
Improved image captioning with subword units training and transformer ①
2020-07-12 02:34:20CaiQiangLiJingLiHaishengZuoMin
High Technology Letters 2020年2期
Cai Qiang(蔡 强) , Li Jing, Li Haisheng, Zuo Min
(School of Computer and Information Engineering, Beijing Techology and Business University, Beijing 100048, P.R.China) (Beijing Key Laboratory of Big Data Technology for Food Safety, Beijing 100048, P.R.China) (National Engineering Laboratory for Agri-Product Quality Traceability, Beijing 100048, P.R.China)
Abstract
Key words: image captioning, transformer, byte pair encoding (BPE), reinforcement learning
0 Introduction
Problems combining image and language understanding like image captioning continue to inspire considerable researches at the boundary of computer vision and natural language processing. In these tasks, it is reasonable to perform some fine-grained visual processing, or even multiple steps of reasoning to create high quality outputs. As a result, visual attention mechanisms have been widely adopted in image captioning[1-4]. These mechanisms improve image captioning performance by extracting salient and useful image features.
However, this problem can also be addressed from a language perspective. Image captioning is more than an image processing problem and a fine-grained method for generating high-quality captions is proposed in this paper. Image captioning has recently shown impressive results[2]by backing off words with a frequency below 5. The training vocabulary of neural models is usually limited in 10 000-30 000 words on MSCOCO[5]image captioning training data, but caption generation is an open-vocabulary problem, and especially for images with massive visual parts, image captioning models require a mechanism that generates more detailed and informative words.
For previous word-level caption models, the generation of out-of-vocabulary words is impossible and these models generate some common words with fixed sentence form. It is observed that such methods make assumptions that often do not hold true in a practical scene. For instance, there is not always a 1-to-1 correspondence between training image and corresponding up to 5 captions in that not all descriptive information is involved in the captions. In addition, word-level models are unable to generate captions unseen before.
In this work, image captioning models that train on the level of subword units[6]is investigated. The goal is to build a model which can handle open-vocabulary problem in the encoder-decoder network itself. The model is able to make the captions generation model more fine-grained and achieve better accuracy for the translation of rare words than back-off dictionaries. It is showed that the neural networks are able to learn rare descriptive words from subword representations in experimental analysis.
To make the image captioning process simpler, transformer[7], instead of recurrent neural network (RNN) or its variants is used as decoder part. Transformer, as a backbone architecture, has been applied to a large amount of natural language processing tasks[8,9]. Transformer is a novel neural network architecture based on a self-attention mechanism proposed by Google that has been proved particularly well suited for generation tasks, such as machine translation and text-to-speech. So it can also contribute to image captioning. The transformer outperforms both recurrent and convolutional models on academic English to German and English to French translation benchmarks. The transformer proposed by Google also complies with sequence-to-sequence structure, consisting of encoder and decoder. The encoder is made up of multi-head attention layer and feed forward layer for extracting features from source and the decoder part consist of masked multi-head attention layer, multi-attention layer and feed forward layer. The decoder part of the full transformer model is employed for decoding visual information. In transformer based image captioning (TIC) model, bi-direction long short-term memory (LSTM) decoder is replaced by transformer decoder for less training time and better captions generation.
This paper has 2 main contributions:
(1) Open-vocabulary image captioning is feasible by encoding (rare) words via subword units is proved. Moreover, byte pair encoding (BPE)[6]is utilized for the task of fine-grained word segmentation and caption generation. BPE allows for the representation of an open vocabulary, which makes it suitable for word segmentation in neural network architecture.
(2) Transformer based image captioning model is proposed, it adopts a self-attention based neural network to the task of image captioning. Other than taking advantage of the full transformer model, the decoder part of transformer is extracted for the generation of sentence and the experimental results show that the proposed method outperforms baseline model.
