
基于粒计算的ELM加权集成算法研究
2020-07-03 08:09:10陈丽芳代琪付其峰
华北理工大学学报(自然科学版) 2020年3期
陈丽芳, 代琪, 付其峰
(1. 华北理工大学 理学院,河北 唐山 063210;2. 华北理工大学 信息工程学院,河北 唐山 063210)
科技的飞速发展使得数据规模不断增大,高维非线性数据急剧增长,面对各类数据的特点和不同的行业需求,人们迫切需要研究数据智能处理算法,挖掘数据中的隐含知识,获取数据的潜在价值。传统的学习机直接在原始数据上进行建模处理,由于计算资源有限、数据潜在特征复杂等原因,难以获得问题的有效解,因此,研究适合规模较大的数据处理集成学习算法,科学高效地挖掘出数据中的隐含知识,充分利用数据隐含价值实现智能决策,是目前智能领域新的研究热点[1],对各个行业领域均具有指导作用和借鉴意义。
极限学习机[2](Extreme Learning Machine)ELM是机器学习领域研究的一个前沿方向,具有结构简单、学习速度快和良好的全局寻优能力,因此,近年来许多学者将ELM作为集成学习的基学习机展开研究。邵良杉等[3]提出一种以旋转森林算法为框架,极限学习机为基学习机的集成学习算法模型,在稳定性和预测精度上与传统算法相比均有明显提升;侯玉倩[4]利用杂交水稻优化算法优化极限学习机参数,以优化后的极限学习机为基分类器,各基学习机经过简单赋权后,学习机性能略有提升;Cao等[5]提出一种基于最小平方误差的加权方法,利用得到的权重,优化多个ELM的线性组合,改善了数据的分类性能。
集成学习,因能显著提高学习系统的泛化能力而得到了人工智能领域的广泛关注,是一种新的机器学习范式[6-7]。如何训练出精度更高、差异度更大的基学习机,实现更有效的集成学习,是集成学习领域研究的焦点。随机子空间法有利于提高基学习机的差异度,提升算法的学习精度,但随机子空间法随机性较强,每个子空间中不一定包含足够的重要属性,导致子空间中的数据不能很好的刻画原始数据集数据结构。丁毅等[8]利用多核最大均值差异作为随机子空间相似性度量,选择具有代表性子空间,得到差异性相似矩阵,提升了算法的稳定性。严丽宇等[9]利用标准互信息熵确定属性重要度,将不同属性划分为不同层次,形成分层子空间,并在子空间上构建集成学习算法,提升了算法的学习性能。
分析学者们在随机子空间集成学习和极限学习机的研究成果,部分学者采用加权集成算法,在一定程度上提升了学习效果,但性能对比分析并不明显,尤其是针对较大规模的数据集,并未体现出算法的高效性。随机子空间法可以提高集成学习基学习机的差异性,算法中属性随机性造成新生成的数据集冗余,算法准确率降低,计算代价增大[10]。粒计算是降低数据规模的有效工具[11-14],其分层处理机制恰恰适应了对数据集进行分布式实施的需求,减少冗余数据集,降低算法运算代价,提升算法性能。
因此,研究一种以极限学习机为基学习机,通过粒计算的权重算法确定重要度排序,并依据排序结果划分矩阵粒,针对不同的矩阵粒构建学习机,最后以条件属性重要度为基学习机权重进行集成学习,可以避免随机子空间随机性对算法的影响,提升学习精度。最后,用Python实现算法仿真,并将结果与其他算法进行对比分析,验证算法的精确性和可靠性。
1 相关理论知识
1.1 集成学习
集成学习采用分类器作为基学习机,并使用某种规则把各基学习机学习结果进行整合从而获得比单个学习机学习效果更好的一种机器学习方法,包括样本集、弱学习机、集成规则三要素,在集成规则框架下,构建多个基学习机模型,对问题进行处理,从而得到一个比单个基学习机更优秀的组合学习机模型,该类算法可以解决很多单一学习机无法解决的机器学习问题[15-16]。大部分集成学习方法对基学习机的类型没有限制,并且在诸多成熟的机器学习框架都具有良好的适用性,因此集成学习也被称为“无算法的算法”[17]。
传统的集成学习方法处理规范数据性能较好,而对于复杂数据分类效果有限。因此,在集成学习中融入数据处理方法显得尤为重要,也是目前的一个研究热点。
1.2 粒计算
粒计算[18-19]是当前人工智能研究领域中模拟人类思维和解决复杂问题的新方法,商空间、粗集、模糊集是其主要理论,是研究复杂问题求解、数据挖掘和不确定性信息处理等问题的有力工具。
粒子粒化和粒的运算是粒计算最核心的问题。粒化的目的将问题空间分解为多个子空间,在各个子空间上进行模型构建或求解,从而降低问题维度,有利于问题的求解。利用粒计算的降维思想,在每个子空间上构建基学习机,以相应的集成规则,实现基于粒计算的集成学习,可以有效的分解问题,并获得问题的有效解。
1.3 极限学习机
极限学习机(Extreme Learning Machine,ELM)是从单隐含层前馈网发展而来,因其结构简单、执行速度快,泛化性能好等优点,成为机器学习领域的研究热点,其学习速度明显优于传统的神经网络[20]。
ELM模型随机产生初始权值和偏置值,将传统的神经网络求解过程由非线性模型转化为线性模型,只要激活函数是连续可微的,输出权值就被唯一确定。ELM使用最小二乘解的方法求解输出权值,避免使用传统神经网络的梯度下降法进行求解,因此速度有了很大的提升。在样本规模适中的情况下,ELM模型具有不用反复调参、学习速度快等优势[21]。

