
基于高光谱的套袋和不套袋苹果糖度无损预测模型研究
2020-07-06 02:48王风云郑纪业阮怀军袁旭林
山东农业科学 2020年6期
王风云,郑纪业,阮怀军,袁旭林
(1.山东省农业科学院科技信息研究所,山东 济南 250100;2.山东大学控制科学与工程学院,山东 济南 250061)
一直以来,苹果都是人们喜爱的水果,市场需求量大。人们对于苹果质量的评价指标有糖度、酸度、单果重以及果实着色等,其中糖度是判断苹果品质好坏的一个重要指标。传统的糖度检测方法过程繁琐,费时费力且具破坏性;高光谱技术是一项快速、不具破坏性的检测技术,是目前无损检测的最佳手段[1]。
20世纪80年代后,苹果市场的竞争日趋激烈,消费者对水果品质的要求越来越高,苹果套袋就此悄然兴起。苹果套袋的作用先期是为了预防病虫害,后期则以促进果实着色为主,减轻果锈,还可以提高果实硬度,从而提高苹果商品率,达到提高经济效益的目的[2,3]。
目前基于高光谱技术的苹果糖度无损检测建模流程为:数据预处理→异常样本剔除→样本划分→特征提取→回归模型的建立。①在光谱采集过程中,除了采集到目标样品的光谱之外,还存在着大量的噪声信号,如周围环境的杂散光、仪器本身的电噪声等,因此,在建模之前对光谱进行预处理是十分必要的。常用的数据预处理方法有标准正态变量变换(standard normal variable transformation,SNV)、求导[4]、基线校正[5,6]、多元散射校正[7]、均值中心化、SG多项式平滑[8]以及小波变换[9]等。②一般情况下,异常样品是由操作失误或者采集高光谱时仪器状态异常等因素造成的,这在实际样品测试时通常难以避免,但异常样本的存在会严重降低模型对未知样品的预测精准度,因此,需在前期将其剔除。目前对于光谱数据异常点剔除的常用方法有模糊C均值聚类[10]、马氏距离法[11]和蒙特卡洛交叉验证算法(Monte-Carlo cross-validation,MCCV)[12]等。