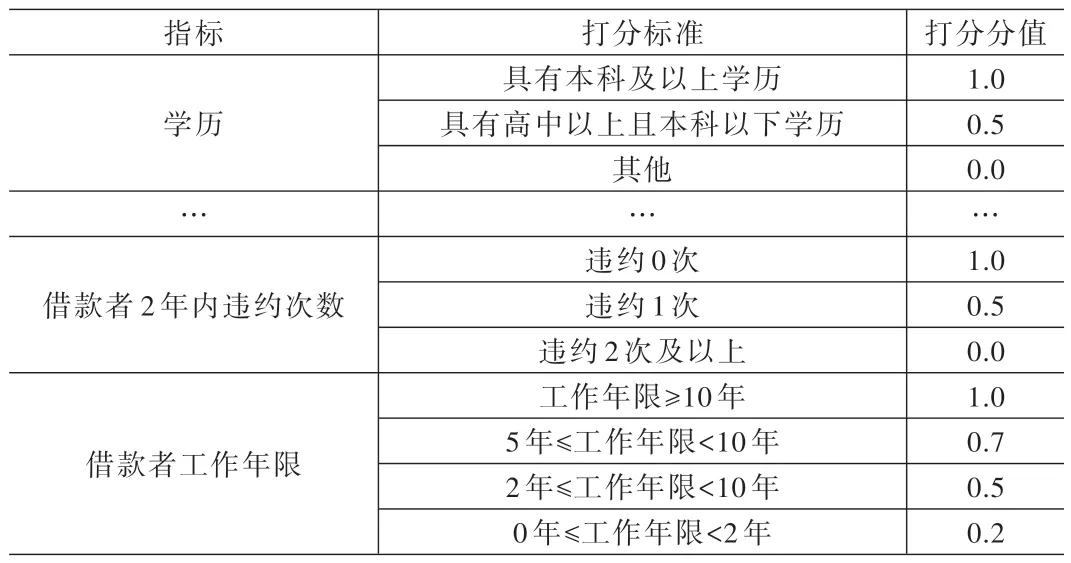
表2 定性指标打分标准
2.指标的正态分布检验
通过Jarque-Bera 正态检验,可判断指标是否服从正态分布。Jarque-Bera 正态检验步骤[19]如下。
(1)建立假设检验。
原假设:第i个指标Xi服从正态分布(H0)。
备择假设:第i个指标Xi不服从正态分布(H1)。
(2)构造JB统计量(即Jarque-Bera 检验统计量)。设为第i个指标标准化得分的平均值,n为样本借款总数,xij为第i个指标第j个借款的标准化得分,j=1,2,…,n,则


设Si为第i个指标偏度系数,由文献[19]可知

式(6)中其他字母含义与式(4)、式(5)相同。
设Ki-第i个指标的峰度系数,由文献[19]可知

设JBi为第i个指标Jarque-Bera 检验统计量,则

式(8)中其他字母含义与式(6)、式(7)相同。
(3)检验标准[19]。原假设H0 成立时,Jarque-Bera 检验统计量JBi服从自由度为2 的χ2分布[19],给定显著性水平α,查表可得χ2分布的临界值J0。若统计量JBi大于临界值J0,则拒绝原假设H0,即第i个指标Xi不服从正态分布;反之,则接受原假设H0,即第i个指标Xi服从正态分布。
3.违约显著区分的指标筛选方法
通过该方法可删除对违约状态区分不显著的指标。
按照某个指标数据,把借款数据分为违约和非违约两类,若该指标K-S检验值愈大,即违约的经验分布与非违约的经验分布的偏离愈大,说明评价指标甄别借款人是否违约的能力越强,指标对信用评价结果影响显著,应保留;反之,说明该指标无法有效区分违约借款人与非违约借款人,指标对信用评价结果影响不大,须删除。
K-S检验筛选指标的计算步骤如下。
(1)建立假设检验。
原假设:第i个指标的违约样本的分布与非违约样本的分布没有显著差异(H0)。
备择假设:第i个指标的违约样本分布与非违约样本分布有显著差异(H1)。
(2)构造K-S检验的D统计量。
步骤1:两类样本经验分布函数的确定。
以违约样本的经验分布为例。设违约借款个数为n1,非违约借款个数为n2,借款总数为n,n=n1+n2。
令xi1,xi2,…,xi,n1为第i个指标n1个违约借款的标准化值。将这n1个数从小到大排序,重新编号得到这n1个标准化值的次序统计量。同理得到n2个非违约借款的标准化值的次序统计量。