1 Related work
Most modern approaches[1,2]encode an image using a convolutional neural network (CNN), and feed this as input to a recurrent neural network or its variants, typically with some form of gating or memory mechanism. The RNN can generate an arbitrary length sequence of words. Within this common framework, many research work[10,11]explored different encoder-decoder structures including attention-based models. Multi-kinds of attention mechanism are applied to the output of one or more layers of a CNN, by predicting weights distribution on CNN output of the input image. Whereas, choosing the optimal number of image regions invariably leads to an unwinnable trade-off between coarse and fine levels of detail. Moreover, the arbitrary positioning of the regions with respect to image content may make it more difficult to detect objects that are poorly aligned to regions and to bind visual concepts associated with the same object.
Comparatively few previous works have considered addressing caption generation problem from a language perspective. Sennrich et al.[6]proposed byte pair encoding to segment words, which enable the encoder-decoder machine translation model to generate open-vocabulary translation. Applied originally for neural machine translation (NMT), BPE is based on the intuition that various word classes are made of smaller units than words such as compounds and loanwords. In addition to making the vocabulary smaller and the length of sentences shorter, the subword model is able to productively generate new words that are not seen at training time.
Neural networks, in particular recurrent neural network, has been the center of leading approaches to sequence modeling tasks such as image captioning, question answering and machine translation for years. However, it takes long time to train an RNN model in that it can only process the input data step by step. The transformer proposed by Google has received much attention in the last two years.In contrast to RNN-based approaches, the transformer used no recurrence, instead processing all words or symbols in the sequence in parallel while making use of a self-attention mechanism to incorporate context from words or features farther away. By processing all words in parallel and letting each word attend to other words in the sentence over multiple processing steps, the transformer was much faster to be trained than recurrent models. Remarkably, experiments on machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to be trained. Transformer achieves state-of-the-art performance on the machine translation task. Besides, given large or limited training data, the transformer model generalizes well to other sequence modeling problem. However, on smaller and more structured language understanding tasks, or even simple algorithmic tasks such as copying a string (e.g. to transform an input of ‘abc’ to ‘abcabc’), the transformer does not perform very well. In contrast, models that perform well on these tasks fail on large-scale language understanding tasks like translation and caption generation.
2 Approach
Given an imageI, the image captioning model takes as input a possibly variably-sized set ofkimage features,VI={v1,…,vk},Vi∈RD, such that each image crop feature encodes a sematic region of the image. The spatial image featuresVcan be variously defined as the output of bottom-up attention model, which extracts multi crop features under the architecture of Faster R-CNN[12]. The same approach in Ref.[1] is followed to implement a bottom-up attention model and the details are described in Ref.[1]. In Section 2.1, the practical use of BPE algorithm for captions segmentation is demonstrated. In Section 2.2, the architecture of TIC model is outlined.
2.1 Byte pair encoding
Byte pair encoding is a technique designed for simple data compression. BPE iteratively replaces the most frequent pair of bytes in a captioning sentence with a single, unused byte. This algorithm is adopted for subword segmentation. Instead of merging frequent pairs of bytes, it uses merge characters or character sequences. Following the work of Ref.[6], the BPE preprocess consists of 2 stages: learning BPE and applying BPE.
First of all, in learning BPE stage, the symbol vocabulary is initialized with the character vocabulary, and each word in image caption sentences is represented as a sequence of characters, plus a special end-of-word symbol ‘·’, which allows it to restore the original tokenization after caption generation. All symbol pairs are iteratively counted and replaced each occurrence of the most frequent pair (‘A’, ‘B’) with a new symbol ‘AB’. Each merge operation produces a new symbol which represents a character n-gram. Frequent character n-grams (or whole words) are eventually merged into a single symbol, thus BPE requires no shortlist. The final symbol vocabulary size is equal to the size of the initial vocabulary, plus the number of merge operations, the latter is the only hyperparameter of the algorithm. For efficiency, pairs that cross word boundaries are not taken into consideration. The algorithm can thus be run on the dictionary extracted from a text, with each word being weighted by its frequency.