(1)
其中,ωi=[ωi1,ωi2,…,ωin]T为第i个输入节点与隐含层节点的权重,βi=[βi1,βi2,…,βin]T和bi分别为第i个隐含层节点与输出节点的权重和偏置。
通过寻求最优的网络参数使目标函数t的取值最小:
(2)
即存在βi,ωi和bi满足:
(3)
式3可以简化为:
Hβ=T
(4)

(5)
H被称为神经网络的隐含层输出矩阵,H的第i列是关于输入的第i个隐含节点的输出。
2 算法设计
该算法的设计流程如图1所示。
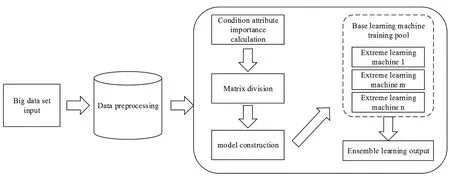
图1 极限学习机加权集成学习算法流程
其计算步骤如下:
Step 1 利用文献[23]中的属性权重计算方法,计算出各条件属性的权重ω1,ω2,…,ωn,并依据权重结果对各条件属性进行排序。
Step 2 对条件属性权重ω1,ω2,…,ωn升序排序后,依据排序结果粒化数据集,将数据集划分为m个矩阵粒,用GrM表示。
设条件属性为ai,决策属性为D。
(1)令ω1={a1},则第一个矩阵粒为GrM1={[a1,D]}1;
(2)令ω2={a2},由此获得第二个矩阵粒为GrM2={[a1,a2,D]}2;
(3)以此类推,令ωn={an},则第n个矩阵粒为GrMn={[a1,a2,…,an,D]}n。
Step 3 以极限学习机为基学习机,对不同的矩阵粒构建学习机模型,实现不同粒层的学习。
Step 4 以各属性的重要度作为基学习机权重,如矩阵粒GrM1上构建的基学习机的权重为属性a1的权重ω1,矩阵粒GrM2上构建的基学习机权重为属性a2的权重ω2,以此类推,对基学习机的结果进行加权集成,获得最终的学习结果。
3 仿真对比分析
基于Python编程,实现以极限学习机为基学习机的加权集成算法仿真。
硬件环境:CPU: i7-4870HQ;RAM:16 GB;软件环境:操作系统:macOS 10.12;解释器:python 3.6,数据集按照训练集80%;测试集20%随机划分,采用十折交叉预测,不同数据集预测结果的MSE均值为最终结果。具体算法描述如下:
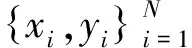
输出测试集的预测结果
(1)数据集预处理阶段
(2)权重计算阶段
按照公式6计算模糊相似矩阵R;
(6)
a. 根据模糊相似矩阵R输出结果,将相似度由大到小排序进行聚类,得到聚类结果C;
for (k= 1;k 删除离散化样本集中的属性k; 将剩余属性值相同的样本划分为同一等价类,得到删除属性k后的等价类集合Dk; end for ③计算样本属性重要度 for (k= 1;k 与聚类结果C进行比对,按照公式Sik=cik/N确定属性重要度矩阵S,其中cik为Dk中等价类中的元素不在第i商空间族的聚类结果Ci中的同一等价类中的样本数目之和; end for (7) (8) (3)训练阶段 for (k= 1;k end for (4)预测阶段 for (k= 1;k for 测试样本Xtestdo end for end for 本文采用UCI数据集中的5组数据进行仿真实验,数据相关信息如表1所示。 表1 数据集基本信息 该方法(GrM-ELM)预测结果分别与以BP神经网络为基学习机的集成模型(E-BP)、传统极限学习机(ELM)进行对比,以均方误差为依据,对比分析验证方法的可行性和稳定性。实验结果如图2所示。 图2 预测结果(MSE)对比分析 由图2实验结果可以看出,该项研究提出方法的均方误差均优于其他两种传统学习机。由于极限学习机自身的原因,预测结果有所不同,在预测过程中,各基学习机的初始权值和偏置值均随机获得,最大程度保证基学习机的多样性,从结果可以看出,加权集成后的结果明显优于直接应用极限学习机预测。以BP神经网络为基学习机的E-BP算法在误差上明显大于GrM-ELM,因此在集成学习过程中,以极限学习机为基学习机更能提升数据的预测精度。从预测结果可以看出,当样本集中属性个数或样本数量较大时,精度提升更明显。 (1)将粒计算的粒化思想引入矩阵中,利用权重计算方法,将数据集按重要程度划分为多个矩阵粒,基学习机权重即为矩阵粒的权重,在矩阵粒上构建极限学习机加权集成,获得最终预测结果。 (2)该方法通过赋予各矩阵粒上基学习机的权重,使权重确定更加科学合理,并提高了集成学习的预测精度。 (3)仿真结果表明,本文提出的方法有效地实现了数据降维,明显优于其他两种传统方法,不论是属性个数的增加还是样本数量的增加,该模型预测精度和稳定性都有较大提升,为集成学习融合的算法开阔了研究思路。


4 结论
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18测控技术(2018年10期)2018-11-25 09:35:26人大建设(2018年5期)2018-08-16 07:09:00自动化学报(2018年2期)2018-04-12 05:46:21电信科学(2017年6期)2017-07-01 15:44:57制造技术与机床(2017年4期)2017-06-22 11:17:32中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32南都周刊(2015年4期)2015-09-10 07:22:44南都周刊(2015年3期)2015-09-10 07:22:44南都周刊(2015年1期)2015-09-10 07:22:44
