融合无人机高分辨率DOM和DSM数据语义的崩岗识别
2020-07-25 03:48沈盛彧程冬兵王志刚赵元凌邓羽松
农业工程学报 2020年12期
沈盛彧,张 彤,程冬兵,王志刚,赵元凌,邓羽松,钱 峰
(1. 长江水利委员会长江科学院,武汉 430010;2. 水利部山洪地质灾害防治工程技术研究中心,武汉 430010;3. 武汉大学测绘遥感信息工程国家重点实验室,武汉 430079;4. 广西大学林学院,南宁 530004)
0 引 言
崩岗是华南广大风化壳坡地上发育着的各种形状的深切山坡崩陷凹地形,其冲沟沟头部分经不断地崩塌和陷蚀作用而形成一种围椅状侵蚀地貌[1]。崩岗的显著特点是侵蚀量大、爆发性强,并且发展速度快、突发性强[2],具有破坏土地资源、毁坏基本农田、恶化生态环境等危害,直接威胁着国土、粮食和生态安全。
自1960年曾昭璇提出“崩岗”概念[1],至今已有60年,国内学者从地貌学、地质学、生态学、土壤学等不同专业角度对崩岗的发生、发育机理、监测和防控治理等方面已经开展了丰富的研究[3]。研究或治理崩岗,首要问题是识别研究对象崩岗。传统的崩岗识别方法,大多为在当地询问、现场寻找,不仅人力、物力成本高而且效率低,难以满足大范围崩岗调查的需要。如2005年12月,水利部组织长江水利委员会水土保持局与珠委、太湖流域管理局水保处组织流域崩岗侵蚀区内各级水保部门,历时16个月才完成了中国南方崩岗侵蚀现状调查[4]。
随着21世纪信息技术的飞速发展,3S技术等高精度空间手段被应用到崩岗研究中[5-7]。崩岗发现和调查在实际操作中改进为根据专家经验在高分辨率卫星遥感影像上进行人工解译搜索[8-9]。但由于在平面遥感影像上崩岗内部与平地裸土极为相似,且崩岗发育到中后期有植被恢复,边界并不明显,因此识别非常困难。近年来,无人机航测技术的爆发和普及,使得高分辨率(厘米、分米级)数字正射影像图Digital Orthophoto Map(DOM)和数字表面模型Digital Surface Model(DSM)等对地观测数据的获取日益容易,这种高精度空间信息采集手段也被越来越多地应用到崩岗调查和监测的定量研究[10-12]。而此类研究大都基于已知崩岗位置前提条件,崩岗发现还是前期通过人工完成,效率低,并未充分挖掘利用无人机所采集的高精度DOM和DSM的潜在价值。如何借助相关分析识别与挖掘技术,进一步结合崩岗自身特点,有效利用高分辨率DOM与DSM进行高效自动的崩岗识别,对于大规模低成本的崩岗调查和崩岗侵蚀机理的研究都具有非常重要的意义。
在遥感影像场景和对象的分类识别领域,为了提高识别精度、解决底层视觉特征与高层语义信息的关联问题即“语义鸿沟”[13],研究者借鉴自然语言处理中的语义分析方法,将词袋模型和概率主题模型[14]引入研究,并取得了不错的效果[13,15-19]。在水土保持应用方面,Cheng等[20]提出了一种基于BoVW(Bag of Visual Words)和PLSA(Probabilistic Latent Semantic Analysis)的场景分类方法从平面遥感影像中自动识别滑坡,较好地区分滑坡和非滑坡遥感影像。但总体来看,当前方法仅使用正射或平面遥感影像,较适合于仅针对角点、边缘、纹理特征明显的地物地貌(如道路、房屋、滑坡等),而对于地形特征明显,边界、纹理特征并不明显的崩岗识别效果并不好。DSM,即高程维度的信息,能很好地描述崩岗地形起伏复杂零碎,崩壁边缘陡变、倾角较大的特征,能有效地区分平坦或平缓地形。将DSM作为DOM的信息补充,融合DOM和DSM就如同给算法输入了三维模型,理论上将极大地提高崩岗识别率。
