
加入惩罚因子的电商平台协同过滤推荐算法
2020-07-14 00:27崔国琪李林
软件导刊 2020年1期
崔国琪 李林

摘要:为提高推荐算法挖掘数据长尾信息的能力,降低推荐结果流行度,使推荐结果更多样,在传统协同过滤推荐算法基础上,分别将热门项目与活跃用户的惩罚因子引入相似性计算中,依据准确度、覆盖率、流行度等评价标准,在上海某电商平台销售数据集上进行比较,并通过多组实验验证不同参数对推荐算法的影响。结果显示,加入惩罚因子后基于用户的协同过滤推荐算法在N值取10、K值取3时,流行度为3.97,比传统方法降低了7.31%:加入惩罚因子后基于项目的协同过滤推荐算法在N值取10、K值取3时,准确率为7.65%,比传统方法提高了5.25%。由此证明加入惩罚因子的协同过滤推荐算法在保持算法准确率的同时,可在一定程度上降低推荐结果流行度。
关键词:推荐算法;协同过滤;惩罚因子;长尾效应;电商
DOI: 10. 11907/rjdk.192435
开放科学(资源服务)标识码(OSID):
中图分类号:TP312
文献标识码:A
文章编号:1672-7800( 2020)001-0103-05
0 引言
随着互联网、移动技术的快速发展,全球数据量呈指数型爆炸增长,用户获取的信息资源越来越丰富,但随之而来的“信息超载”问题使获取有效信息的难度越来越大[1]。为解决该问题,IBM、Google、Yahoo等多家公司陆续推出了个性化电子商务原型系统TELLIM。个性化推荐系统通过分析用户个体行为和偏好,“一对一”地提供其感兴趣的信息,并根据新录入的行为变化自动调整推荐内容。该方式不需要用户较大的参与成本,推荐内容也更准确[2]。协同过滤推荐算法是当前应用最为广泛的个性化推荐技术,其基本思想是根据其他用户偏好的项目进行推荐,首先找到一组与目标用户偏好一致或相近的邻居用户,然后分析邻居用户偏好,将邻居用户喜爱的项目推荐给目标用户[3]。目前,协同过滤推荐算法主要有基于内容的推荐[4-5]、基于邻域的推荐[6-7]、基于矩阵分解的SVD++算法[8]等。
为有效提高协同过滤推荐算法准确率,众多学者针对相似度计算进行了大量研究。李容等[9]提出利用用户共同项目数与用户平均评分修正因子改进传统相似度,同时改进协同过滤算法,并将其应用于电影推荐;王志虎等[10]提出基于用户历史行为的协同过滤推荐算法,根据用户历史行为预测用户对每一个项目的偏好程度,大幅降低了推荐误差;王余斌等[11]将改进的用户偏好与信任度引入传统协同过滤算法中,提出了基于用户评论评分与信任度的协同过滤算法;王永贵等[12]通过矩阵分解实现对原始数据的降维及数据填充,并引入时间衰减函数预处理用户评分,提出一种改进的协同过滤算法,可在多维度下反映用户兴趣变化;胡朝举等[13]通过对用户进行模糊C均值聚类操作,将用户分为用户簇,使用加权的欧氏距离计算相似度,提高了推荐精度,减少了评分误差。
现有算法在计算用户相似性时,没有考虑热门项目对相似性的影响,即大部分用户对热门项目有反馈,导致算法推荐结果越来越倾向于热门项目;另一方面,在计算项目相似性时,由于活跃用户对多个项目均有反馈,算法推荐结果更易受到活跃用户的影响。
针对以上问题,本文通过加入惩罚因子以降低热门项目和活跃用户相似性权重,在利用传统余弦相似度计算相似性的基础上改进相似性计算方法,并将改进的协同过滤算法在上海某电商公司购物评分数据集中进行实证研究,验证其可行性。
1 协同过滤推荐算法
1.1 传统协同过滤推荐算法
目前应用最广泛的协同过滤推荐算法主要包括基于用户的协同过滤算法与基于项目的协同过滤算法[14]。协同过滤推荐算法通过分析数据,生成当前用户最近邻居集合,将该集合最感兴趣的前N个项目推荐给当前用户,即Top N推荐,协同过滤推荐算法推荐过程主要分为3个步骤[15]。
(1)将数据表述为矩阵。根据用户对项目的评价建立m*n阶user-item评价矩阵R=(rij),m表示用户总数,n表示项目总数,rij表示第i个用户对第j个项目的评价,在本文使用的数据集中,rijE[0,5],0表示用户对该项目的兴趣最低,5表示最高。
