
基于标准数据集的分类器融合学习模型
2020-06-30 10:15吴疆刘欢董婷
微型电脑应用 2020年4期
关键词:支持向量机
吴疆 刘欢 董婷


摘 要: 判别式分类器通过生成不同复杂度的指示函数去调节算法与所解决问题的适应性,能有效地避免过拟合现象。分类器融合方法就是应用单个分类器对特定样本预报的特异性来提高模型的整体预测精度,应用支持向量机(SVM)对乳腺癌数据进行建模,通过选取不同的模型参数(径向基核函数参数gamma和正则化约束参数cost)构建9个单分类器,通过投票策略在单分类器上构建融合分类器,融合模型对乳腺癌数据的预测精度为98.59%,相比单分类模型对此数据集的预测精度97.72%有明显的竞争力,试验结果表明融合模型能有效提升分类器的泛化能力。
关键词: 支持向量机; 交叉验证; 分类器融合
中图分类号: TP 391 文献标志码: A
Classifier Fusion Learning Model Based on Standard Dataset
WU Jiang, LIU Huan, DONG Ting
(School of Information of Engineering, Yulin University, Yulin, Shanxi 719000, China)
Abstract:
The discriminant classifier generates indicators with different complexitres that adjusts flexibility between method and problems, which can efficiently avoid the over-learning. Fusion method is to improve the prediction accuracy by summarizing the specificities of individual classifiers. The purpose of the study is to predict breast cancer with support vector machine (SVM). Nine individual classifiers are trained by selecting different parameters (gamma of radial basis function, cost of regularization parameter), on which the fusion classifier is construct by using voting strategy. 98.59% prediction accuracy is obtained, it is very promising compared with 97.72% obtained by optimal individual classifier. The experimental results indicate that the ensemble model can enhance the prediction accuracy.
Key words:
support vector machine; cross validation; classifier fusion
0 引言
