
OPTICS与离线批处理在轨迹聚类中的应用
2020-07-17 07:35陈金勇张新宇孙未未
计算机工程 2020年7期
郭 雨,陈金勇,张新宇,李 梁,孙未未
(1.复旦大学 计算机科学技术学院,上海 201203; 2.中国电子科技集团公司航天信息应用技术重点实验室,石家庄 050081)
0 概述
计算机网络技术在各个领域的广泛应用以及GPS定位、传感器、卫星遥感等先进定位技术的不断发展,形成了大量时空轨迹数据,如许多基于位置的服务(Location Based Service,LBS)应用积累了丰富的用户出行路线与移动轨迹数据。这些大规模的数据可以弱化数据质量低下的缺点[1],使得从中提取出隐含信息并演化出新型应用成为可能。由于服务都建立在对大量时空轨迹数据简化分析和高效提取的基础上,因此如何高效地利用这些数据便相应成为数据分析的热点问题。
轨迹模式挖掘是通过大量的空间轨迹分析移动物体的移动模式,其由包含特定模式的单个轨迹或具有相似模式的一组轨迹来表示。为了找到由不同运动物体共享的代表性路径或共同趋势,通常需要对类似的轨迹进行聚类。轨迹聚类在数据分析中发挥了至关重要的作用,因为它在揭示物体移动潜在趋势的同时为行为模式的刻画提供支持,并且可以用于旅行路线建议、出行模式理解以及后续位置预测等诸多方面[2-3]。
在轨迹聚类问题上,许多不同类型的聚类方法被提出应用于复杂的实际情况。文献[4-5]为在道路监控时检测异常车流提出的在线轨迹聚类方法,避免了传统的“两步聚类”,而是在获取数据时使用树形结构在线更新聚类结果,构建概率转移模型以判断异常数据。也有研究者提出对数据进行二次筛选达到降载的目的[6]。为了对受道路网络约束的轨迹数据进行聚类,研究者又提出适应道路网络视点的距离度量法,并将其应用于新的轨迹聚类算法[7-9]。针对隐私保护需求,文献[10-11]对传统轨迹聚类算法进行改进,使其能够利用更多的信息。此外,也有将轨迹转换为特征向量[12]、加入隐马尔可夫模型[13-14]或者运用最长公共子序列(LCSS)进行聚类[15]的算法,且都在不同领域得到了应用。
关于适用于轨迹分析的聚类方法,研究者发现:与传统的k-means聚类相比,基于密度的聚类算法有明显优势[16],例如:聚类结果可以自然扩展形成任意形状;能够发现任意数量的类别以更好地适应源数据;能够很好地处理数据中的噪声。文献[17]提出基于密度的聚类算法TRACLUS,通过轨迹分割、聚类、生成3个步骤进行轨迹聚类并得到对应的频繁模式。TRACLUS算法不需要考虑轨迹的时间因素,即使一些运动对象从未同时在一起移动,也有可能被分在同一组聚类。该算法不以一条完整的轨迹为单位进行聚类,而是通过轨迹分割将轨迹转化为若干条线段,再对线段进行聚类,因此,生成的聚类结果更为灵活多变。TRACLUS的算法思想也被用于轨迹离群点检测[18]、轨迹分类[19]以及增量聚类等工作[20]。
TRACLUS在聚类时使用传统的DBSCAN算法,需要人为设定参数ε与MinLns,并且由于实际需求的不同,可能会得到不同疏密程度的聚类结果,此时参数的设定几乎完全取决于工程师的经验。同时,由于每生成一次聚类结果都需要对所有数据运行一遍完整算法,这增加了在大规模数据集上调试参数的难度。也有类似TRACLUS的算法,如文献[21]算法,其先将轨迹分割为线段,再将线段投影至一维空间并做聚类,最后在聚类完成的线段中提取运动模式。该算法的聚类过程在一维空间中实现,避免了在二维空间中线段聚类的许多实际困难,但相应也会损失一定的可用信息。一些学者将改进的Hausdorff距离与离散Fréchet距离作为TRACLUS算法的距离度量,考虑了更多的影响因素,获得了更有效的聚类结果[22-24],但这些尝试都未关注运行速度的优化。
本文将OPTICS[25]这一基于DBSCAN的改进算法用于优化TRACLUS算法,同时通过引入离线批处理过程使其能够自动给出若干可选的参数并生成对应的聚类结果,从而减少工程师在调整参数上需要花费的时间与精力。
1 形式化表示及问题定义
1.1 形式化表示
