
数据挖掘中三种典型聚类算法的分析比较
2020-07-04 02:15李煜堃
电脑知识与技术 2020年15期
李煜堃
摘要:大数据时代从大量无序的数据中发现隐含的、有效的、有价值的、可理解的模式变得越发重要。在此背景下,以数据挖掘众多算法中的聚类算法为切人点,选取三种典型的聚类算法——K-means算法、AGNES算法、DBSCAN算法,进行可视化聚类结果和FMI值比较分析,归纳出DBSCAN算法可以发现任意形状的簇类,AGNES算法和K-Means算法在中小型数据集中挖掘得到球形簇的效果较好。
關键词:聚类;K-means算法;AGNES算法;DBSCAN算法
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2020)15-0052-05
1引言
聚类是通过发现数据集中数据之间的相关关系,将数据分类到不同的类或簇的过程。聚类并不关心某一类别的信息,其目标是将相似的样本聚在一起,实现同一类对象的相似度尽可的大,而不同类对象之间的相似度尽可能地小。因此,聚类算法只需要知道如何计算样本之间的相似性,就可以对数据进行聚类。
目前聚类的方法很多,根据基本思想的不同,大致可以将聚类算法分为五大类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维度的聚类算法。
选取划分聚类算法中传统的K-means算法、层次聚类算法中具有代表性的AGNES算法以及典型的基于密度的聚类算法DBSCAN等三种算法对不同数据集的聚类效果进行分析,归纳不同聚类算法优缺点。
2算法相关理论
2.1 K-means算法的基本原理及实现步骤
2.1.1 K-means算法的基本原理
K-Means是典型的划分聚类算法,其中K表示的是聚类为k个簇,Means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心,即用每一个类的质心对该簇进行描述。
K-Means算法的原理是对于给定的数据集,按照各数据点之间的距离大小关系,将数据集戈0分为K个簇。目标是实现簇内的点尽可能紧密的连在一起,而让簇间的各点之间的距离尽可能大。在这里,距离是指各点之间的欧式距离。
2.1.2 K-means算法的实现步骤
第一步:在样本数据集中任选k个样本点作为初始的簇心;
第二步:扫描每个样本点,求该样本点到各个簇心之间的距离,选择其中最短距离的簇心,并将样本点归入该簇心所表示的类;
第三步:分别对每个类中的所有样本点求均值,作为新的簇心;
第四步:重复第二步和第三步,直至达到最大迭代次数,或者更新后的簇心与原来的簇心几乎吻合(形成不动点)。
2.2 AGNES算法的基本原理及实现步骤
2.2.1 AGNES算法的基本原理
AGNES算法是具有代表性的层次聚类方法,采用自底向上聚合策略的算法。其思想是最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度有多种不同的计算方法。聚类的合并过程反复进行直到所有对象最终满足簇数目。
2.2.2 AGNES算法的实现步骤
