
利用机器学习对生物医药文献命名实体识别和关系抽取研究
2020-07-09 08:16吕佳高
机器人技术与应用 2020年2期
王 熙 吕佳高
(北京航空航天大学软件开发环境国家重点实验室,北京,100083)
0 引言
近年来,随着科学技术的迅猛发展,海量的科研成果涌现,极大地丰富了科技文献宝库。据统计,目前全球每年发表的科技论文在500万篇以上,且每年增长率约为7%~8%,而这其中的80%-90%都是生物医药文献[1]。
生物医药研究领域存在文献数量庞大的情况,在实验过程中新发现、新积累的数据和研究对象也增长迅速,因此迫切需要运用自然语言处理和机器学习的新方法对该领域的命名实体识别和关系抽取进行研究和改进。生物医药文献的命名实体识别和关系抽取是进行大规模生物医药数据分析的重要工具,已经被广泛应用于许多实际的任务中,例如生物医药网络构建、基因优先排序、药物重定位、新药预测、知识库构建等。其中,生物医药命名实体识别是生物医药文本挖掘的关键步骤,随着技术的不断完善,文本挖掘系统的准确性也在不断提高。近10年,生物医药文本挖掘和自然语言处理技术取得了巨大突破,并从生物医药文献中挖掘出有价值的科学信息,为科研人员和大众服务[2]。
1 生物医药文献命名实体识别和关系抽取研究
1.1 生物医药文献命名实体识别
命名实体最初是在第六届消息理解会议(MUC)[3]上被提出。在语言使用中,命名实体具有独立的意义,常常作为一个整体出现在语句中。命名实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,其扩展任务还包括名实体的单复数识别任务。
生物医药文献命名实体识别相较于一般的命名实体识别更加专业化,不同的研究对命名实体的定义各有不同,主要体现在实体类型的粒度上,如医疗一体化语言系统UMLS[4]定义的语义类型把命名实体分为3类:医疗问题(包括疾病和症状)、治疗、检查。这种分类充分体现了面向问题的思想,医疗手段是为了治疗医疗问题,检查是为了确认医疗问题。
1.2 生物医药文献实体关系抽取