本文提出了一种利用无人机航测所获得的高分辨率DOM和DSM自动识别崩岗的方法。本文提出视觉-地形词袋模型(BoV-TW),并基于此对DOM和DSM所提取的局部特征进行混合描述,并通过LDA[21]进行潜在语义分析融合,最后使用支持向量机SVM[22]进行监督学习训练分类器,实现了崩岗的高精度自动识别。
1 材料与方法
1.1 研究区概况
研究区在湖北省通城县大坪乡坪山村,位于通城县西北角的半山区丘陵地带,113°48'E,29°18'N,亚热带季风气候,光照适中,气候温和,雨水充足,四季分明。根据2018通城年鉴记录,年平均日照时数1 706 h,年平均气温 17.1 ℃,历史最高气温 40.7 ℃,历史最低气温-15.2 ℃,年平均降雨量1 556 mm[23]。该区域土壤大多为由花岗岩母质发育的红壤,土壤结构松散,水土流失情况严重,崩岗侵蚀广泛分布。试验对象为该村附近的 3处发育晚期的崩岗,如图1所示。灌木、草木群落交错,伴有部分次生乔木,如图2所示,平均海拔110 m左右。
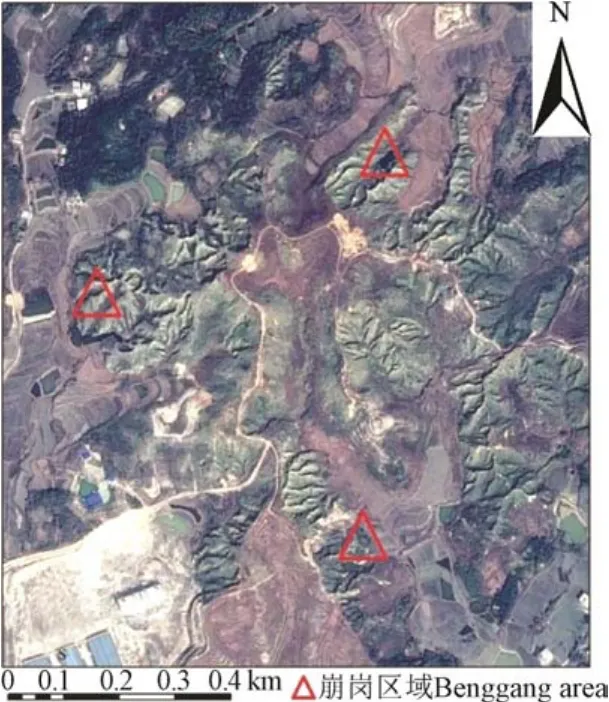
图1 研究区3处崩岗(2015年谷歌地球影像)Fig.1 Three Benggang in research area(Google Earth images in 2015)

图2 崩岗现场照片Fig.2 Benggang scene photos
1.2 数据采集
本试验数据采集于2016年9月,使用大疆精灵3P微型无人机,3个架次航线均设计为长500 m、宽200 m、航高150 m,来回2次航向重叠率70%,旁向重叠率60%。无人机航拍影像通过Photoscan v1.4.1进行拼接、空三、纠正、建模处理后获得 3块崩岗区域的 0.07 m分辨率DOM和0.15 m分辨率DSM,如图3所示。本文以1、2号崩岗数据为训练集,3号崩岗数据为测试集进行试验。
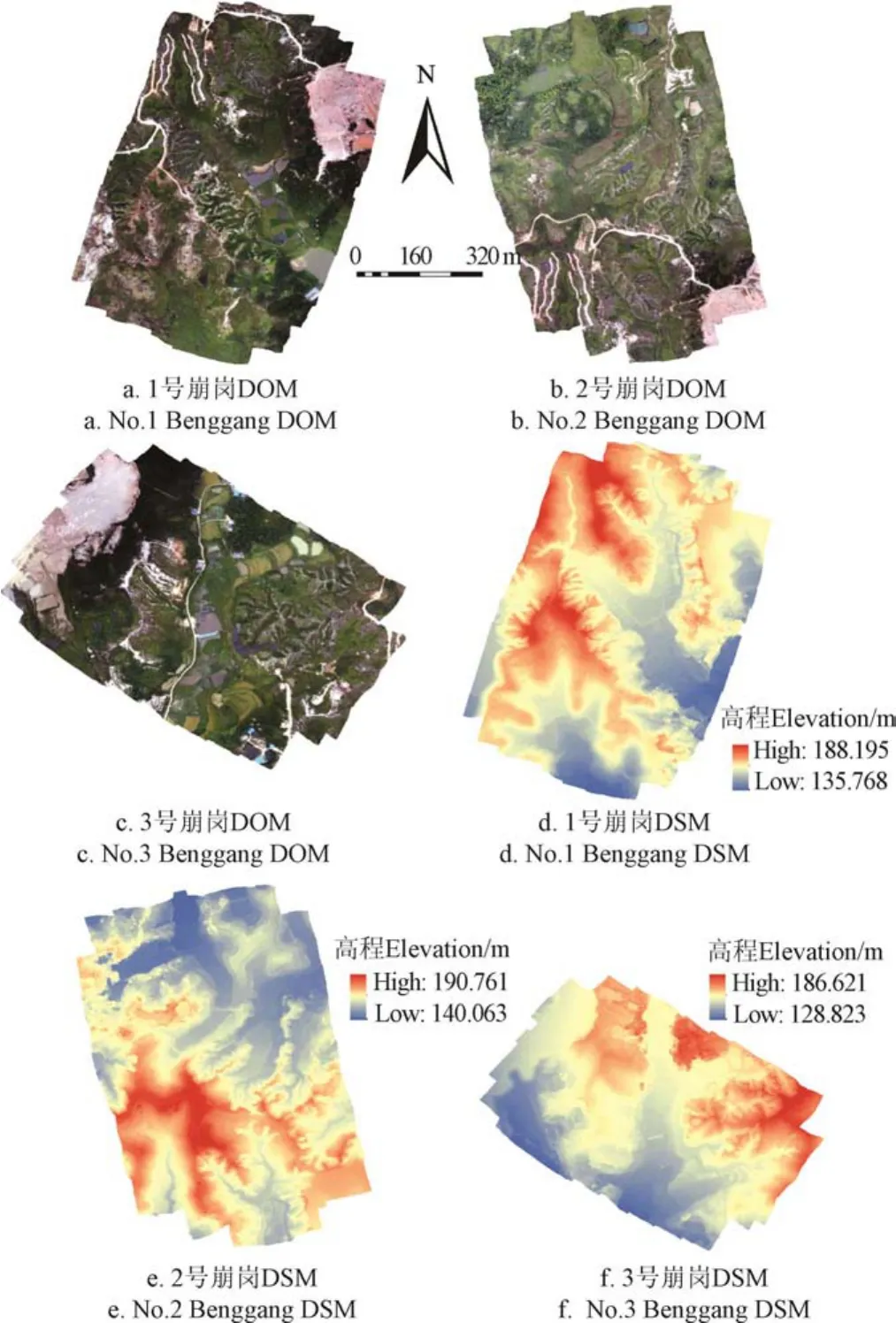
图3 3处崩岗的数字正射影像图DOM和数字表面模型DSMFig.3 Digital Orthophoto Map (DOM) and Digital Surface Model(DSM) of three Benggang
1.3 研究方法
1.3.1 关键理论
1)视觉-地形词袋表达
在自然语言处理中,文档集合的处理主要涉及 3个层次的实体,即“词项”“文档”和“文档集”,并定义如下:
① 一个词项是最基本的离散单元,通过特定词汇表定义为索引{1,2,3,…,V}中的一项,其中V为词项的总数量,即词汇表容量;
② 一个文档是一个由N个词项组成的序列,表示为W=(w1,w2,w3, …,wN),其中wN是此序列中的第N个词项;
③ 一个文档集是M个文档的集合,可表示为D=(W1,W2,W3, …,WM)。
Bag of Words(BoW)模型,即词袋模型,忽略文档中词项的词序、语法、句法和段落间联系,假设每个词项的出现是独立事件,将文档看作一系列词项的集合,只统计词项在文档中出现的次数。类似 BoW,Bag of Features(Keypoints)和 Bag of Visual Words相继被图像和计算机视觉领域的研究者提出[24-25]。他们将图像看作文档,将图像的底层视觉特征聚类后的中心看作词汇表用来描述图像。
本文方法在Bag of Visual Words基础上,进一步融入DSM局部特征,将地形局部特征聚类后的中心作为描述地形的词汇表,联合DOM局部特征形成视觉-地形词袋模型(BoV-TW),实现对崩岗区域的视觉-地形词袋表达。
2)局部特征
① DOM局部特征
