
大规模科技文献深度解析和检索平台构建
2020-07-20 06:41吴素研吴江瑞李文波
现代情报 2020年1期
关键词:信息检索
吴素研 吴江瑞 李文波

摘 要:[目的/意义]在信息检索、科技论文评价和知识结构演化方面,引文分析都起着至关重要的作用。随着格式化全文数据库的出现,引文分析迈入了4.0时代——全文引文分析阶段。但是,目前还没有中文的格式化全文数据库,这极大地制约了全文引文分析在我国科技文献中的研究和应用。[方法/过程]在本文中我们提出建立高效的中文全文引文分析依赖的数据集和检索平台的方法,主要包括:1)提出了基于规则和SVM分类方法的论文元数据和引用提取方法;2)提出基于Spark平台的实现高效引文内容分析标准化数据集生成方法;3)提出建立引用内容的科技文献检索平台。[结果/结论]引文内容分析标准化数据集的建立将全面提升全文引文分析在我国科技领域中的研究效能,提高科技文献查找精度。
关键词:全文引文分析;信息抽取;信息检索;Spark
DOI:10.3969/j.issn.1008-0821.2020.01.012
〔中图分类号〕TP393 〔文献标识码〕A 〔文章编号〕1008-0821(2020)01-0110-06
Construction of Deep Resolution and Retrieval Platform for
Large Scale Scientific and Technical Literature
Wu Suyan1 Wu Jiangrui2 Li Wenbo3
(1.Beijing Institute of Science and Technology Information,Beijing 100044,China;
2.Henan Institute Technology,Xinxiang 453003,China;
3.Institute of Software Chinese Academy of Science,Beijing 100081,China)
Abstract:[Purpose/Significance]Citation analysis plays a vital role in the three aspects of information retrieval,scientific paper evaluation,revealing the knowledge structure evolution.With the appearance of full-text literature repositories,Citation analysis entered the 4 Era——full-text citation analysis age.However,there is no Chinese full-text literature database,which have greatly restricted the research and application of full text citation analysis in Chinese Literature.[Method/Process]In this paper,we proposed a method to establish efficient data set and retrieval platform for Chinese full text citation analysis,including:(1)the paper metadata and reference extraction methods based on rules and SVM classification methods were proposed;(2)a standard data set generator based on spark platform was proposed;(3)a scientific literature retrieval platform with reference content was put forward.[Result/Conclusion]The establishment of the standardized data set of the citation content analysis will improve the research efficiency of the full text citation analysis in the field of science and technology in our country and improve the search precision of the scientific and technological literature.
Key words:full text citation analysis;information extraction;retrieval;Spark