实体和实体之间存在着语义关系,当两个实体出现在同一个句子里时,上下文环境就决定了两个实体间的语义关系,如雇员和公司间的雇佣关系、商品和类目之间的类属关系、药品和疾病之间的治疗关系等。完整的实体关系包括两方面:关系类型和关系的参数,其中关系类型说明了是什么关系,如雇佣关系、类属关系等;关系的参数则是发生关系的实体,如雇佣关系中的雇员和公司,并且至少是两个参数,两个参数的关系叫二元关系,两个以上参数的关系是多元关系。
实体关系抽取任务在命名实体识别基础上开展,对生物医药文献中同一个语句中的两个命名实体赋予预定义的关系类型,从而将该任务转化为分类问题,通常采用基于机器学习的方法来实现,评价指标采用精确度、召回率和F值。
2 相关算法研究
本文基于大量英文生物医药科技文献数据,利用递归神经网络、卷积神经网络、条件随机场等多种机器学习模型,进行生物医药领域的文献命名实体识别和关系抽取研究,提高相应性能指标,并最终构建了一个生物医药文献热点发现和追踪系统。该系统主要研究方法如下。
2.1 生物医药文献命名实体识别算法
本文利用带有条件随机场层的双向长短时记忆网络(Bi-LSTM-CRF)模型进行生物医药文献命名实体的识别和标注,并使用多任务学习方法,利用多个数据集同时训练和学习,来提升命名实体识别算法的性能。
通过比较不同的多任务模型,并针对生物医药领域的命名实体识别,笔者提出一种新的交叉共享网络结构。该模型基于卷积神经网络,以条件随机场为输出层的双向长短时记忆网络(Bi-LSTM-CNN-CRF)单任务学习模型(STM)为基础,如图1所示。
在上述模型中,共享的双向长短时记忆网络Bi-LSTM单元用以学习共享的特征[5],并且针对每个数据集都有一个独占的双向长短时记忆网络Bi-LSTM单元,用以学习任务相关的特征。该模型能够捕捉两个数据集的特征信息,并充分利用两者的特性,优化主数据集的命名实体识别效果。多任务学习模型中的嵌入层、双向长短时记忆网络Bi-LSTM层、条件随机场CRF输出层的内部结构与基准模型中对应层的结构完全相同。