轨迹Ti是一个多维点序列,通常表示为{p1,p2,…,pli},其中,li是轨迹Ti的长度,pj是一个多维点。本文算法不使用轨迹的时间信息,因此不需要特意记录pj的时间信息。
轨迹序列集合I是轨迹的无序集合,通常表示为{T1,T2,…,TnI},其中nI是集合中轨迹的数量。
轨迹分割针对一个线段pipj,其中pi和pj是从同一轨迹中选择的点,通过从一条轨迹中选择若干个点(记为n′个),取其中任意相邻两点可以得到共(n′-1)个轨迹分割结果。
聚类O是一个轨迹分割的集合,属于同一个聚类的轨迹分割在设定的距离下相互接近。
代表轨迹Ri是一个多维点的序列{p1,p2,…,pl′i},其中l′i是轨迹Ri的长度,用于表示一个聚类中所有线段主要行为虚构的轨迹。
1.2 问题定义
根据给定的轨迹序列集合I,算法需要生成一个聚类的集合O={C1,C2,…,CnI},以及每个聚类对应的一个代表轨迹。
2 TRACLUS算法
TRACLUS算法分轨迹分割、聚类和生成3个子部分进行轨迹聚类[17]。首先应用最小描述长度(MDL)原理,将原序列分解成代表原轨迹序列的特征线段集合;然后通过DBSCAN得到线段的聚类;最后对每一个聚类生成一个对应的代表轨迹。算法第一部分轨迹划分的时间复杂度为O(N),第二部分线段聚类的时间复杂度为O(N2),如果使用合理索引如R-tree,可将时间复杂度降至平均O(NlogaN),第三部分特征轨迹的生成需要经过排序,因此,复杂度为O(NlogaN)。显然,在不使用高效的索引时,第二部分为整个算法的复杂度瓶颈,达到了O(N2),而当使用高效的索引时,虽然第二和第三部分复杂度一致,但由于复杂度常数上R-tree远大于排序,因此第二部分依然是整个算法的瓶颈。
此外,由于DBSCAN包含2个人为控制的参数MinLns与ε,分别代表邻域内的对象个数与邻域大小,用于共同决定邻域的密度。它们的确定需要依靠数据分析任务的实际需求和数据分析工程师的经验,但实践中工程师可能会在这其中耗费大量无意义的时间而又难以保证其设置的合理性。为了在大规模数据上运用该算法,本文将对该部分进行优化。
由于本文的目的在于对TRACLUS算法第二部分(使用DBSCAN对线段进行密度聚类)的优化,因此算法第一部分(轨迹分割)与第三部分(代表轨迹的生成)[17]的具体实现本文不再赘述。
3 聚类算法优化
3.1 基于OPTICS的密度聚类优化
DBSCAN存在一个一般化的改进版本,被称为OPTICS[25]。OPTICS并不直接生成数据集聚类,而是先为聚类分析生成一个有序排列,再对比有序排列进行后续处理以得到聚类结果。这个有序排列代表了各样本点基于密度的聚类结构,数据越接近,越有可能被分在同一聚类的样本,在排列中的位置就越靠近。以样本点输出次序为横轴,以可达距离为纵轴,可通过实验得到如图1所示的输出结果。

图1 OPTICS有序排列输出结果
样本的聚类在图1中体现为低谷,当以参数ε2为阈值时,有序排列被划分为3个小于ε2的低谷,每个低谷对应一个样本聚类;而当以更小的参数ε1为阈值时,有序排列被划分为多个小于ε1的低谷,同样一个低谷对应一个样本聚类。因为在对多个不同的参数ε生成聚类时,所使用的有序排列是完全相同的,所以如果根据有序排列生成聚类的运行时间小于传统DBSCAN算法的运行时间,那么当ε阈值数量增多时,算法的运行速度就会得到改善。
传统DBSCAN算法[26]十分经典,本文不再赘述。OPTICS在DBSCAN的基础上,增加了核心距离和可达距离[25]2个新的定义:
定义1(核心距离) 一个对象p在参数ε与MinLns下的核心距离,等于其第MinLns近的对象到对象p的距离。如果对象p的ε邻域中对象个数小于MinLns,那么对象p在参数ε与MinLns下的核心距离为UNDEFINED。
定义2(可达距离) 对象o和对象p在参数ε与MinLns下的可达距离为max(核心距离(o),distance(o,p))。如果对象p的ε邻域中对象个数小于MinLns,那么对象p在参数ε与MinLns下的可达距离为UNDEFINED。
生成有序排列的函数伪代码如下:
算法1ExpandClusterOrder