③数据集的恰当划分有利于提高模型对未知样本的预测精度,对样本校正集和测试集的划分方法有随机采样法、均匀采样法和K-S法[13]等。④高光谱数据有多达成百上千的波段,维度高且波段间的相关性较高,导致数据具有较高的冗余度,直接建模不仅精度不够,而且计算量大大增加,因此需要对数据进行特征提取,常用的特征提取方法有主成分分析(principal component analysis,PCA)[14]、连续投 影 算 法[15,16]、禁 忌 搜 索 算 法[17]、遗 传 算法[18]、人工蜂群算法[19]、粒子群算法[20,21]、蚁群算法(ant colony optimization,ACO)[22-24]等。⑤关于苹果糖度与光谱的回归模型,国内外学者已取得了一些成果,2016年,Nascimento等利用偏最小二乘(partial least squares,PLS)回归建立了低温桃的可溶性固形物含量和硬度预测模型[25];2017年,刘燕德等利用最小二乘支持向量机建立了梨与苹果糖度的通用数学模型[26];2018年,温馨设计了一种基于深度学习的水果糖度回归模型,提出了一种新的检测算法[27];李盛芳使用随机森林对多种水果光谱建模[28]。
目前关于苹果糖度无损检测的研究并没有区分套袋与不套袋苹果,考虑到套袋会对苹果的外在和内在品质产生一定影响,那么对其高光谱图像也会产生一定的影响,如果对苹果套袋与否不加区分,直接建立统一模型进行无损检测,模型精度势必会受到影响,因此,探究分别适用于套袋和不套袋苹果的无损检测模型十分必要。本研究以烟台栖霞生产基地的套袋和不套袋红富士苹果为对象,以糖度为测试指标,分别建立全光谱反向传播神经网络模型(FS-BP)、全光谱偏最小二乘模型(FS-PLS)、主成分分析反向传播神经网络模型(PCA-BP)、主成分分析偏最小二乘模型(PCA-PLS)、蚁群算法反向传播神经网络模型(ACO-BP)、蚁群算法偏最小二乘模型(ACOPLS),并对这六种模型的糖度预测精度进行对比分析,以期找出分别适用于套袋和不套袋苹果的最优糖度预测模型。