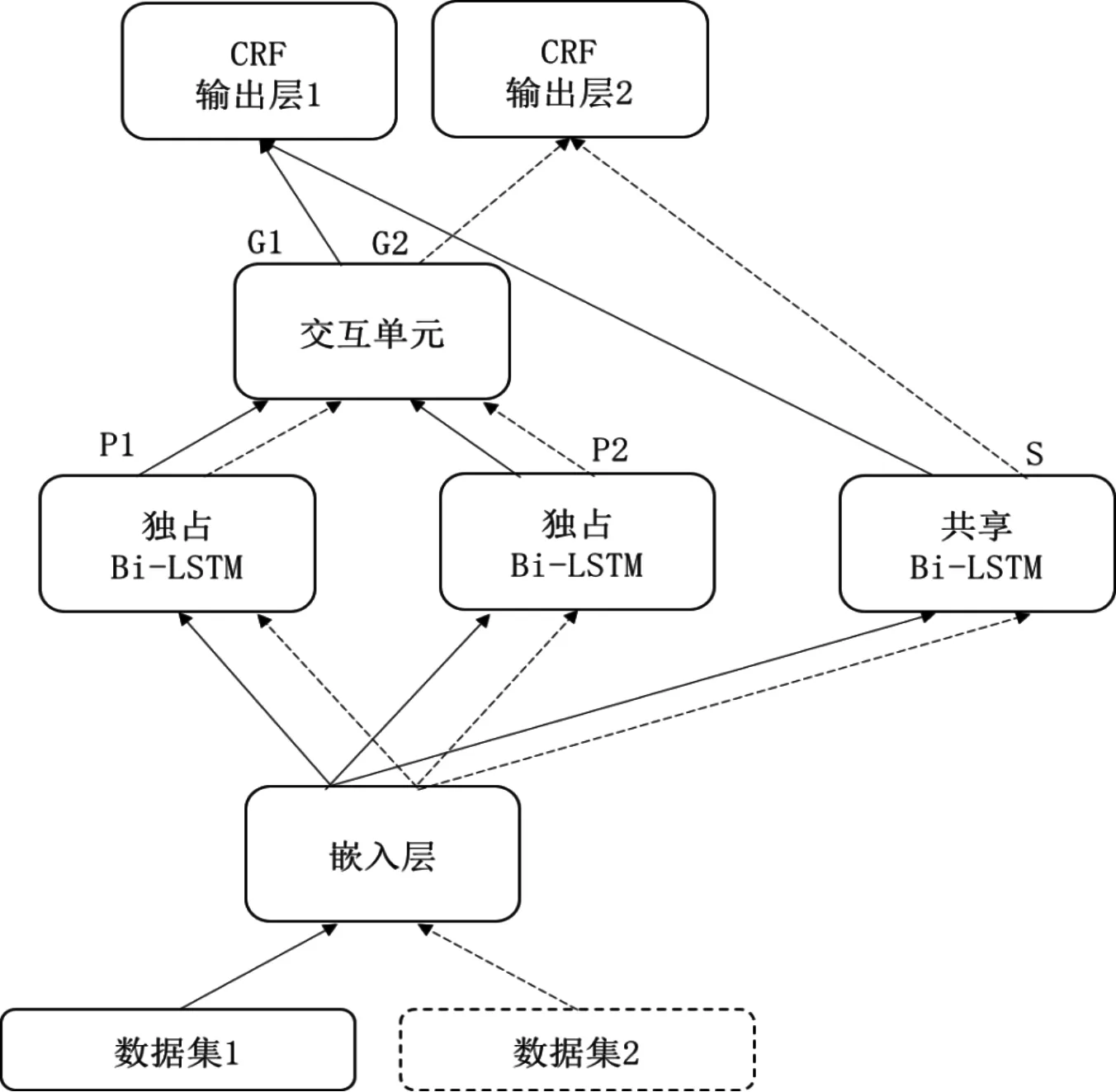
图2 交叉共享多任务学习模型(CS-MTM)
如图2所示,数据集中的词向量和字符向量首先被输入到嵌入层。在交叉共享结构多任务学习模型中,嵌入层的结构与基准模型中嵌入层的结构相同。嵌入层能够捕捉到词向量和字符向量中的信息,并生成最终的表征向量,供后续的双向长短时记忆网络Bi-LSTM层使用。
笔者通过实验将Ma[6]等学者提出的单任务模型作为基准的单任务学习模型(STM)和其他的多任务学习模型(MTM),并对其识别效果进行对比,实验结果如表1所示。表1展示了不同模型分别在BC2GM、Ex-PTM、NCBI-disease、Linnaeus这4个目标数据集上的效果,包括精确率、召回率、F1值的百分比指数,表中加粗数值代表当前数据集的最佳F1值。
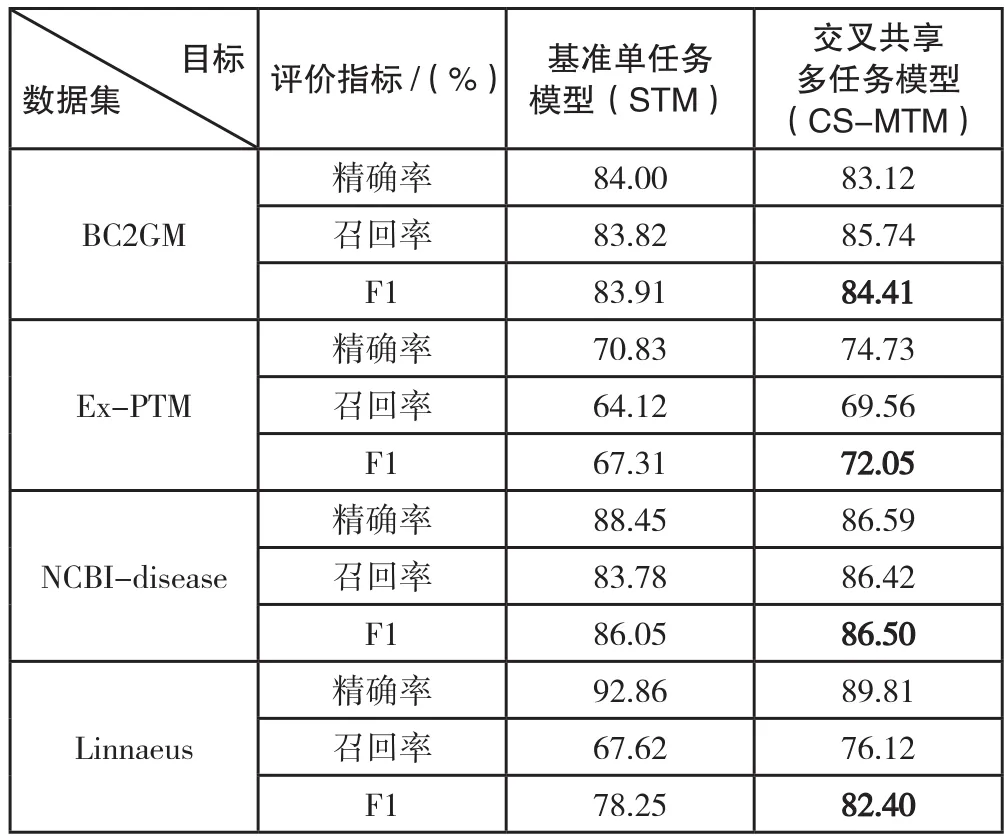
表1 命名实体识别效果对比实验结果
通过比较各个数据集的精确率和召回率结果可以发现:交叉共享多任务模型(CS-MTM)倾向于产生更高的召回率,并充分利用共享特征和独占特征,从而减少了假负率。
2.2 生物医药文献关系抽取算法
本文提出一个用于生物医药领域事件抽取和关系抽取的卷积神经网络。该模型将输入处理成了一种词表示,充分利用多种语义特征信息,采用基于卷积神经网络的分类模型,能同时用于检测实体关键词和实体关系信息,实现自动化的关系抽取,达到较为理想的关系抽取效果。
笔者选用图尔库大学开发的生物事件提取系统TEES[7](Turku Event Extraction System,TEES)作为基准模型,TEES的整个处理系统是一个流水线结构。该模型使用了词向量、词性标注、距离特征、实体特征、相对位置、路径嵌入、最短路径嵌入和事件参数嵌入等8种特征向量,所有特征均以向量的形式表示,而且每一个词语标记都对应唯一的特征向量。
设计的系统将结果作为分类模型的输入,分类模型采用卷积神经网络模型,替换基准模型TEES系统中的支持向量机(SVM)[8]分类模型。该模型通过使用多种特征向量,得到关系抽取结果,提升了模型的效果;并具有原始TEES系统模块化的属性,方便使用者进行修改和拓展,如图3所示。