同理得第i个指标的非违约经验分布。

其中:v表示在第i个指标n2个非违约借款的标准化值中,小于等于x的标准化值的个数。
步骤2:K-S检验D统计量的确定。
设Di为第i个指标K-S检验的D统计量,I为由第i个指标n个借款的标准化值构成的实数集合,即I={xi1,xi2,…,xi,n},为第i个指标的违约经验分布,为第i个指标的非违约经验分布,由文献[19]可知

其中:第i个指标K-S检验统计量Di等于第i个指标违约经验分布与第i个指标非违约经验分布之差的绝对值的最大值。
K-S检验统计量Di反映了第i个指标区分违约状态的能力强弱。第i个指标的D统计量越大,第i个指标在违约样本与非违约样本中的差异越大,表明第i个指标区分违约状态能力越强;反之亦然。
式(11)采用K-S检验筛选指标的好处:一是按照违约样本与非违约样本的分布函数的差异越大,这个指标越能显著区分违约与否状态的思路,构造指标的K-S检验值,遴选能显著区分违约状态的指标,弥补现有研究不以能否区分违约状态为标准遴选评价指标的不足;二是采用K-S检验这一对评价指标的总体分布无任何要求、适用于分布未知的非参数统计方法筛选指标,克服现有方法要求指标服从正态分布的这一严格假设弊端。
(3)筛选标准。在原假设H0 成立时,第i个指标K-S检验的统计量Di服从Kolmogorov 分布[17]。给定显著性水平α,通过查表可得Kolmogorov 分布的临界值D0。
①若统计量Di大于等于临界值D0,则拒绝原假设H0,即第i个指标的违约样本分布与非违约样本分布有显著差异,说明违约样本与非违约样本能被第i个指标明显区分,则保留第i个指标。
②若统计量Di小于临界值D0,则接受原假设H0,即第i个指标的违约样本分布与非违约样本分布没有显著差异,说明违约样本与非违约样本不能被第i个指标明显区分,则删除第i个指标。
4.冗余信息剔除的指标筛选方法
该方法可在关联程度高的一对指标中筛选出违约甄别能力强的指标,确保得到信息不重复的指标。
距离相关系数是一种新型相关系数,其基本思想是根据两个随机变量的联合分布函数F(x,y)与各自的边缘分布函数FX(x)、FY(y)间的距离测度随机变量X与Y之间的相关性[20-21]。与传统皮尔逊相关系数、秩相关系数等线性相关系数相比,距离相关系数无论变量间是线性关系或是非线性关系均可度量,无需任何假设与分布条件,具有很强的普适性。因此,本文采用距离相关系数度量同一准则层下两指标间的相关性,进而进行冗余指标的删除。
距离相关系数筛选指标的步骤如下。
(1)距离相关系数的计算。设有m个指标,n个借据。令Xi为第i个指标归一化值的向量,即Xi=(xi1,xi2,…,xin)。则向量Xi与向量Xj的距离相关系数drij[20]为

其中:dcov(Xi,Xj)为向量Xi、Xj的距离协方差,由下式(13)计算得到。

其中:Akl、Bkl由式(14)与式(15)确定。

设xik为第i个指标第k笔借款的归一化值,则式(14)的4 个参数分别由式(16)~式(19)确定。

(2)临界值确定。设定临界值M∈[0,1],若距离相关系数绝对值 |rik|≥M,则删除两个指标中反映违约鉴别能力弱的指标。两个指标距离相关系数大于0.8 时属高度相关[20]。因此,选取临界值M=0.8。
(3)指标筛选标准。若第i个指标与第k个指标的距离相关系数绝对值 |rik|≥0.8 时,则第i个指标与第k个指标反映信息重复,应删除其中K-S检验值较小的;反之,说明指标反映信息不重复,同时保留两指标。
本研究筛选信息冗余指标方法的好处:通过距离相关系数删除反映信息重复的指标,保留K-S检验值大的,即对违约区分能力强的指标,避免对违约状态区分能力强的指标被误删,无论指标间是线性关系或是非线性关系均可适用,无须指标数据满足正态分布,适用于指标分布未知的情形。
(三)评价指标体系的合理性检验
信用评价指标体系合理与否是看基于指标体系构建信用评价模型的违约预测力是否显著。即检验利用指标体系构建的信用评价模型违约预测能力越显著,信用评价指标体系就越合理。
先利用上述指标筛选方法构建网络借贷的信用评价指标体系。再根据该指标体系及Logistic 模型可以计算得到每个借款者的违约概率(PDi)。将PDi与违约临界值比较,可对借款者是否违约进行预测。继而采用ROC 曲线(受试者工作特征曲线)AUC 值(ROC 曲线所覆盖的区域面积)对网贷信用评价指标体系的违约预测效果进行检验。
将实际违约借款被模型判定为违约借款数量记为DD;实际违约借款被模型判定为非违约的借款数量记为DN;实际非违约借款被模型判定为违约的数量记为ND;实际非违约借款被模型判定为非违约的数量记为NN,见表3。