输入objects[]
输出ResultList[],ReachDist[],CoreDist[]
Initialize:
Visited[]=[false]
temp=1
while temp<=objects.size do
m=null
i=1
while i<=objects.size do
if visited[i]==false then
m=i
end if
end while
visited[m]=true
ResultList[temp]=m
CoreDist[m]=FindMinLnsthDistance()
for each i in EpsNeighborhood(m) do
ReachDist_=max(CoreDist[m],dist(i,m))
if ReachDist[i]>ReachDist_ then
if visited[i]==false then
ReachDist[x]=ReachDist_
end if
无线数据与能量协同传输技术:编码与调制设计………………………………………………胡杰,金石 24-5-43
end if
end for
temp=temp+1
end while
ExpandClusterOrder函数每次选择一个未被选择的对象m,且满足ReachDist[m](之前已被选择的对象到对象m的最近距离)为最小值。将对象m添加到结果序列,并标注其已被选择。FindMinLnsthDistance()函数会计算对象m的核心距离,随后枚举对象m的ε邻域,用m到其他对象的可达距离更新ReachDist数组。如此循环直到所有对象都被选择。
根据定义1与定义2可知,OPTICS使用的参数ε是一个限制邻域大小上限的宽松上界,过大的参数ε仅可能拖慢运行时间,而不会影响之后生成的聚类质量。如果将参数ε设置为正无穷,那么核心距离与可达距离均不会出现UNDEFINED,此时需要枚举所有对象对并计算它们的间距以得到核心距离并更新可达距离,复杂度退化到O(N2),与不使用高效空间索引的DBSCAN相同。如果根据实际需求确定了参数ε的上限(并不需要十分精确),那么OPTICS也可以使用高效空间索引,在O(logaN)的时间内得到第MinLns近的对象并更新邻域的可达距离,从而将总的时间复杂度降低到O(NlogaN)。因此,相对于DBSCAN而言,OPTICS的时间复杂度并没有增加,参数ε设置不再敏感。
3.2 基于有序排列的聚类
虽然已经获得了对聚类元素的有序排列,但为了得到最终需要的密度聚类结果,仍需要对此排列进行分析。如果已知一个DBSCAN参数ε的取值,通过算法2可以得到对应的密度聚类结果。
输入ResultList,ReachDist,CoreDist
输出mark[]
Initialize:
mark[]=[UNCLASSIFIED]
clusterID=0
i=1
while i<=ResultList do
x=ResultList[i]
if ReachDist[x]>eps then
if CoreDist[x]<=eps then
clusterID=clusterID + 1
mark[x]=clusterID
else
mark[x]=NOISE
end if
else
mark[x]=clusterID
end if
end while
ExtractDBSCANClustering函数依序枚举有序排列中的每一个对象,如果当前被枚举对象x的可达距离小于参数ε,那么将对象x与前一个对象合并到同一个聚类中;否则,如果对象x的核心距离小于参数ε,则将对象x标记为一个新的聚类。当可以合并时,将对象x与其前一个对象合并是合理的[25],具体证明此处不再赘述。由于ExtractDBSCANClustering函数只对有序排列进行一次扫描,因此时间复杂度为O(N)。
3.3 参数ε的生成
使用OPTICS替代DBSCAN用于密度聚类,可以大幅缩短多组参数存在时的运行时间,但在ExtractDBSCANClustering阶段依然需要手动指定参数ε。如果能够根据中间结果自动生成可供参考的参数ε,则能大幅减少参数调整的工作量。