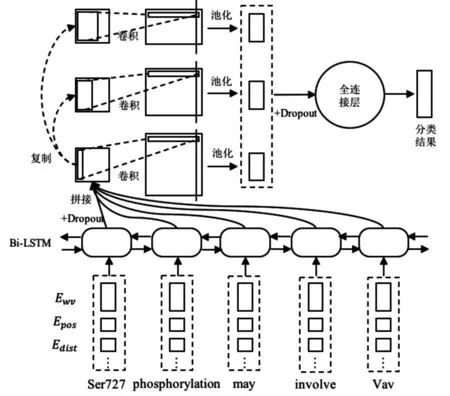
图3 分类模型结构图
设计的模型将输入处理成了一种词表示,充分利用多种语义特征信息,采用基于卷积神经网络的分类模型,可同时用于检测实体关键词和实体关系信息,实现自动化的关系抽取,达到较为理想的关系抽取效果。
笔者利用生物医学数据集BioNLP系列(EPI11、GE09、GE11、GE13、PC13),分别对TEES模型和Ours(集成模型)的精确率、召回率、F1值进行百分比指数对比试验[9-10],实验结果如表2所示。BioNLP系列数据集具有丰富的语料信息,并拥有多样的数据标注类型和相对小的数据规模。从表2中可以看出,设计的模型(Ours)除了在GE09语料数据集上的F1值达到51.79%,略逊于TEES模型外,在EPI11、GE11、GE13、PC13语料数据集上均实现了较好的效果。
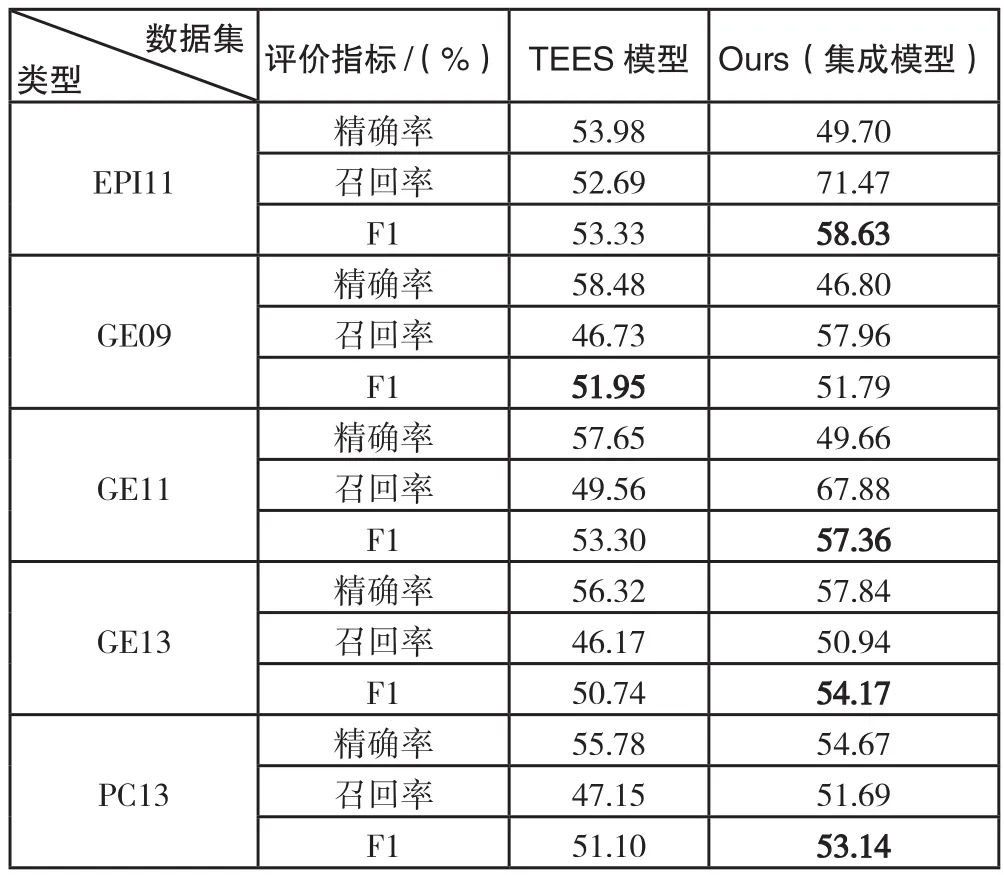
表2 BioNLP数据集对比实验结果
本文提出的基于卷积神经网络关系抽取模型,通过使用多种特征向量,提升了模型的效果。将TEES系统的分类模型替换为卷积神经网络模型,并在数据集上进行测试,实验结果显示该模型可实现较为理想的效果。
2.3 生物医药领域热点主题的发现
传统的文本挖掘系统,文献数据通常是以手工定义的分类或关键词来进行组织的,需要花费大量的人力和时间。为了减少处理大量文献数据的成本,本文提出使用主题模型(LDA)[11]来构建一个文本挖掘系统,通过该模型挖掘出的主题,能够帮助终端用户更好地对文献数据进行探索和查看。