(2)发现最近邻居。发现最近邻居指通过计算用户或項目相似度,建立当前用户最近邻居集,根据最近邻居集对项目进行兴趣排序,实现当前用户推荐。它可表述为针对目标用户ut,根据相似度排列顺序建立一个邻居集N={ u1,U2,…,un},设目标用户UT和ui的相似度为sim( UT,u;),相似度逐个递减,即sim(uT,UI)> sirTi( UT,U2)>…>sim (UT,un)。最近邻居集建立得准确与否,是协同过滤算法实现的关键。
基于用户的协同过滤算法通过计算用户相似度建立最近邻居集,本文通过余弦相似度计算目标用户(记为u)和邻居用户(记为v)之间的相似度,计算公式[16]为:
1.2 改进的协同过滤推荐算法
(1)基于用户的改进算法(UserCF-IIF)。用户相似度计算是基于用户对某个项目共同的反馈行为,但对热门项目来说,有太多用户对其作出反馈,这种反馈不能体现用户之间的差异性。所以加入惩罚因子lflog(l+IN(i)l以降低热门项目对用户相似度的影响,即冷门项目更能体现用户相似性,由式(1)得到:
(2)基于项目的改进算法(ItemCF-IUF)。两个项目相似度的出现是因为这两个项目同时出现在用户反馈列表中,即用户反馈行为对项目相似度的计算作出了贡献,但活跃用户反馈行为更多,对相似度影响更大。所以加入惩罚因子lflog(I+IN(u)l以降低活跃用户对项目相似度的影响,即不活跃用户更能体现项目相似性,由式(2)得到:
1.3 改进算法实现
(1)UserCF-IIF算法。
#一*一coding:utf-8一*一
import math
import operator
def UserSimilarity( train):
#为项目一用户矩阵生成反向表
item_users= dict()
foru, items in train.items():
fori in items.keys():
ifi not in item_users:
item_users[i]= set()
item_users[i] .add(u)
#计算用户之间有共同正反馈的项目
C= dict()
N= dict()
for i, users in item_users.items():
foru in users:
N.setdefault(u,O)
N[u]+=1
C.setdefault(u,{})
forv in users:
ifu==v:
continue
C[u] .setdefault(v,O)
C[u][v]+=l/math.log( l+len( users))
( 2)ItemCF-IUF算法。
#一*一coding:utf-8一*一
import math
import operator
def ItemSimilarity( train):
#计算项目之间对其有共同正反馈的用户
C= dict()
N= dict()
for u,items in train.items():
fori in items:
N.setdefault(i.O)
N[i]+=1
C.setdefault(i,{})
forj in items:
ifi-=j:
continue
C[i] .setdefault(j,O)
C[i][j]+=1,math.log( l+len( items)*1.0)
2 实验结果与分析
2.1 数据集选择
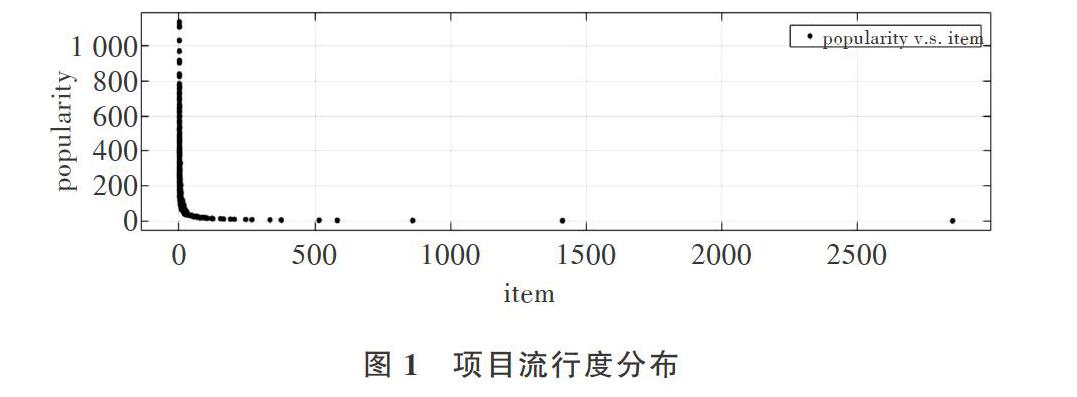
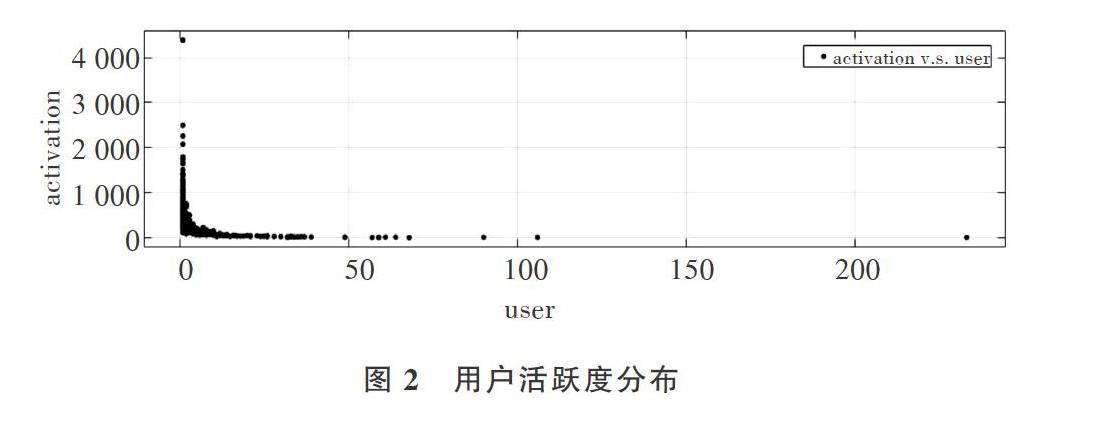
本文选取的数据集是上海某电商公司2018年6月至2018年12月的销售明细,原始数据集包括用户信息、商品信息、用户购买记录和评分记录。本文实验提取了用户购买记录和评分记录,其中包括2 929位用户、11 537件商品、310 040条购买评分记录(0-5分),用户评分记录最少为10条,数据稀疏度为99.08%,随机抽取其中的80%为训练集,其余20%为测试集。其用户活跃度与项目流行度分布均符合长尾效应[17]。
2.2 评价标准