科技文獻是科学研究的结晶,是科技创新的成果,而创新的过程本身又是一个信息资源的沉淀过程,因此,科技情报服务工作很重要的一个研究领域——文献计量学就是对海量的文献进行分析,从中获取到有价值的信息,如了解学科研究现状及前沿领域的分布,把握学科的整体发展态势,分析预测学科未来趋势等。
自从16世纪后期论文引用制度形成以来,参考文献成为学术论文的第二特征,也是合理有效地进行科学交流的必要部分,通过对学术文献之间引用与被引用关系的研究,可以获知学科之间的关系与发展以及学术传播的历程,进而可以感知研究近况和发展趋势[1]。20世纪中期,美国霍普金斯大学Garfield E开创了科学引文索引(SCI),提出了通过引文索引来对科技文献进行检索的方法,从而开启了从引文角度来研究文献及科学发展动态的新领域,掀开了引文分析的新篇章[2]。网络版数据库WoS(Web of Science)[3]的问世进一步促进了引文分析的普及。在引文分析研究领域,文献索引格式的发展程度决定了引文分析的发展程度。在过去50多年里,由于缺少可以提供全文信息的数据,引文分析主要集中在引用频次分析研究中,引文内容分析也有所涉及,主要集中在对施引文献的标题、关键词和摘要的分析上。近年,随着可扩展标签语言技术的发展,出现了科学文献全文电子数据库,如世界著名科学期刊发行商Springer、Eldevier和Wiley等都提供或部分提供XML格式全文阅读和下载。为引用内容深入分析研究提供了数据基础,通过全文数据库可以获取引文在现实科学文本中引用的空间分布和语境信息,可以让我们从空间维度和语义维度上展现科技文本中的知识流动,分析作者的引用动机和施引文献与被引文献之间的主题关联性等,全文本蕴藏的丰富引文空间信息引领引文分析进入新阶段,开创了引文分析4.0的时代,吸引大量学者对全文引文分析的探索[4]。
科技文献检索是引用内容分析主要的3个应用方面其中之一,传统的共被引分析和文献称合分析都可以用于信息检索,但文献的相似度都是通过共被引文献或亲合文献的共被引频次或称合频次来测度的,在统计共被引频次时,只是通过文献著录中的信息统计,并未深入到共被引文献在施引文献中的实际引用句子中进行研究,但是施引文献的引用句子包含了引用性质、引用主题等更深层次、更细粒度的信息。因此将传统引文索引理论与引文内容信息相结合作为指导,以信息检索领域最新研究技术为基础,对提高科技文献査询效率具有重要意义[5]。
进行引文内容层面上的分析需要依赖文献全文数据库,目前国际上已有可供学者分析的格式化全文数据库,但是国内中文文献数据库一般都提供科技文献全文下载技术,但一般都是PDF或者CAJ等格式,这些格式只是描述文档的打印,并没有描述文档语义内容的数据结构,还不支持对引用内容信息的获取。极大地抑制了全文引文分析在我国科技文献中的研究和应用。本论文研究科技文献深度解析方法,建立自动构建中文全文标注数据集平台,并在此基础上建立基于引用内容的科技文献检索平台。
本文的主要贡献如下:
1)提出了基于Spark平台上,利用规则和SVM分类相结合的信息抽取方法,实现实时全文引用分析数据集的建立。
2)提出了基于引用内容的科技文献检索方法,实现引用信息在文献检索中的应用,提高检索效率,优化检索结果。
1 相关工作
目前科技文献数据抽取主要有两条技术路线:基于规则的抽取和基于机器学习的抽取[6]。基于规则的方法根据文本结构特征,建立规则的语法、语义和规则库,通过规则对信息进行抽取[7],但科技文献中很多信息没有严格的格式,因此基于规则的抽取模型结果虽然比较精确,但通常很复杂,适应性较差,适合简单元信息的抽取,不适合复杂信息的抽取。基于机器学习的抽取模型主要包括:隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机域模型(Conditional Random Fields,CRFs)和支持向量机模型(Support Vector Machine,SVM)等,基于HMM模型[8]的信息抽取通过文本的词序列或语义块序列来确定状态序列实现了对论文头部信息的抽取,因此必须作出严格的独立性假设,无法考虑语境信息。CRFs[9]是一种复杂的全局HMM模型,避免了HMM模型中的强相关性假设,展现了优于HMM的抽取效果,但缺点是训练时间长。基于SVM模型抽取信息是将上下行的信息通过一种迭代算法加入文本行的特征向量中,在提高了准确率的同时也增加了计算量,总的准确率达到92.9%[10-12]。总体来说,科技文献的信息抽取技术相对成熟,但是没有针对大规模数据集设计高性能的、分布式计算分析系统。
本项目针对处理大批量国内PDF格式的科技论文,利用OCR(Optical Character Recog-nition,光学字符识别)文本识别、信息抽取、大规模数据处理等技术实现高效、自动抽取论文中引用句子,将科技文献PDF论文构建成标准全文引文分析的数据集。
2 基于规则和SVM结合的内容抽取方法