1 材料与方法
1.1 试验材料
从烟台栖霞生产基地选取形状大小相似且无机械损伤的套袋红富士苹果134个,不套袋红富士苹果105个,对苹果表面进行清水清洗,再静置2 h达到室温状态后,进行高光谱图像采集。
1.2 设备和仪器
1.2.1 高光谱成像系统 采用美国ASD公司设计制造的FieldSpec Hand-Held便携式地物光谱仪,其主要部件包括光源、光谱相机以及采集数据的软件。主要技术参数如下:波长范围325~1 075 nm,光谱分辨率<3.0 nm@700 nm,波长精度±1 nm,积分时间最小为8.5 ms,等效辐射噪声为5×10-9W/(cm2·nm·sr)@700 nm,视场角为25°,可存储多达2 000个光谱数据。为了避免光照对数据采集的影响,保证目标样本光照的均匀性,将整个图像采集系统置于暗箱中运行。
1.2.2 糖度计 选用杭州陆恒生物科技有限公司生产的LH-B55数显糖度计。该糖度计的量程为0~55%,分辨率为0.1%,精度为±0.2%,可以快速测定含糖溶液的糖浓度和折射率。
1.3 数据采集
1.3.1 高光谱数据采集 在苹果赤道位置选取4个分布均匀、直径为150像素的圆形区域作为感兴趣区(region of interest,ROI)。对每个ROI进行5次高光谱采样,取5次平均作为每个ROI的高光谱数据。共采得239个苹果的956条光谱样本。
1.3.2 苹果糖度测量 完成高光谱图像采集后,分别从每个苹果的每个ROI挖取边长为15 mm的立方体果肉,分别榨汁后用吸管吸取一定量汁液到数字折光仪(LH-B55)的棱镜上读取糖度数据,每个苹果得到4个糖度值(以下称为光谱糖度值)。最后将该苹果4个ROI的果汁充分混合,用糖度计测量混合果汁的糖度,作为该苹果的实际糖度值(以下称为苹果糖度值)。