本文推荐算法应用在数据集上的目的是向用户推荐其购买可能性最大的项目,而不是预测用户对项目可能的评分[18],故使用Top N推荐。Top N推荐指算法为用户提供個性化推荐列表,不采用RMAE、MAE等基于回归模型的评价指标,其推荐预测准确率通常使用准确率( Preci-sion)、召回率(Recall)、覆盖率(Coverage)及流行度(Popu-larity)度量19]。准确率指推荐给用户的项目属于测试集的比例,表示预测为正的样本中有多少是真正的正样本,则推荐结果准确率定义为:
其中R(u)表示提供训练集给用户u提供的推荐项目列表,T(u)表示用户u在测试集中作出反馈的项目列表。
召回率指测试集中有多少项目在用户的推荐列表中,表示样本正例有多少被预测正确,推荐结果召回率定义为:
覆盖率( Coverage)指推荐列表包含的所有推荐项目占项目总和的比例。设系统的用户集合为U,项目总和为I,推荐系统向用户提供的推荐项目列表为R(u),则推荐系统覆盖率计算公式为:
项目流行度指有多少用户对该项目作出反馈,项目流行度越高,代表该项目越热门[20]。设项目i流行度为P(i),推荐项目列表R(u)长度为N,推荐系统平均流行度可由式(9)计算得到。
2.3实验结果与分析
本文在协同过滤推荐算法中加入惩罚因子,在电商销售数据集上验证其可行性,以期提升相似度算法准确性,增强算法挖掘长尾数据的能力。在保证推荐算法准确率的前提下,尽可能加强算法对冷门项目推荐的权重。
本文采用的对比算法为两种协同过滤推荐算法:基于用户的协同过滤算法与基于项目的协同过滤算法,记为UserCF和ItemCF。加入惩罚因子的改进算法分别记为UserCF-IIF和ItemCF-IUF。实验推荐列表长度N取10,相似用户列表长度K取1-12不同值,推荐算法结果如图3所示。
其中横坐标为相似用户列表长度,从图3可以看到,随着K值的增加,各算法准确率逐步下降并趋近稳定,基于用户的改进算法较原算法准确率略低,基于项目的改进算法较原算法准确率稍有提高。由于数据稀疏性较高,各算法均在K取值为1时准确度最高,随着相似用户列表的增多,准确率也随之降低。
如图4、图5所示,随着K值的增加,各算法召回率、覆盖率逐渐上升并趋近稳定,基于用户的改进算法与基于项目的改进算法召回率、覆盖率均高于原算法。
在图6中,随着K值的增加,各算法流行度逐渐下降并趋近稳定,基于用户的改进算法流行度较原算法明显下降,但基于项目的改进算法流行度与原算法接近一致。
本文也进行了一次实验,其中相似用户列表长度不变,取K值为3,推荐列表长度N取10-100,N值以10为间隔,实验结果各指标变化基本不变,故实验结果未列出。
综合比较各评价标准,基于用户的改进算法较原算法准确率虽略有降低,但其召回率、覆盖率和流行度均优于原算法;基于项目的改进算法在准确率、召回率和覆盖率上均优于原算法,流行度与原算法无明显差异;基于项目的推荐算法在准确率上均高于基于用户的推荐算法,这主要是由于采用的电商平台数据集中,用户兴趣爱好一般比较固定,推荐算法往往围绕用户兴趣爱好推荐相关领域物品,但两种算法并无优劣之分。
3 结语
协同过滤推荐算法准确率是评价推荐算法优劣的重要指标,但挖掘数据中的长尾信息,将冷门项目更多地推荐给用户,使长尾曲线变得更加扁平,对用户选择与项目效益均具有重要意义。本文在传统协同过滤推荐算法基础上,分别将热门项目与活跃用户的惩罚因子引入相似性计算中,并在电商平台数据集上验证算法可行性。试验结果表明,本文算法在保持准确率的同时,有效挖掘了数据中的长尾信息,提高了冷门项目权重,向用户提供的推荐列表召回率与覆盖率均有提高,更能体现个性化推荐算法的多样性。下一步将针对数据稀疏性和冷启动问题,引入更多影响相似度的参数,进一步提高算法准确率。在算法方面,引入的参数越多,其算法复杂度也随之越高,如何更好地调整参数、优化算法也是待研究内容。
参考文献:
[1]SAYAKHOT P,CAROLAN-OLAH M.Sources of information on ges-tational diabetes mellitus. satisfactionWith diagnostic process and in-formation provision [J]. BMC Pregnancy and Childhirth. 2016, 16(1):287.