针对生物医药领域文献,笔者提出了一个基于LDA主题模型的生物医药文献挖掘系统BioTopic,BioTopic是一个浏览器/服务器结构(Browser/Server)系统,可以分为6个组成部分:数据获取、数据存储、数据预处理、索引和检索、主题模型、应用服务。其中,数据获取可从已有的文献数据库中获取标题、作者、机构、摘要等信息;数据存储可为海量的文献数据提供存储功能,采用一个分布式的非关系型的数据库(NoSQL)进行文献数据的存储;在数据预处理部分,使用了基于名词词组块和词性标注的预处理策略,以提升挖掘出的主题的一致性;利用主题模型,可以获取对应主题中作者和机构的列表,并按相应的发表数量进行排序,此外,还可以获取研究者之间的关系,例如共同作者网络和机构内协作网络等;在应用服务部分,大量的挖掘应用构建于模型部分和搜索部分。
BioTopic系统设计如图4所示。
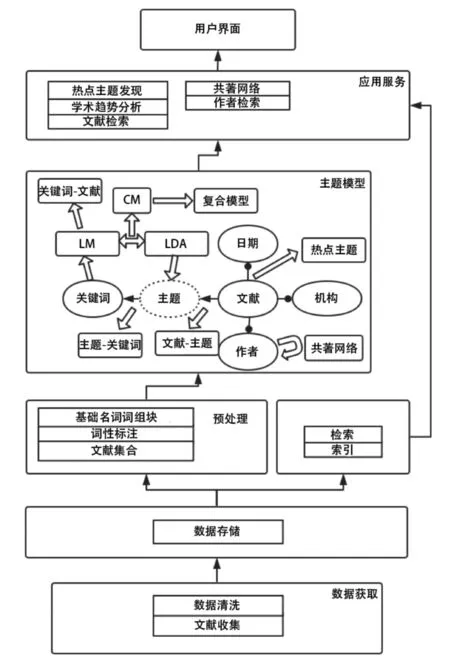
图4 BioTopic系统设计图
BioTopic系统能够从大量文献中挖掘出热点主题。如图5所示,BioTopic展示了生物文献中的热点主题,包括:real time pcr assay(实时定量聚合酶链反应检测)、arabidopsis thaliana(拟南芥)、reactive oxygen species(活性氧簇)、inflammatory response(炎症反应)、genetic diversity(遗传多样性)、cell line(细胞株)、breast cancer(乳腺癌)、estrogen receptor(雌激素受体)、species richness(物种丰富度)、neuron(神经元)、cell death(细胞坏死)、transcription factor(转录因子)、water quality(水质)、crystal structure(晶体结构)、e.coli(大肠杆菌)、synaptic plasticity(突触可塑性)、microbial community(微生物群落)、ms medium(培养基)、molecular mechanism(分子机理)、ion channel(离子通道)、stem cell(干细胞)、growth rate(生长率)、gene expression(基因表达)、hepatitis