1.4 数据处理与建模
高光谱数据处理基于软件平台Microsoft Excel 2013、Matlab 2014a进行。
1.4.1 光谱预处理 由图1可以观察到采集到的原始光谱图像比较分散,并且在波段的初始位置和末端位置,光谱曲线抖动严重,存在大量噪声,这是由采集反射光谱的硅光电二极管的特性决定的,光谱仪和其它许多仪器一样,量程中间精度好,两端差。为了减小噪声对结果的影响,本研究中去除了起始位置325~441 nm波段和末尾位置941~1 075 nm波段的光谱数据,只保留441~940 nm波段的数据进行研究。
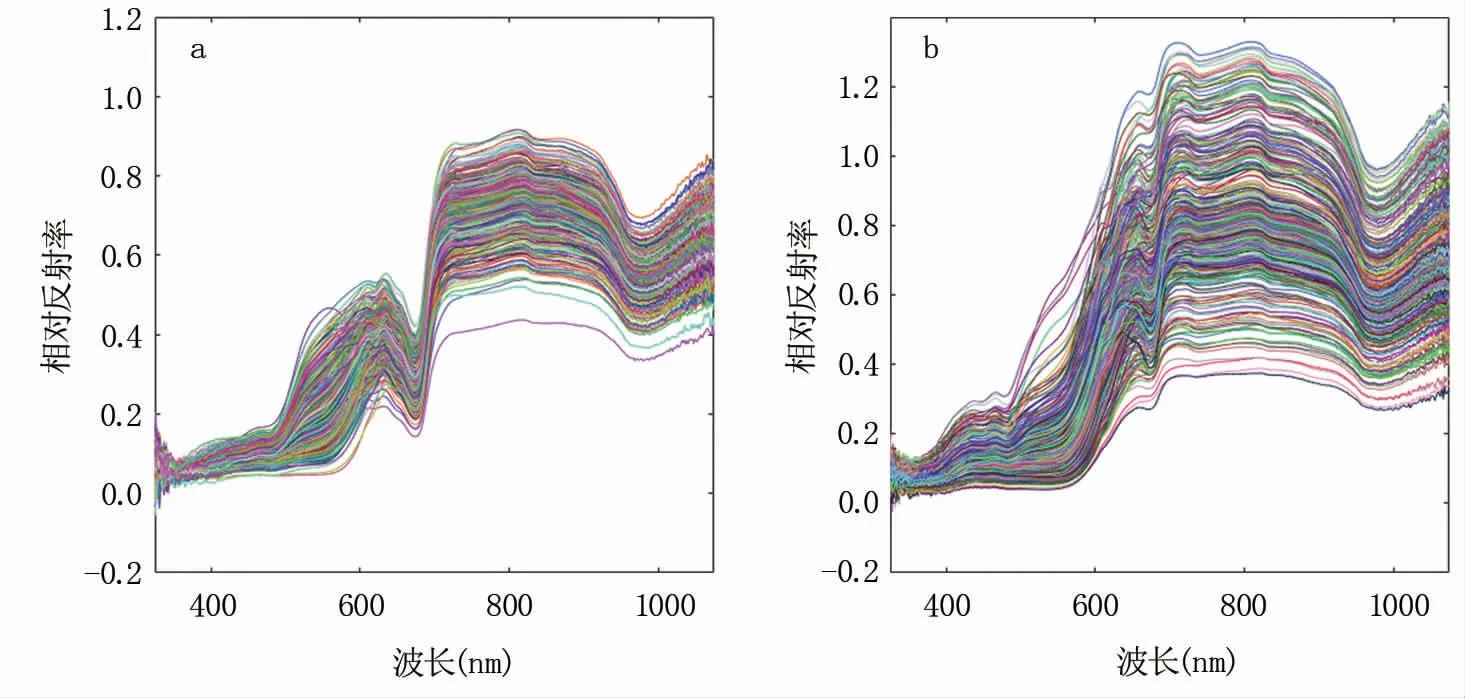
图1 不套袋(a)和套袋苹果(b)原始光谱
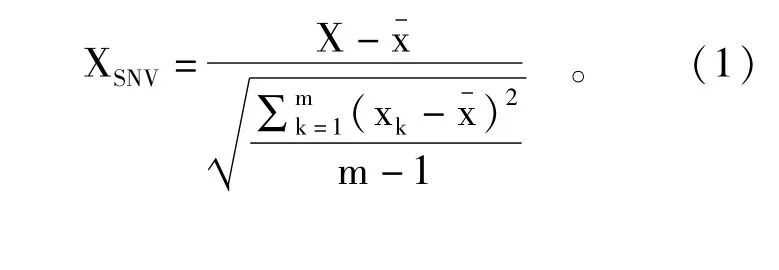
图2(a)为预处理后的不套袋苹果光谱,图2(b)为预处理后的套袋苹果光谱,可以看到光谱反射曲线都向中心点聚拢;不套袋苹果在630~700 nm的反射率在-1.5~0之间,而套袋苹果在630~700 nm的反射率在-0.5~1.0之间,明显高于不套袋苹果,说明套袋对苹果的高光谱图像产生了一定程度的影响。
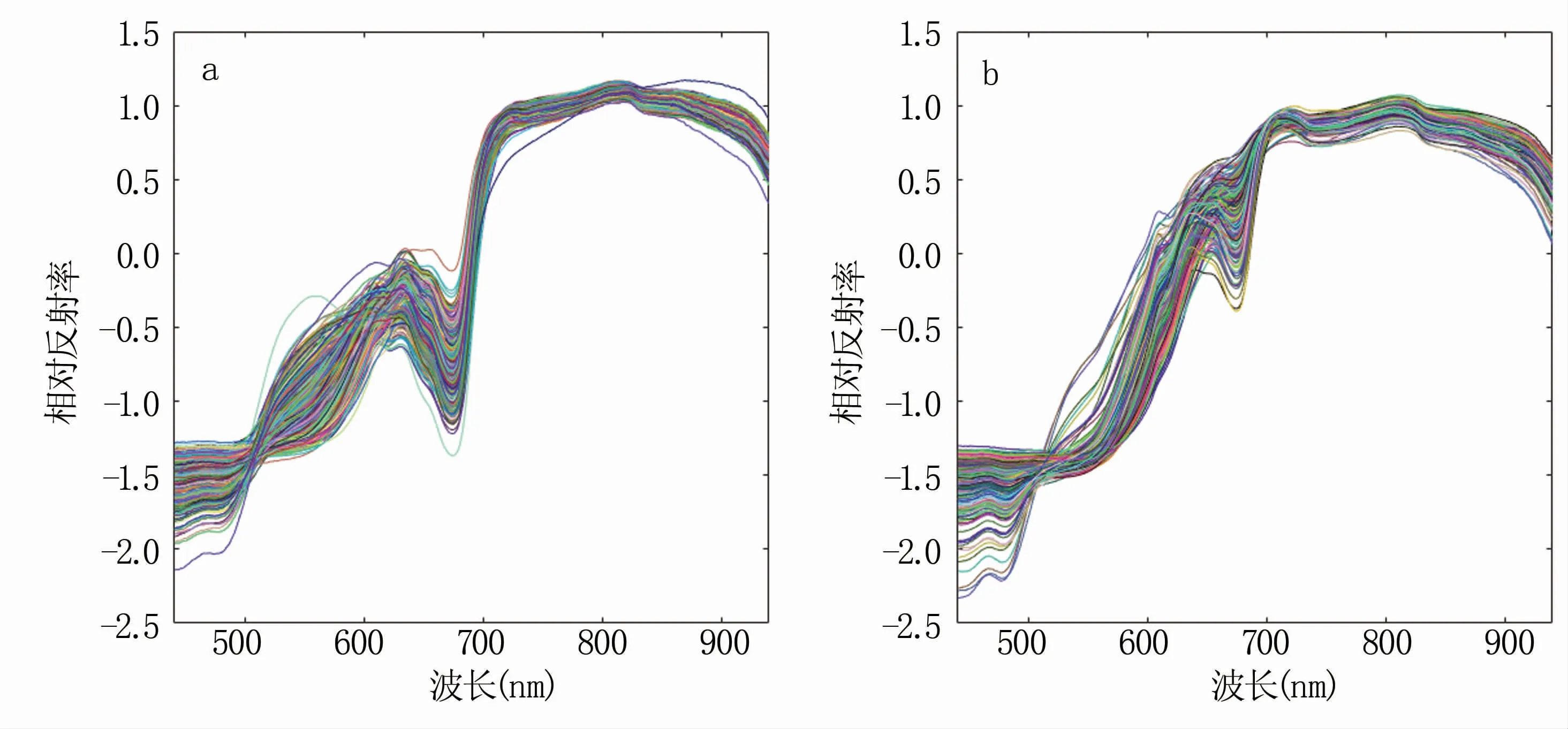
图2 预处理后的不套袋(a)和套袋(b)苹果光谱
1.4.2 异常样本剔除和样本集划分 MCCV异常样本筛选法能够在一定程度上降低由掩蔽效应带来的风险,有效检测出光谱阵和性质阵方向的奇异点,与传统方法相比具有较高的识别奇异样本的能力[29]。本研究运用MCCV法剔除了不套袋苹果异常样本4个,套袋苹果异常样本8个。