第一步:将每个对象当成一个初始簇;
第二步:
REPEAT
计算任意两个簇的距离,并找到最近的两个簇;
合并两个簇,生成新的簇的集合;
UNTIL终止条件得到满足。
终止条件:
(1)设定一个最小距离阈值d,如果最相近的两个簇间的距离已经超过d,则无须合并,即聚类终止。
(2)限定簇的个数k,当得到的簇的个数已经达到k,则聚类终止。
2.3 DBSCAN算法的基本原理及实现步骤
2.3.1 DBSCAN算法的基本原理
DBSCAN算法是一种基于密度的数据聚类方法,也是较常用的聚类方法。该算法将具有足够密度的区域划分为簇,不断生长该区域。其基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。
DBSCAN算法利用基于密度的聚类的概念,要求聚类空间中一定区域内(eps范围内)所包含对象(点或其他空间对象)的数目不小于某一给定阈值(MinPts)。该算法能够在具有噪声的空间数据集中发现任意形状的簇,并且可将密度足够大的相邻区域连接,从而对异常数据实现有效处理。其中,最重要的两个参数为:扫描半径(eps)和最小包含点数(MinPts)。
2.3.2 DBSCAN算法的实现步骤
第一步:DBSCAN通过检查数据集中各个点的eps邻域来搜索簇,如果点p的eps邻域包含的点多于MinPts个,则创建一个以p为核心对象的簇;
第二步:DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,该过程可能涉及一些密度可达簇的合并;
第三步:重复第一步和第二步,直到没有新的点添加到任何簇时,该过程结束。
3三种典型聚类算法分析方式
3.1分析方式
考虑到针对不同的数据集,上述三种算法聚类得到的效果可能略有差异。选取两种数据集:Iris Data Set和小规模的非凸数据集,对上述三种算法进行简单的比较分析。
为了评估各算法对数据集的聚类效果,采取两种分析方式:一是可视化聚类结果;二是利用FMI值,来分析比较对已有标签数据集的聚类效果。
3.2评估方式
(1)可视化聚类结果:将得到的聚类结果绘制成二维图像,与实际数据集图像比较,大致观察聚类效果。
(2)FMI(Fowlkes-Mallows IndeX):对聚类结果和真实值计算得到的召回率和精确率进行几何平均的结果,取值范围为[0,1],越接近1越好。故通过比较其值是否接近于1,来大致判断聚类效果。
4Iris Data Set比较效果
为了分析比较上述三种算法的差异,选取了经典的数据集Iris Data Set,通过评估三者对数据集的聚类效果,来分析各算法间的优缺点。
4.1IrisDataSet
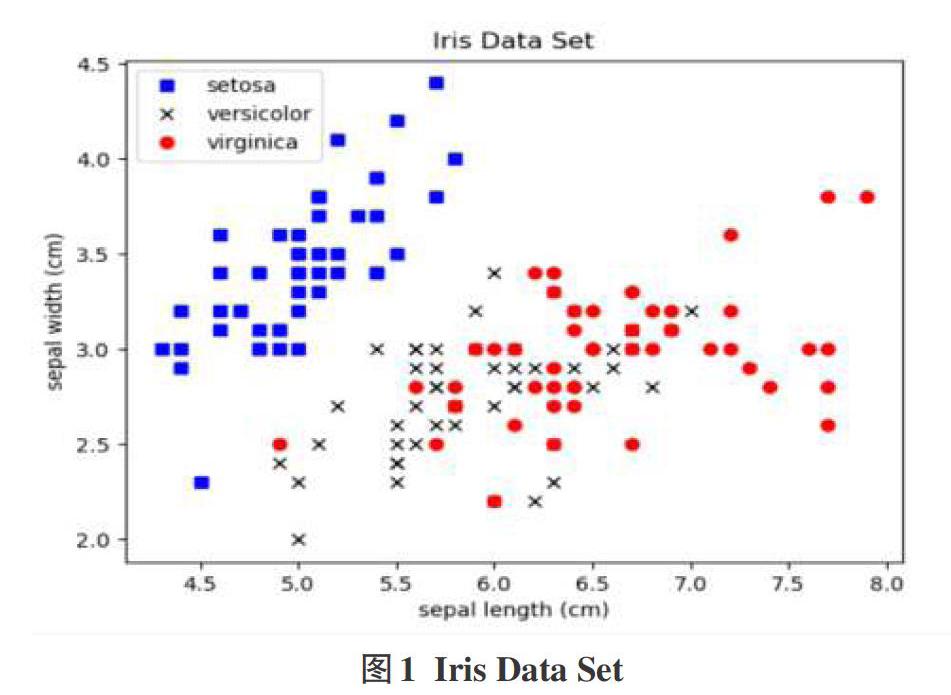
Iris Data Set(鸢尾属植物数据集)是历史比较悠久的数据集,也是聚类分析常用的数据集。它首次出现在著名的英国统计学家和生物學家Ronald Fisher 1936年的论文《The use of mul-tiple measurements in taxonomic problems》中,被用来介绍线性判别式分析。在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类分别收集了50个样本,共包含了150个样本。