考虑密度聚类中参数ε的定义[26],即用于确定聚类对象的邻域大小,聚类对象间的距离整体越大,通常就需要越大的邻域用以判断疏密(过小的邻域将难以包含足够的对象以至于随机性过大),而聚类对象间的距离整体越小,就需要越小的邻域(过大的邻域将包含过多的对象以至于密度趋近于整体平均密度,从而失去代表性)。
通过分析算法2可以发现,两个相邻的对象是否被合并到同一个聚类,仅与它们的可达距离有关,而核心距离仅影响了在未被合并时是否将其判断为噪声。因此,参数ε与聚类对象可达距离的分布有关。可达距离的分布示例如图2所示,其中横轴为可达距离,纵轴为等于可达距离的聚类对象数量。

图2 聚类对象可达距离分布
本文用正态分布拟合此分布,并计算N等分点的数值(N为任意设定的整数),将它们作为一系列可选的参数ε返回。虽然越靠近边界(如10%与90%处)的数值通常被需要的可能性越小,但本文依然将其作为参数纳入考虑,因为ExtractDBSCANClustering的时间复杂度仅为O(N),相对于ExpandClusterOrder的时间复杂度O(N2)或O(NlogaN)显得微不足道。
3.4 离线批量聚类
OPTICS算法的ExtractDBSCANClustering函数运行一次只能对一组参数生成对应的聚类结果,面对需要对多组参数分别生成聚类结果的需求,仍有一定的优化空间。
上文3.2节已经提到,在OPTICS的有序排列中相邻的两个对象,后者或者与前者合并到同一个聚类,或者成为一个新的聚类,或者成为噪声。如果将噪声视为仅含有一个对象的聚类(在正常的密度聚类中,不会出现只含有一个对象的聚类,它无法扩展也无法被扩展,因此没有分析意义),那么相邻的两个对象是否被合并仅与可达距离有关。随着参数ε的逐渐增大,可达距离越小的对象将会越早被合并,已经被合并到同一个聚类内的对象不会再被拆分至两个聚类。如图1所示,在参数ε从ε1逐渐增加的过程中,原先被几个峰分隔的许多个聚类逐渐合并,直至增加到ε2时只剩下3个聚类。
正是由于只存在集合合并的操作,并查集很适合被用于维护这些聚类之间的关系。在将可达距离与参数ε按升序排序后,当参数ε增大后,小于参数ε的可达距离也相应增加,只需要将这些新增的相邻对象合并,即可得到对应新参数ε的聚类结果。上述操作的算法伪代码如下:
算法3offlineExtractClustering
输入ResultList,ReachDist
输出cluster[]
Initialize:
DistList=sort(ReachDist)
i=1
while i<=size do
mark[i]=i
end while
cur=1
for each eps in EpsList do
cur=RenewClustering(cur,eps,DistList)
cluster[eps]=mark
end for
算法4RenewClustering
输入cur,eps,DistList
输出cur
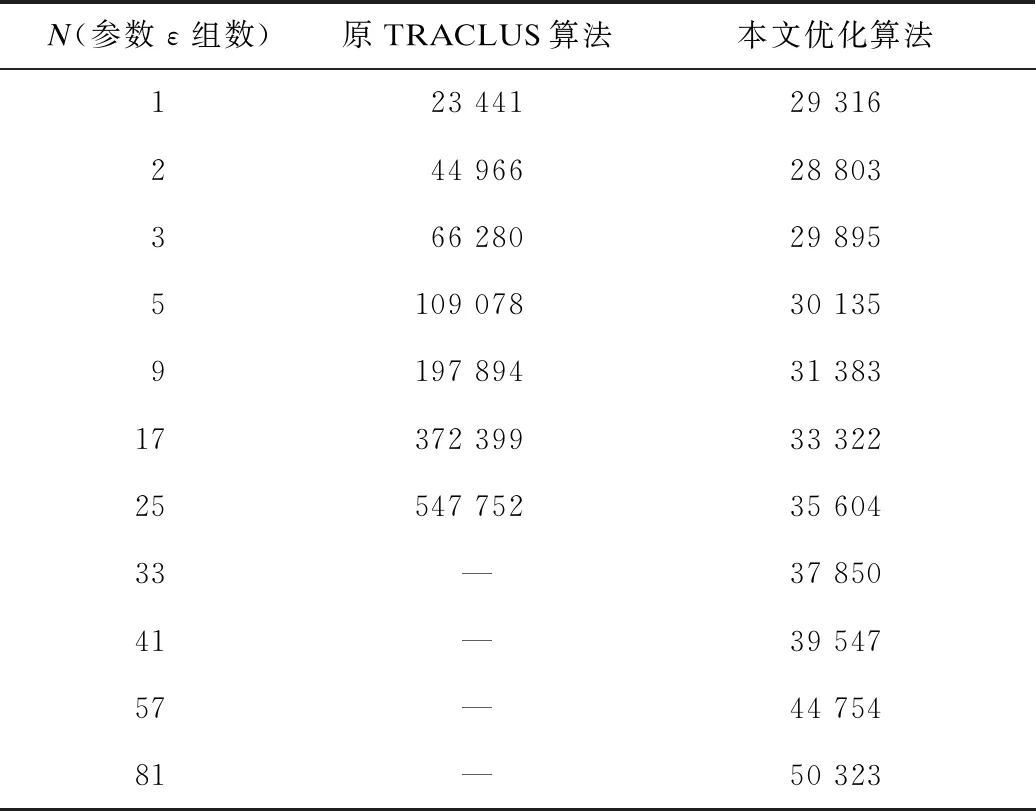
while cur if DistList[cur]>eps then break; end if x=DistList[cur].from mark.merge(x,x-1) cur=cur+1 end while 上述代码对ReachDist数组进行从小到大排序,并存储在DistList数组中。从小到大枚举每一个候选的ε,每次调用RenewClustering函数以更新mark数组。RenewClustering 函数从当前cur位置开始扫描DistList内的对象,如果当前对象的ReachDist小于参数ε,那么说明对应的位置需要进行一次合并,调用并查集merge函数。如果可达距离大于参数ε,那么之后的可达距离也均大于ε,此次更新就到此结束,返回移动后的cur。 可以看到,该部分对所有待计算的ε取值都计算出了对应的聚类结果,且所有对象仅被单调扫描了一次,因此其复杂度为O(αN)(其中α为并查集效率常数)。