
基于优化粒子群算法的云环境大数据聚类算法
2020-07-23 08:54胡毅朱子江
现代电子技术 2020年14期
胡毅 朱子江

摘 要: 对于传统云环境大数据聚类中的量子进化方法的聚类精准度比较低的问题,为了降低存储开销,提高数据管理能力与调度能力,提出将优化粒子群算法作为基础的云环境大数据聚类算法,对云环境大数据聚类原理进行分析,将传统模糊C均值聚类作为基础,通过粒子群聚类算法对大数据聚类算法进行改进,从而实现空间分割,得出云存储系统的海量数据模糊聚类。利用粒子群聚类方法分配聚类数据离散成本,得到数据聚类信息浓度;与粒子群优化聚类约束条件结合,得到云环境大数据聚类中心最优解。仿真结果表明,此算法的数据聚类精准度比较高,具有良好的收敛性能。
关键词: 大数据聚类; 云环境; 粒子群优化; 空间分割; 模糊聚类; 仿真测试
中图分类号: TN919?34 文獻标识码: A 文章编号: 1004?373X(2020)14?0072?04
PSO?based big data clustering algorithm in cloud environment
HU Yi, ZHU Zijiang
(South China Business College Guangdong University of Foreign Studies, Guangzhou 410545, China)
Abstract: As the clustering accuracy of the quantum evolution method of the big data clustering in the traditional cloud environment is relatively low, a PSO?based big data clustering algorithm in the cloud environment is proposed to reduce the storage cost and improve the abilities of data management and scheduling. The principle of big data clustering in the cloud environment is analyzed. By taking the traditional fuzzy C?means clustering as the basis, the big data clustering algorithm is improved by means of the particle swarm clustering algorithm, so as to achieve the spatial segmentation and get the fuzzy clustering of mass data in the cloud storage system. The discrete cost of clustering data is distributed by means of the particle swarm clustering method to get the information concentration of data clustering, and is combined with the clustering constraint condition of particle swarm optimization to get the optimal solution of big data clustering center in the cloud environment. The simulation results show that the algorithm has high accuracy of data clustering and good convergence performance.
Keywords: big data clustering; cloud environment; particle swarm optimization; space division; fuzzy clustering; simulation testing
0 引 言
云计算概念是IBM于2007年提出的。云计算是并行处理、分布式计算、网格计算之后所发展起来的最新计算方式,其将各种互联计算、数据、存储和使用等资源整合,从而能够实现多层次虚拟化和抽象,用户只需要和网络连接,就能够利用云计算强大的计算和存储能力实现功能。基于云计算背景,大数据信息处理能够实现数据聚类,利用大数据的特征参量可以对数据进行分析。基于数据聚类可实现大数据的创建,并且利用模式识别与诊断实现服务分析。
1 云环境大数据存储的设计
云计算是指通过现代互联网对结构模型与存储空间进行动态扩展。要想以云计算作为背景,进行分类挖掘与大数据存储,首先就要实现大数据存储机制架构的创建。在云环境中,大数据存储通过虚拟化存储在计算机集群开展云计算部署,通过USB磁盘层、结构层、计算机等构成,企业利用终端就能够使用,通过分布式计算机就能进行计算。
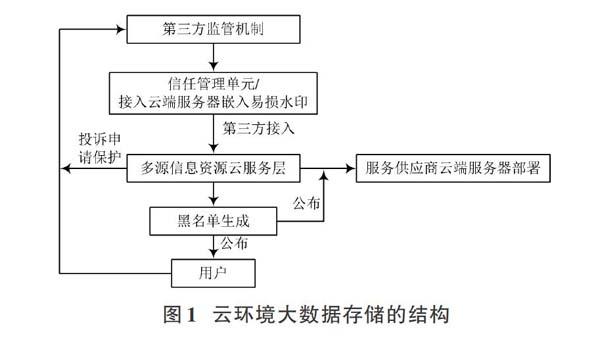
