
基于卷积神经网络的软件漏洞自动分类方法
2020-07-07 06:23刘烊侨杨频王炎
现代计算机 2020年15期
刘烊侨,杨频,王炎
(四川大学网络空间安全学院,成都610065)
0 引言
随着信息技术的飞速发展,互联网和计算机的应用给社会带来的影响是双重的。它们带来了便利,但也带来了巨大的风险和隐患。近来,随着各个行业的数字化水平的提高,信息安全问题变得越来越突出。漏洞的定义是指未经授权的人员可以非法利用的系统软件和硬件缺陷。一旦信息系统的漏洞被恶意攻击者所利用,信息系统的安全性将面临极大的风险,可能造成不可估量的后果。例如,2017 年,黑客利用Windows系统漏洞,用比特币勒索病毒对全球200 万台终端发起过攻击,攻击次数高达1700 万余次。黑客可以利用办公室漏洞进行高级持久威胁(APT)攻击,传播僵尸网络,勒索软件等。近年来,漏洞的数量和种类逐渐增多,因此软件漏洞的管理和分析变得越来越重要。如果能够有效地对漏洞进行分类和管理,不仅可以提高漏洞修复和管理的效率,还可以降低系统受到攻击和破坏的风险,这对于系统的安全性能至关重要。因此,越来越多的研究将机器学习和深度学习应用到漏洞自动化分类中。但由于漏洞数量大、漏洞描述文本简短且生成的词向量空间具有高维和稀疏的特征,导致这些方法分类效果不理想。为解决上述问题,提出了一种基于深度学习的漏洞自动化分类模型(Word2Vec-CNN),目的在于提高漏洞自动化分类的准确度。使用Word2Vec 方法构建词向量,利用CNN 神经网络模型构造自动漏洞分类器,实现漏洞自动化分类。接着构建了其他三个模型,分别是One-hot-CNN、One-hot-RNN 以及Word2Vec-RNN 作为实验对比的基线模型。然后将四种模型与传统机器学习算法[1](神经网络、贝叶斯算法)在单个CVSS[2]属性分类上进行了比较,最后将四种模型在漏洞类别的分类效果上进行了比较,测试结果表明,提出的漏洞自动化分类模型(Word2Vec-CNN)综合效果最优,有效地提高了漏洞分类的性能。
1 相关研究
近年来,在文本分类[3]领域中已经提出了许多机器学习方法。其中,许多研究将文本分类技术用于漏洞分类这一场景下。Davari 等人提出了一种基于激活漏洞条件的自动漏洞分类框架[4],使用不同的机器学习技术(随机森林、C4.5 决策树、逻辑回归和朴素贝叶斯)来构造具有最高F 度量的分类器。并使用Firefox 项目中的580 个软件安全漏洞来评估分类的有效性。Shuai Bo 等人将基于LDA 的SVM 多分类器[5]用于漏洞分类领域,实验结果表明SVM 分类方法在漏洞分类方面取得了较好的效果。Dumidu Wijayasekara 等人证明了朴素贝叶斯分类器根据漏洞的描述信息对漏洞进行分类的可行性[6]。Marian Gawron 等人在相同的数据集中,用朴素贝叶斯算法和简化的人工神经网络算法进行漏洞分类[1]。实验结果表明,在漏洞分类中,人工神经网络算法优于朴素贝叶斯算法。
尽管这些机器学习分类算法在许多领域都取得了令人满意的结果,但是在漏洞分类这一场景下,由于漏洞数据量大、漏洞描述文本简短且生成的词向量空间具有高维和稀疏的特征,导致这些机器学习算法在处理这种高稀疏问题方面不是很有效。而且传统方法大多基于人工提取特征,导致分类准确性不高。近年来,深度学习已在许多领域得到应用,对于自然语言领域也有重要的影响。Hwiyeol 等人将卷积神经网络(CNN)和递归神经网络(RNN)应用于大规模文本分类领域并取得了成功[7]。Wu Fang 等人提出了三种深度学习的漏洞检测模型[8]预测二进制程序的漏洞,分别是卷积神经网络(CNN)、长短期记忆(LSTM)和卷积神经网络长短期记忆(CNNLSTM),实验结果表明,漏洞预测的准确率达到了83.6%,优于传统方法。可以看出,深度学习应用于软件漏洞检测领域,并取得了良好的效果。