将每个苹果作为一个样本,可以获得4个光谱糖度值和1个苹果糖度值。对样本校正集和测试集的划分方法如下:首先按苹果糖度值排序,去除糖度值最高和最低的样本,然后通过均匀采样法挑选出测试集的n个样本(套袋和不套袋苹果样本都取20个),其余的作为训练集样本。各数据集描述性统计见表1。
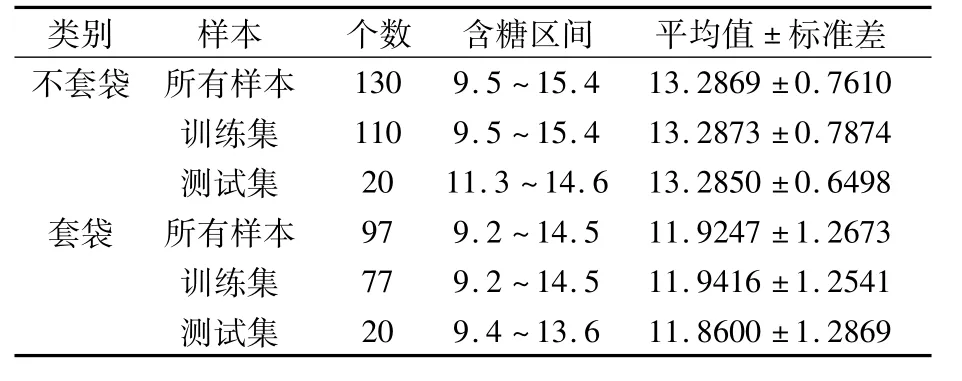
表1 各数据集含糖量描述性统计 (%)
1.4.3 特征提取 采用PCA和ACO法对光谱数据进行特征提取和特征选择以降维。PCA是一种使用广泛的数据降维算法。其主要思想是将n维特征映射到k维上,k维全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的。将其应用在高光谱数据的特征提取上,是将存在高相关性的原始高光谱数据用尽可能少的主成分来表示。
ACO是一种用来寻找优化路径的概率型算法,具有分布式计算、信息正反馈和启发式搜索的特征,本质上是进化算法中的一种启发式全局优化算法,蚁群算法用在波长特征筛选时,是对高光谱的特征波段进行筛选[30]。
1.4.4 模型建立 在完成特征提取后,利用PLS回归和反向传播神经网络(back propagation artificial neural network,BP-ANN)两种方法来建立光谱数据与糖度之间的回归模型。
PLS回归是一种多元线性回归方法,集成了线性回归分析、主成分分析和典型相关分析的优点。它提供一种多对多线性回归建模的方法,适用于样本个数较少且自变量之间存在多重相关性的情况,目前该方法在光谱的定量分析中应用最为广泛。
BP-ANN是一种非线性回归方法,是由大量数据按一定的结构相互连接而形成的复杂网络,是一种按误差反向传播训练的多层前馈网络。基本思想是梯度下降法,利用梯度搜索技术,使网络的糖度输出值和实际测量的糖度值的均方误差最小。所建立的BP-ANN结构为一个三层神经网络,如图3所示。本研究中神经网络隐含层神经元个数设置为9。