After learning BPE stage, a fixed dictionary is completed. In applying BPE stage, all words in all sentences from training data are substituted for subword units according to the BPE dictionary. Then this dictionary is used to represent each subword units. At last, the one-hot vectorxfor each word is acquired. The embedding model embeds the one-hot vector into admodeldimensional vector. All these embedding vectors in one sentence are combined into a matrixL×dmodelas the input to the transformer decoder, whereLis the length of the sentence.
Two methods of applying BPE are evaluated: learning encodings only for image captioning training dataset, or learning the encoding on the union of the MSCOCO2014 image captioning training dataset and VQA v2.0 dataset[13](which is called expand BPE). The former has the advantage of being more compact in terms of text and vocabulary size, whereas the latter leads to accurate semantic units by taking the larger vocabulary into account.
2.2 Transformer based image captioning
Transformer based image captioning model contains 2 parts, the encoder and the decoder, as is shown in Fig.1.
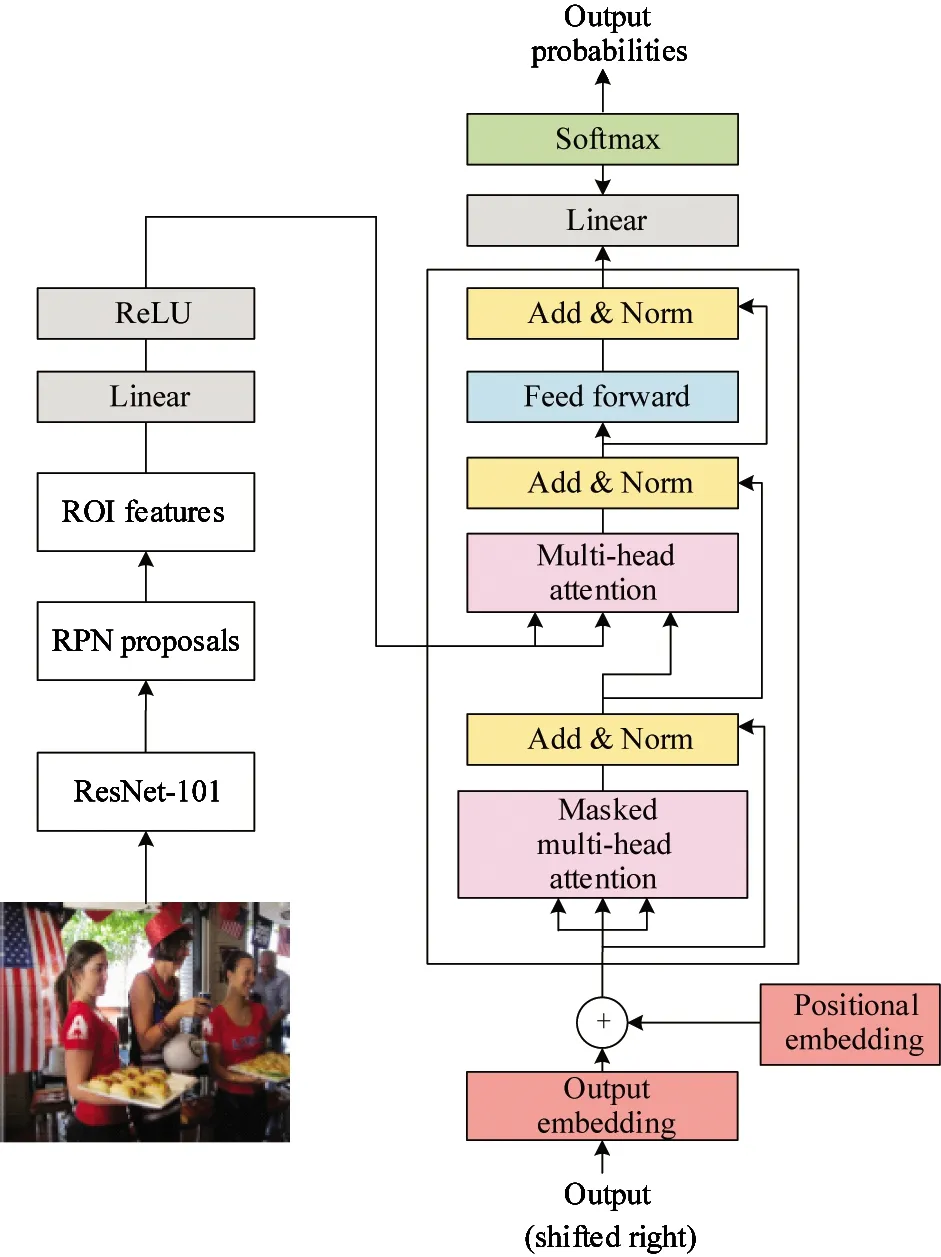
Fig.1 The framework of the proposed TIC model
Most image captioning models are made up of the encoder-decoder structure. The encoder used in this work is a bottom-up attention model borrowed from Ref.[1]. Bottom-up attention model utilizes Faster R-CNN for mapping an image to a context featureVI. This process is shown as
VI=FasterR-CNN(I)
(1)
where,Iis vector of input image,VI={v1,…,vk} is the image features processed by Faster R-CNN based bottom-up attention model.
Faster R-CNN is an object detection model designed to localize and recognize objects in a project given image with bounding boxes. Objects are detected by Faster R-CNN in 2 stages. The first stage, described as a region proposal network (RPN), predicts object proposals. Then the predicted top box proposals are selected as input to the second stage for labels classification and class-specific bounding box refinements. In this work, ResNet-101 CNN is used as feature extractor in Faster R-CNN model. The final output of the model is selected