因此,为了更好地处理词向量空间的高稀疏性并充分利用深度学习自动提取特征的优势,提出了一种深度学习漏洞自动分类模型(Word2Vec-CNN),旨在于提高漏洞自动分类准确率。
2 模型介绍
2.1 Word2Vec-CNN模型介绍
Word2Vec-CNN 模型框架如图1 所示。基于Word2Vec-CNN 的漏洞描述文本分类模型主要分为4个层面,包括词嵌入层、卷积神经网络层、Max 池化层和全连接Softmax 分类层。①漏洞描述文本通过数据预处理划分为单个词并将单个词送入词嵌入层生成词向量。②构建维度为n×k 的输入矩阵,其中n 为文本句子中单词的数量,k 为每个词的embedding 维度。③输入矩阵进入卷积层与m 个大小不同的卷积核分别做卷积。④在池化层采用max 池化的方式对卷积后的输出结果做池化处理,压缩数据。⑤池化层处理后得到的特征向量进入全连接层,先flattening 扁平化,然后乘以权重求和加偏置,激活函数处理,梯度下降优化权重,Softmax 输出分类标签。
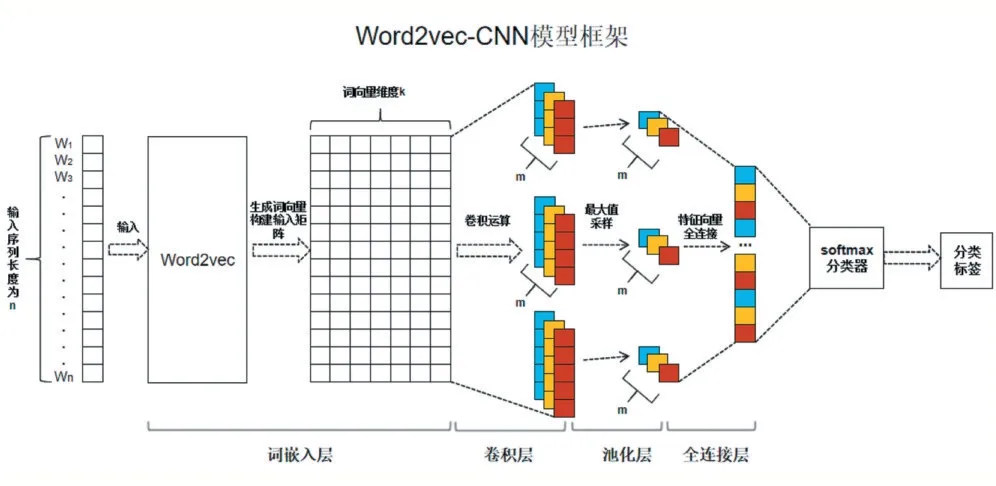
图1 Word2Vec-CNN模型框架图
2.2 数据集
为了验证有效性,使用国际认可的国家漏洞数据库(NVD)[9]作为实验数据。该数据集的源文件是一系列XML 文件,其中包含有关漏洞的全面信息,例如CVE 号、漏洞发布日期、CVSS_version、CVSS_score、CVSS_vector、漏洞文本描述等。NVD 漏洞数据库的年度漏洞数量(2002 年-2019 年6 月)如图2 所示,漏洞记录总数为121164 条。
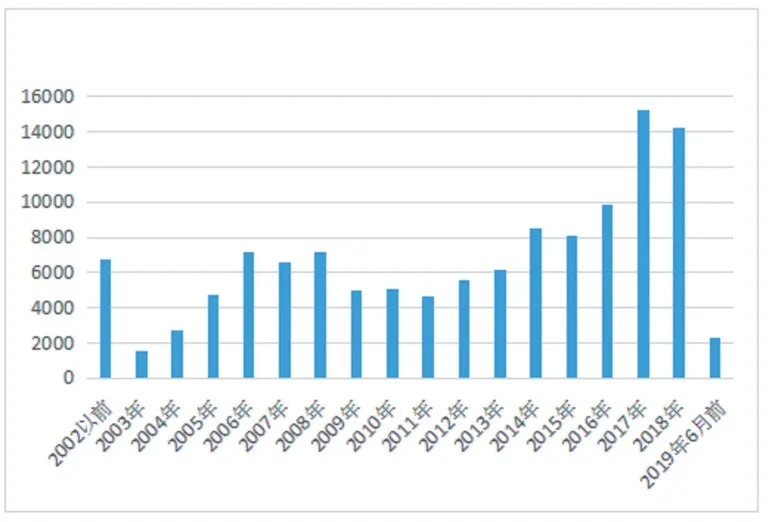
图2 各年的漏洞数量
到2019 年6 月,CVE-Detail 中记录了13 个漏洞类别,大部分漏洞可被标记为多个漏洞类别,如CVE-2012-5835 漏洞被标记为DoS、Exec Code 以及Overflow 三种漏洞类别,被分类为多个漏洞类别的漏洞对于模型训练没有价值,实验中排除存在多个漏洞类别的漏洞。统计剩余漏洞信息,File Inclusion、Memory Corruption、Http Response Splitting 三种类别的漏洞分别只有69、60、163 条,由于数量过少对于深度学习模型训练没有价值,也一并排除。其他10 个漏洞类别的漏洞记录如图3 所示。

图3 各个类别的漏洞数量
从漏洞文件中提取所需的漏洞信息,包括CVE号,漏洞文本描述以及攻击矢量(access-vector)、机密性(confidentiality-impact)、完整性(integrity-impact)和可用性(availability-impact)四个CVSS 指标,以及从CVE-Detail 中提取漏洞类别。其中,机密性、完整性和可用性三种属性均包括NONE、PARTIAL、COMPLETE三种取值作为分类的标签。攻击矢量包括ADJACENT_NETWORK、LOCAL、NETWORK 三种取值作为分类的标签。
2.3 数据预处理
从NVD(National Vulnerability Database,国家漏洞数据库)上获取到的漏洞描述是计算机无法直接识别和计算的文本数据,不能直接放进CNN 卷积神经网络进行处理,需要进行数据的预处理,预处理的过程如下:
(1)分词
分词是指将连贯的漏洞描述的文本信息切分为单个词,将整个漏洞描述的文本信息转化为可以由统计信息计算的最小语义单位。这个过程是漏洞文本预处理的第一步也是最重要的一步。对于用英文单词描述的漏洞信息,单词细分是很简单的。只需要识别整段漏洞描述文本间的空格或标点来划分单词。例如CVE-2016-6045 漏洞的描述为:"IBM Tivoli Storage Manager Operations Center is vulnerable to cross-site request forgery which could allow an attacker to execute malicious and unauthorized..."分词之后变为["IBM","Tivoli","Storage","Manager","Operations","Center","is","vulnerable","to","cross","-","site","request","forgery","which", "would","allow","an","attacker","to","execute","malicious","and","unauthorized",...]。
(2)数据清洗与小写化
数据清洗是指去除分词后数据中的标点符号以及单个字母,如“%”,“a”。小写化是指对数据清洗后的单词中的大写字母转变为小写,如“Manager”经过小写化后变为“manager”,方便更加准确的对词进行统计,并在此之后生成词汇表。通过对漏洞数据库中的漏洞报告分析,确定漏洞描述的最大长度约为400 个单词,并对长度不够400 个单词的漏洞描述进行补0。
(3)构建单词向量空间
词向量又称为词嵌入,是自然语言处理中语言建模和特征学习的统称,将词汇表中的词映射为实数域上的向量,以便计算机进行处理和建模。Word2Vec[10]是一个多层的神经网络,可以将词向量化。在Word2Vec 中存在两个模型CBOW 模型和Skip-gram模型,第一个模型的作用是已知当前词Wt 的前后单词(Wt-2,Wt-1,Wt+1,Wt+2)来预测当前词,第二个模型的作用是根据当前词Wt 来预测上下文(Wt-2,Wt-1,Wt+1,Wt+2)。两种模型都包含输入层,投影层,输出层如图4 所示。由于漏洞描述信息复杂多变,生僻词较多,而Skip-gram 模型比起CBOW 模型准确率更高[10],更能准确处理生僻词。因此,选择Word2Vec 中的Skipgram 模型来构建词向量。经过反复的实验,Word2Vec参数设置如下时效果最好,特征向量100 维,窗口大小为5,训练并行数为6。

图4 Word2Vec两种模型
2.4 卷积神经网络
CNN(卷积神经网络)[11]最早应用于图像识别[12]的领域中,将一张图像看作是一个个像素值组成的矩阵,那么对图像的分析就是对矩阵的数字进行分析,通过对矩阵做卷积运算,从而得到图像中的特征。CNN 最大优势在于网络结构简单,这使得它网络参数数目少,计算量少,训练速度快。之后,CNN 第一次被用于文本分类[13],并取得了不错的效果。基于CNN 的文本分类主要过程如下:
(1)卷积神经网络层将数据预处理后得到的400×100 矩阵作为输入,400 为每条漏洞描述中单词的个数,100 为词向量维度。将输入矩阵与卷积核做卷积得到若干个列数为1 的特征图。由于漏洞描述中每句话的单词数较少,并且采用大小不同的卷积核能更好地提取文本信息中的特征,因此,卷积核窗口设置为3,4,5 三种大小合适,步长为1。