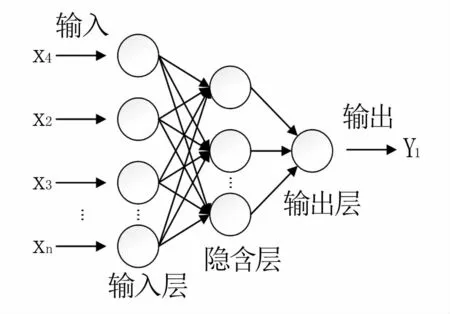
图3 BP神经网络示意图
通过线性和非线性方法建立苹果糖度预测的回归模型,模型精度的高低由测试集的糖度预测值与实际值的相关系数(R)和均方根误差(RMSE)来判定,训练集的R和RMSE作为辅助判定指标。测试集的R值越高且RMSE越小,表示模型的性能越好,同时应使训练集的R值尽可能高且RMSE尽可能小。
由于一个苹果对应4条高光谱数据、4个光谱糖度值,通过建立的高光谱数据与光谱糖度值之间的模型,可求得4个预测光谱糖度值,对其取平均作为该苹果的预测光谱糖度值,求取该值与苹果实际糖度值的相关系数和均方根误差,对模型的精度进行检验。
2 结果与分析
2.1 光谱数据降维
2.1.1 基于PCA的特征提取 将n维高光谱数据转换到k个特征向量对应的新空间中,由于在后面建模用到的PLS算法还需要对数据提取因子,因此设定k=90,即将原始的500维数据预降维到90维,结果表明,90维主成分的累计贡献率超过了99.99%,能全面表征高光谱数据的原始信息。
2.1.2 基于ACO的特征波段选择 设定最大迭代次数为200,蚁群大小为30,选取的波段数为60,更新信息素时的显著因子为0.1,挥发系数为0.65,信息素权重矩阵全部初始化为1。基于ACO的特征波段选择得到的预测光谱糖度值与实际光谱糖度值的RMSE变化曲线和高光谱特征波段如图4所示。可以看出,套袋和不套袋苹果的RMSE随着迭代次数的增加不断下降,最终趋于平缓,算法收敛,得到最小RMSE的波段组合;不套袋苹果特征波段分布比较均匀,而套袋苹果特征波段主要集中在700~880 nm,两者间存在一定的差异。
2.2 模型建立
