
安全类文章的多文本分类系统的设计与实现
2020-07-21 06:43吴习沫朱广宇
网络安全与数据管理 2020年7期
吴习沫,朱广宇,张 雷
(华北计算机系统工程研究所,北京100083)
0 引言
互联网已成为信息传播的普遍途径,然而,由于互联网中的冗余信息过多,各网站提供的标签没有统一的分类标准,使得整合某一特定类的文章信息所消耗的时间成本和人力成本增加。但目前为止,针对网络安全类网站的技术类文章,还没有一套系统能够很好地解决上述对应问题。
为迅速掌握最新的网络安全信息,本文设计并实现了基于CNN和LSTM混合模型的安全类文章多文本分类系统,该系统从多种来源收集安全类技术文本,并将它们以特定格式汇总,自动标记汇总后的文章内容。就信息收集而言,系统主要采集近一年的安全类技术文本,收集的目标内容主要包括文章内容和网页自带的标签,对于各网站自定义的文章标签,可作为多标签的一部分,供用户参考。安全类文本与普通文本对比需要由多个标签对其进行标记分类处理。因此安全类文本的分类要难于普通文本分类处理。
面向网络安全数据高并发的安全类网站,本文设计和实现了信息采集模块,该模块主要实现了基于Scrapy框架的分布式爬虫程序设计,完成了多个安全类网站技术类文章的文本信息数据采集。
本文设计并实现了信息分类模块,它负责对所获得的数据进行预处理、文本表示以及文本分类,其中文本分类模块具体提出了一种基于CNN和LSTM的混合分类模型,它综合了CNN与LSTM的优点,提高了模型的特征提取能力。实验结果表明,基于CNN和LSTM的混合分类模型达到了比较高的准确率,CNN和LSTM的混合模型的准确率为91.99%。CNN-LSTM与CNN、LSTM相比分类准确率提高了1.79%和1.54%。
1 相关工作
文本分词是中文文本预处理过程中的一个重要环节,分词技术是把由字构成的句子按语义划分为由单词组成的句子。由于网络语言表现形式自由、语言不规范、内容多样化等特点,传统分词算法难以充分提取特征,此外,网络新词的创造相对于传统词汇具有一定的变异性[1]。为了克服上述问题,本文应用Bi-LSTM-CRF模型[2]对待分类文本进行中文分词。神经网络[3]通过自动学习从样本数据中提取文本特征,成功地克服了传统人工提取方法的不足,具有广泛的应用范围和广泛的适用性。在自然语言处理方面谷歌提出的Word2Vec[4]算法在文本表示方面十分突出,该算法使得文本表示更加精准而被广泛使用,本文通过结合使用Word2Vec字向量和词向量完成了中文文本的分词和向量化表示。
HOCHREITER S等人[5]提出短期记忆网络(Long Short Term Memory,LSTM),它是一种时间递归神经网络,该神经网络近期被AlexGraves进行了改进。LSTM模型一般用于多文本分类实验,该模型的优点是可以利用文本中的上下文信息和特征进行非线性拟合,从而实现时间序列的处理和预测。基于该模型设计的系统,已经在聊天机器人、文档摘要等相关领域被广泛使用[6]。
KIM Y[7]首次将CNN模型应用在了序列文本问题上,在效果上和LSTM模型互有所长,更多的研究发现,CNN更擅长提取数据不同尺度的局部相关特征,且在处理效率上相较于循环神经网络有大大提高。两者单独使用已经在文本分类问题上取得一定效果。
Lai Siwei等[8]提出在文本分类问题中同时使用CNN和LSTM的混合模型,这两种模型在文本分类中分别发挥了CNN模型和LSTM模型各自的优势,故分类试验的准确率将显著高于两种模型中任意一种单独使用的准确率。
2 系统设计
本系统包括图1所示的两个功能模块:信息采集和信息分类。
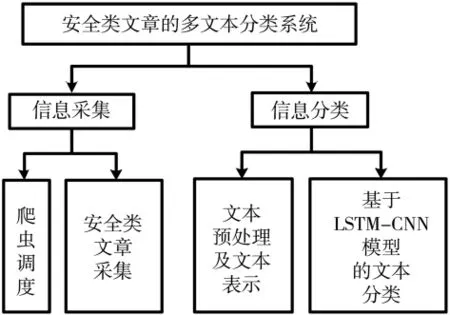
图1 系统组成图
信息采集模块包含爬虫调度子模块和安全类文章采集子模块,实现了基于Scrapy框架对多个安全类网站进行文本信息采集的相关功能。
信息分类模块包括文本预处理及文本表示子模块和基于LSTM-CNN模型的文本分类子模块。
2.1 信息采集
信息采集模块具体功能包括:获取当前爬虫任务状态,对站点信息进行更新和配置查询模块状态从而进行信息采集。
为实现该爬虫的上述功能,如图2所示,设计并实现了两个交互页面,分别是配置子页面和爬虫管理子页面,其中页面交互功能通过信息处理层和业务逻辑层实现。