云环境大数据存储结构如图1所示。
利用图1所示结构,将屋内分配应用到云计算虚拟机中。通过式(1)、式(2)实现优化聚类算法,利用最优解实现云计算背景中大数据特点聚类物理分配,公式为:
[x=12μ(1+μ+(μ+1)(μ-3))]
[x=12μ(1+μ+(μ+1)(μ-3))]
为了避免粒子陷入局部最优,实现大数据信息特征矢量Xi存档,计算公式为:
[li(k)=(1-ρ)li(k-1)+γf(xi(k))]
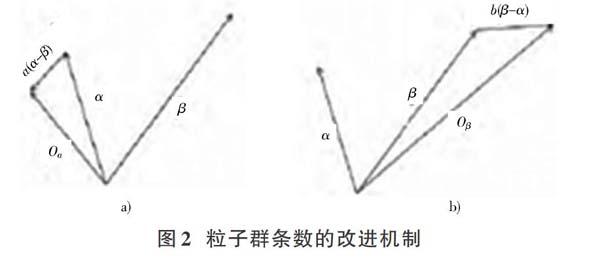
设置聚类阈值为Nth,在Neff [Oα=α+a(α-β)Oβ=β+b(β-α)0 使用粒子群跳数的改进机制对存储库粒子群进行更新[5],图2为粒子群条数的改进机制。 粒子群更新过程中的粒子空间位置为: [Gbesti(g+1)=argminPbestijf(Pbestij(g+1))] 在均匀分布评估解集的过程中,通过最优化的聚类中心矢量函数进行计算,根据模因组中更新迭代顺序得出: [τdiag(max(σi-τ,0))] 以此能够得出云存储大数据聚类粒子适应度函数: [w=w(t)·wstart, k≥αw=w(t)·1wend,k<β] 式中,α与β指的是分集聚类敛目标函数,通过粒子群聚类方法的优化,聚类云存储大数据,对算法进行改进[5]。算法的改进流程详见图3。 4 仿真测试分析 为了对本文算法验证,对云环境大数据优化聚类性能进行仿真实验。仿真实验硬件环境为WIN7操作系统、内存2 GB、CPU主频2.93 GHz,使用Matlab 7仿真软件。在实验过程中,设置大数据采样频率[7]fs=4f0=20 kHz。大数据聚类时间中心t0=15 s,数据量为10 MB~1 GB,将10 MB作为单位,粒子群数量N共有30 984个,在粒子群聚类的过程中,设置空间搜索维度为30,粒子群移动概率设置为0.34,优化粒子群算法运行迭代为5 000次。表1为大数据聚类算法处理参数[8]。 通过以上仿真环境和设置参数的结果,对云计算中心进行大数据聚类仿真。原本大数据二维特征分布随机,在二维空间中无法实现规律性特征分类与提取。使用文中算法处理数据聚类,提取其中的特征与大数据,创建信息模型,实现粒子群优化算法特征聚类的设计,图4为特征提取结果。 由图4可以看出,本文算法能够有效提取云计算大数据中的特征,具有良好的波束聚焦性能,以此能够为数据优化聚类提供精准特征,数据聚类得到实现。 本文算法在计算迭代的过程中,稳定收敛速度朝着最优解逼近,和其他算法对比,具备良好的全局最优解搜寻优势与收斂速度,使数据聚类寻优能力得到提高,使大数据聚类精度得到提高,从而使误分率得到降低。对比文中算法与传统算法,误分率降低13.56%,表明大数据聚类挖掘能力良好[9]。 5 结 语 本文设计云存储系统的大数据优化聚类,使存储开销得到降低,调度能力与数据管理也有所提高。通过量子进化方法能有效实现传统云环境大数据聚类,随着量子群的个体非线性偏移,数据聚类具备局部收敛性,降低了聚类的精准度。本文云环境聚类的粒子群优化算法,在进行设计的时候要分析云环境存储,基于传统粒子群算法优化设计大数据聚类算法,利用仿真实验检测性能,充分展现大数据聚类中本文设计算法的优越性能。实验结果表明,此数据聚类具有良好的聚类性能,能够在短时间内计算出最优解,具备良好的数据聚类挖掘能力。 参考文献 [1] 刘云恒.云环境下基于群智能算法的大数据聚类挖掘技术[J].现代电子技术,2019,42(9):73?75. [2] 王东强,王晓霞.云存储中大数据优化粒子群聚类算法[J].电子设计工程,2017,25(2):26?30. [3] 朱亚东,高翠芳.基于PSO的云计算环境中大数据优化聚类算法[J].计算机技术与发展,2016,26(9):178?182. [4] 项丽萍.结合大数据流特征和改进SOM聚类的资源动态分配算法[J].计算机应用与软件,2019,36(5):262?268. [5] 李斌,王劲松,黄玮,等.一种大数据环境下的新聚类算法[J].计算机科学,2015,42(12):247?250. [6] 李庆伟,陈慧枫,姚桂焕,等.基于距离学习粒子群算法的NOx减排优化[J].动力工程学报,2016,36(5):404?410. [7] 蔡晓丽,钱诚.基于改进的粒子群算法的云资源调度策略[J].微电子学与计算机,2018(6):28?30. [8] 邹华.云计算环境下大数据分布规律的结构优化设计[J].现代电子技术,2016,39(8):18?20. [9] 蔡宇翔,付婷,张辉,等.云计算环境下移动大数据合理分流方法[J].科学技术与工程,2018(2):194?199. [10] 李立军,张晓光.基于动态粒子群优化与K?means聚类的图像分割算法[J].现代电子技术,2018,41(10):164?168.
猜你喜欢
计算机应用(2016年12期)2017-01-13科教导刊·电子版(2016年27期)2016-11-18科教导刊·电子版(2016年23期)2016-10-31科教导刊·电子版(2016年24期)2016-10-29科技视界(2016年20期)2016-09-29中国教育信息化·基础教育(2016年3期)2016-06-07科技与创新(2015年9期)2015-06-02