as the input caption model. For each selected regioni,VIis defined as the mean-pooled convolutional feature from this region, such that the dimensionDof the image feature vectors is 2 048. Faster R-CNN is served as a ‘hard’ attention mechanism using this fashion, as only a relatively small number of image bounding box features are selected from a large number of possible configurations.
The decoder part of the transformer with stacked attention mechanisms is taken to decode the encoded image feature into the sentence. The transformer model composes of a stack ofNidentical layers and contains no RNN structure. Note that each layer has 3 sub-layers. The first sub-layer uses the multi-head self-attention mechanism. The multi-head attention is shown as
(2)
H=Concat(h1,…,hn)
(3)
O=HWh
(4)

Fig.1 shows that the inputs of this layer are fixed to output embedding plus positional embedding. This sub-layer makes use of a masked mechanism for preventing this model from seeing the future information, which ensures the generation of the current word with only the previous generated words. In contrast to the first sub-layer, the second sub-layer is a multi-head attention layer without the masked mechanism in that it takes all the image features into consideration in every time step. The multi-head attention is employed over preprocessed image features and the output of the first sublayer. This sublayer is vital importance to blend the text information with the image information using attention mechanism. The third sublayer is a position-wise fully connected feed-forward network aiming at selecting the most relevant information for generating image captions. In addition, a residual connection is utilized around each of the 3 sub-layers in the transformer decoder, followed by layer normalization. Finally, a full connected layer and a softmax layer is used to project the output of the transformer decoder to the probabilities distribution of the vocabulary. Using the notationy1:Tto refer to a sequence of words (y1,…,yT), at each time steptthe conditional distribution over possible output words is given by
(5)
where,Wp∈R|Σ|×Mandbp∈R|Σ|are learned weights and biases.