[2] YANG J M, LI K F.An inference-based collaborative filtering ap-proach[C].Third IEEE International Symposium on Dependable, Au-tonomic and SecureComputing, 2007: 84-94.
[3] 冷亚军.协同过滤技术及其在推荐系统中的应用研究[D].合肥:合肥工业大学,2013.
[4]WU M L,CHANC C H,LIU R Z.Integrating content based filteringwith collahorative filtering using co-clustering with augmented matri-ces[ Jl. Expert Systems with Applications, 2014 .41(6):2754-2761.
[5]杨武,唐瑞,卢玲.基于内容的推荐与协同过滤融合的新闻推荐方法[J].计算机应用,2016,36(2):414-418.
[6]L1 D S,CHEN C,LU Q,et al.An algorithm for efficient privacy-pre-serving item-based collaborative filtering[J].Future Ceneration Com-puter Systems, 2016.55: 311-320.
[7] 叶西宁,王猛.音乐个性化推荐算法TFPMF的研究[J].系统仿真学报,2019,31(7):1397-1407.
[8]KOREN Y.Factorization meets the neighborhood:a multifaceted col-lahorative filtering model[C].Proceedings of the 14th ACM SICKDDInternational Conference on Knowledge Discovery and Data Mining,2008:426-434.
[9] 李容,李明奇,郭文强.基于改进相似度的协同过滤算法研究[J].计算机科学,2016,43( 12):206-208, 240.
[10]王志虎,黄曼莹.基于用户历史行为的协同过滤推荐算法[J].微电子学与计算机,2017, 34(5):132-136.
[11]王余斌,王成良,文俊浩.基于用户评论评分与信任度的协同过滤算法[J].计算机应用研究,2018,35(5):1368-1371+1402.
[12]王永贵,宋真真,肖成龙.基于改进聚类和矩阵分解的协同过滤推荐算法[J].计算机应用,2018 .38(4):1001-1006.
[13] 胡朝举,孙克逆.基于用户模糊聚类的个性化推荐研究[J].软件导刊,2018, 17(2):31-34.
[14] 王惠敏,聂规划.融合用户和项目相关信息的协同过滤算法研究[J].武汉理工大学学报,2007(7):160-163.
[15] 张献忠.基于商品流行度和用户活跃度的推荐算法研究[J].电脑知识与技术,2014,10( 32):7641-7643+7649.
[16] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014, 35(2):16-24.
[17]PELTIER S,MOREAU F. Internet and the' long tail versus superstar effect' debate: evidence from the French hook market [J]. Applie-dEconomics Letters, 2012. 19(8):711-715.
[18] LINDEN G. What is good recommendation algorithm[ EB/OLl. http:,,cacm.acm.org/blogs/blogcacm/22925 -what-is-a-good-recommenda-tion-algorithm/fulltext.
[19] 郝立燕,王靖.基于项目流行度的协同过滤TopN推荐算法[J].计算机工程与设计,2013,34( 10):3497-3501.
[20]STECK H. Item popularity and recommendation accuracy ICl. TheFifth ACM Conference on Recommender systems, 2011: 125-132.
(責任编辑:江艳)
作者简介:崔国琪(1994-),男,上海理工大学管理学院硕士研究生,研究方向为数据挖掘;李林(1966-),女,博士,上海理工大学管理学院副教授、硕士生导师,研究方向为工业工程质量管理、服务管理。
猜你喜欢
今日农业(2022年16期)2022-11-09
现代企业文化(2018年13期)2018-06-09
机电信息(2015年28期)2015-02-27