按照计算机视觉领域的相关研究,Affine Covariant Regions(仿射协变区域)[26],如Harris-Affine[27]、Maximally Stable Extremal Regions(MSER)[28]等等,具有以下优点:多尺度视点描述不变性;对指定区域有较好的描述稳定性;对辐射变化具有较好的容错性,是描述高分辨率遥感影像是较好的选择。因此,本文方法采用Harris-Affine和 MSER两种视觉特征,再使用公认最好的 SIFT(Scale-Invariant Feature Transform)特征描述器[29]来描述特征。
② DSM局部特征
遵循地学原理,为保留主要地貌形态,并在局部抑制破碎的微地貌特征,本文方法采用三维Douglas-Peucker算法[30]提取地形特征点。为了保证特征描述的方向不变性和泛化性,本文方法设计的DSM特征描述是取特征关键点邻域范围的圆形窗口,计算出每个像素的梯度大小和梯度方向,并对各点的梯度采用反向距离加权,然后使用多个梯度方向来统计直方图,最后将主方向旋转至第一维度,实现描述向量的标准化。
3)LDA模型
LDA(Latent Dirichlet Allocation)是一种文档集的概率生成模型,通过基于概率的有限混合将词项、主题和文档 3个层次组织起来。每个文档可以表示为多个主题的有限概率混合,而每个主题对应于词汇表上的一个多项式分布,主题被文档集中的所有文档所共享。
将生成过程按模型描述,LDA的图模型如图4所示。其中,空心圆表示潜在变量,而实心圆表示观察变量;2个矩形框表示重复过程。内矩形表示文档中的N个词项从以β为参数的多项式分布生成的过程,外矩形表示文档集中的M个文档中的主题从以α为参数的狄利克雷分布生成的过程。
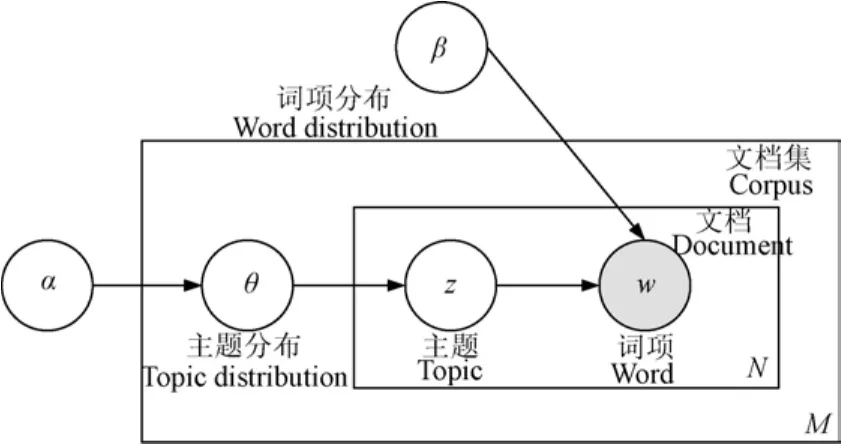
图4 LDA图模型[21]Fig.4 The graphic model of Latent Dirichlet Allocation
一个K维的以α为参数的狄利克雷随机变量θ的概率如下式所示:
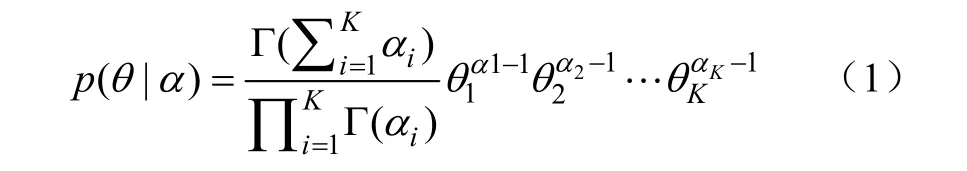
给定参数α和β,主题混合变量θ、N个主题的集合z和N个词项的集合w的联合概率可定义为
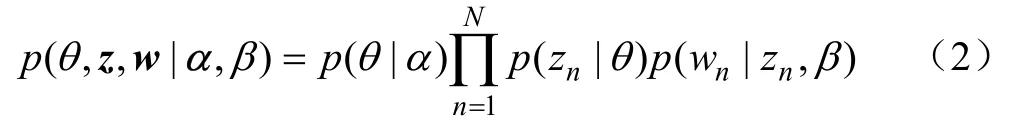
式中p(z|θ)代表使得= 1 的i所对应的θi。然后,对nθ积分,并对主题z求和,便可以获得文档的边缘概率:
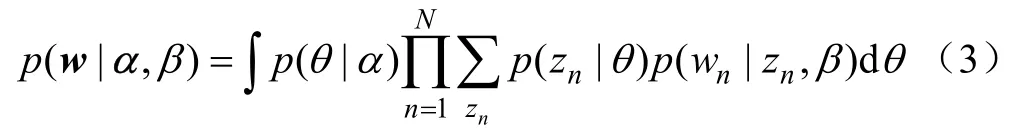
最后,通过连乘独立文档的边缘概率,就可以获得文档集D的概率:
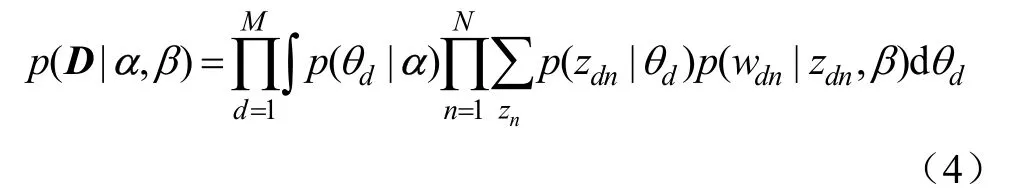
通过LDA的图模型不难看出,参数α和β是文档集级的参数,它们在生成一个文档集过程中只需要采样一次;变量θd是文档级的变量,每个文档需采样一次;最后,变量wdn和zdn是词项级的变量,对每个文档中的每个词项都要采样一次。
1.3.2 总体流程
本文方法流程共分为五大部分:1)DOM和DSM数据预处理;2)局部特征提取与描述,视觉-地形词汇表生成;3)崩岗训练集特征提取和词频统计,形成视觉-地形词袋表达,通过潜在语义分析建立 LDA模型;4)崩岗测试集特征提取和词频统计,形成视觉-地形词袋表达,基于已有 LDA模型生成概率主题分布表达;5)崩岗标记,SVM分类器训练,对崩岗测试集进行预测,完成崩岗自动识别,如图5所示。
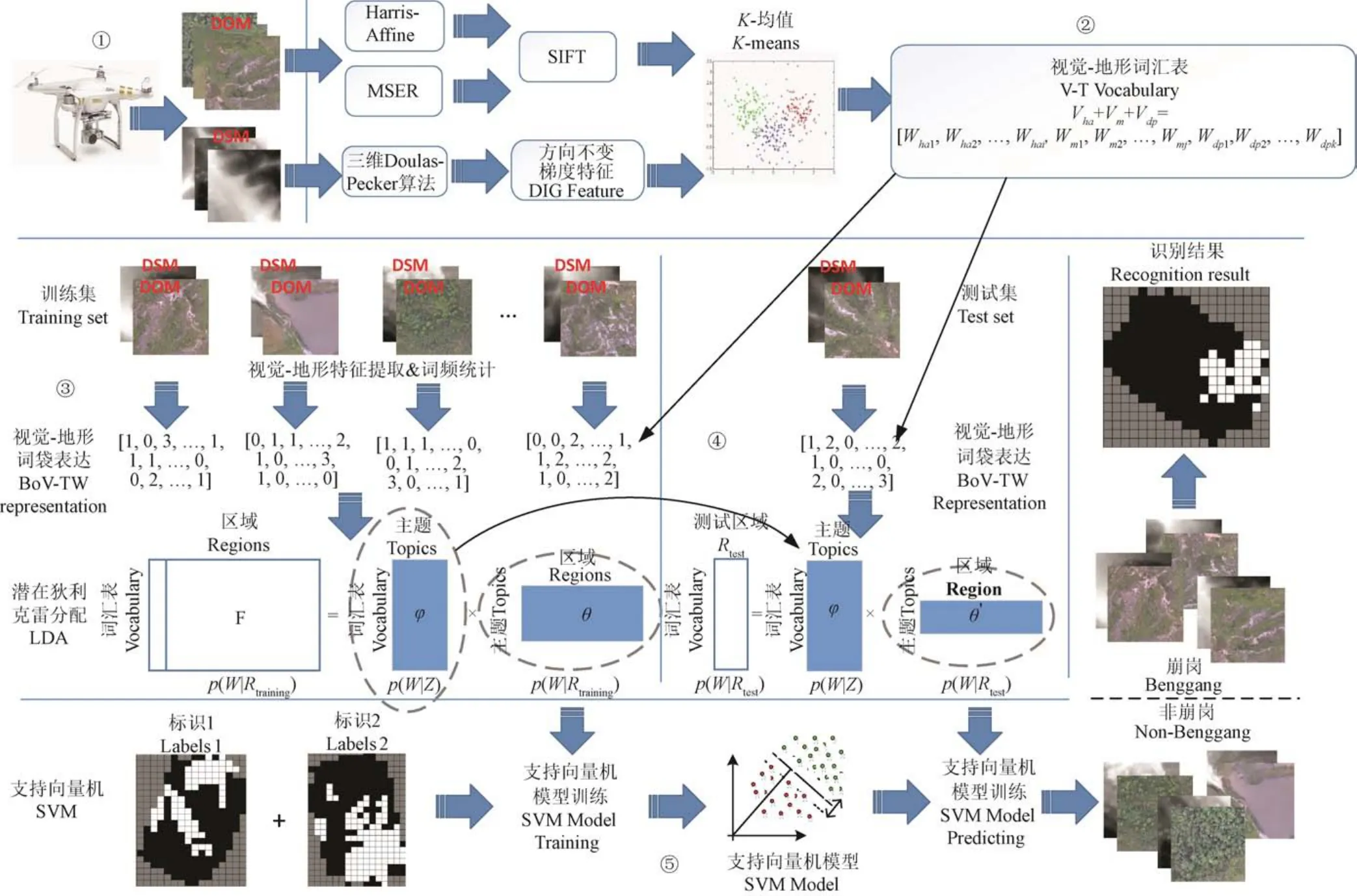