表3 实际违约状态与模型判别结果划分
ROC 曲线涉及两个变量,灵敏度(Sensitivity)和特异度(Specificity),如式(20)和式(21)[22]所示:

灵敏度(Sensitivity)等于实际违约借款中被模型判定为违约的个数DD与实际违约借款总数(DD+DN)的比率,即借款违约状态的判对率。

特异度(Specificity)等于实际非违约的借款中被模型判定为非违约的个数ND与实际非违约借款总数(ND+NN)的比率,即借款非违约状态判对率。
ROC 曲线的纵轴为Sensitivity,横轴即1-Specificity,也就是1-借款非违约状态判对率。
ROC 曲线下方围成面积为AUC 值。当横轴不变时,纵轴越向上,即实际违约借款判对率越高,模型判别准确率也越高,ROC 曲线也越向上,曲线下围成的面积AUC 值也越大。因此,AUC 值越大,信用评价模型对违约状态判别准确性越高,信用评价指标体系也就越合理。
四、实证研究
(一)实证样本与数据来源
本文的指标实证样本来自美国P2P 借贷平台LendingClub 提供的借款标的数据[23],样本数据区间为2009—2014。Lending Club 成立于2007 年,是目前世界上最大的在线P2P 网络借贷平台,平台提供企业及个人信贷、房贷及消费贷款等借贷品种。在样本区间内,选取已完结的网络借款,并去掉数据缺失较多的指标,最终得到31000 条借款信息,对应31000 个借款人。非违约样本为27000 个,违约样本为4000 个。违约系指贷款到期后90 天内未能足额偿还贷款的本金与利息。P2P 网络借贷的指标原始数据见表4 第31000 列所示。表4 第33 行为贷款借款的违约状态标识,违约、非违约分别用“1”和“0”标识。
(二)信用评价指标体系的建立
1.指标的归一化
(1)定量指标归一化。根据表4 的指标类型,分别将表4 第1~31000 列的正向指标、负向指标、区间型指标数据pij代入式(1)~式(3),得到指标的标准化得分xij,列入表4 后31000 列各定量指标对应行。
(2)定性指标标准化。根据表4 的指标类型及表2 定性指标的打分标准,为表4 中的各个定性指标进行归一化打分。结果列入表4 各定性指标的对应行。
2.指标的正态分布检验
(1)Jarque-Bera 正态检验统计值的确定。以第1 个指标X1“借款金额”的Jarque-Bera 正态检验统计量的确定过程为例。把表4 第1 行指标X1的归一化得分x1j、借款总数n=31000 依次代入式(4)~式(7),得到指标X1的偏度系数S1=-0.531、峰度系数K1=-0.949。把偏度系数S1=-0.531、峰度系数K1=-0.949 代入式(8),得到指标X1的正态检验统计值JB1=126.412。将结果列入表5 第1 行第3 列。同理得其余指标的统计量JBi,结果列入表5 第3 列其余行。
(2)正态检验结果。原假设H0 成立时,第i个指标的检验统计量JBi服从自由度为2 的χ2分布[18],给定显著性水平α=0.05,查表得χ2分布的临界值J0=5.991。由于表5 第3 列的81 个指标的JBi均大于J0=5.991,由正态检验标准,则32 个指标Xi均不服从正态分布。在表5 第4 列用“否”标注。
由于所有32 个指标Xi均不服从正态分布,故本文采用K-S检验、距离相关分析的非参数统计方法筛选信用评价指标。
3.违约显著区分的指标第1 次筛选
(1)K-S检验值的确定。以指标“X1借款金额”为例。
步骤1:违约样本经验分布函数的确定。把表4 第1 行指标X1的4000 个违约借款的归一化值x1j按照从小到大次序排列,得到指标X1对应次序统计值。把得到的指标X1标准化值对应的次序统计值,n1=4000 代入式(9),得到违约样本经验分布。仿照上述过程,可得非违约样本经验分布。
步骤2:K-S检验值的确定。把指标X1第1 个借款的归一化值x11依次代入函数,得到x11的违约样本经验分布值、非违约样本经验分布值,得到|F1(1)(x11)-F1(2)(x11)|。同理,可得其余归一化值的违约样本与非违约样本经验分布值之差的绝对值。