图2 爬虫架构图
配置子页面用于接收具体采集属性信息,为便于后续消息预处理功能模块解析,每类请求都有相应的固定格式。该爬行器通过对子页集群爬虫的启动和停止进行配置,从而实现了对集群爬行的实时动态监控。其中,Handler层的主要任务是验证和处理页面发送的请求消息;MessagePression模块通过自带的计数器功能对爬虫请求类型进行计数分析处理;通过对文本信息的请求验证,将符合队列信息的内容放入到爬虫请求队列中,Redis的循环检测是由Redisvisition功能模块执行相关的检查处理,处理后启动响应插件,以完成对请求的处理解析,增加Redis监控数量可以显著提高请求响应速度和可靠性[9]。
2.2 信息分类
本文提出的信息分类模块主要包括文本预处理及文本表示子模块和基于LSTM-CNN模型的文本分类子模块,实现了三个主要功能:文本预处理,文本表示,训练分类模型。
2.2.1 文本预处理及文本表示
文本预处理包括文本清洗、分词和文本表示。文本清洗主要有去停用词,去除非文本符号等。分词阶段,本文使用了基于LSTM模型和字向量的的Bi-LSTM-CRF中文分词模型[2]进行分词,通过对典型语料数据集的测试结果表明[10],对于未收录词的分词准确率,该模型明显好于传统的分词方法。第二步结合Bi-LSTM-CRF的输出结果,对中文文本进行分词和和索引化,并使用Word2Vec词嵌入矩阵转化为词向量形式。词向量为文本在高维空间的分布式表示,如图3所示。文本向量化训练模型Word2Vec将文本中的每个单词映射成一个固定维度的向量,这些单词的向量组合到一起形成词向量空间。
2.2.2 基于CNN和LSTM的文本分类
对于文本分类,若每一类的关键字确定、稳定,使用正则匹配准确率较高。然而,若文本分类界限无明显区分,关键词混淆、不明确,正则关键字匹配分类效果较差。本文的自动化分类是基于深度学习的分类模型,采用基于CNN和LSTM的混合模型,对安全类文本进行分类。利用K-MaxPooling方法提取更多的特征用于分类,在分类器层使用Softmax函数来计算每一类的概率。基于CNN和LSTM,本文设计并实现了一个多文本分类模型,其总体结构如图4所示,模型分为9个层次:输入层、Embedding层、双向 LSTM层、拼接层、CNN层、K-MaxPooling层、全连接层、Softmax层、输出层。

图3 词语向量化
第一层为输入层,输入经过文本分词和索引化后的文本序列。
第二层为Embedding层,作用是将输入层传递来的数据中的每个数字索引转化为对应的词向量[11]。
第三层为Bi-LSTM层,如图5所示,主要负责提取句子向量的上下文信息。相较于单层的LSTM,增加了对语句逆向特征的提取能力。为了防止过拟合,结合使用了L2正则和dropout方法。