融合方法(Ensemble methods)能有效提高個体分类器预测精度,通过组合单个分类器或者不同的输出特征来提高分类器的预测精度,其核心内容是将多个单分类器的输出结果通过某种决策给出最终的融合结果,期望融合多个分类器对样本预测的特异性来提高对样本的整体预测性能,得到比单个分类器更好的泛化能力。融合分类器主要有以下几种方式:(1)单分类器输出的对待测样本的类别决策(预测结果),然后通过某种决策,如投票策略来确定最终的融合结果,这个方式也叫做决策层融合;(2)将每个单分类器对待测样本的决策输出(样本类别或决策实值)构建新的训练集训练二级决策模型,这种方法也叫做度量层融合。
分类器融合方法在很多领域的应用取得巨大成功,应用玉米叶部病害识别[1]、手语识别 [2]、多分类器融合提取土壤养分特征波[3]、基于多分类器融合的卫星图像舰船目标识别[4]及结合时序方法与环境变量的煤矿生产过程控制[5]等。
实验通过投票策略构建支持向量机[6-7]融合分类器对乳腺癌数据进行预测,期望融合方法能有效提高单分类器的预测准确率。
1 方法和数据
1.1 数据来源
试验所用数据威斯康星乳腺癌数据库(Wisconsin Breast Cancer Database),如图1所示。
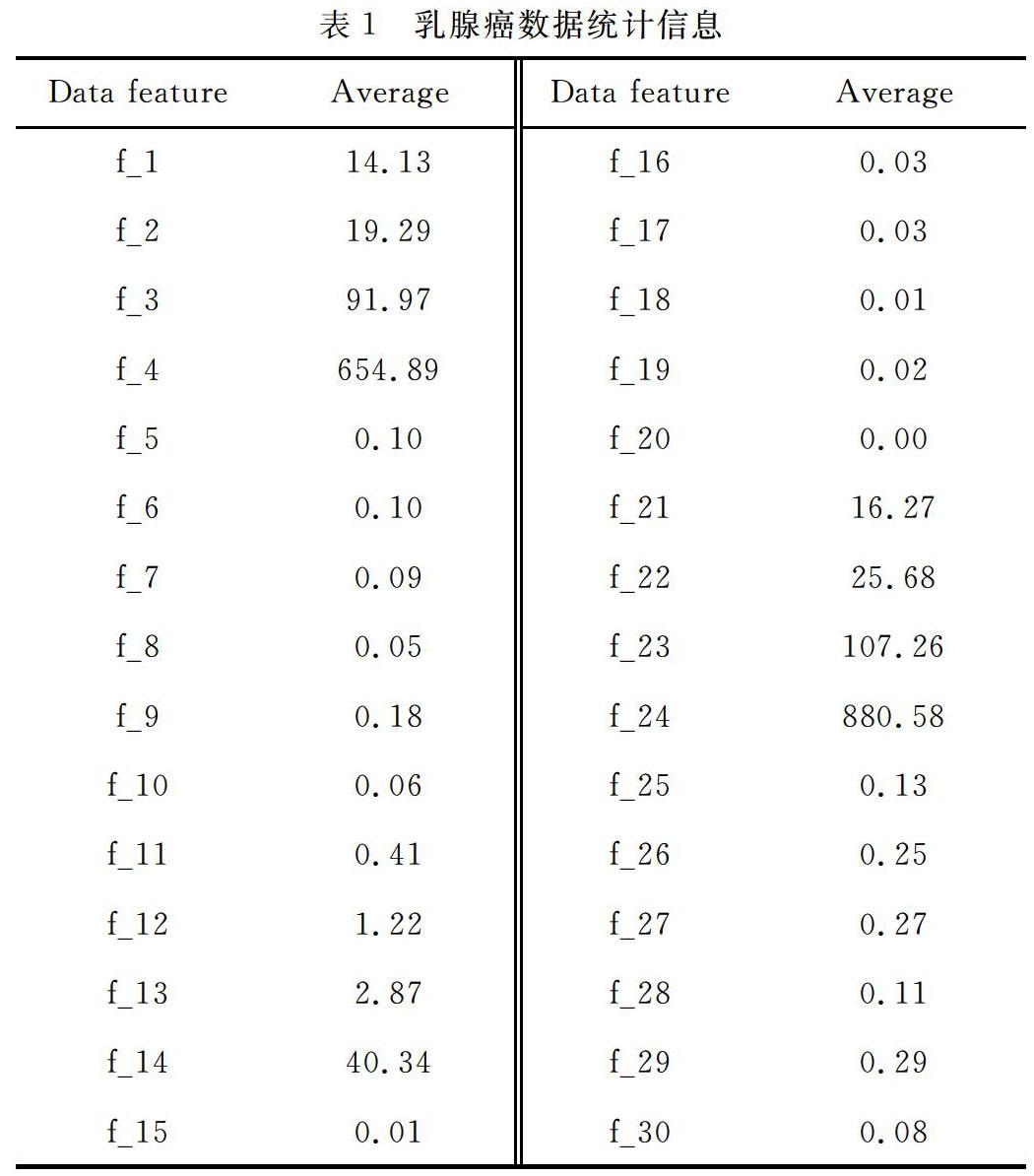
来源于机器学习标准数据库(UCI Repository of Machine Learning Databases),共有569条数据,其中有212条数据来源于恶性的乳腺细胞的测试数据,占整体数据的37.26%;剩余的357条均来源于良性的乳腺细胞的测试数据,占到整体乳腺癌数据的62.74%。其中每一条数据都具有30个特征,原始数据中第一列表示数据的Id号,第二列是数据类别,表示数据的属性是良性还是恶性,M代表恶性乳腺细胞,B代表良性乳腺细胞。剩余的数据项为乳腺癌数据的30个诊断特征,对乳腺癌数据30个属性的统计结果,如表1所示。
1.2 模型评价参数
灵敏度(Sensitivity)、特异性(Specificity)、准确度(Accuracy)用来评价模型的预报性能和泛化能力。其中TP代表将正样本预测为正样本的个数,TN代表将负样本模型预测为负样本的个数,FN代表将正样本模型预测为负样本的个数,FP代表将负样本模型预测为正样本的个数。灵敏度评价模型对正样本预测的准确度,特异性表达模型是对负样本的预测精度,准确度评价模型对样本数据的整体预报能力,三个评价参数的联合应用就可以评价模型对样本数据预报的稳定性,如式(1)—(3)。
2 试验结果与讨论
2.1 支持向量机算法用于乳腺癌数据建模
本实验数据集共两类样本569条数据,属于小样本学习问题,将良性乳腺细胞定义为正样本,恶性乳腺细胞定义为负样本训练SVM分类器。选用径向基核函数,8-fold交叉验证和Grid方法用来挑选最优分类器参数gamma, cost。
首先将数据集平分为8个子集(7个子集样本数为71,一个子集样本数为72)。然后依次选取其中7个子集作为训练集,剩余的一个子集作为预测集构建8个最优分类器,分类模型对乳腺癌数据的预测结果。如表2所示。
2.2 融合分类器算法用于乳腺癌数据建模
分类器融合方法通过一定的融合决策组合个体分类器对样本预测的特异性来提高整体分类性能,大量的研究结果表明分类器融合方法能有效提高分类器的预测精度,融合模型如何组合个体分类器对特定样本预测的特异性来提高模型对样本数据的预测精度,如图2所示。