(2)池化层将卷积神经网络层中输出的一维特征图进行采样,提取出最大值。最终池化层的输出为各个特征图的最大值,即一个一维的向量。Max 池化操作能减少文本矩阵补零操作噪声影响,实验得出的效果更好。
(3)最后一层采用全连接的方式,对池化后得到的文本特征向量进行全连接后,送入Softmax 分类器,用来预测类别概率。
2.5 深度学习模型基线
One-hot[14]又称为热独编码,用于单词的向量化。近年来,One-hot 被广泛应用于文本分类领域中数据的预处理。因此,选择One-hot 作为构建词向量的基线方法。采用字符级One-hot 编码的方式,即维度为1×n 的向量,向量所有位置上都是0,只有在对应字符的索引位置上是1,其中n 为字符表中所有字符的数量。如字符”b”索引位置为2,则对应的one-hot 码为[0 0 1 0...]。
RNN 循环神经网络[15]近年来被广泛用于构建文本分类器,因此,选择RNN 循环神经网络作为分类器的基线方法。最终组合出三种基线模型,即One-hot-CNN、One-hot-RNN、Word2Vec-RNN。
3 实验及结果分析
3.1 环境
实验是在PC 上进行的,处理器为Intel E3-1230 V5,3.40 GHz 和8.00 GB。
内存,运行Windows 7 操作系统。编程使用PyCharm 2017 和TensorFlow 框架。
3.2 神经网络参数设定
CNN 参数设定如下:
(1)卷积核设为3,4,5 三个大小,每个大小的卷积核数量设为128,每个卷积核步长设为1。
(2)输入层的正向传播和隐藏层使用ReLU 作为激活函数,而输出层使用Softmax 作为激活函数。
(3)使用TensorFlow 中的dropout 功能来防止过度拟合,dropout 值设为0.5。
(4)使用批量梯度下降优化CNN 模型,批量大小设置为128,学习率设置为1e-3。
(5)训练轮数epoch 设置为20。
3.3 实验数据集
收集2000 年至2019 年6 月NVD 上所有漏洞的文本信息以进行统计,对于单个CVSS 属性(Confidentiality、Integrity、Availability 以及Access)的分类,分别选择其中20000 个作为训练集,2000 个作为验证集,2000个作为测试集。对于漏洞类别的分类,选择其中40,000 个作为训练集,并使用5000 个作为验证集,5000个作为测试集。具体的数据样本列于表1。

表1 数据样本
3.4 实验评估
(1)评估指标
为了评估所提出的漏洞自动分类模型(Word2Vec-CNN)的性能并比较不同算法之间的性能,需要统一的评估标准。采用多类混淆矩阵来评估模型分类性能,如表2 所示。
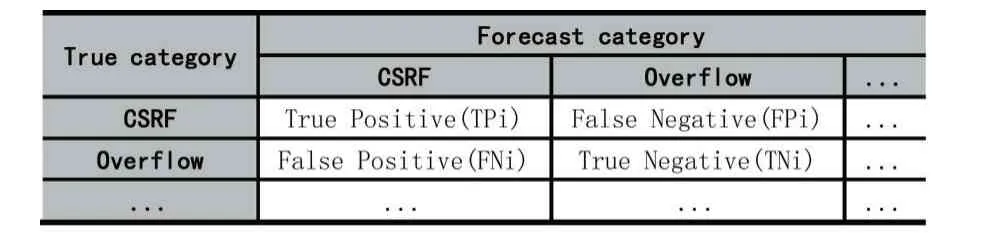
表2 混淆矩阵
其中i 代表漏洞的类别。根据混淆矩阵的准确性、召回率、准确率和F1 得分用作评估指标TFI-DNN 模型。每个指标的计算公式如下。
Accuracy(i):表示测试次数的比率实例按漏洞i 正确分类到总数中测试实例数。计算公式如下:

Recall(i):表示正数的比例按漏洞正确分类的示例到数字实际的正面例子。计算公式如下:
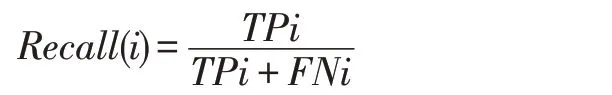
Precision(i):代表正数的比例按漏洞正确分类的示例到数字实例被归类为积极实例。计算公式如下:

F1-score(i):结合了召回率和准确率。计算公式如下:

F1 分数的值介于0 到1 之间,并且数值越高,漏洞分类模型的性能越好。
(2)单个CVSS 属性分类的比较结果
机密性、可用性、完整性以及攻击矢量的比较结果如表3 所示。
比较结果中,可以看到,在机密性(Confidentiality)、可用性(Availability)、完整性(Integrity)三个属性的分类中,Word2Vec-CNN 测试精度比传统的神经网络算法分别高出1.9%、1.3%、4.3%。对于攻击矢量(Access)属性则比神经网络算法低1.2%,由于Access 属性相比于其他三个属性的特征更易提取和识别,因此,机器学习算法在Access 属性的分类上优于深度学习算法,这个结果是合理的。从四个CVSS 属性的分类结果中可以看出,Word2Vec-CNN 模型的分类效果均高于其他三个基线深度学习模型。

表3 单个CVSS 属性的分类准确率
(3)漏洞类别分类的比较结果
将提出的Word2Vec-CNN 模型与三个基线深度学习模型在漏洞类别的分类上进行了比较。比较结果如表4 所示。
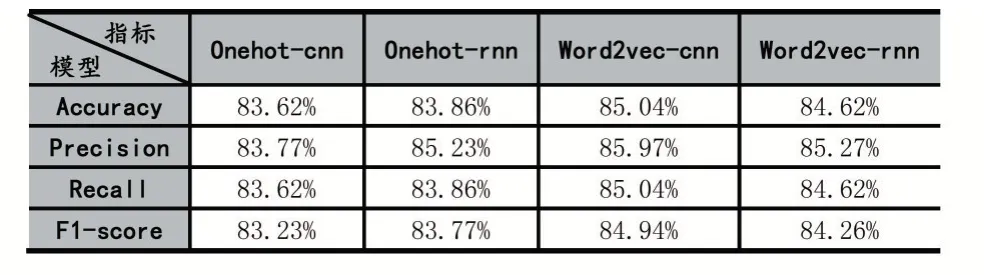
表4 漏洞类别分类结果
根据实验比较结果,可以看到,Word2Vec 漏洞的整体性能优于其他三种模型。具体而言,与One-hot-CNN、One-hot-RNN 和 Word2Vec-RNN 相 比,Word2Vec-CNN 模型分类准确度分别高1.4%、1.2%和0.4%,F1 评分指标分别高1.7%、1.2%和0.7%。以上实验结果验证了Word2Vec-CNN 在漏洞自动分类中的有效性。同时,Word2Vec-RNN 模型的分类效果接近Word2Vec-CNN 模型,比One-hot-CNN 模型与Onehot-RNN 模型的分类效果更好。
取得以上效果的原因,可以归纳为以下2 点:①由于One-hot 生成向量空间并不全面,没有考虑到上下文词语间的关系,而Word2Vec 则是根据上下文的词向量来生成当前词向量,这样更好地保留了上下文语义间的关系,使得Word2Vec 的模型在实验中表现更好。②由于RNN 模型的复杂性,在处理长序列时容易出现梯度爆炸问题,在模型训练的过程中,RNN 循环神经网络模型比起CNN 卷积神经网络模型更难训练,所消耗的时间更长。因此,提出的Word2Vec-CNN 模型在漏洞类别分类的过程中取得的效果更好。
4 结语
为了根据漏洞的所属类别以及单个漏洞属性更好地分析和管理漏洞,提高系统的安全性能,降低系统被攻击和损坏的风险,将深度神经网络应用于软件漏洞的分类,提出了一种漏洞自动分类模型(Word2Vec-CNN),并详细讨论了Word2Vec 和CNN 的构建过程。用NVD 上的数据集比较了Word2Vec-CNN 模型与三个基线深度学习模型(One-hot-CNN、One-hot-RNN 和Word2Vec-RNN)和传统的机器学习算法(神经网络、贝叶斯算法)在单个漏洞属性上的分类效果,接着比较了Word2Vec-CNN 模型与三个基线深度学习模型在漏洞类别上的分类效果。在这两方面的综合评价指标上,Word2Vec-CNN 模型取得的效果更好,展示了Word2Vec-CNN 在漏洞分类中的有效性。
猜你喜欢
今日农业(2022年13期)2022-09-15
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
阅读(低年级)(2018年2期)2018-05-14
儿童时代(2016年6期)2016-09-14
微型计算机(2009年4期)2009-12-23