图4 神经网络结构架构图
第四层为拼接层,函数主要用于拼接双向LSTM层和Embedding层所输出的特征向量和词向量。在Embedding层中将LSTM层的特征向量与特征提取和原始向量相结合,可以使处理的文本更丰富,原始信息更完整。在CNN层中加入最终得到的信息,可以有效地提高CNN层次特征表达的能力。
第五层为卷积层,作用是通过卷积操作提取特征之间的局部特征。
第六层为K-MaxPooling层,主要从卷积层提取出多个最大特征值,即提取出最重要的最大特征值数量的信息。
第七层为全连接层,作用是特征降维。
第八层为分类器,通过Softmax函数将文本特征进行类别分类。
第九层为输出层,主要负责输出结果数据。
3 实验分析
3.1 数据集
本实验数据集来源如表1所示,数据采集层采集多个安全类网站文本信息,采集内容属性具体包括:文章标题、作者、文章具体内容、原网页自带标签、文章发表日期。数据量为1万条。标注方式为人工标注。

表1 数据集来源
3.2 基准模型分类实验结果
如表2所示,文章内容为采集模块输出的安全类文章的内容,人工标注的分类结果作为目标分类结果,为CNN-LSTM模型分类结果。
表3所示为不同模型的实验结果,表格显示CNN-LSTM模型比传统的CNN、LST模型更准确。
3.3 实验的参数设置
梯度更新采用动量梯度下降算法,相比原始梯度下降算法,收敛速度更快,效果更好,公式如下:

实验使用Glove.Twitter.42B.300d向量作为英文词向量表示,Glove.微博.300d向量作为中文字向量表示,相关主要超参数初始化如表4所示。
4 结论

图5 BiLSTM网络结构图

表2 文本内容及分类结果

表3 不同模型的实验结果对比
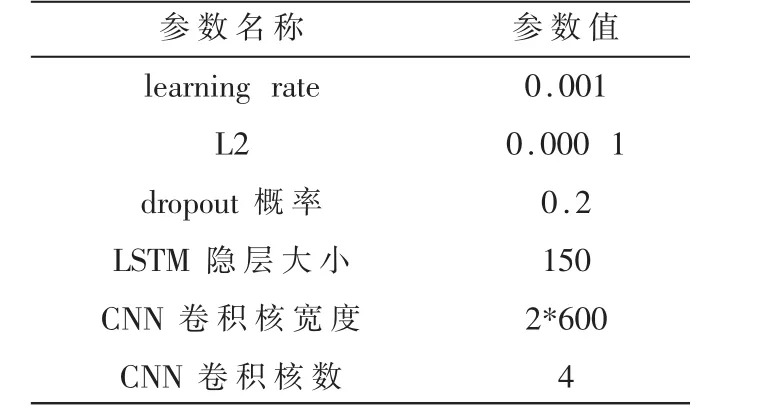
表4 实验主要超参数设置
本文设计并实现了安全类文章多文本分类系统,主要包含信息采集模块和信息分类模块,首先通过信息采集模块对安全类网站进行大量的信息采集,将采集到的文本数据存入数据库,然后通过信息分类模块对存入数据库中的文本进行了预处理及文本表示,具体包括数据清洗、文本分词、文本表示等,将文本表示后得到的词向量分别输入CNN模型、LSTM模型和CNN-LSTM模型这3个文本分类模型进行多文本分类实验。实验结果表明,CNNLSTM混合模型的准确率和F1值分别达到 91.99%和88.02%,均优于CNN和LSTM模型。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
现代信息科技(2021年21期)2021-05-07
校园英语·月末(2021年13期)2021-03-15
建材发展导向(2021年23期)2021-03-08
数码设计(2019年5期)2019-12-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年2期)2018-04-18