图5 崩岗自动识别总体流程Fig.5 Overall workflow of automatic Benggnang recognition
1.3.3 具体流程
1)预处理
本部分以图1中3号崩岗数据作测试集为例介绍数据的划分。本文方法采用均匀网格划分法将整个崩岗区域的DOM和DSM,统一以DSM的XY方向水平分辨率0.15 m划分为两两相对应的256×256像素瓦片,即每块区域约38 m×38 m。测试集DOM和DSM划分后的拼接图,如图 6所示。去除掉各种边缘拉伸形变过大和高程变化异常的瓦片后,1、2、3号崩岗数据分别得到240、291和208块区域。
2)视觉-地形词汇表生成
为了将每块崩岗瓦片区域表达成有限等长的向量能进行后期的潜在语义分析,就必须建立视觉-地形词袋模型的词汇表。
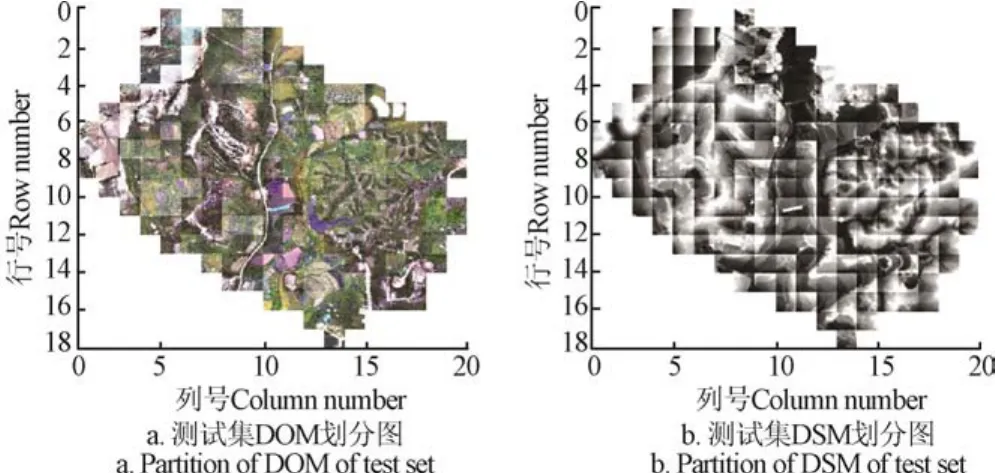
图6 测试集DOM和DSM的划分图Fig.6 Partition of DOM and DSM of test set
本文方法 DOM 局部特征采用了牛津大学 Visual Geometry Group(VGG)的Harris-Affine特征、MSER特征提取算法以及72维的SIFT描述器。本文方法设计的DSM局部特征,在提取3DDP地形特征点时,使用了2倍于水平分辨率的高程阈值,特征描述中邻域半径为 16个像素,梯度统计方向设定为24个。
对训练集DOM和DSM各531块,分别提取获得Harris-Affine特征描述25万个、MSER特征描述34万个以及3DDP特征描述10万个,再分别对它们做一定簇数(如500个)的K-means聚类,最后顺序连接形成(1500维的)视觉-地形词汇表。
3)LDA模型训练
通过视觉-地形词汇表,531个训练集区域可以使用kNN(k-Nearest Neighbor)算法表达为1500行×531列的共现矩阵p(W|Rtraining)。然后通过设定不同的主题个数,进行LDA训练实现潜在语义分析和降维,获得p(W|Z)和p(Z|Rtraining)。
4)测试集融合表达
对208个测试集区域进行DOM和DSM特征提取和表达,通过 kNN和视觉-地形词汇表,表达成词汇表达1500行×208列p(W|Rtest),再基于LDA模型训练生成的p(W|Z)通过Gibbs-resample重采样生成测试集的DOM和DSM融合表达p(Z|Rtest)。
5)崩岗与非崩岗场景分类
① 崩岗与非崩岗标记。为了获得最真实的分类标记作为验证本文方法精度和准确度的标准,本文采用了人工解译判读和现场复核相结合的方式对训练集和测试集进行崩岗与非崩岗标记。首先,通过从多视角和多尺度查看photoscan中利用无人机航拍影像生成的高分辨率崩岗三维模型,如图7a所示,根据地形、岩石/土壤、植被等的颜色、形态、纹理信息对照规划格网划分的DOM瓦片逐一进行目视判读。如果单块网格区域超过 50%以上面积是崩岗,才会被标记为崩岗,否则标记为非崩岗。然后,开展了现场复核,实地使用手持GPS定位,查勘了崩岗的集水坡面、崩壁、崩积体、沟道、冲积扇以及积水区等部分形态特征,并从细节上调查了基岩性质和土壤、植被类型,对照内业人工解译判读的崩岗区域进行定位核实,重点排查了被植被覆盖而无法从 DOM 和DSM中目视判读的崩岗区域,获得了测试集崩岗和非崩岗标记的最终结果,如图7b所示。训练集与测试集数据及分类标记情况如下表1所示。

图7 测试集崩岗三维模型和标记Fig.7 3D model and labels of Benggang of test set
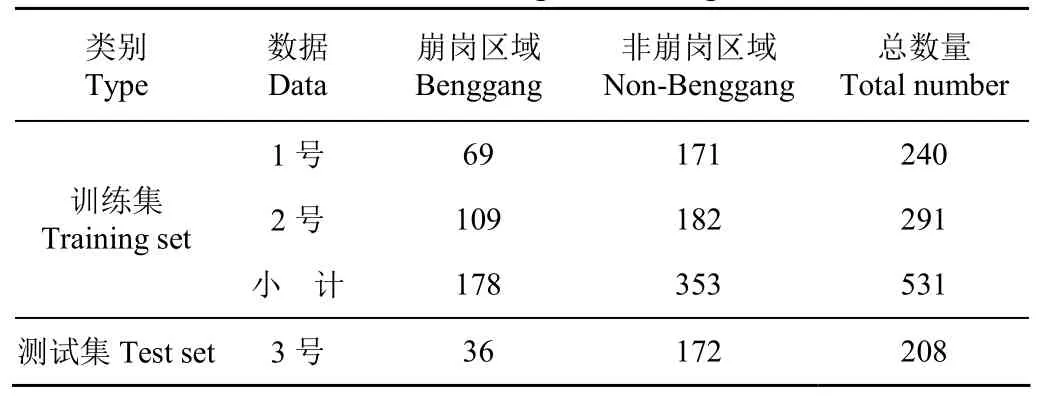