经上述处理,原始光谱数据的500个波段经PCA提取了90维特征,经ACO选择了60个波段,然后对每一种特征提取方法分别建立PLS回归模型和BP-ANN回归模型,并建立全光谱的PLS回归模型和BP-ANN回归模型作为对照。本研究中,对套袋和不套袋苹果分别建立FSBP、FS-PLS、PCA-BP、PCA-PLS、ACO-BP、ACO-PLS模型,将训练集和测试集光谱代入模型,求得训练集和测试集预测苹果糖度值和实际苹果糖度值的R和RMSE。
从表2可以看出,对于不套袋苹果,ACOPLS模型的预测精度最高,其测试集R为0.9279,比对照组FS-PLS模型高0.0244;RMSE为0.3247,比对照组FS-PLS模型低0.1009;同时训练集的R和RMSE也是6种模型中最优。
对套袋苹果,同样是ACO-PLS模型的预测精度最高,其测试集R为0.9602,比FS-PLS模型高0.0476;RMSE为0.3146,比FS-PLS模型低0.1675,精度提升效果显著;同时训练集的R和RMSE也是6种模型中最优。
基于PCA特征提取方法建立的模型其精度与基于全光谱建立的模型精度相当,而基于ACO特征波段选择方法建立的模型精度均优于两者,说明ACO法能更好地提取出对苹果糖度影响大的特征波段用于建模,不仅大大减少计算量,加快运算速度,而且提高了预测精度,能够满足苹果品质分级系统的实时检测需求。
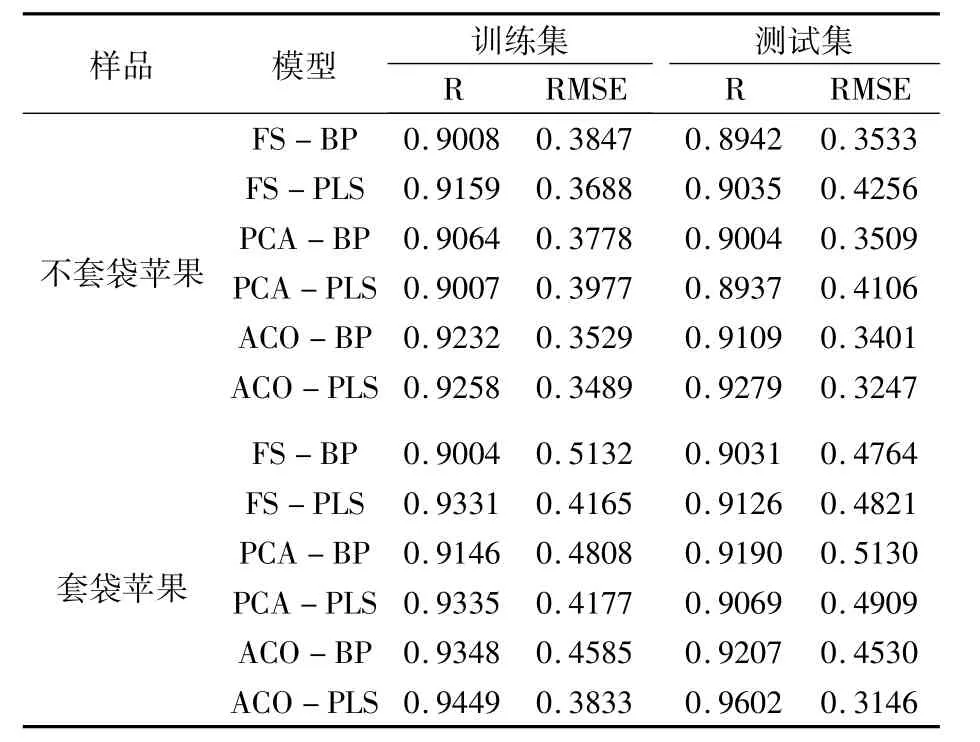
表2 套袋和不套袋苹果糖度的六种模型预测结果
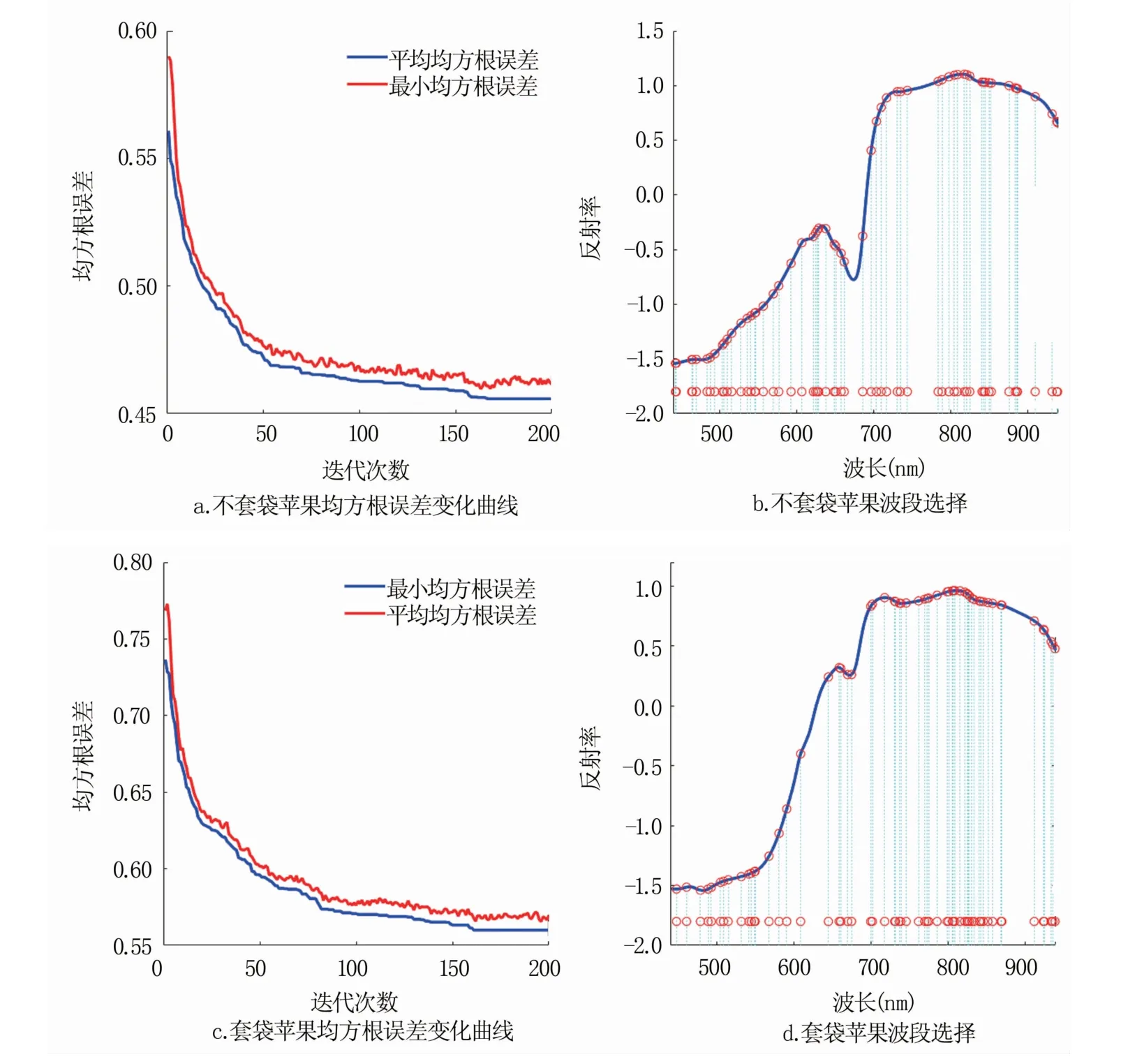
图4 基于ACO算法的RMSE变化曲线和波段选择
尽管套袋和不套袋苹果的光谱曲线和特征波段存在明显差异,但建立的最优模型均为ACOPLS模型,只是测试精度上存在一定差异。利用该模型对套袋和不套袋苹果的训练集和测试集苹果糖度进行预测,结果见图5、图6。可以看出,不套袋苹果利用ACO-PLS模型的糖度预测值与实际糖度值相关性达到0.92,套袋苹果的超过0.94,ACO-PLS模型为套袋和不套袋苹果糖度预测的最优模型。