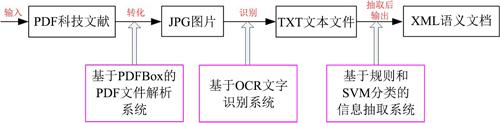
中文出版網上出版平台如CNKI、万方、维普等,都提供科技文献PDF格式全文下载。因早期PDF文科技文献生成方式的不同以及参考文献一般都是上角标的形式标注等因素,一般类库提供的PDF解析文件不能正确提取正文中引用句子。与此同时,对印刷体的识别的OCR技术已经成熟和完善,对版面识别正确率达到90%以上。因此本项目技术流程如图1所示。
2.1 语义标注的内容
首先是文献基本元数据,如作者、机构、题目、摘要、关键词、参考文献列表等标注。其次根据目前全文引文分析研究关注的点,主要是引用位置、引用强度、引用语境3个方面。为了进行引用位置的分析,将文档分为引言、文献综述、方法、结果、结论等5部分。需要标注引用出现文档的位置。为进行引用强度的分析,需要标注引用出现的次数。为进行引用语境的分析需要标注引用在文中的句子,以及用+1和-1等设定引用出现的前后句子,叫做引用句子窗口。最后,需要对参考文献列表进行标注,标注出参考文献的作者、题目、出版物、出版年等信息。
2.2 基于规则和SVM分类相结合的信息抽取方法
对于作者、机构、参考文献引用位置确定等具有明显特征词和特定构成规则的元数据抽取,采用基于规则的方法。例如对于作者元数据,首先构建姓氏特征词字典,其次构建字符长度为2~4字符长度,且全为中文的字符的规则,采取正则表达式进行匹配。
对于参考文献引用位置,采取字符“[”和“]”或者“(”和“)”为特征词,二者符号之间必须包含阿拉伯数字,可以出现标点符号“,”或者“-”等规则进行匹配。
对于其他复杂信息的抽取,如题目、摘要、关键词、文档结构(即上面说的文档5个部分分析),采取SVM分类方法,针对每种信息抽取任务建立单个SVM分类器。思路如下:首先针对不同的信息抽取分析信息的性质,提取特征集,然后通过标注数据训练SVM模型,最后利用训练模型对实际文献进行信息抽取。对具有明显特征词和规则的信息抽取,可以将是否满足规则作为SVM分类器的特征之一。例如,对文档结构的提取,一般文章章节之间的标题都含有1、2、3、3.1等字符,但是单从含有这些字符不能确定是否章节标题,可以这些字符出现次数作为特征之一,在结合包含字符串段落长度、字符串的位置等特征,通过SVM进行判断。
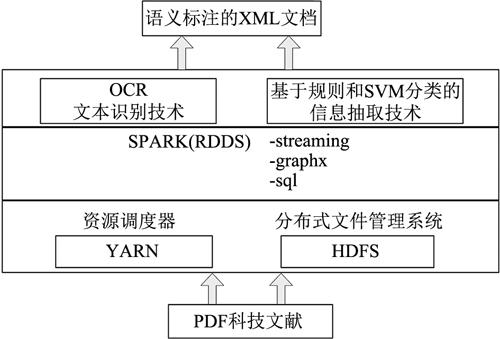
2.3 基于Spark平台的实时引文内容分析的标准化数据集生成系统 对科技文献的分析和抽取计算量大,如果完成对大批文档的实时分析和抽取,必须采用大数据处理技术,采用基于Spark计算引擎的大数据处理平台,Spark是基于内存的分布式计算框架,其核心是弹性分布式数据集(Resilient Distributed Datasets,RDD),它是对集群上并行处理数据的分布式内存的抽象,Spark通过将中间结果缓存在内存减少磁盘I/O通信来提升性能。本项目将PDF文件解析算法、OCR文字识别算法和基于规则和SVM分类的信息抽取算法置于Spark平台上,实现科技文献快速转化和抽取以及生成XML语义文档,具体系统架构如图2和图3所示。
工作流程如下:1)每个工作节点初始化规则所依赖的字典表和软聚类的簇中心,形成初始化弹性分布式数据集RDD,主节点等待新进入的科技文献;2)如果有新进入的科技文献,主节点对新进入科技文献进行Map操作,进行PDF分析,生成JPG图片格式,形成待OCR识别的RDD;3)对待识别的RDD执行Map操作,通过OCR识别生待信息抽取的RDD;4)对待信息抽取RDD进行元数据、参考文献、引用信息抽取。形成待进行标注的文本;5)最后,通过Reduce操作将待标注文本进行合并,进行语义标注。
3 基于引用内容的科技文献检索平台
基于引用内容的科技文献检索平台主要包含3个模块,分别是数据处理模块、检索模块和检索结果可视化模块。其中数据处理模块是在本项目研究一的结果上进行处理,因此不包括传统检索系统的信息抽取的内容,只是对相关项建立索引,出了传统文献检索的元数据题目、摘要、关键词等,本项目将引用信息也作为检索域进行索引。检索系统模块是核心,通过与用户交互,获取用户查询条件,通过分词,将检索项在各个检索域的索引词上进行相似度计算,得出各个域上的相似条目后,最后根据各个域的权重综合计算对结果进行排序。结果可视化模块是将结果以列表页显示出来,对关键字段如题目和作者显示,同时对检索项出现的检索域部分以高亮显示。在结果详细页,除了传统检索系统的文献原文外,还以列表项显示出该文献出现在其他施引文献中的引用信息。检索平台系统设计图如图4所示。
本论文采用Elasticsearch技术实现可扩展、高性能的科技文献检索平台搜索引擎的搭建。分布式搜索引擎Elasticsearch是基于Lucene的开源分布式搜索引擎。Elasticsearch具有高可用、易扩展以及近实时的特点,可以实现稳定、实时、可靠的检索服务。同时采用RESTful风格的设计,能够提供易用的查询与共享接口。