(6)
For fair comparison with recent work[14], results optimized for CIDEr is also reported. Initializing from the cross-entropy trained model, the training seeks to minimize the negative expected score:
LR(θ)=-Ey1:T~pθ[r(y1:T)]
(7)
where,ris the score function (e.g., CIDEr). Following the approach described as self-critical sequence training (SCST), the gradient of this loss can be approximated:
(8)
3 Experiments and results
3.1 Datasets
The MSCOCO2014 captions dataset[5]is employed to evaluate the proposed transformer based image captioning model. For validation of model hyperparameters and offline testing, this paper uses the ‘Karpathy’ splits[16]that have been used extensively for reporting results in prior work. This split contains 113 287 training images with 5 captions each, and 5 K images respectively for validation and testing. To explore the performance of BPE, all sentences are converted to lower case, tokenized on white space, and substituted words with subword units according to BPE vocabulary. To evaluate caption quality, this work uses the standard automatic evaluation metrics, namely SPICE[17], CIDEr, METEOR, ROUGE-L[18]and BLEU[19].
To evaluate the proposed expand BPE model, the recently introduced VQA v2.0 dataset[13]is used. VQA v2.0 is proposed to minimize the effectiveness of learning dataset priors by balancing the answers to each question, but in the experiment this dataset only takes advantage of expanding BPE corpus with 1.1 M questions and 11.1 M answers relating to MSCOCO images.
3.2 Experiment settings
For fair comparison with bottom-up and top-down baseline model, TIC model takes the same pretrained image features of bottom-up and top-down baseline model as inputs. To pretrain the bottom-up attention model, Anderson et al.[1]initialized Faster R-CNN with ResNet-101 pretrained for classification on ImageNet, then trained it on visual genome[20]data. For the six-layer-stacked transformer model, this work sets the model size which isdmodelto be 512 and the mini-batch size to be 32. The Adam method is adopted to update the parameters of transformer. The initial learning rate of the transformer is 4×10-4. The momentum and the weight-decay are set as 0.9 and 0.999 respectively. All implements of neural networks are based on PyTorch deep learning framework. In evaluation stage, the beam search size is set to 5 for high-quality caption generation at the sacrifice of decoding time.
3.3 Image captioning results
Table 1 shows single-model image captioning performance on the MSCOCO Karpathy test split. TIC+BPE-10K-exp stands for expanding BPE trained on MSCOCO2014 captions dataset and VQA v2.0 dataset with a dictionary of 10 000. The TIC model obtains similar results to baseline, the existing state-of-the-art on this test set. TIC plus BPE training model achieves significant (2%-7%) relative gains across all metrics regardless of whether cross-entropy loss or CIDEr optimization is used, which illustrates the contribution of transformer and BPE algorithm to image captioning task.
In Table 1 the performance of the improved TIC model and the existing state-of-the-art bottom-up and top-down baseline is demonstrated in comparison to SCST approach on the test portion of the Karpathy splits. For fair comparison, results are reported for models trained with both standard cross-entropy loss, and models optimized for CIDEr score. Note that the SCST[14]takes advantage of reinforcement learning to optimize evaluation metrics. And it also uses ResNet-101[21-23]encoding of full images, similar to the bottom-up and top-down baseline model and TIC model. All results are reported for a single model with no fine-tuning-of the input ResNet/Faster R-CNN model.