通过选取不同的参数g, c训练9个支持向量机单分类器(选取训练奇数个单分类器可以避免融合模型投票策略出现冲突现象),假设乳腺癌样本x, SVM(j,x)表示第j个分类器对样本x的预测结果,二分类问题中预测结果用于乳腺癌数据预测流程将所有个体分类器对乳腺癌样本x的预测结果进行统计分析,半单分类器的预测结果半数以上是融合模型对样本的最终预测结果,则融合分类器对乳腺癌样本x的预测结果C(x)运用投票规则可以表示为公式(5)所示。
在公式(5)中,a用来控制投票机制的松弛度,当a取值为1时,要求所有个体分类器对样本x的预测结果一致,在本实验中,选取a=0.5,也就是说融合模型对样本x的预测结果以半数以上单分类器对样本x的预测结果为准。融合SVM分类器对乳腺癌數据的预测结果,如表3所示。
运用多数投票法对个体分类器的特定样本的预测特异性进行融合,能获得更好的预测准确度,与二分类SVM在相同数据集上所得到的预测结果相比,能够得到比之前更好的预报能力,降低对正负样本预测偏置,融合分类器具有更好的置信度和稳定性。融合模型与最优SVM单分类器对乳腺癌数据的预测结果,如表4所示。
运用多数投票法构建融合模型对乳腺癌数据的预测结果可以看出,灵敏度相较于单分类器提高了0.22%,特异性提高了0.72%,准确度提高了0.87%。融合模型对数据集的预测精度提高不大是因为单分类模型本身具有很好的泛化能力,在这个基础上仍然能提高预测准确率说明这种融合算法能有效提升单分类器的预报精度,获得更加平衡稳定的模型。
3 总结
SVM融合分类器方法用乳腺癌数据建模,实验结果表明分类器融合方法能有效提高模型的预测性能。在实验过程中发现选择不同的单分类器构建融合分类器,导致具有不同泛化能力的融合模型。如何选择合适的单分类器来融合是构造出具有更好泛化能力融合分类器的关键环节,在后续工作中将重点研究一种主动的方法来挑选具有显著预测特异性的单分类器,从而构建性能更优异的融合分类器。
参考文献
[1] 许良凤,徐小兵,胡敏,等.基于多分类器融合的玉米叶部病害识别[J]. 农业工程学报,2015(14):194-201.
[2] 林亚飞,曾晓勤. 融合SURF与sEMG特征的手语识别研究[J]. 微型电脑应用, 2019,35(4):55-57
[3] 李雪莹,范萍萍, 刘岩, 等. 多分类器融合提取土壤养分特征波长[J]. 光谱学与光谱分析, 2019, 39(9):2862-2867.
[4] 张晓,王莉莉. 基于多分类器融合的卫星图像舰船目标识别[J]. 通信技术,2019, 52(9):2143-2148.
[5] Feng Z, Zhu S, Wu J, et al. Theory and Method of Time-varying Computational Experiments for the Fully Mechanized Mining Process in an Artificial System Environment[J]. IEEE Access, 2019, 7(6): 168162-168174.
[6] 吴迪,焦东升,张筱,等. 基于SVM 的钢坯号自动识别算法[J]. 微型电脑应用, 2011, 27(10): 49-51.
[7] 曹纳. 基于支持向量机的企业财务风险预警系统设计[J]. 微型电脑应用,2018,34(8):73-77.
(收稿日期: 2019.07.28)
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