表4 P2P 网络借贷指标筛选原始数据

表5 Jarque-Bera 正态检验结果
综上,总共得到指标X1的31000 个、违约样本与非违约样本的经验分布函数值之差的绝对值。求解这31000 个绝对值中的最大值即得到指标X1的K-S检验统计值D1,即。其中,I为由表4 第1 行指标X1的归一化值组成的实数集合。结果列入表6 第1 行第3 列。重复上述步骤1~步骤2,可得其余31 个指标的K-S检验统计值Di,结果列入表6 第3 列其余行。
(2)K-S检验筛选指标的结果。K-S检验统计量Di服从Kolmogorov 分布[19]。给定显著性水平α=0.05,通过查表可得Kolmogorov 分布的临界值D0≥1.358。
通过表6 第3 列可知,在32 个指标中,“X3还款月数”等13 个指标的K-S检验值全都低于1.358,检验不通过,说明这些指标的违约借款与非违约借款的经验分布函数并不存在明显区别,指标无法显著甄别借款者是否违约,应删除。通过表6 第3 列可知,32 个指标中,“X1借款金额”等19 个指标的K-S检验值全都大于1.358,表明这些指标的违约借款与非违约借款的经验分布函数存在明显区别,指标可以显著甄别借款者是否违约,应保留。

表6 K-S 检验指标筛选结果
4.冗余信息删除的指标第2 次筛选
(1)距离相关系数的确定。经过第四节第(二)节第3 小节的第一次筛选,删除了13 个指标,剩余19 个指标。将表6 第1~2 列的K-S检验保留的19 个指标按准则层合并,合并后的19 个指标进行距离相关分析的第二次指标遴选。用于距离相关分析的第二次指标遴选的19 个指标标准化数据见表7。利用表7 的标准化数据以及式(12)~式(19),可得到同一准则层下两个指标的距离相关系数。
以指标X1的和X2的距离相关系数计算为例。利用指标X1归一化得分x1j、指标X2归一化得分x2j及式(12)~式(19),得到指标X1和X2的距离相关系数r12=0.353。其他指标的距离相关系数类推可得。将所有指标中绝对值大于0.8 的距离相关系数 值rik列入表8 第5 列。表8 第2、4 列的Di来源于表6 第3 列的相应行。
(2)距离相关分析筛选结果。选取0.8 作为距离相关系数临界值。由表8 第5 列可知,共有7对指标的距离相关系数大于0.8,故此7 对指标属于反映信息冗余,在这7 对指标中保留K-S检验统计值Di较大的指标。由表6 第3 列的Di可知,max{D11、D12}={2.311、1.842}=2.311,指 标X11“年收入”的K-S检验统计值D11最大,故保留指标X11,删除指标X12,删除的指标列于表8 第2 行第6列。同理,其他的删除指标列于表8 第6 列的其他行。
综上,通过距离相关分析将K-S检验筛选后留下的19 个指标进行第二次筛选,去除反映信息冗余的7 个指标,最终保留了12 个指标。删除的7 个在表1 用“冗余信息删除”标出;最终保留的12 个指标在表1 用“保留”标出。
5.网络借贷信用评价指标体系的建立
在32 个指标中,根据K-S检验去掉区分违约不显著的13 个指标,利用距离相关分析删除7 个信息冗余的指标,最后建立了包含12 个指标的小企业信用评价指标体系,见表9 第a~d列。同时,最终保留12 个指标在表1 中用“保留”标出。

表7 进行距离相关分析的19 个海选指标的标准化数据

表8 经距离相关分析删除的评价指标

表9 网络借贷信用评价指标体系
(三)信用评价指标体系合理性检验
根据表9 的网络借贷信用评价指标体系及Logistic模型计算得到实证31000 个借款者的违约概率PDi(i=1,2,…,31000)。当取违约临界值为0.5 时,即当违约概率PD低于0.5,判定贷款者为违约;不低于0.5 判定贷款者为非违约。