而在传统OPTICS的ExtractDBSCANClustering过程中,该部分的复杂度为O(运行次数×N)。 传统TRACLUS算法时间复杂度瓶颈在第二部分的线段密度聚类上,因为使用了DBSCAN,所以在对多组不同的参数进行密度聚类时,时间复杂度为O(参数组数×N2),即使使用了合理的空间索引,时间复杂度也为O(参数组数×CNlogaN)(其中C为空间索引带来的巨大常数)。当数据规模较大且参数组数较多时,未经优化的算法会严重拖长运行时间。 经过优化后,DBSCAN被OPTICS替代,原本对每组参数需要扫描所有数据并计算它们的间距,现在可以一次完成,复杂度降为O(CNlogaN+参数组数×N),其中前部分是生成有序排列的代价,后部分是从排列中对每组参数生成对应聚类结果的代价。经过离线批处理优化,从有序排列生成对应聚类结果的过程被进一步合并,复杂度降为O(CNlogaN+αN+参数组数)(其中α为并查集的时间复杂度常数,通常小于5)。可以发现,优化后第二部分的时间复杂度几乎不受参数组数影响,这在需要对多组参数进行计算的情况下是较大的改进。 本文实验环境为单个计算机,处理器型号 Intel(R) Core(TM) i5-4690K CPU @ 3.50 GHz,内存大小为16 GB,操作系统为 Win10(64位),使用相同软件环境。 本文在Starkey项目提供的1995年鹿类动物迁徙轨迹数据集(http://www.fs.fed.us/pnw/starkey/data/tables/)上进行对比实验,该数据集是相关问题的经典数据集,TRACLUS原论文也在该数据集下进行实验。实验结果表明,在生成相同质量聚类结果的同时,本文所提出的优化算法花费时间小于原算法,由此说明本文的优化确实对其有所改进。为了对比,2种算法都没有使用诸如R-tree数据结构等额外的优化结构。 2种算法一次性生成N张聚类结果所需要消耗的时间比较如表1所示(当参数ε组数N大于33时,传统TRACLUS算法的运行时间过长,不再具有比较的意义)。可以看出,TRACLUS所花费的时间与参数ε组数近似呈正比例关系,而使用离线与OPTICS优化后的TRACLUS,虽然在仅有一组ε参数时花费的时间高于TRACLUS(因为有更大的常数),但随着参数ε的取值数量增长,算法运行的时间增长缓慢,远低于直接使用TRACLUS进行聚类的耗费。正如之前的分析,改进后的算法节省了大量重复计算过程,在同时对多组ε参数进行计算时具有明显的速度优势。 表1 多组参数情况下的聚类时间比较 可以看出,因为TRACLUS的第三部分仍要对聚类结果进行再加工,所以优化后的算法聚类时间依然随着参数ε组数增加而保持缓慢增长,但这个增长十分缓慢,以至于生成对应81组参数的聚类结果所花费的时间,也未超过生成对应1组参数的聚类结果所花费时间的两倍。 本文运用OPTICS算法与离线批处理技术改进TRACLUS轨迹聚类算法。优化后的算法从需要两个外部参数降低到仅需要其中一个,即能够自动生成可供参考的参数组并输出对应多种密度的聚类结果,同时只额外消耗极少的时间,从而提高效率。实验结果表明,在最优参数未知需要对多组参数进行轨迹聚类时,改进算法在运行速度上较原算法具有明显优势。本文仅对TRACLUS的密度聚类部分进行改进,在未来工作中,将对轨迹划分和代表轨迹生成部分进行优化,进一步提升轨迹聚类的效率及质量。3.5 时间复杂度分析
4 实验与结果分析
5 结束语
猜你喜欢
农业工程学报(2022年7期)2022-07-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
吉林大学学报(理学版)(2020年3期)2020-05-29
中国惯性技术学报(2019年6期)2019-03-04
自动化学报(2018年7期)2018-08-20
现代装饰(2018年5期)2018-05-26
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
中国三峡(2017年2期)2017-06-09
周口师范学院学报(2016年5期)2016-10-17