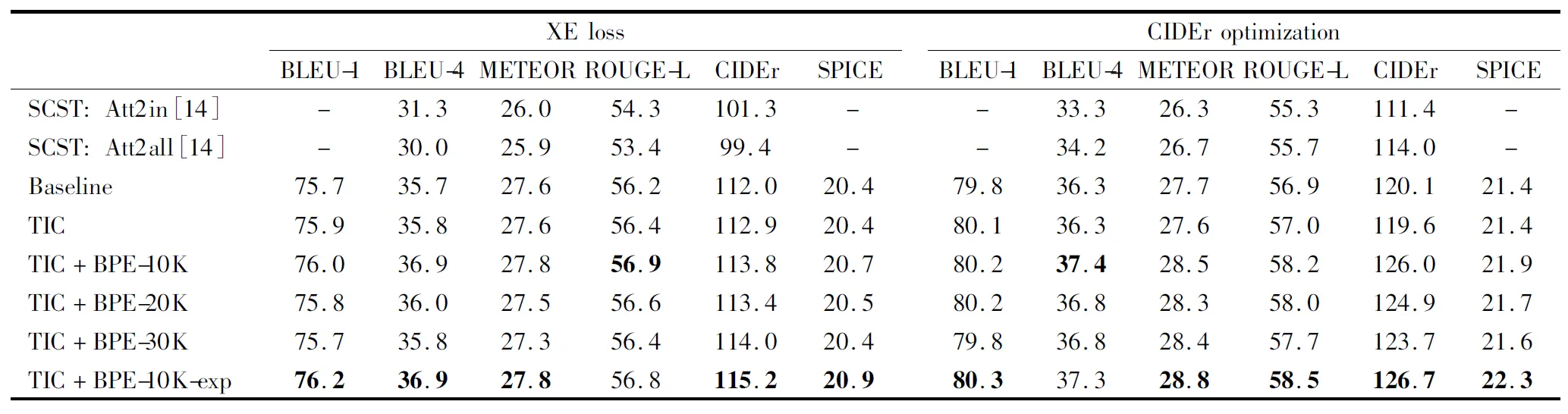
Table 1 Performance of different models on MSCOCO2014
Compared to the bottom-up and top-down baseline model, TIC model obtains slightly better performance under both cross-entropy loss and CIDEr optimization loss, which shows the feasibility of replacement of RNN with transformer. Moreover, instead of using word-level model with a back-off dictionary, BPE subword units model brings improvements in the generation of rare and unseen words and outperforms the bottom-up and top-down baseline by 0.1-1.2 BLEU-4 and 0.9-3.2 CIDEr under XE loss training. Regardless of whether cross-entropy loss or CIDEr optimization is used, Tabel 1 shows that TIC models acquire improvements across all metrics using just a single transformer decoder model and BPE method. The TIC model achieved the best reported performance on the Karpathy test split as illustrated in Table 1.
In addition, the results about the effect of the different sizes of BPE dictionary is explored. Three different sizes are implemented to find the appropriate settings. The TIC+BPE-10K model means that BPE dictionary size is set to 10 000. From these scores in Table 1, it can be implied that all TIC with BPE model is improved over the baseline model. And when the vocabulary size is set to 10 000 and trained on multi-dataset, the TIC+BPE-10K-exp model gets the best performance. According to these scores, it can be inferred that fixed dictionary size is necessary for the generation common description. Whereas, it is believed that larger dictionary size is needed given larger image captioning dataset.
4 Conclusions
This work proposes a novel transformer image captioning model which is improved by training on subword units. It is shown that image captioning systems are capable of open-vocabulary generation by representing rare and unseen words as a sequence of subword units. The transformer decoder with multi-head self-attention modules enables the caption model to memorize dependencies between vision and language context. With these innovations, performance gains have been obtained over the baseline with both BPE segmentation and transformer decoder. The state-of-the-art performance is achieved on the test portion of the Karpathy MSCOCO2014 splits. In addition, the proposed models can be taken into consideration in vision to language problems like visual question answering and text-to-speech.
 High Technology Letters2020年2期
High Technology Letters2020年2期
- High Technology Letters的其它文章
- MW-DLA: a dynamic bit width deep learning accelerator ①
- Influence of velocity on the transmission precision of the ball screw mechanism ①
- Physical layer security transmission algorithm based on cooperative beamforming in SWIPT system ①
- GNSS autonomous navigation method for HEO spacecraft ①
- Control performance and energy saving of multi-level pressure switching control system based on independent metering control ①
- RGB and LBP-texture deep nonlinearly fusion features for fabric retrieval ①