该数据集测量了所有150个样本的4个特征,分别是:
(1)sepal length(花萼长度)
(2)sepal width(花萼宽度)
(3)petal length(花瓣长度)
(4)petal width(花瓣宽度)
以上四个特征的单位都是厘米(ca)。
通常使用m表示样本量的大小,n表示每个样本所具有的特征数。因此在该数据集中,m=150,n=4。
利用该数据集4个特征中的前两个f即花萼的长度和宽度),来展示所有的样本点。选取sepallength和sepalwidth为坐标轴来绘制二维图像,如图1所示:
4.2 K-Means算法聚类
利用Python sklearn模块中自带的K-Means聚类模块来对Iris Data Set进行聚类分析。由于已经知道数据集的分类数目(即K值)为3,故我们选取最终划分成的簇数n_clusters的值也为3。以此,选取最佳的K值来得到K-Means中的最佳聚类效果。本文选取sepallength和sepalwidth为坐标轴来绘制二维图像,可视化聚类结果如图2所示:
4.3 AGNES算法聚类
利用Python sklearn模块中自带的Agglomerative Clustering聚类模块来对Iris Data Set进行聚类分析。由于已经知道数据集的分类数目为3,故我们选取最终划分成的簇数n_clusters的值也为3。同时设置参数linkage的值为"waYd”,表示定义类之间的距离为其间的离差平方和。以此,近似得到AGNES中的最佳聚类效果。选取sepal length和sepal width为坐标轴来绘制二维图像,可视化聚类结果如图3所示:
比较实际分类的图1和AGNES聚类得到的图3,可以发现选取n_clusters值为3的AGNES聚类模型,能够得到较符合实际的结果,即取得了较好的聚类效果。
经计算,簇数为3时的AGNES聚类模型的FMI值为0.822170。
4.4 DBSCAN算法聚类
利用Pvthon sklearn模块中自带的DBSCAN聚类模块来对Iris Data Set进行聚类分析。DBSCAN需要两个重要参数:扫描半径(eps)和形成高密度区域所需要的最少点数(MinPts)。MinPts的选取有一个指导性的原则,MinPts≥dim+1,其中dim表示待聚类数据的维度。由于已知数据集中每个样本所
具有的特征数为4,不妨设置MinPts为5。而设置扫描半径eps为默认值0.5。以此,初步观察当前DBSCAN聚类模型的聚类效果。选取sepal length和sepal width为坐标轴来绘制二维图像,可视化聚类结果如图4所示:
观察图4可知:因为DBSCAN算法不需要预先指定聚类的类数,所以最后得到的类数也不确定。而在选取扫描半径eps为0.5H.最少点数MinPts为5时的DBSCAN聚类模型将该数据集聚成了两类,与实际结果并不相符,即聚类效果不理想。