virus(肝炎病毒)、phylogenetic analysis(系统进化分析)、signaling pathway(信号通道)、heat shock protein(热激蛋白)、significant association(显著相关性)、molecular dynamic simulation(分子动力学模拟)等主题词。其中,字体越大的主题词语热度越高,主题的热度值由该主题下文档的数量所决定。

图5 BioTopic热点主题词云
BioTopic系统在对文献进行预处理后,使用LDA主题模型分析和挖掘发现生物医药领域的热点主题,这有助于发现更多有意义、有价值的主题。
2.4 生物医药文献热点发现和追踪系统
本文基于上述相关技术设计生物医药文献热点发现和追踪系统,依托LDA主题模型发现生物医药热点主题,并进行可视化展示,同时形成热点主题报告,包括相关领域、相关热点、相关作者、相关机构等信息。
生物医药文献热点发现和追踪系统基于海量的生物医药文献进行多角度、多层次的挖掘和分析,然后以多种不同的方式对挖掘结果进行展示,便于用户了解生物医药领域的最新热点,掌握该领域内的热点变化情况。图6展示了该系统的总体架构。
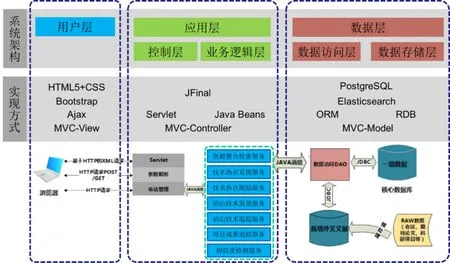
图6 生物医药文献热点发现和追踪系统总体架构
该系统分为用户层、应用层和数据层3个层次,其中应用层又分为控制层和业务逻辑层,数据层又分为数据访问层和数据存储层。原始文献相关数据经过预处理后存入数据库,供系统使用。
基于海量外文文献发现的知识主要是指抽取与领域相关的实体,如生物医药领域的一些专家、优势机构及项目成果,并整合三者建立多维语义网络,从而构建一个丰富的知识库(Knowledge Base)。基于该知识库,通过主题模型和频繁模式挖掘等技术手段,进一步发现重点领域的产业技术研究知识热点,如生物医药领域开始关注大数据、可穿戴设备的研究;跟踪知识热点涉及到的专家、机构、项目成果等。从数据处理角度看,其基本流程如图7所示。