表1 训练集与测试集分类标记统计Table 1 Statistic of training set, testing set and labels
② SVM训练。利用LDA模型训练生成的p(Z|Rtraining)和训练集区域崩岗与非崩岗标识,matlab R2018a的SVM工具,以RBF径向基函数为核,进行2000次迭代训练,生成SVM分类器。
③ 测试集分类。将p(Z|Rtest)输入2)中生成的SVM分类器,获得测试集的崩岗与非崩岗预测值及标记。
2 试验结果与分析
为了证明结合DSM特征和使用潜在语义分析LDA进行融合能较好的提升识别精度和效果,进行3组对比试验。第1组为本文方法与仅基于DOM局部特征融合的方法[16]进行崩岗识别对比。第2组为本文方法与仅基于BoV-TW模型而不进行潜在语义分析的方法进行崩岗识别对比。第3组为本文方法与基于 ResNet50网络[31]的 DOM 及DOM+DSM两种数据源的崩岗识别对比。
本试验主要指标包括总精度(Total Accuracy,TA)、崩岗查全率(Benggang Recall,BR)和崩岗查准率(Benggang Precision,BP)3 个。其中,TP(True Positives)代表崩岗识别正确个数,TN(True Negatives)代表非崩岗识别正确个数,FP(False Positives)代表崩岗识别错误个数,FN(False Negatives)代表非崩岗识别错误个数。

2.1 与仅基于DOM局部特征融合的方法对比
本组试验中仅基于 DOM 局部特征融合的方法同样采用Harris-Affine和MSER两种局部特征。保持3种特征的提取方法、词汇表大小(每类词汇各500个)、SVM分类器参数不变,依次计算LDA潜在语义分析主题个数2~50个时2种方法的崩岗识别结果,如图8所示。

图8 基于DOM局部特征融合方法与融合DOM和DSM局部特征方法的崩岗识别Fig.8 Benggang recognition result of method based on fusion of DOM local features vs. the method based on fusion of DOM and DSM local features
仅使用DOM特征的方法,总精度在4个主题后就一直保持在85%左右,崩岗查全率保持在70%~85%之间,崩岗查准率在50%左右波动。而本文方法总精度在4个主题后就一直保持在95%左右;崩岗查全率在80%以上,在34、46、48个主题时获得最高的崩岗查全率97.22%;崩岗查准率在80%以上,在主题12个时获得最高崩岗查准率94.44%。最优识别效果出现在38个主题时,查全率为94.44%,查准率为85.00%,如图9所示。

图9 融合DOM和DSM局部特征方法的崩岗识别Fig.9 Benggang recognition of the method based on fusion of DOM and DSM local features
与基于DOM局部特征融合的方法相比,总精度、崩岗查全率和查准率 3项指标分别提高了约 12%、11%和32%。本文方法的崩岗识别效果整体较优。
2.2 与仅基于BoV-TW模型的方法对比
本组试验中仅基于 BoV-TW 模型的方法,在采用BoV-TW 模型生成视觉-地形词袋表达共现矩阵p(W|Rtraining)后,对各个区域的表达进行归一化处理,使每个区域的表达之和为1,符合概率分布要求,再进行SVM训练和分类。保持3种特征的提取方法,LDA潜在语义分析主题数为40个,SVM分类器参数不变,依次计算词汇表大小分别为300、600、900、1 200、1 500、1 800个时2种方法的崩岗识别结果(3类局部特征分别为100、200、300、400、500和600个)。