经计算,扫描半径eps为0.5,最少点数MinPts为5时的DB-SCAN聚类模型的FMI值为0.705385。
由于上述所得结果不理想,故简单调整其参数eps和Minpts,得到与之对应的FMI值及相应的聚类类数,得到表1:
选取eps=0.43、Minpts=7时的DBSCAN模型作为近似的DBSCAN算法的最佳聚类效果,如图5所示。
可见,DBSCAN算法对eps及Minpts两个参数极其敏感。在实际聚类的过程中,必须找到最佳的参数值,才能得到良好的聚类效果。否则,两参数值的细微变化将会导致其聚类效果的较大差异。
4.5分析比较
根据三种算法的聚类效果,可以看出针对Iris Data Set,K-Means算法与AGNES算法的聚类结果近似,且优于DBSCAN算法的聚类结果。
其原因是DBSCAN算法很难通过观察来得到合适的参数——扫描半径eps和最少点数Minpts。而上述参数值的细微变化,又会导致聚类结果产生较大差异。故,DBSCAN算法的关键便是找到合适的参数——eps和Minpts。
进一步考虑参数簇数n_clusters的选取,分析其对K-Means模型和AGNES模型的聚类效果的影响程度,通过列出簇数n_clusters与之对应的FMI值表格,来度量其间的影响程度如表2所示:
可见,K-Means算法与AGNES算法虽然也需要明确参数簇数n_clusters,但两者对参数不会像DBSCAN算法那样敏感。此外,在某些领域中,可以通过观察来确定簇数的大致范围。
5小规模非凸数据集比较效果
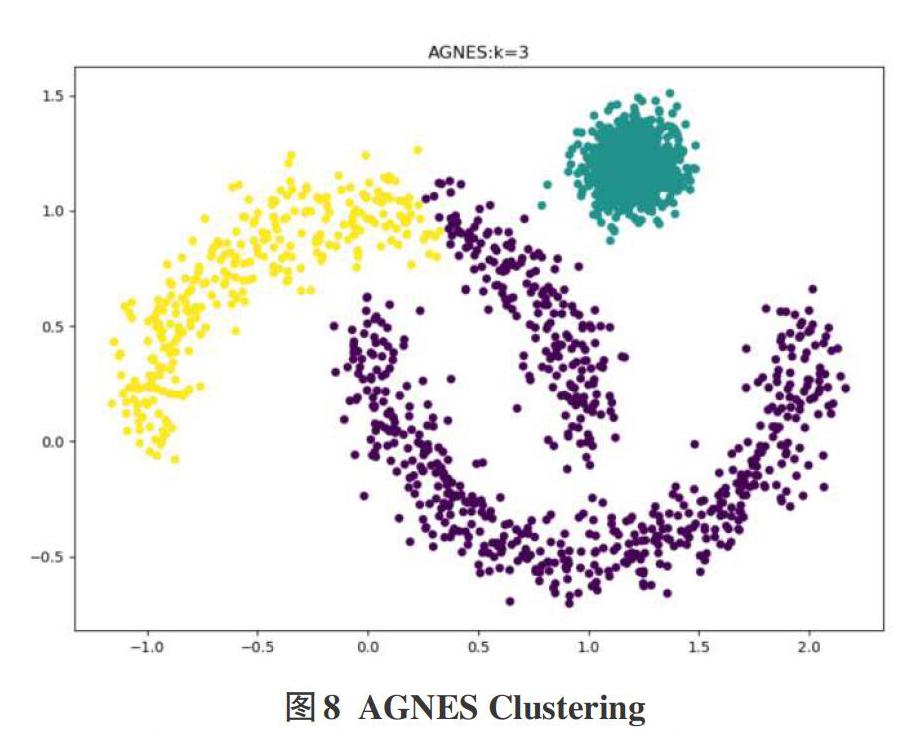
利用Python sklearn模块中自带的make_moons函数和make_blobs函数,加入高斯噪声来生成小规模的非凸数据集,其各样本点分布如图6所示。构造的数据集的样本量大小为2000,每个样本所具有的特征数为2,整体大致分为三类。
5.1 K-Means算法聚类
依据上一部分的发现,k-means依赖于K值的选取。于是选取K值为3,来近似得到K-Means的最佳聚类效果。K-Means模型的聚类效果如图7所示。
可见,K-Means算法对噪声和离群值非常敏感,对非凸区域的鉴别效果不理想。查阅资料可知:
K-Means算法需要数据符合以下三个条件,才能得到较为良好的聚类效果:
(1)数据集中每个变量的方差基本上要保持相同
(2)每一个cluster中每个变量都近似正态分布(或者众数等于中位数的对称分布)
(3)每一个cluster中的元素个数要基本相同
其中,条件1和条件2几乎保证每个cluster看起来像是球形而不是椭球形。上述三个条件,会使K-Means算法倾向于得到大小接近的凸型cluster。故,K-Means算法对非凸数据集的聚类效果不佳。
5.2 AGNES算法聚类
由于已经知道数据集的分类数目为3,故选取最终划分成的簇数n_clusters的值也为3。同时设置参数linkage的值为“ward”,表示定义类之间的距离为其间的离差平方和。以此,近似得到AGNES算法的最佳聚类效果。AGNES模型的聚类效果如图8所示:
可见基于此数据集,AGNES算法的聚类效果略优于K-Means算法,但其对非凸数据集并不能起到很好的聚类效果。
5.3 DBSCAN算法聚类
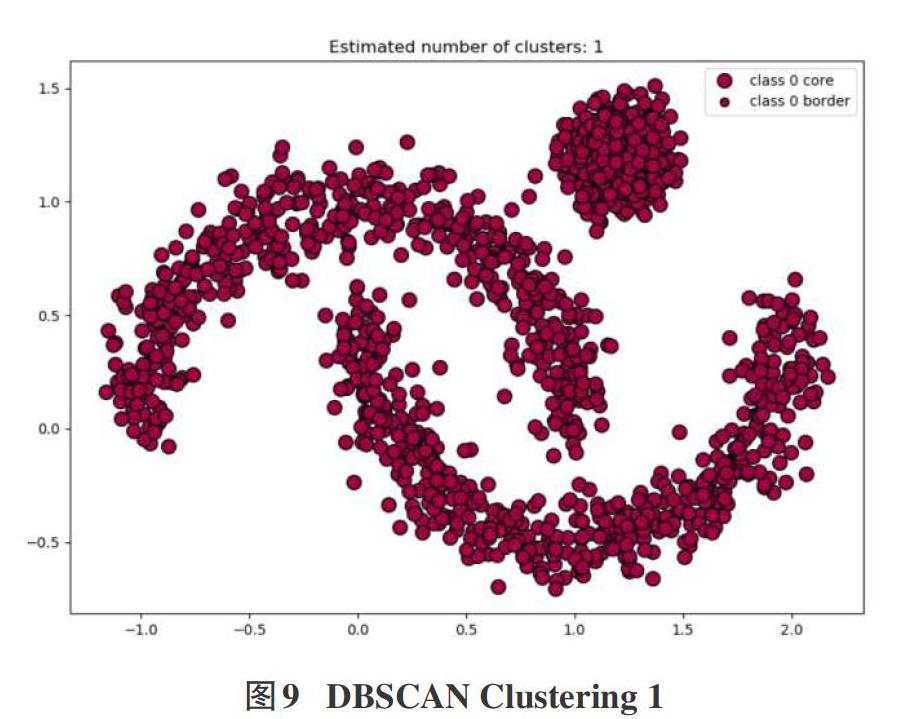
依据上一部分的发现,DBSCAN算法对参数eps和Minpts是较为敏感的。为了获得近似最佳的DBSCAN模型的聚类效果,通过调整两个参数值,以找到最符合实际划分的DBSCAN模型。
当选取eps=0.5,Minpts=5时,整个数据集被聚成了一个大类,如图9所示:
当选取eps=0.1,Minpts=5时,整个数据集被很好地分为三个类别,符合实际观察情况,如图10所示。
可见:DBSCAN算法能够发现任意形状的簇类,无论数据集本身是凸还是非凸,也能够识别噪声。但聚类的效果与参数的选取有较大关系。
6结论
6.1 K-Means算法与AGNES算法比较
K-Means算法的时间复杂度和空间复杂度都较低,即使对于大型数据集,也是简单高效的。而AGNES算法的时间复杂度高,并不适合大型数据集。此外,对于AGNES算法一旦凝聚形成了新簇,就不会对此再发生更改。虽然,k-means算法与AGNES算法都需要指定划分的簇数,但由于k-means算法需要挑选初始中心点,故其对初始值的设置很敏感。一般而言,上述两种算法都对非凸数据集无法起到良好的聚类效果,但在中小型数据集中挖掘得到球形簇的效果较好。
6.2 K-Means算法与DBSCAN算法比较
与K-Means算法相比,DBSCAN算法不需要明确K值,即不需要事先指定形成簇类的数量。此外,DBSCAN算法可以发现任意形状的簇类,也能够识别出噪声点。而K-Means算法对噪声和离群值非常敏感,并且对非凸数据集的聚类效果不佳。当数据集较大时,K-Means算法容易陷入局部最优。虽然DB—SCAN算法具有众多优点,但其对两个参数eps和Minpts的设置却非常敏感,导致聚类的效果与参数值的选取有较大关系。
6.3 AGNES算法与DBSCAN算法比较
AGNES算法可解释性好,能产生高质量的聚类,但其时间复杂度较高,不适合大型数据集。同时,AGNES算法与K-Means算法类似,倾向于得到凸型的cluster,对非凸数据集并不能得到較好的聚类效果。而DBSCAN算法可以发现任意形状的簇类。
7结语
K-means算法、AGNES算法、DBSCAN算法分别是聚类算法中基于划分、层次、密度的三种典型算法。通过对上述三种算法的简单分析比较,我们可以依据实际情况选取最为合适的算法对数据集进行聚类,从而得到最佳的效果。
猜你喜欢
电子测试(2017年15期)2017-12-18
哈尔滨理工大学学报(2016年4期)2016-11-10
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
电子设计工程(2015年6期)2015-02-27
现代电子技术(2014年8期)2014-09-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