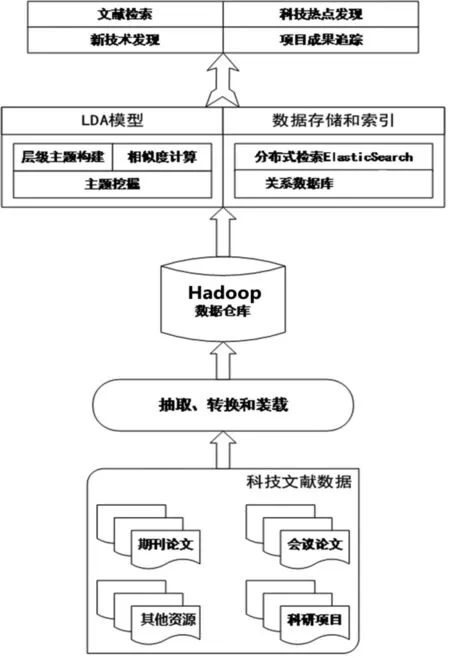
图7 数据处理流程示意图
生物医药文献热点发现和追踪系统的知识热点发现模块,首先采用自然语言处理技术对外文文献数据进行预处理,然后采用主题模型从外文文献数据中提取有意义的主题(知识热点),对重点领域新出现的、关注频率较高的新技术进行发现;同时提取与主题相关的研究人员、研究机构等实体信息,建立主题、研究人员、研究机构之间的对应关系,并对其他功能子系统提供知识热点和实体的查询服务;还可对知识热点和其他实体进行重要性排序,最终以词云和列表等形式展示知识热点,以关系网络形式等展示知识热点、学者和机构的关联关系,用户可以对感兴趣的主题知识热点进行订阅。
除了从海量文献中发现知识热点,该系统还可以通过知识热点追踪模块,利用技术手段并结合专家建议对该领域内的知识热点进行跟踪,提供与知识热点主题词相关的详细信息,包括相关文献、作者、机构等信息,并对相关信息进行简要分析,例如该知识热点的出现时间、发展趋势等。此外,该系统可对技术领域情报需求进行快速响应,从领域角度提供分析信息,节省研究人员搜索确定有效文档的时间和精力。
2.5 生物医药文献热点发现和追踪系统功能
2.5.1 知识热点百科
利用维基百科数据,可获取该技术基本概况、应用领域、起源、发展阶段等信息,供研究者初步了解知识热点的基本信息,如图8所示。

图8 知识热点百科
2.5.2 知识热点热度曲线
根据知识热点在不同年份对应的文献数量,可以绘制一张文献数量变化趋势图。文献数量的变化能间接反映知识热点的热度变化,如图9所示。

图9 知识热点热度曲线
2.5.3 相关知识热点
使用知识热点关键词对文献进行共现分析,寻找与之相关的知识热点词语并绘制成词云,如图10所示。
2.5.4 知识热点与学者关联
利用关联规则挖掘技术,建立知识热点之间的关联。知识网络系统由知识节点(指各类知识单元)以及节点之间的关联构成,根据主题模型挖掘的结果可以建立知识热点和学者的关联,如图11所示。
2.5.5 知识热点与机构关联