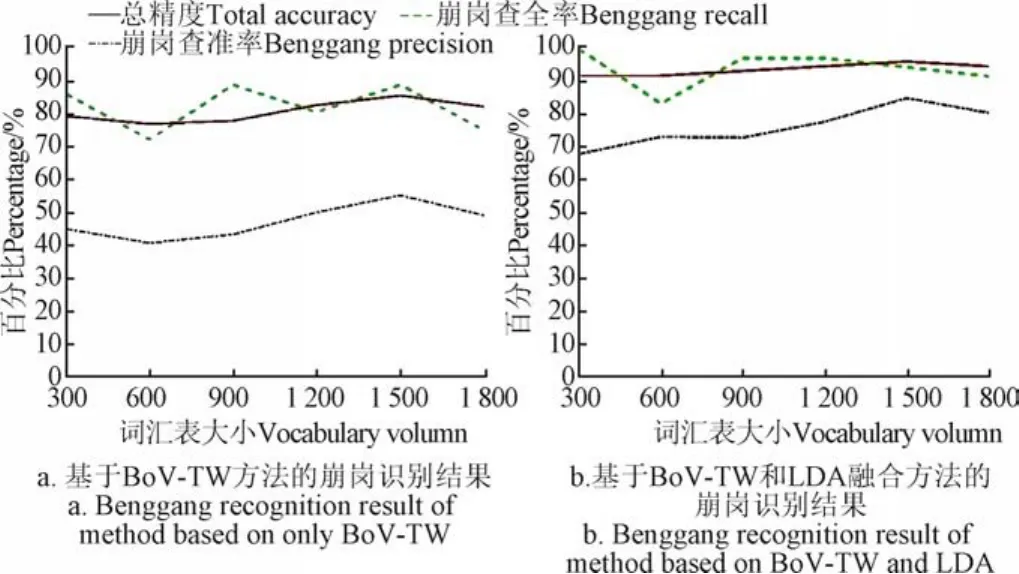
图10 基于BoV-TW方法与BoV-TW和LDA融合方法Fig.10 Benggang recognition result of method based on only BoV-TW vs. method based on BoV-TW and LDA
仅基于 BoV-TW 方法总精度在 80%左右,虽然崩岗查全率能达保持在80%左右,但崩岗查准率平均在50%以下。而本文方法总精度一直在90%以上,最高为 96.10%,崩岗查全率也基本在 90%以上,最高为100%,并且崩岗查准率随着词汇表大小的增加逐渐提升,到1 500个时达到最高的85.00%。与仅基于BoV-TW模型的方法相比,3项指标分别提高约13%、12%和30%。6种词汇量大小时的识别效果如图11、图12所示。证明运用LDA进行潜在语义分析实现多特征融合能大幅提高识别效果。
2.3 与基于ResNet50网络的方法对比
在崩岗研究领域,目前还没有基于遥感数据进行崩岗自动发现的相关研究,故选择当前计算机视觉领域图像识别公认效果最好的 ResNet50网络进行崩岗识别对比。具体测试分为2个:1)以DOM为数据源,RGB三层数据,使用pytorch的ResNet50网络预训练数据微调后进行崩岗识别;2)以DOM+DSM为数据源,RGB+DSM高程4层数据,并扩展 ResNet50网络输入使用 pytorch的ResNet50网络预训练数据微调后进行崩岗识别。
测试结果表明:基于ResNet50网络和DOM的方法前期迭代训练中总精度和崩岗精度波动较大,迭代至第 28次时收敛,如图 13a所示;基于 ResNet50网络和DOM+DSM的方法崩岗查全率波动较大,迭代至第54次时收敛,如图13b如所;本文方法的总精度、崩岗查全率和查准率都优于基于ResNet50网络的2种方法,详见表2。
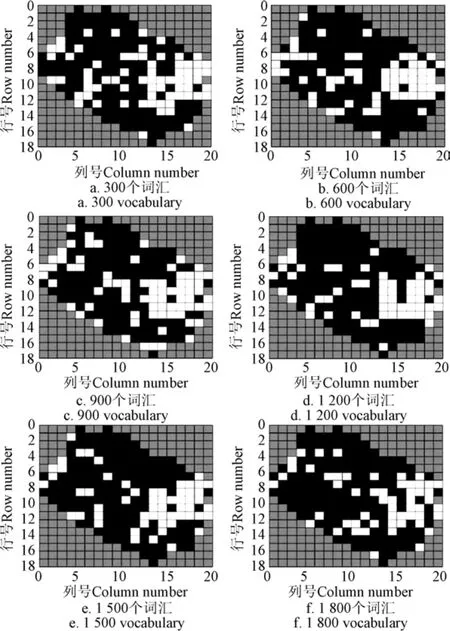
图11 不同词汇表大小时基于BoV-TW方法的崩岗识别Fig.11 Benggang recognition of the method based on BoV-TW with different size of vocabulary
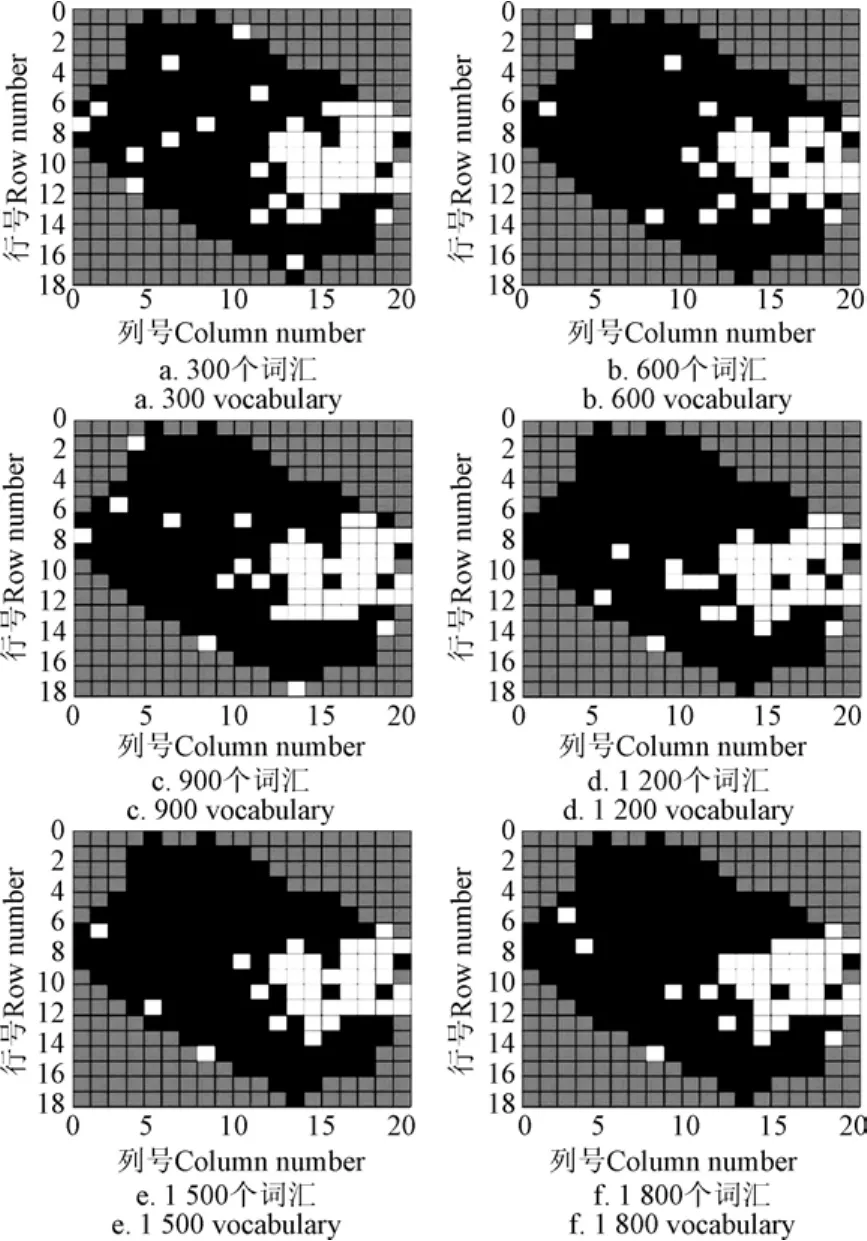
图12 不同词汇表大小时基于BoV-TW和LDA融合方法崩岗识别效果Fig.12 Benggang recognition result of the method based on BoV-TW and LDA with different size of vocabulary
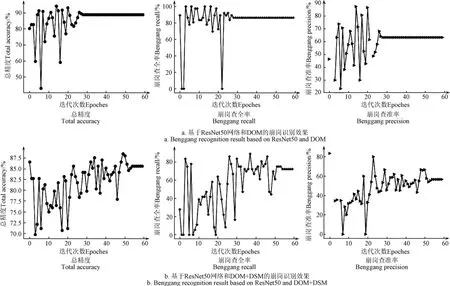
图13 基于ResNet50网络DOM和DOM+DSM两种数据源的崩岗识别效果Fig.13 Benggang recognition results based on ResNet50 with DOM and DOM+DSM two kind of data source
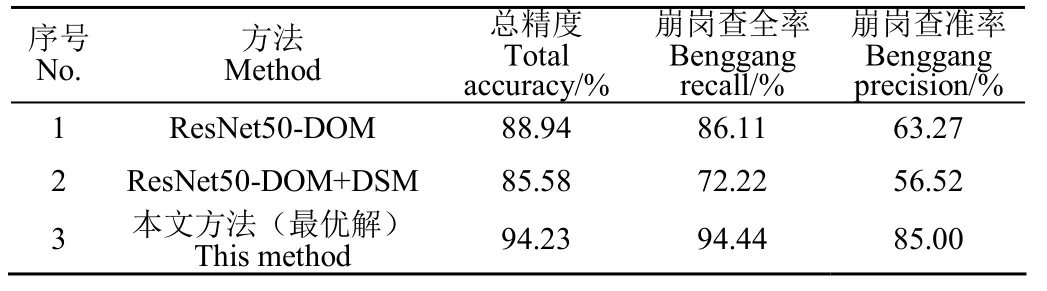
表2 3种方法崩岗识别结果对比Table 2 Comparison of Benggang recognition results of three methods