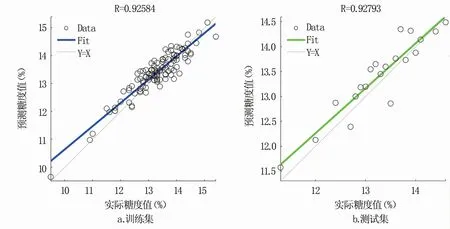
图5 基于ACO-PLS模型的不套袋苹果训练集和测试集预测糖度值与实际糖度值的相关系数
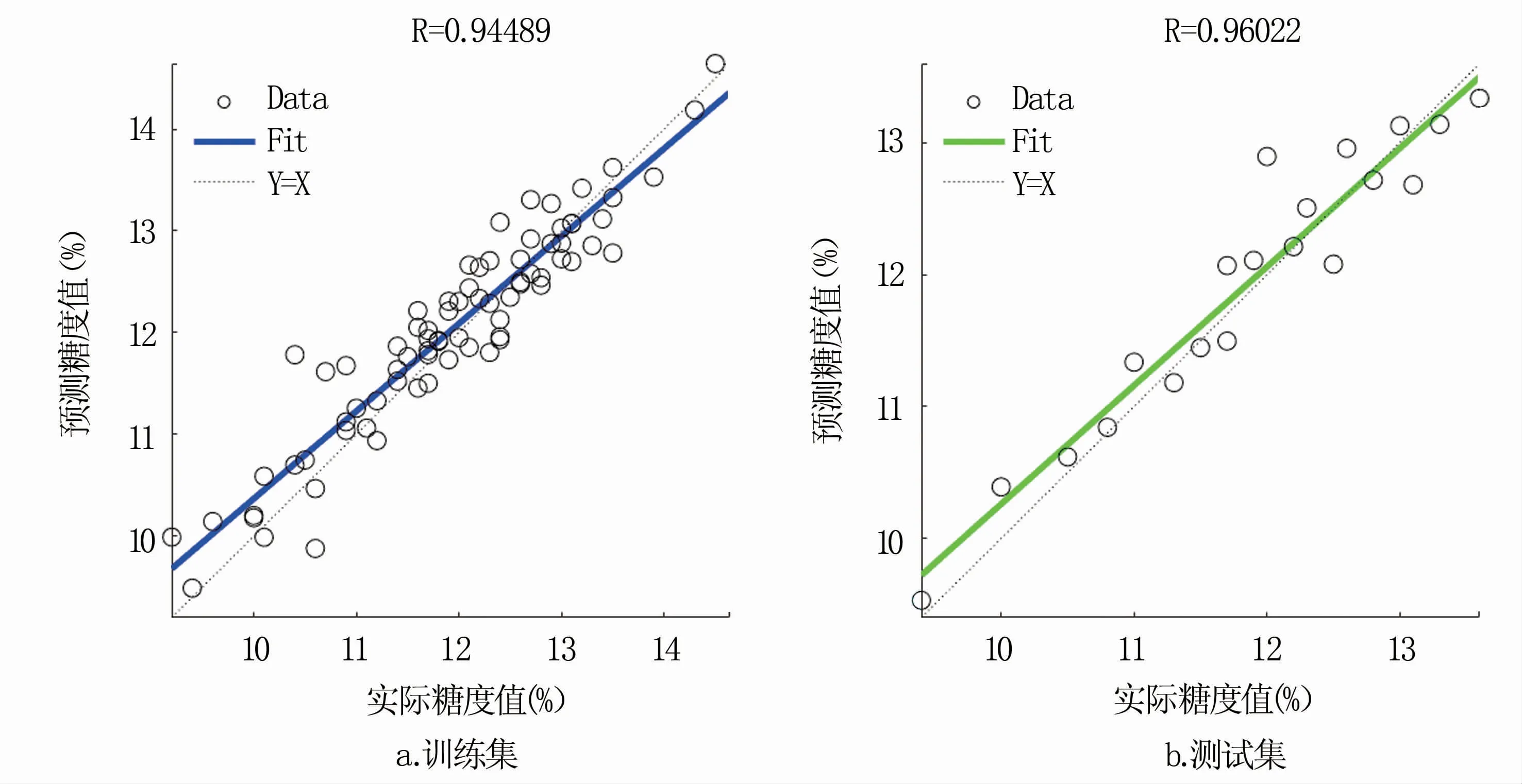
图6 基于ACO-PLS模型的套袋苹果训练集和测试集预测糖度值与实际糖度值的相关系数
3 结论
在采集套袋和不套袋苹果赤道部分的高光谱及其对应糖度后,对原始数据进行SNV预处理,之后利用MCCV算法剔除异常样本,经PCA算法和ACO算法分别进行特征提取和特征波段选择,分别提取了90维主成分和60个波段,然后分别建立FS-BP、FS-PLS、PCA-BP、PCA-PLS、ACO-BP、ACO-PLS六种模型,并对模型的预测精度进行比较,结果表明,无论对于套袋苹果还是不套袋苹果,ACO-PLS模型训练集和测试集的相关系数和均方根误差均表现最优,模型精度最高。本研究建立了分别适用于套袋和不套袋苹果糖度的无损检测模型,可为高精度苹果品质分级系统的建立提供参考。
猜你喜欢
今日农业(2022年15期)2022-09-20
热带作物学报(2022年8期)2022-09-16
今日农业(2022年13期)2022-09-15
航天返回与遥感(2022年2期)2022-05-12
波谱学杂志(2022年1期)2022-03-15
中国果业信息(2021年6期)2021-12-02
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
电脑迷(2020年5期)2020-06-09
制导与引信(2017年3期)2017-11-02
安徽农学通报(2016年21期)2016-12-22