类似知识热点与学者的关联,该模块可以构建知识热点和机构的关联,如图12所示,显示与区块链相关的机构。
2.5.6 知识热点与文献关联
对于给定的知识热点,筛选出与之相关度最高的文献,并分类整理成文献列表,供研究者阅读和参考,如图13所示。
生物医药文献热点发现和追踪系统实现了海量外文生物医药文献的检索,并能实现相应的扩检缩检;同时以图形化的形式展示了LDA主题模型发现的生物医药热点主题;对热点主题形成追踪报告,涵盖相关领域、相关热点、相关作者、相关机构等信息,提高了生物医药文献的挖掘和检索效率,可为使用者提供有效的参考帮助。
3 结论

图10 相关知识热点
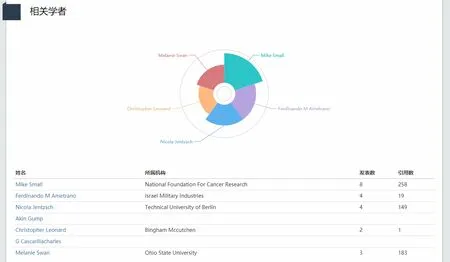
图11 知识热点与学者关联
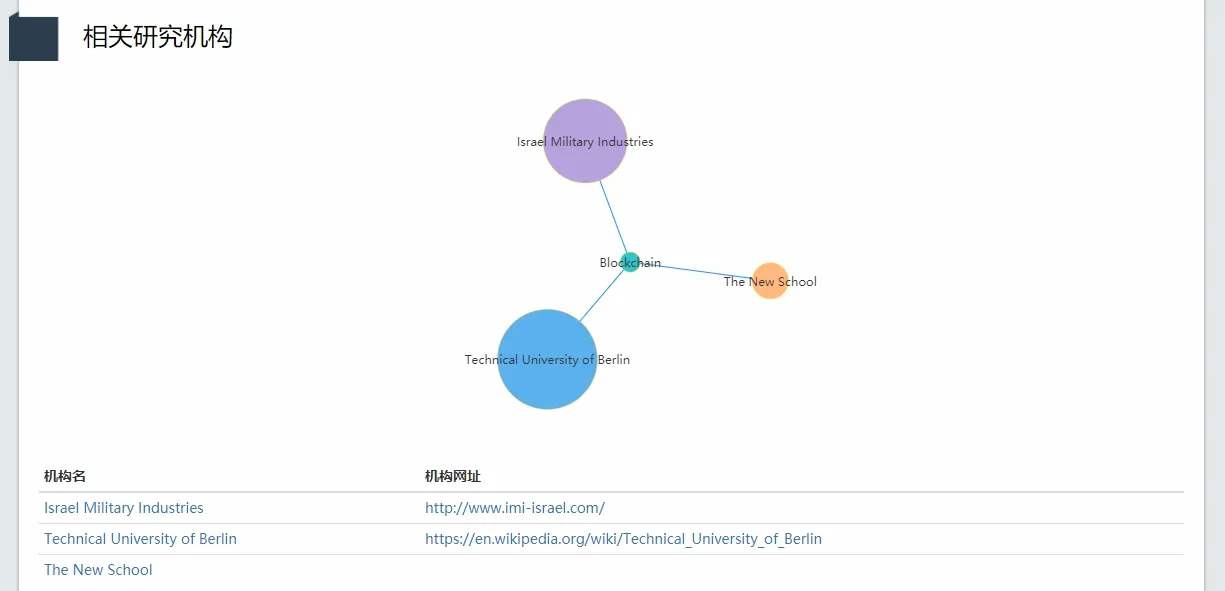
图12 知识热点与机构关联

图13 知识热点与文献关联
本文研究基于大量英文生物医药科技文献数据,利用递归神经网络、卷积神经网络、条件随机场等多种机器学习模型,并在此基础上综合交叉共享多任务学习模型、分类模型、LDA主题模型等建立了一个生物医药文献热点发现和追踪系统,用以生物医药领域的实体识别和关系抽取研究。实验表明,该系统可以实现对海量文献中热点主题的主动挖掘,有效提升了生物医药文献的挖掘和检索效率,为相关应用者提供高效、有价值的参考。
猜你喜欢
医疗装备(2022年20期)2022-11-11
临床检验杂志(2022年8期)2022-10-19
加油站服务指南(2022年6期)2022-07-28
医疗装备(2022年8期)2022-05-16
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
华人时刊(2020年15期)2020-12-14
车迷(2019年10期)2019-06-24
快乐语文(2018年7期)2018-05-25
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