3 讨 论
3.1 创新性与先进性
崩岗作为一种自然地貌特征,很难仅通过人工解译DOM平面信息准确识别,因此基于DOM局部特征融合的方法查全率和查全率都不高。本文创新性提出结合DOM和DSM来识别崩岗,相当于为识别算法输入了三维模型信息。通过增加高程维度的信息,能有效利用崩岗区域高程差异显著的特点进而增强识别效果,因此总精度、查全率和查准率都有大幅度提升。图14展示了使用本文方法识别崩岗中LDA主题变化时,被识别为崩岗的DOM与DSM(图14a、14c、14e、14g)和非崩岗的DOM与DSM(图14b、14d、14f、15h)频次最高的各4个样例。其中,DOM上标注了DSM局部特征点,不难看出DSM局部特征点主要分布为高程变化复杂剧烈的区域。崩岗区域普遍分布着DSM局部特征点,再基于其梯度统计特征,就能较好的描述崩岗地形。非崩岗区中,图14b为乔木区域,图14d为乔木和建筑混合区域,图14f为水域与耕地混合区域,图14h为耕地区域,说明本文方法能将其他多种类型的区域都与崩岗区分开。但也会存在误判,如图15所示。

图14 崩岗与非崩岗区域样例Fig.14 Samples of Benggang and non-Benggang

图15 误判为崩岗频次最高的4个区域Fig.15 The top 4 misclassifications to Benggang
传统的崩岗研究专注于其发生、发育机理、监测和防控治理等方面,并没有将崩岗识别作为一个独立的科学问题进行研究,仅作为研究之前的一个操作步骤,往往采用当地询问、现场寻找等群策群力的方式开展[4]。随着亚米级高分辨率遥感影像和无人航测技术的普及,通过遥感影像进行崩岗的发现和调查成为了当前崩岗研究的热点[8-12],但崩岗发现本质上依然靠人工完成。本文方法提出通过机器学习的方式高效完成崩岗自动识别。
在遥感领域,当前遥感影像检索、分类以及识别等研究,多以高分辨率遥感平面影像为基础,主要研究人工地物对象的识别,如本文试验中使用的基于DOM局部特征融合的方法[16]和基于BoVW的方法、以及基于全局特征融合的方法等[15-19]。此类方法对自然地貌识别迁移效果不佳,对崩岗识别效果较差,不能直接使用。本文针对崩岗高程差异显著的特点,提出结合DSM高程信息扩展遥感影像识别的方法,获得了较好的崩岗识别效果,实现了遥感与崩岗学科研究的深度交叉。
同时,针对深度学习,本文也进行了以ResNet50网络[31]为例的对比试验。试验结果表明无论是以DOM作为输入还是以DOM+DSM简单叠加作为输入,ResNet50网络都无法实现令人满意的崩岗识别效果。前者印证了仅使用DOM无法较好的识别崩岗这种地貌特征,后者则说明即使有DOM和DSM的充分信息,没有有效的融合策略,崩岗识别效果仍然较差,甚至可能产生负影响。还可能原因是ResNet50网络预训练参数是以海量自然图像为基础,对遥感影像具备一定适用性,但对于DSM不适合。因此,一方面是需要海量的崩岗遥感数据作为训练样本,另一方面是研究更好的DOM和DSM融合策略,是后期基于深度学习研究崩岗识别的2个关键点。
3.2 局限性与复杂性
虽然本文方法识别崩岗的查全率和查准率已比较高,但仍存在一些的误判。图15a~15d是被误判为崩岗频次非常高的 4个区域,误判率分别为 92.53%、80.05%、62.69%、52.23%。它们的共同原因是在DOM上都有与崩岗相似的裸土和植被纹理结构,并且在DSM上都有植被或房屋产生的明显高程变化特征。