表10 实际违约状态与模型判别结果
在31000 个借款者中,有4000 个违约借款者与27000 个非违约借款者。将4000 个违约借款者的违约概率PDi逐个与临界值0.5 比较,可得实际违约借款人被判定为违约的个数DD、实际违约借款人被判定为非违约的个数DN。同理可得到实际非违约借款人被判定为违约个数ND、实际非违约借款人被判定为非违约个数NN。计算结果列入表10 的数字矩阵。
表10 的数据代入式(20),得到灵敏度为0.897;代入式(21),得到特异度为0.902,也就得到横坐标1-特异度为0.098,这样就可以确定ROC 曲线上的一个点(0.098,0.897)。ROC 曲线中,每取一个临界值,就得到一组灵敏度和特异度,每个(1-特异度,灵敏度)可确定一个点坐标,取不同临界值50、60…,会得到多个点,可画出ROC 曲线,如图2 所示。

图2 检验指标体系的ROC 曲线
经计算,本文构建的网络借贷信用评价指标体系对违约与非违约借款者违约状态判别精度的AUC=0.913。一般认为违约判别精度AUC 超过0.8[19]时,评价指标体系的违约判别能力就较强。因此,由于本文构建的网络借贷信用评价指标体系的AUC=0.913>0.8,故认为构建的评价指标体系具有较强违约鉴别力,则评价指标体系构建合理。
五、结论与建议
(一)主要工作
本文根据K-S检验与距离相关分析相结合,筛选对借款客户违约状态甄别能力强的指标,建立了网络借贷信用评价指标体系,并通过全球最大的P2P 网络借贷平台Lending Club 的实际交易数据进行实证研究。结果表明:本研究评价指标体系中的借款金额、借款者职业、失业率等12 个指标均对区分违约状态有显著影响。
(二)特色与创新
(1)按照K-S检验统计值愈大、其对应违约样本分布函数与非违约样本分布函数的偏离愈大,表明评价指标甄别借款客户违约状态的能力愈强,遴选能显著区分违约状态与否的评价指标,弥补现有研究不以能否区分违约状态为标准遴选评价指标的不足。
(2)通过距离相关系数反映同一准则层下两个指标间的线性与非线性关联程度,在关联程度强的一对指标中,剔除K-S检验较小、对违约状态影响较小的指标,删除了反映信息冗余指标,克服现有相关分析、因子分析等指标筛选方法仅揭示了指标间的线性关联程度,无法反映指标间非线性关联程度的弊端,拓展信用评价指标筛选方法适用范围。
(三)启示及政策建议
本文采用K-S检验与距离相关分析构建的网络借贷信用评价指标体系,实证表明:借款金额、借款者职业、失业率等12 个指标均对区分违约状态有显著影响。上述研究有助于理解网络借贷违约行为及其变化规律,预测借贷违约的发生,进而在发放贷款时制定或调整相应的借贷标准,控制借贷违约的发生。
P2P 网络借贷作为新型经济业态,已成为拉动国民经济的重要增长点,但由于网络借贷的违约风险较难甄别,导致当前P2P 平台的相关监管存在一定程度的缺失或滞后。基于上述研究结果,本文提出如下政策建议:
(1)建议监管部门构建网络借贷违约风险评估模型,对P2P 平台进行风险监测。相关监管机构可以借鉴本文评价指标筛选方法,充分利用大数据技术,识别网络借贷的违约风险,从而对P2P 平台潜在的风险进行及时预判与控制。
(2)建立金融机构与P2P 平台的信息共享机制,融合多源数据。由于商业银行对借款者历史违约信息了解更多,监管部门应倡导银行等机构与P2P 平台加强信息共享,融合多维度信息,为准确地评估借款人违约风险提供充分的数据资源。
(四)不足之处及展望
本文主要属于应用性研究,在指标筛选方法的改进上创新有限,这也是本文的不足所在。在之后研究中,拟在信用评价指标赋权方面,按照对借款者违约状态区分能力愈强、指标赋权越大的思路,测算评价指标的权重。由于该项研究与本文的科学问题聚焦不同,因而本文未做进一步拓展,后续我们将另文专述。
猜你喜欢
今日农业(2021年5期)2021-11-27
蒙古学问题与争论(2020年0期)2020-03-29
领导决策信息(2017年13期)2017-06-21
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
中国流通经济(2015年10期)2015-12-05
商界(2015年9期)2015-10-15
商业会计(2015年11期)2015-09-18
民生周刊(2015年17期)2015-09-10
植物营养与肥料学报(2011年4期)2011-10-26