基于引用内容的科技文献检索实验平台的Elasticsearch分布式集群模块由5个节点构成,1个作为主控节点,4个作为数据节点,节点中分别部署Elasticsearch Server,设置服务集群为相同网段,利用Elasticsearch的广播监听机制连接各个节点,组成分布式索引集群。论文数据中对题目、摘要、关键词、引用信息、内容进行分词后建立索引,对作者直接建立索引。
4 系统运行界面
4.1 引文内容分析的标准化数据集生成系统
该系统可以通过选择一个PDF抽取论文的元数据和引用信息,也可以选择一个文件夹,系统将进行递归调用,将选择该文件夹下和其所有子文件夹下的所有PDF文件进行抽取,结果保存在数据库中。下面将以一篇论文为例,查看其解析后的结果如图5所示。
4.2 基于引用内容的科技文献检索系统
Elasticsearch是基于Lucene的开源分布式搜索引擎,首先将要查询的目标文档中的词通过分词提取出关键词,计算关键词TF/IDF后建立索引,再对索引进行搜索。当输入一个查询文本,搜索机制先把文本中的内容通过分词切分成若干个关键词,然后根据关键词查询索引,最终找到包含关键词的文章,搜索结果按照喝查询结果的相关性进行排序。基于引用内容的科技文献检索系统界面如图7所示,通过输入查询条件,可以选择在题目、摘要、关键词和引用句子中查找,查找到的结果按照相关性排序,最相关的在前面;和查询相匹配的查询条件在结果总用红色标识出来。
5 总 结
本文根據中文科技论文多样性的特点,提出了利用OCR技术提取内容的方法,同时采用基于规则和SVM的内容方法,对科技论文元数据和引用信息进行了抽取,并考虑到数据集的规模和计算量提出了基于Spark的高效处理技术,并结合Elasticsearch平台建立了接近实时、高扩展的科技文献引用检索平台,这对于建立中文引用内容分析平台具有实际意义。
参考文献
[1]梁永霞,刘则渊,杨中楷.引文分析学的知识流动理论探析[J].科学学学习,2010,28(5):668-674.
[2]Garfield E.Citation Indexes for Science:A New Dimension in Documentation Through the Association of Ideas[J].Science,1955,(122):108-111.
[3]Reuters T.Web of Science[EB/OL].http://www.isiknowledge.com,2017.
[4]胡志刚.全文引文分析理论、方法与应用[M].北京:科学出版社,2016.
[5]王贤文.科学计量大数据[M].北京:科学出版社,2016.
[6]张铭,银平,邓志鸿,等.SVM+BiHMM:基于统计方法的元数据抽取混合模型[J].软件学报,2008,19(2):358-368.
[7]Kim J,Le D X,Thoma G R.Automated Labeling Algorithms for Biomedical Document Images[C]//7th World Multiconference on Systemic,Cybernetics and Informatic,Orlando:ISAS Press,2003:352-357.
[8]Lafferty J D,Mccallum A,Pereira F C N.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[J].2002,3(2):282-289.
[9]于江德,樊孝忠,尹继豪,等.基于隐马尔可夫模型的中文科研论文信息抽取[J].计算机工程,2007,33(19):190-192.
[10]Han H,Giles C,Manavoglu E,et al.Automatic Document Metadata Extraction Using Support Vector Machines[C]//3th Joint Conference on Digital Libraries,Pittsburgh:ACM Press,2003:37-48.
[11]刘宇,钱跃.基于字典匹配和支持向量机的中文科技论文元数据抽取[J].工程数学学报,2012,29(4):586-592.
[12]张梦莹,卢超,郑茹佳,等.用于引文内容分析的标准化数据集构建[J].图书馆论坛,2016,36(8):48-53.
(责任编辑:陈 媛)
猜你喜欢
吉林化工学院学报(2021年8期)2021-09-06
电脑与电信(2018年11期)2018-02-16
山西青年(2018年5期)2018-01-25
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
地理与地理信息科学(2015年4期)2015-10-13
教育与职业(2014年36期)2014-04-17
河南科技(2014年11期)2014-02-27
山东图书馆学刊(2013年3期)2013-04-10