本文方法流程较为复杂,各处理环节的参数多,都对结果有一定影响,比如视觉和地形特征的选择和描述、各类特征词汇表大小、LDA主题个数以及 SVM参数设置等等。本文试验是在限定了大部分环节和参数后实施,仅针对词汇表大小和LDA主题个数变化进行,已获得较好的识别效果,如基于本框架,通过进一步优化调整各环节参数,将能获得更好的效果。
试验计算机配置为CPU i9 9900k,RAM 32GB,SSD 512GB,软件环境为Matlab R2018a。本框架下词汇表为1 500个、主题为40个时,各阶段的运算时间统计如下:训练集531个区域DOM的Harris-Affine和MSER提取和描述时间为187s,DSM的3DDP特征提取与描述为3 970 s,LDA训练时间为13.25 s,SVM训练时间为 1.24 s,测试集 208个区域 DOM 的Harris-Affine和MSER提取和描述时间为 68 s,DSM的3DDP特征提取与描述为1 536 s,LDA预测时间为0.27 s,SVM 预测时间为 0.05 s。其中,3DDP特征提取最为费时,主要因为算法中要迭代反复计算高程点到三角平面的距离,无法节省计算次数。
4 结 论
为了给大规模的崩岗调查、治理和崩岗侵蚀机理等研究提供研究对象和高效手段,本文提出了基于高分辨率数字正射影像图(Digital Orthophoto Map,DOM)与数字表面模型(Digital Surface Model,DSM)局部特征潜在语义融合的崩岗自动识别方法。借鉴遥感影像场景分类识别思路,本文提出建立视觉-地形词袋模型(BoV-TW)进行崩岗区域DOM和DSM局部特征的混合描述,再通过潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)潜在语义分析融合形成低维度高层次语义表达,最后以支持向量机作为监督学习训练分类器,实现崩岗的高精度快速自动识别。主要结论如下:
1)LDA主题个数变化时,本文方法总精度可保持在95%左右,崩岗查全率和查准率保持在80%以上,最高分别为97.22%和94.44%,与基于DOM局部特征融合的方法相比,总精度、崩岗查全率和查准率 3项指标分别提高了约12%、11%和32%,证明结合DSM局部特征后识别效果明显提高。
2)视觉-地形词袋词汇表大小变化时,本文方法总精度一直在90%以上,最高为96.10%,崩岗查全率也基本在90%以上,最高为100%,崩岗查准率随词汇表大小的增加逐渐提升,最高为85.00%,与仅基于BoV-TW模型的方法相比,3项指标分别提高了约13%、12%和30%,证明运用LDA进行潜在语义分析实现多特征融合能大幅提高识别效果。
3)本文方法优于基于 ResNet50网络以 DOM 和DOM+DSM 为数据源的 2种识别方法,印证了仅使用DOM无法较好的识别崩岗这种地貌特征,同时还说明没有合适的特征提取和融合策略,DOM和DSM结合也无法提高崩岗识别效果。同时,该方法时间花费少,效率高,可行性强。
下一步工作将尝试融合全局特征对DSM特征进行优化,并结合深度学习自编码方法对更多类型和发育阶段的崩岗自动识别进行研究。
猜你喜欢
客联(2022年3期)2022-05-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中华书画家(2021年12期)2022-01-06
中国新闻周刊(2021年26期)2021-07-27
散文诗(2020年1期)2020-07-20
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
电脑爱好者(2017年7期)2017-05-06
东方艺术·国画(2016年3期)2017-02-08
发明与创新(2016年38期)2016-08-22